藏文句义分割方法
2020-02-19色差甲才让加
柔 特,色差甲,才让加
(青海师范大学 a.计算机学院; b.青海省藏文信息处理与机器翻译重点实验室; c.藏文信息处理教育部重点实验室,西宁 810008)
0 概述
自然语言处理主要研究词法分析、句法分析、语义分析和语用分析等技术。对于不同的语言单位,语义分析的任务不同,例如,在词义层次上,语义分析的主要任务是进行词义消歧,在句义层面上,其任务是语义角色标注,而在篇章语义层面上,则为指代消歧。随着自然语言处理技术的发展,藏语自然语言处理研究的主要任务从句法分析逐渐转向语义分析。语义分析能够揭示句子的语义,在自然语言处理和机器学习中得到广泛应用。
目前,主要采用基于知识库的方法和表示学习法进行语义分析。基于知识库的方法利用语义词典,如WordNet[1-2]、中文概念词典[3]、知网[4]、汉英双语概念对应方法[5]、蒙汉语义词典[6]、蒙古语名词语义信息词典[7]、藏文语义词典[8-9]等,以及知识图谱[10-11]的语言资源解析句义。表示学习[12-13]法是当前语义分析的主流技术,其通过词向量[14-15]和句向量解读句义。这两种方法都采用“分治”的思想,在分词的基础上通过不同方法达到语义分析的目的。

1 相关研究
语义分割是计算机视觉中的基本任务,其将视觉输入分为不同的语义可解释类别,并且每一类别在真实世界中都有意义。目前,将语义分割应用于自然语言处理的研究较少,本文针对藏文句义分析提出一种语义分割的新思路,即将藏文句子分解成多个语义块,然后通过整合这些语义单元来理解句子语义。本文的主要思想来源于语块理论[16-17],实验证明,大脑对语言进行编码和解码时,能容纳的离散块的最大范围为±7个语块,关注范围是±4个语块,这是语块理论的核心内容。语块理论的实质是一种人类对语言的认知和理解模式。人类在交流时不是先分析语法,再理解语义,语言的流利度很大程度上取决于大脑记忆库中所存储的语块的数量。语块在形义关系上是比较固定的,其以整体的形式存储在大脑中,在使用时直接进行提取或存储[18]。语块的积累可以减轻人类大脑进行语言处理时的负担,减少语法分析过程所耗费的时间和精力[19],从而满足即时交际的需要,使语言从加工到提取,再到使用的过程更加迅速、准确。语义块方法以语块理论为基础,并结合藏文自身的语言特性,是一种以自然语言理解为向导、以句子语义分析为中心的研究方法。
组块分析的方法与语义块的方法类似,组块是一种语法结构,是符合一定语法功能的非递归短语。每个组块都有一个中心词,组块内的所有成分都围绕该中心词展开,且一种类型的组块内部不包含其他类型的组块[20]。汉语组块借鉴了英文的相关研究成果[21-22],其常见的组块类别有名词短语、动词短语、形容词短语、副词短语和数量词短语等。汉语组块的相关研究认为序列具有重要作用,而虚词和助动词等没有实际意义,因此,虚词和助动词等不在研究范围之内[23]。在藏文组块研究方面,文献[24]将提取的汉语组块翻译成藏文,然后利用藏文词序列相交算法抽取藏文短语,文献[25]提出基于藏语组块分析和块内分词的组块自动分词方法,并进行功能性归并,文献[26]提出5种句法功能组块及其功能组块边界的识别策略,并基于条件随机域模型解决功能组块边界的识别问题。组块分析为句子的深入理解提供了有力的支持,众多研究者对其产生了研究兴趣[27]。
组块是在语法分析层面进行句子分割的颗粒度,其大小介于词与句之间,组块分析法是一种浅层句法分析方法,而语义块是在语义分析层面进行句义分割的颗粒度,其大小介于词语与句子之间,语义块分析法是一种浅层句义分析方法。藏文语义块与藏文组块的区别在于藏文语义块需要考虑虚词,虚词不独立成块,且块与块之间相对语义独立。在应用方面,目前大多数藏文信息处理研究都采用深度学习方法,先进行分词再数学化,即利用词向量进行数学化。然而,藏文词向量的颗粒度较小,易产生词语歧义的问题,因此,本文从语义角度进行考虑,利用语义块来弥补上述不足。
2 藏文句义分割
2.1 语义块的定义
语义块是指将一个句子分割为若干个相对独立的语义单元,其长度介于词语和句子之间,语义块分析法是一种语法、语义、语用关联的预处理手段。各语义块之间非递归、非嵌套、不重叠,是藏语自然语言理解中浅层句义分析的一个缓冲,也是把整句先分解后分析的一个媒介。句义、语义块和词义的关系如图1所示。
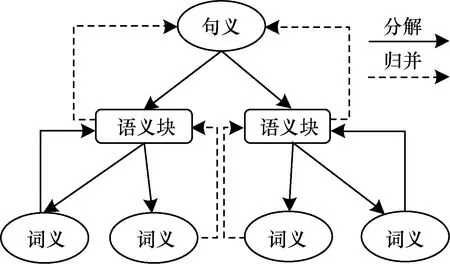
图1 句义、语义块和词义的关系
Fig.1 Relationship of sentence meaning,semantic chunks and word meaning
传统语法研究可以分为词法分析、组块(短语)分析和句法分析,语义研究一般包括词义分析和句义分析。组块是以语法为中心的浅层句法分析方法,不强调语义和功能,其可以简化句子结构,降低句法分析的难度。但是,组块不能覆盖整个句子的所有成分,有些句子成分不属于任何组块。语义块是以语义为中心的浅层句义分析方法,其颗粒度大小介于词语和句子之间,可简化句义,强调语义和功能,从而降低句义分析的难度。在语义块分析中,整个句子的所有成分都要被覆盖,由于藏文中的虚词不能成为独立的语义块,因此将其作为其他语义块的一部分。
2.2 句义分割过程
自然语言处理通常需要对语法、语义和上下文3个方面进行分析。以往藏文自然语言处理研究集中在以词法和句法为主的语法层面,目前,以词义和句义为主的浅层语义研究逐渐增多,并向着以上下文为中心的深层语义研究方向发展。由于句子是语言的最小单位,句子连成段落,段落组成文章,因此句义的正确理解具有重要意义。本文的句义分割方法主要包括4个步骤。



步骤4语义块分割。在完成藏文分词、块标注、块重组之后,需要进行语义块识别,其等同于藏文句义的自动分割。由于块重组是以语义和功能为核心的藏文语义研究思路,不同于短语或组块工作,因此在满足语义块条件下,这些相对独立的语义块在藏文句子中跟序列无关,但表达的句义保持一致。图2为对一个藏文句子进行语义分割的实例。

图2 藏文句子语义分割实例
Fig.2 Examples of semantic segmentation for Tibetan sentences
语义块是为句义理解服务的,而组块是为句法分析服务的。语义块在不需要深层次语言知识的前提下,利用语义颗粒度来缩短句子长度,降低藏文句义分析的难度。此外,语义块遵循传统句法树的语法分析规律、藏文语义角色标注规律和藏文依存语义分析规律,其与传统句法树可以相互转换,符合语法、语义、语用一体化的语义分析研究趋势。
2.3 语义块结构分类


图3 藏文语义块的分类
藏文语义块在符合语法和语义的前提下,其组合结构较稳定且具有一定的凝固性,同时,语义具有完整性和专指性。藏文语义块并非临时性的组合,其在大规模真实文本中具有一定的流通性,含有统计意义。
3 藏文句义分割方法
3.1 基于ID-CNN模型的分割方法
句子的语义分割是藏文句义理解的一项基础工作,可以将其简单理解为一个序列识别的问题,即对于一个给定的句子,先进行分词和标注,在此基础上识别语义块。
语义块识别与命名实体识别具有一定的相似性,本文借鉴实体识别技术进行藏文句义分割。目前,主流的实体识别方法为Bi-LSTM+CRF和ID-CNN+CRF,本文采用dilated CNN模型[28-29]进行句义分割。dilated CNN模型诞生于图像分割领域,对图像进行卷积操作后池化,在降低图像尺寸的同时增大感受野。由于图像分割预测是pixel-wise的输出,因此要将池化后尺寸较小的图像上采样为原始尺寸的图像,然后再进行预测,同时池化层操作使得每个像素的预测都能得到较大的感受野。本文在dilated CNN模型的基础上增加条件随机场(Conditional Random Field,CRF),构建ID-CNN+CRF模型,如图4所示。

图4 ID-CNN+CRF模型结构
在藏文句子分词后,每个词都转化为对应的词向量矩阵,由于颗粒度大小不同,因此句子长度不一致,词向量矩阵的大小也有差异[30]。为了解决这一问题,本文以最长的藏文词为基准,在长度不足的句子两端补充占位符,使得所有词向量矩阵大小相同。对于1维的输入序列和卷积核f:{0,1,…,k-1}→R,空洞卷积运算F可以定义为如下形式:
其中,d为扩张系数,k为卷积核大小。扩张系数控制每两个卷积核间所插入的零值个数,当d=1时,空洞卷积就会退化为一般卷积运算。在扩张系数较大时,输出端的神经可以表征更大范围的输入序列,因此能实现有效扩张。在卷神经积网络输出结果后,通过CRF即可得到本文语义块。
3.2 结果分析
由于目前未发现藏文语义块研究的相关工作,因此没有适合的基准(Baselines)与本文方法的实验结果进行对比。从整体上来看,本文方法的识别效率高于一般分词和短语的识别方法。
本文实验数据主要来源于人工整理的数据和藏文电子书,构建了包含102 358个句子的藏文句库,将其中92 358个句子作为训练集,其余10 000个句子作为测试集。实验数据为藏文简单陈述句,句型结构包括“主语+表语+系动词”“主语+谓语”“主语+宾语+谓语”“主语+双宾语+谓语”“主语+宾语+宾补+谓语”等。在句子长度方面,最短的句子包含5个藏文词,最长的包含22个藏文词。实验的超参数包括词向量维数e、学习速率r、分类器隐藏层节点数h,其具体设置和相应的识别效果对比如表1所示。
表1 不同参数下ID-CNN+CRF模型的识别效果对比
Table 1 Comparison of recognition performance of ID-CNN+CRF model under different parameters

参数设置准确率/%召回率/%F值/%e=50,h=50,r=0.190.1285.1687.56e=50,h=100,r=0.192.6786.5489.50e=100,h=50,r=0.0194.3191.5892.92e=100,h=100,r=0.0194.6890.2292.39

4 结束语
本文提出一种藏文句义分割方法,在对句子进行分词、标注和重组后,通过语义块技术对藏文句子进行句义分割和解析。实验结果表明,该方法能对藏文句义进行有效分割,且可以与藏文句法树分析、藏文依存句法分析、藏文句子语义角色标注等进行相互转化,对藏文句子的知识提取、知识表示和资源扩充等有很好的应用价值。下一步将针对具体的句义理解任务进行研究并验证此方法的有效性。
