基于典型相关分析的多视图降维算法综述
2020-02-19张恩豪陈晓红朱玉莲
张恩豪,陈晓红,刘 鸿,朱玉莲
(南京航空航天大学 a.理学院; b.信息化技术中心,南京 211106)
0 概述
在多数科学数据分析中,对于同一事物可以通过不同的角度或方式来获取信息,这些信息表现出不同的特征属性,如果将每个角度或方式的观察结果视为一个视图或视角,则每个视图均可以得到与之相应的数据,这种数据统称为多视图数据[1-2]。包含多个视图的样本数据可以采用不同的形式进行特征描述[3],如对于一幅图像,颜色信息和纹理信息是2种不同的特征,可以看作是2个视图数据。在网页分类中,通常可以用网页本身的文本内容和链接到此网页的超链接2种特征来描述给定的网页。相比于仅来源于单一渠道的单视图数据,多视图数据更能全面描述事物所具有的信息。
传统的机器学习算法,如支持向量机[4]、判别分析[5]、光谱聚类[6]等算法都是针对单视图数据提出的,面对大量涌现的多视图数据,之前很多算法只是将多个视图简单地合并为单视图数据,以适应学习环境,但是每个视图都有特定的统计属性,这种简单的合并忽略了各自的特性,导致学习效果并不理想。针对有多个视图的数据集,文献[7]提出多视图学习,它的定义宽泛而自然,只要学习任务所给定的经验数据由多个视图来表示,都称为多视图学习。文献[3,8]利用多视图数据不同的信息特征,设计相应的多视图学习策略以提高分类器的性能。与单视图学习相比,多视图学习能充分利用原始数据集,最大限度地挖掘各个视图所包含的先验信息提高学习的效果。因此,多视图学习受到研究人员越来越多的关注[9]。
本文研究基于多视图数据的典型相关分析(Canonical Correlation Analysis,CCA)方法,介绍加入判别信息的相关分析,给出相关算法的基本信息及常用的多视图数据集,在此基础上分析目前多视图降维算法需要解决的问题,并给出相关研究方向。
1 相关研究
多视图学习可以通过视图间互补信息的融合,增强单视图方法的鲁棒性提升学习性能[10]。目前,研究人员已陆续提出了许多多视图学习算法,如多视图迁移学习[11-13]、多视图降维[14-15]、多视图聚类[16-19]、多视图判别分析[20]、多视图半监督学习[21-24]和多任务多视图学习[25-26]等。当前针对多视图数据的研究大致可分为侧重于分类与聚类的协同算法[16,27]以及侧重于降维的相关分析及其改进算法等[28-29]。后者最经典的算法是文献[30]提出的典型相关分析,其主要目的是为识别并量化两组变量之间的关联程度。
近年来,在不同的应用场景中,研究者提出了许多基于典型相关分析的改进算法。典型相关分析最初仅适用于2个视图的情景,文献[31]提出多视图典型相关分析(Multi-view Canonical Correlation Analysis,MCCA)实现了CCA的多视图扩展,使其可同时寻找m(m>2)个视图数据的相关性。但是,对于有标号的多视图数据,CCA与MCCA都没有利用数据集所包含的类信息,造成了类信息的浪费,从而限制了分类性能的提升。文献[32]将类信息嵌入CCA基础框架中进行扩展,得到双视图的判别型典型相关分析(DiscriminantCanonical Correlation Analysis,DCCA),文献[33]在DCCA的基础上提出多视图判别型典型相关分析(Multiple Discriminant Canonical Correlation Analysis,MDCCA)。
CCA是一种线性映射,只能处理视图间的线性关系,文献[34]提出的核典型相关分析(Kernel Canonical Correlation Analysis,KCCA)和文献[35]提出的核判别型典型相关分析(Kernel Discriminant Canonical Correlation analysis,KDCCA)分别为CCA和DCCA的非线性扩展,可求2个视图数据的最大相关的非线性投影。
CCA本质上属于无监督降维,如果将原始数据作为一个视图,将类标签作为另一个视图,利用CCA可将原始数据投影到由标签信息指导的低维空间中,从而实现单视图数据的监督学习[36]。此外,文献[37]提出的局部判别典型相关分析(Local Discrimination Canonical Correlation Analysis,LDCCA)考虑局部特征的组合和不同类之间的判别信息,实现了双视图数据的监督降维。文献[38]提出的广义多视图分析(Generalized Multi-view Analysis,GMA)是双视图到多视图的扩展,并且利用了视图内的判别信息。但是,GMA没有考虑视图间的判别信息,而文献[39]基于典型相关性提出多视图的判别型典型相关(Discriminative Canonical Correlation,DCC)、KAN等人提出的多视图判别分析(Multi-view Discriminant Analysis,MvDA)和YOU等人在MvDA的基础上提出的多视图共分量判别分析(Multi-view Common Component Discriminate Analysis,MvCCDA)则同时融合了视图内和视图间的判别信息。
目前,CCA及其改进算法已经成功应用于许多研究领域,如面部表情识别[40]、图像分析[6]、机器人的位置估计[41]、参数估计[42]、数据回归分析[43]、数据纹理分析[44]、图像检索[45]、基于内容的文本数据挖掘[46]和函数的渐近收敛[47]等。从判别型典型相关分析的研究成果来看,上述研究仍处于初步阶段,但是对现有研究成果的梳理与总结,可以为从事多视图数据分析的研究者提供借鉴。
2 多视图的典型相关分析方法
本节介绍基于多视图学习的典型相关分析算法,并给出相关的理论基础和加入判别信息的典型相关分析方法。
2.1 典型相关分析
典型相关分析是一种用于建模2个变量集之间关系的技术,能够识别并量化2组变量之间的关联程度,它在处理多视图数据的各种学习问题上取得了巨大的成功。CCA可以被视作主成分分析(Principal Component Analysis,PCA)的多视图推广,目的是为了最大化2个数据集的低维映射之间的关系(由相关系数度量)。

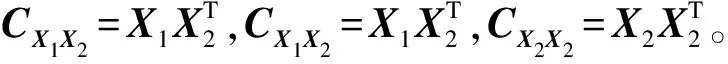
基于尺度不变性,CCA可转化为:
(1)
引入拉格朗日乘子λ1和λ2,可得到如下拉格朗日函数:
(2)

进一步可表示为如下的广义特征值问题:
由此可见,CCA仅为2个视图数据在观测空间中呈线性关系时适用,并且CCA没有利用样本的标签信息,属于无监督降维。
2.2 多视图典型相关分析
典型相关分析(CCA)只能有效处理双视图数据,文献[6]提出的MCCA则将其推广到多视图数据,其基本思想是寻找多个视图的线性变换,对每个视图的样本数据进行投影,使得投影向量之间的相关性最大化。
(3)
利用拉格朗日乘子法可以得到如下形式:
其中:
当N=2时,MCCA退化为CCA,但是MCCA只是CCA在多视图中的延伸,也没有考虑数据本身的监督信息。
2.3 核典型相关分析
典型相关分析(CCA)是从两视图数据中提取信息的技术,它仅适用于线性空间中,在非线性情况下,CCA不再适用。而支持向量机(Support Vector Machine,SVM)[48]中的核方法是一种改进该问题的有效方法[49]。SVM以其在模式识别方面的先进性能而备受关注,SVM中的核技巧不仅适用于分类,也适用于降维算法,如核Fisher判别分析[50]和核PCA[51]等。KCCA[48,52]则是把核技巧融入CCA,得到CCA的非线性扩展,目的是把低维的数据映射到高维的特征空间(核函数空间),并在核函数空间进行关联分析。通过表征引理[53],KCCA的优化目标可以表述为:
(4)
其中,K1和K2是关于X1和X2的核矩阵,A1和A2对应视图的基矩阵,即:
K1(i,j)=K1(X1i,X1j)=φ1(X1i)Tφ1(X1j)
K2(i,j)=K2(X2i,X2j)=φ2(X2i)Tφ2(X2j)
φ1(X1)=(φ1(X11),φ1(X12),…,φ1(X1N))
φ2(X2)=(φ2(X21),φ2(X22),…,φ2(X2N))
其中,φ1和φ2分别表示作用于X1和X2上的变换。
3 加入判别信息的典型相关分析方法
上文介绍的多视图降维方法未考虑样本数据的判别信息,属于无监督学习的范畴。在实际应用中,有些多视图数据本身包含类信息,无监督降维无法有效提取有利于分类的低维特征。目前,已有很多研究者将监督学习融入典型相关分析,得到许多融入判别信息的多视图降维算法,本节介绍其中的部分工作。
3.1 判别典型相关分析
CCA、KCCA和MCCA都属于无监督学习范畴,它们使得样本数据在投影后的方向上相关性达到最大,没有类信息指导的降维无法保证不同类样本在低维空间的分离性。而在分类学习中,各样本的判别信息非常重要,CCA、KCCA和MCCA的无监督特性限制了降维后的可分离性。判别典型相关分析(DCCA)的提出弥补了CCA和MCCA的不足[32]。
对于已经中心化的两组样本数据X1和X2,DCCA的目标是求得一组投影向量w1、w2,使得投影后同类样本之间的相关性最大化,同时使得不同类样本之间的相关性最小化,其目标函数如下:
(5)
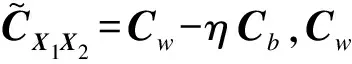
(6)
DCCA的求解可转化为广义特征值问题:
CCA与DCCA的区别在于DCCA利用了数据的判别信息,因此,DCCA能提取有利于分类的低维特征。DCCA同CCA相似,仅适用于双视图数据。DMCCA[29]是DCCA的多视图扩展。
3.2 多视图判别典型相关分析
DMCCA作为DCCA的扩展,将2个视图的数据扩展到多个视图的数据X1,X2,…,XN,求得一组投影向量,使得投影后同类样本之间的相关性最大化,同时使得不同类样本之间的相关性最小化[33],得到DMCCA的优化目标函数:
(7)

约束条件为:
利用拉格朗日法,可以得到如下形式:
(8)

3.3 局部判别典型相关分析
局部判别典型相关分析(LDCCA)是在CCA的基础上同时融入了样本之间的近邻信息和判别信息[36],通过最大化局部类内相关矩阵和最小化局部类间相关矩阵,可以有效实现不同类样本的分离,并进一步提出了核LDCCA(KLDCCA)。
(9)

与CCA类似,LDCCA的解等价于以下最优问题:
(10)
利用拉格朗日乘子法也可转换为广义特征值问题,文献[37]进一步将其核化,得到核局部判别典型相关分析(KLDCCA)以适应于非线性模型。
3.4 广义多视图分析
文献[38]从线性判别分析(LDA)入手[54],将LDA从单视图推广到双视图,从而得到:
(11)
式(11)仅考虑了各个视图内部类信息,之后借助于CCA,进一步考虑了视图间的配对信息,使得配对样本降维之后同类样本尽量相近,不同类样本尽量分离,得到GMA的目标函数为:
(12)
其中,Ai和Bi分别表示每个视图内的类内和类间散度矩阵,权重μi(i=1,2,…,N)用于平衡不同视图的重要性,参数γi=tr(Bi-1)/tr(Bi),i=2,3,…,N对总体性能影响不大。
3.5 判别型典型相关
判别型典型相关(DCC)是由文献[55]基于典型相关性(Canonical Correlations,CC)提出的。CC是由文献[56-57]进行图像集匹配时提出的,文献[58-59]给出了典型相关的非线性扩展。与传统的基于参数分布和非参数样本的方法相比,典型相关性可有效提升算法的准确性、效率和鲁棒性等。
Λ=diag(η1,η2,…,ηd)
其中,Q12、Q21是正交矩阵,典型相关性即为{η1,η2,…,ηd},对应的典型相关向量为U=P1Q12=[u1,u2,…,ud],V=P2Q21=[v1,v2,…,vd]。而DCC的目标则是使任意一对数据集之间的类内关联度最大,同时使类间关联度最小,其目标函数定义如下:
(13)

3.6 多视图判别分析
多视图判别分析(MvDA)将视图内的判别信息和视图间的判别信息结合起来,目标是为了得到N个映射,w1,w2,…,wN把N个视图投影到一个公共判别空间中,使类内相关性最大化且类间相关性最小化[61]。
MvDA的目标函数可表示为广义瑞利熵[62]:
(14)
其中,SW和SB可以表示为:
SB=∑ni(μi-μ)(μi-μ)T
其中,μi是公共子空间中所有视图中第i类样本的平均值,μ是公共子空间中所有视图的所有样本的平均值,ni是所有视图中第i个样本的总数,n是所有视图中所有样本个数。
3.7 多视图共分量判别分析

4 算法基本信息和常见数据集
4.1 算法基本信息
本文中所涉及的算法基本信息如表1所示,其中,√表示存在。

表1 各算法基本信息
根据表1并结合文中对各算法的描述,通过进行对比分析可得如下结论:
1)CCA、MCCA、KCCA只利用配对信息进行相关分析,使得配对的样本数据之间的相关性最大。
2)DCCA、DMCCA不仅利用了数据的配对信息,还利用了数据的监督信息,LDCCA则在DCCA的基础上又考虑了各个视图间的近邻信息,这3个算法的公共目标是投影后同类样本之间的相关性最大化,不同类样本之间的相关性最小化。
3)与前述算法相比,MvDA则是LDA从单视图到多视图的推广,在计算类内差异和类间差异时考虑了视图内和视图间的相关性,并且将多个视图中的样本投影到一个公共空间中,MvCCDA在MvDA的基础上考虑了近邻信息,并且期望第i组配对样本的投影向量收敛到一个公共分量,能够更好地区分视图间的差异性,提高跨视图分类的精确度,并且还可以处理非线性问题。
4)除DCC利用迭代求解外,其余各种方法均有解析解,这利于算法的非线性拓展。
图1为基于CCA的算法发展体系的整体结构。

图1 CCA算法发展体系整体结构
4.2 常见的多视图数据集
为对多视图学习的研究提供实验支持,本文描述了一些广泛使用的多视图数据集并且给出了相应的获取方法。
4.2.1 多特征手写数据库
多特征手写数据库(Multiple Feature Database,MFD)是由一组手写数字(0~9)组成的数据集[64],其中每个图像已经数值化,每个数字(类)都有200个样本(共2 000个样本),这些样本在数据集中由6个特征集(视图)表示。表2是所抽取的6个特征的名称、缩写和维数[65]。
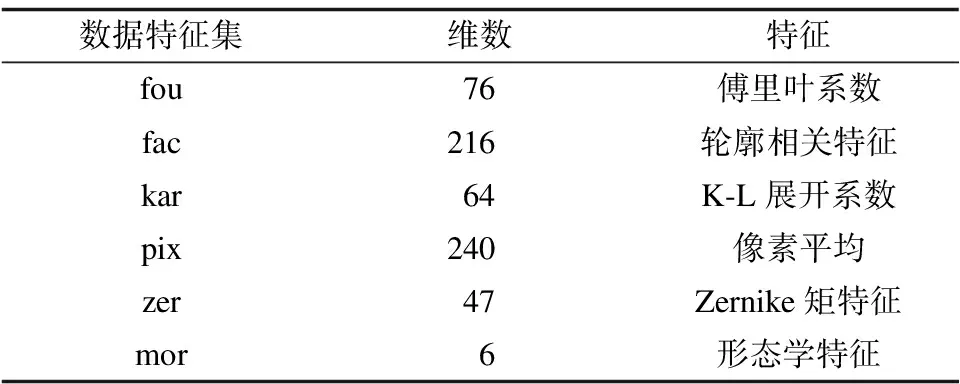
表2 多特征手写数据库
4.2.2 广告数据集
广告数据集[66]包括3 279个网页,每个网页已被处理为稀疏的0-1二值向量,其中,459个是广告(正面样本),2 820个非广告(负面样本),每个网页已经被处理为稀疏的0-1二值向量,表3为Ads数据集中的5种特征。

表3 Ads数据集
4.2.3 Web_KB数据集
Web_KB数据集[66]收集了康奈尔大学、华盛顿大学、威斯康辛大学和德克萨斯大学的计算机系网页的1 051个双视图页面,分为课程类和非课程类,课程类有230个100维的样本,非课程类有821个100维的样本。其中每个页面对应于 fulltext 和 inlinks,分别表示该页面的文本和指向该页面的超链接文本。
4.2.4 Multi-PIE数据集
Multi-PIE(Pose,Illumination,and Expression)数据集[67]被用来评估面部识别的姿态,它包含了75万张不同视图下的337个人的人脸图片。研究对象在15个视点和19个光照条件下拍摄了一系列面部表情。此外,还获得了高分辨率的正面图像。图2所示为5个人每人2幅正面图像。

图2 Multi-PIE数据集图片
4.2.5 中大人脸速写数据集
中大人脸速写数据集是研究人脸速写合成和人脸速写识别的数据库,它包括来自FERET数据库[68]的1 194人。对于每个人来说,在观看这张照片时,都会有一张带有灯光变化的脸部照片和一张由艺术家绘制的带有形状夸张的素描,图3所示为6个人的脸部照片和素描照片。

图3 中大人脸速写数据集图片
4.2.6 HFB数据集
HFB(HeterogeneousFaces Biometrics)数据集[69]包含来自100个受试者的人脸图像,包括4个近红外(NIR)图像和4个视觉(VIS)图像,它们各自没有任何自然配对,其中这2种模式都是图像但是来自不同的视图,如图4所示。

图4 HFB数据集图片
4.2.7 ORL人脸数据集
ORL人脸数据集,又称AT&T人脸数据集[70],包含40个不同受试者,其中每人有10幅不同的图像,图像是在不同的时间、不同的照明、不同面部表情(开/闭着眼睛,微笑/不笑)和不同面部的细节(眼镜/不带眼镜)情况下分别拍摄的,图像为均匀黑色背景的正面人脸(允许有小角度偏离)。图5为1个人的5幅不同的图像。

图5 ORL人脸数据集图片
4.2.8 3Sources数据集
3Sources数据集收集了BBC、路透社和卫报3个著名的新闻社的948篇新闻文章,涵盖2009年2月—4月期间的416篇不同新闻故事。每个故事都用6个主题标签中的一个或多个手工标注,即商业、娱乐、健康、政治、体育、科技。它们大致对应于3个新闻源使用的主要部分标题,共包含3个不同的视图。
5 存在的问题及发展趋势
5.1 多视图降维算法存在的问题
虽然众多研究者已对多视图数据的降维做了许多工作,但仍有很多问题需要进一步研究。目前所存在的问题主要有以下4个方面:
1)现阶段数据规模越来越庞大,而大多数基于CCA的降维算法涉及到矩阵的QR分解或奇异值分解,对于小型数据集性能较好,但是对于大型数据集的计算速度非常慢,时间复杂度较高,可能会导致维数灾难[71],这使得处理大型多视图数据集变得非常困难。因此,如何有效处理此类问题是众多研究者所面临的一个难题。
2)本文所介绍的算法大都为线性降维,在实际应用中很多数据是非线性可分的。目前,针对此问题常用的方法有两种:一种方法是运用核技巧将数据映射到高维特征空间,从而实现原始数据的非线性降维[35];另一种方法是与流行学习相结合,利用各个样本的近邻信息进行相关分析[72],但是这2种方法受噪声影响比较大,导致算法性能不稳定。
3)受收集环境和实际应用场景的限制,收集到的数据往往是不完整的,而现有的多数多视图降维算法,不但要求多视图数据集是完整的,而且要求不同视图的数据完全配对,所以这些方法无法有效处理视图数据缺失的情形,从而限制了应用范围。
4)在现实生活中,多视图(多于2个视图)数据随处可见。本文介绍的多视图降维算法大多是基于2个视图降维算法的简单拓展,即通过对目标函数进行加法运算,将所有的视图结合起来。这种方法忽略了数据本身的高阶统计信息(相关信息),影响了算法性能的提升。
5.2 发展趋势
针对目前多视图降维算法所存在的问题,本节给出一些值得研究的方向,主要分为以下4个方面:
1)与稀疏学习相结合。数据的稀疏性可以降低算法的时间复杂度和存储空间,并且稀疏表示使得模型的可解释性提高,所以将稀疏学习与多视图降维算法相结合,有利于提高算法的性能[73]。文献[74]提出了LS_CCA(Large-Scale CCA)算法,该算法是一种可以在大型稀疏数据集上快速计算CCA的迭代算法。文献[75]将稀疏表示嵌入到CCA中,提出了稀疏典型相关分析,使得当数据维数较高时,同样能有效地对数据进行相关性分析。此外,其他一些多视图降维算法也需要设计出大规模的学习算法,将稀疏学习与数据的监督信息相结合是一种处理大量数据的潜在算法。
2)与深度学习相结合。近年来,深度神经网络在人脸识别、目标分类[76]和目标检测[77]等任务中表现优异,对于大规模的多视图学习任务,它们的性能明显优于其他方法。将多视图降维算法与深度学习方法相结合,可提高其性能。文献[78]提出了深度典型判别分析(Deep Canonical Correlation Analysis,Deep CCA)算法,避免了将数据映射到更高维的特征空间,从而降低时间复杂度。因此,将多视图降维算法与深度学习相结合,设计出更多高效的算法将是机器学习领域的一大趋势。
3)与贝叶斯方法相结合。因为贝叶斯方法可以对变量进行积分与求和来处理不完整的数据,所以它是解决多视图降维算法中视图数据缺失问题的一种可行方法。文献[79-80]利用贝叶斯方法对视图中的缺失数据进行重构,进而处理多视图数据缺失的聚类问题。受此启发,可将贝叶斯方法与多视图降维算法相结合,来解决数据不完整的多视图降维问题。
4)与张量相结合。与向量相比,张量对数据的表示更精确、更有效,可以最大程度地保留数据的原始结构和判别信息,并且基于张量的算法减少了待估参数的个数,可以有效降低算法的时间复杂度。文献[81]提出的Tensor CCA(TCCA)算法将张量应用于CCA,TCCA通过分析不同视图的张量协方差,直接最大化多个(多于2个)视图的典型相关性,可以有效地解决多个视图的特征提取问题。因此,将多视图降维算法与张量表示相结合,是一个值得研究的方向。
6 结束语
现实生活中的许多场景可以从多个视角来描述事物,从而得到多视图数据,多视图数据能更全面地描述事件所具有的信息,因此,针对此类数据的多视图学习受到研究人员越来越多的关注。本文介绍了多视图数据降维算法的发展过程,并对其进行分析和对比,列出常用的数据集,从而为研究人员进行研究提供方便。讨论多视图降维算法目前所存在的问题,并给出研究的方向。本文研究对进一步促进多视图降维算法及实际应用具有一定的参考价值。
