一种基于ExtraTrees的差分隐私保护算法
2020-02-19陈子彬谢光强
李 杨,陈子彬,谢光强
(广东工业大学 计算机学院,广州 510006)
0 概述
随着计算机存储数据成本的不断降低以及云计算、大数据、移动互联网等技术的广泛应用和普及,企业、政府组织的信息系统存储了海量数据,如社交网络公司的社交数据、各大电商平台的顾客购买数据以及医院的病人医疗数据等,这些隐私数据常被用于分析、统计和挖掘。从这些数据中发现潜在的商业价值和规律,同时保证不泄露用户敏感信息,引起了数据挖掘和隐私保护领域相关学者的广泛关注。
在早期的相关研究中,数据隐私保护的方法主要是k-anonymity[1]及其扩展模型,如l-diversity[2]、t-closeness[3]和(α,k)-anonymity[4]等。尽管这些模型能够在一定程度上保护数据中用户的敏感信息,但是它们的共同缺点是需要假设攻击者拥有的背景知识和特定的攻击模型,导致其应用场景受到很多制约。在这种背景下,DWORK C等学者[5-6]在2006年提出具有严格理论证明的差分隐私保护模型,该模型为保护数据隐私带来了一种新的解决思路。在差分隐私保护的定义下,即便攻击者拥有除目标用户以外的全部其他信息,用户仍然能够防御攻击并且不会泄露敏感信息。差分隐私保护通过在针对某个数据集上的查询结果添加噪声来提供保护,且基于差分隐私保护的算法在输出结果上添加的噪声独立于数据集的规模,添加少量的噪声能够保证隐私数据的安全性以及输出结果的可用性。
目前,差分隐私保护的研究方向集中在差分隐私数据发布[7-9](延伸至社交网络[10]、轨迹数据[11])、社交网络研究[12-13]、查询处理[14-15]以及和数据挖掘相结合(如聚类[16]、分类[17-19]、集成学习[20])等方面,而在回归分析上的研究则相对较少。进行差分隐私保护回归分析研究的难点在于求解回归目标函数的敏感度很大,难以保证回归准确度。
ExtraTrees作为一种使用频率较高的集成学习模型,能够应用于决策树分类和回归分析中,本文提出一种基于ExtraTrees的差分隐私保护算法。在决策树分类上,利用ExtraTrees算法2次随机选择的特性,提高指数机制在同等隐私预算下的使用效率,通过将基尼指数作为指数机制在分类树特征选择上的可用性函数来降低敏感度,从而减少所添加的噪声量。在回归树上,选择最佳分裂特征和分裂点时将方差作为指数机制的可用性函数,标记叶子节点时对其均值添加拉普拉斯噪声。
1 相关工作
1.1 差分隐私的定义
定义1(ε-差分隐私) 设有2个数据集D1和D2,两者的属性结构相同,不同的记录数量为|D1ΔD2|。当|D1ΔD2|=1时,设一个随机化算法为M,RRange(M)代表算法M的所有输出构成的集合体,S是RRange(M)中的一个子集,若算法M提供ε-差分隐私保护,则对于所有的S∈RRange(M),有:
Pr[M(D1)∈S]≤exp(ε)Pr[M(D2)∈S]
(1)
其中,Pr[]代表某个事件泄露隐私的概率,其由算法M本身的性质所决定,ε称为隐私保护预算,是由数据提供者视隐私保护程度所给定的参数,隐私保护程度与ε的取值成反比,ε通常取小于1的常数。式(1)表示对算法M的任何一个输出结果,不管函数的输入是D1还是D2,最后得到这个输出结果的概率差别很小。
1.2 差分隐私保护实现机制
差分隐私保护的实现原理是通过添加噪声来提供保护,经常使用的2种噪声模型为拉普拉斯机制[21]和指数机制[22]。某个算法提供差分隐私保护所添加噪声的多少与全局敏感度有关。
定义2(全局敏感度) 设函数f:D→Rd的输入为数据集D,输出为任一实体对象,数据集D1和D2之间不同的记录个数不大于1,则f的全局敏感度定义为:
(2)
其中,‖f(D1)-f(D2)‖1表示f(D1)和f(D2)之间的1-阶范数距离。
定义3(拉普拉斯机制) 对于数据集D上的任一函数f:D→Rd,算法M添加由拉普拉斯分布产生的相互独立的噪声变量,以提供ε-差分隐私保护,具体如下:
(3)
定义4(指数机制) 设算法M的输入为数据集D,输出为一个具体对象r∈RRange(M),q(D,r)为可用性函数,Δq为函数q(D,r)的敏感度。如果输出结果满足式(4),则称算法M提供ε-差分隐私保护。
(4)
1.3 差分隐私的性质
定义5(并行组合性)[22]设算法M提供ε-差分隐私保护,给定数据集D被切割成互不相交的子集D1,D2,…,Dn,则M作用在{D1,D2,…,Dn}上的组合算法{M(D1),M(D2),…,M(Dn)}具有ε-差分隐私。
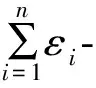
1.4 ExtraTrees算法
ExtraTrees是一种集成学习算法,包含众多决策树,分类结果最终由其包含的众多决策树的输出结果共同投票决定,回归则由这些决策树输出值的均值来决定。ExtraTrees算法最大的特点是在分裂特征的选择上采用随机的方式,随机选择某个特征的某个取值作为该特征的分裂点。由于这2个随机性特点,使得ExtraTrees算法泛化能力较强,具有抵抗噪声的能力。
1.5 已有相关研究
在差分隐私保护决策树分类算法研究中,文献[24]提出了基于线性查询函数的分类器算法SuLQ-based ID3。文献[25]为解决SuLQ-based ID3算法添加噪声过多的问题,提出一种基于决策树建造的差分隐私保护算法DiffP-C4.5。文献[26]沿用数据泛化的思想,在决策树的基础上,提出一种非交互式的差分隐私数据发布算法DiffGen。实验结果表明,在隐私预算相同的情况下,DiffGen的实验效果相较于其他算法更好。文献[27]在DiffGen算法的基础上,通过对细分方案进行改进,为连续型数值加上权重,从而更充分地利用隐私预算,相较于DiffGen具有更好的分类效果。文献[28]将差分隐私和随机决策树模型相结合,提出了RDT算法,但是该算法仅使用拉普拉斯机制,在叶子节点的向量添加噪声。文献[29]提出了差分隐私随机森林算法,该算法的缺点在于仅适合标称型属性的数据集,对于包含连续属性的数据集需要先将连续属性转化成离散属性,然后对数据集进行分类。
在差分隐私保护回归分析算法研究中,文献[30]提出了一个利用拉普拉斯机制和指数机制进行统计分析的总体框架,但是该框架要求统计分析的输出空间有界,导致不适用于线性回归,并且其直接在计算结果上添加拉普拉斯噪声,虽然在一定程度上保护了用户隐私,但是由于添加过多的噪声,造成计算结果的可用性非常低。文献[31-32]研究表明,当回归任务的成本函数是凸函数并且可微时,回归才能满足差分隐私保护。相较于文献[30]直接在输出结果上添加噪声,文献[31-32]在n个目标函数的输出平均值上添加噪声以实现隐私保护,其添加的噪声量有所减少,但该方法普适性较低。文献[33]为了解决回归结果误差大的问题,提出了一种函数机制(Functional Mechanism,FM)。FM机制不是在输出结果上添加噪声,而是通过对回归的目标函数添加噪声,得到加噪的目标函数,然后求解出最优回归模型参数。因此,该机制普适性较高,在多种回归模型上都能应用。但是,由于其计算出来的全局敏感度与数据集的维度成正比,造成噪声添加过多,使得回归结果误差大。文献[34]提出了一种根据回归目标函数敏感度大小来分配隐私预算的算法Diff-LR。该算法将线性回归分析的目标函数拆分成不同的模块,再分别求解出不同模块的敏感度。对模块分配隐私预算时,敏感度大的模块分派隐私预算多,敏感度小的模块分派隐私预算少。虽然相对于函数机制FM,该算法有效降低了敏感度,但是其敏感度依然和数据集维度正相关,导致在数据集维度较大的情况下带来过多的噪声。
2 DiffPETs算法的框架描述与分析
本文提出一种基于ExtraTrees的差分隐私保护算法DiffPETs,并将其应用于决策树分类和回归分析。
2.1 算法描述
DiffPETs差分隐私算法伪代码如下:
算法1DiffPETs(D,A,Pε,t,h)
输入数据集D,特征集A,总隐私预算Pε,产生决策树的个数t,单棵树的高度h
输出满足ε-差分隐私的学习器T={T1,T2,…,Tt}
3.for i = 1 to t:
4.从D中有放回地随机抽样大小为|D|的训练集D(i)
5.调用算法2生成树Ti=Build_DiffPET(D(i),A,ε2,1)
6.end for
7.返回提供ε-差分隐私的学习器T={T1,T2,…,Tt}
算法2Build_DiffPET(D,A,ε,h)
输入数据集D,特征集A,隐私预算ε,单棵树的高度h
输出满足ε-差分隐私的学习器Ti
终止条件节点全部记录的标签一致,误差达到阈值或树达到最大高度h
1.if节点达到了终止条件:
2.返回叶子节点ND=Noise(|D|)
3.end if
5.从K个特征中分别随机选择K个分裂点{s1,s2,…,sK}
6.从K个特征和分裂点中,使用指数机制用以下概率选择最优特征和分裂点:
其中,q(D,A′)表示可用性函数,Δq为可用性函数的敏感度.
7.根据最佳分裂特征和分裂点将当前数据集分割成2个子集Dl和Dr
8.在最佳分裂特征和分裂点的基础上分别建立左右子树tl=Build_DiffPET(Dl,A,ε,h+1),tr=Build_DiffPET(Dr,A,ε,h+1)
9.返回提供ε-差分隐私的学习器Ti
算法1展示了DiffPETs的基本框架,其涉及5个主要的输入参数:数据集D,特征集A,隐私预算Pε,产生决策树的数目t和单棵树的高度h。DiffPETs首先根据生成决策树的数量t和树的高度h将隐私预算Pε进行分配(第1~第2行),然后根据生成决策树的数量t循环建立单棵决策树,每次建立单棵决策树时使用不同的抽样样本,以提高算法的泛化能力(第3~第6行)。算法2展示了生成单棵决策树的详细步骤,首先根据如下规则判断当前节点是否达到终止条件:1)分类树上节点所属记录的分类特征是否相同;2)回归树上节点误差是否小于阈值;3)树是否达到最大高度h。当满足终止条件以后,使用拉普拉斯机制返回添加了噪声的叶子节点(第1~第3行),然后从特征集A中随机选择K个特征和分裂点,使用指数机制选择最佳分裂特征和分裂点(第4~第6行)。本文指数机制的选择方法为:将算法2第6行计算出的各概率值按顺序排列放在坐标轴上,分别对应0~1上的某个区间,之后随机生成一个0~1之间的数,随机数对应哪个区间,指数机制就挑选相应备选项作为输出。最后,根据最佳分裂特征和分裂点递归构造左右子树,返回单棵决策树Ti(第7~第9行)。
2.2 算法隐私性分析
DiffPETs算法首先将总隐私预算Pε平均分配给每一棵决策树ε1=Pε/t。根据差分隐私的性质[22],由于单棵树的样本有交集,因此算法耗费的隐私预算为单棵决策树耗费隐私预算的总和,然后按照同样规则递归产生每一棵决策树。具体步骤如下:首先从D中有放回地抽取大小为|D|的训练集D(i),随后将单棵树的隐私预算平均分配给各层ε2=ε1/(2(h+1)),每层的隐私预算平均分成两部分,一部分应用拉普拉斯机制对划分到该节点的样本数添加噪声,然后判断是否满足终止条件,若满足则将此节点标记为叶子节点,若没有达到终止条件,随机地从|A|个特征集中选择K个特征,之后再随机产生K个分裂点,利用指数机制和剩余的隐私预算选择最佳分裂特征和分裂点。因此,算法所耗费的全部隐私预算是Pε,提供ε-差分隐私保护。在分类中,指数机制中的可用性函数为基尼指数,而在回归中其可用性函数为方差。
2.3 敏感度分析
2.3.1 基尼指数的敏感度
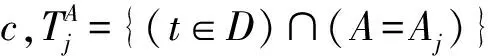
(5)

(6)
2.3.2 均值的敏感度
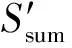
2.3.3 方差的敏感度
决策树方差的定义如下:
(7)
3 实验结果与分析
本文分类器训练算法、测试算法和数据处理均通过Python3.5版本实现,无差分隐私的算法调用scikit-learn库实现。硬件环境为Intel(R)Core(TM)i5 2.5 GHz,内存为8 GB 1 600 MHz DDR3。为检验DiffPETs算法的性能,采取如下5个UCI公开数据集进行实验:1)Mushroom数据集,根据蘑菇的各种特征预测蘑菇是否可以食用;2)Nursery数据集,根据家庭背景等特征预测申请幼儿园的等级;3)Congressional Vote Records(CongVote)数据集,美国国会投票记录,预测共和党或民主党是否能够当选;4)WineQuality数据集,根据物理化学特性预测红葡萄酒的质量;5)Daily_Demand数据集,预测巴西某一家物流公司订单的总量。表1所示为5个数据集的基本信息。
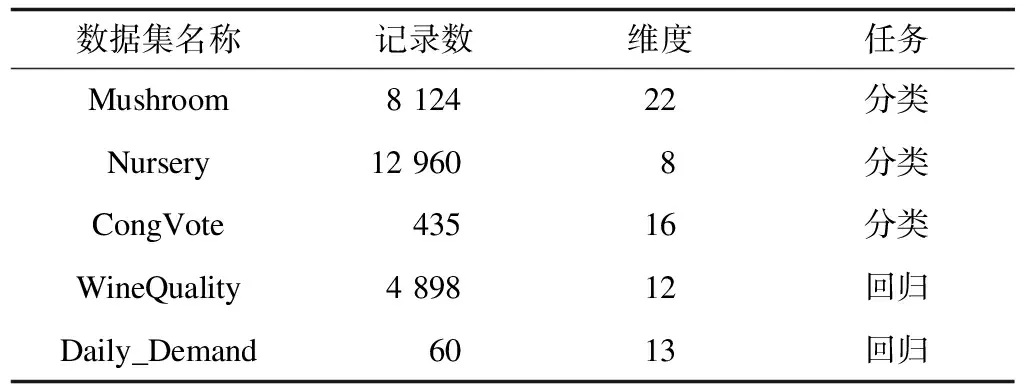
表1 实验数据集信息
3.1 分类实验结果
为验证DiffPETs算法在分类预测中的性能表现,分别令ε={0.50,0.75,1.00}(其对应森林中树的个数分别为t={10,10,5}),设置每棵树的高度为h=k/2,k为对应数据集的维度,可用性函数为基尼指数。本文首先利用DiffPETs算法在训练集上生成算法模型,之后在不同的隐私预算、树的棵数和单棵树的高度下进行实验,最后在测试集上作预测,并计算相应的准确率。每组实验进行10次,以平均实验结果作为最后的准确率,将DiffPETs算法与无差分隐私、RDT[28]和DiffPRF[29]算法进行比较,实验结果如图1~图4所示。
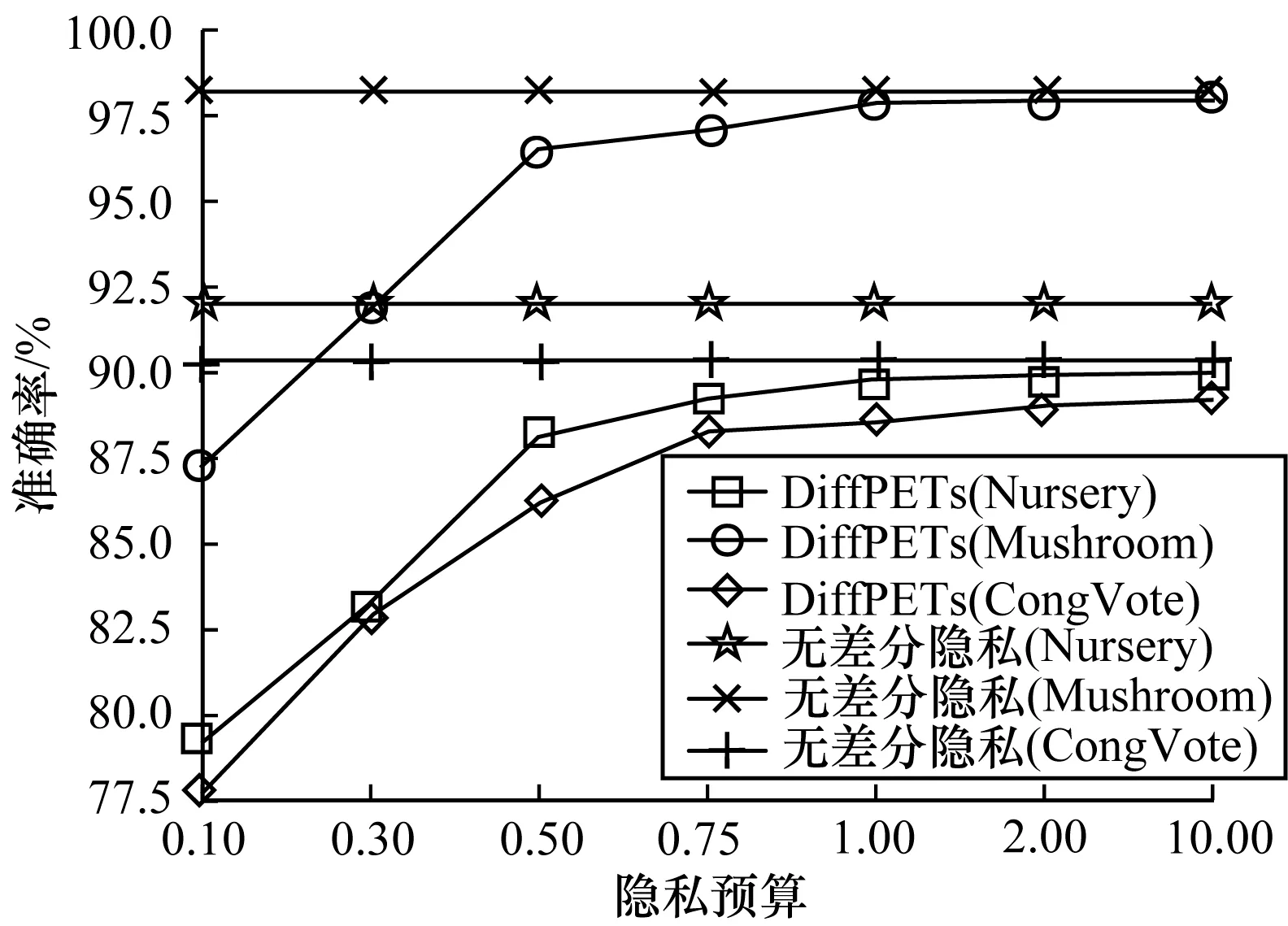
图1 不同隐私预算下的分类结果

图2 Mushroom数据集在不同隐私预算下的实验结果
Fig.2 Experimental results of Mushroom dataset under different privacy budgets
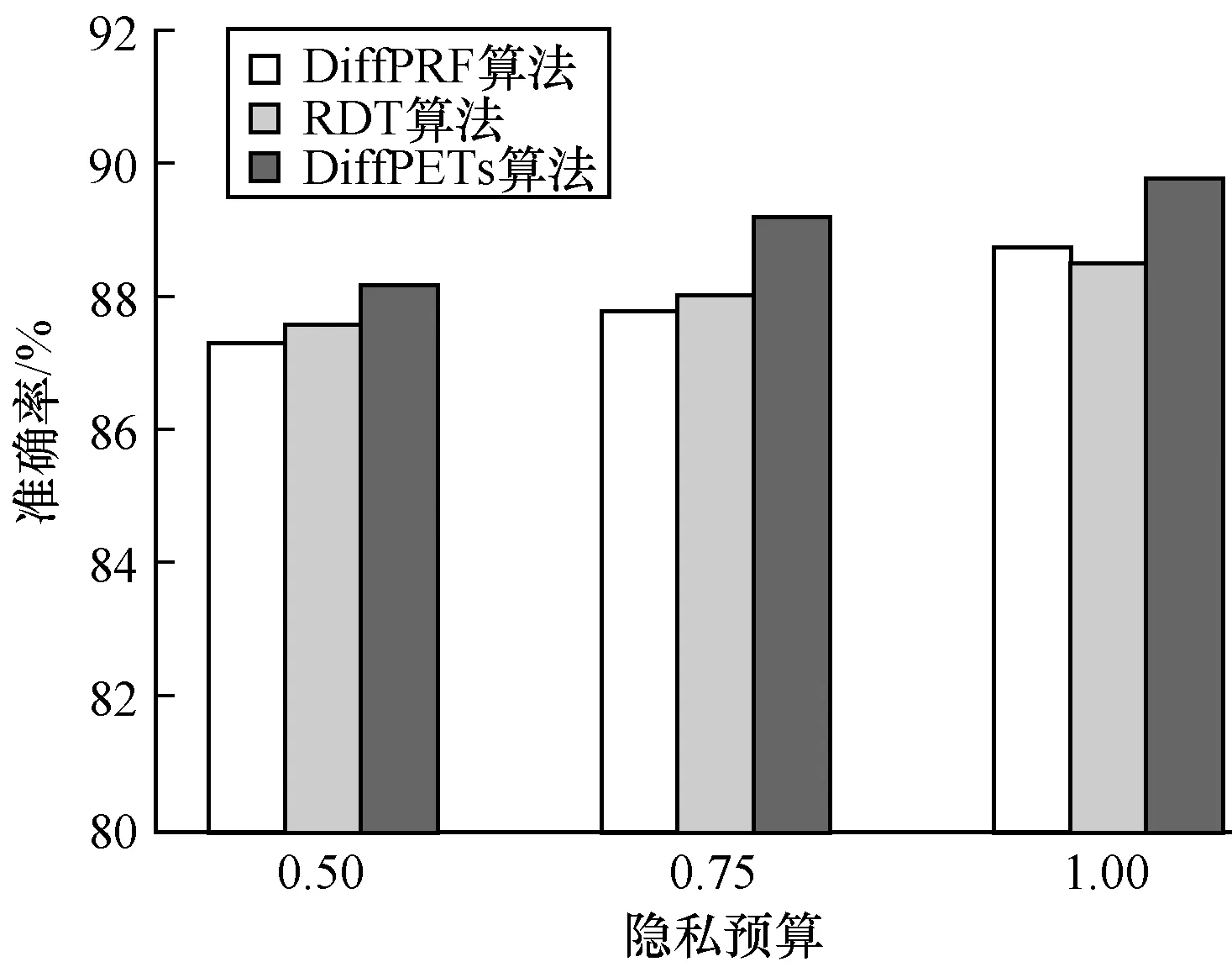
图3 Nursery数据集在不同隐私预算下的实验结果
Fig.3 Experimental results of Nursery dataset under different privacy budgets
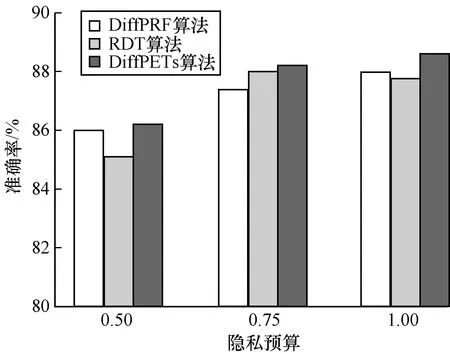
图4 CongVote数据集在不同隐私预算下的实验结果
Fig.4 Experimental results of CongVote dataset under different privacy budgets
从图1可以看出,在隐私预算较小时,DiffPETs算法的准确性不高,可以理解为为了实现高级别的隐私保护,算法不得不做出一些牺牲。随着隐私预算的增加,DiffPETs算法的准确率逐渐提高,原因是添加到算法中的噪声量逐渐减少。通过与DiffPRF和RDT算法进行对比可以看出,本文算法在同等隐私预算下能够实现较低的分类误差。
3.2 回归实验结果
在回归实验中,本文采用均方误差(MSE)来判断算法的性能,其定义如下:
(8)
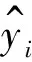
和分类实验一样,令ε={0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0},森林中对应树的个数为t=10。每组实验重复10次,采用最后的平均误差为实验结果,并将本文算法与无差分隐私、FM[33]、Diff_LR[34]算法进行比较,实验结果如图5、图6所示。
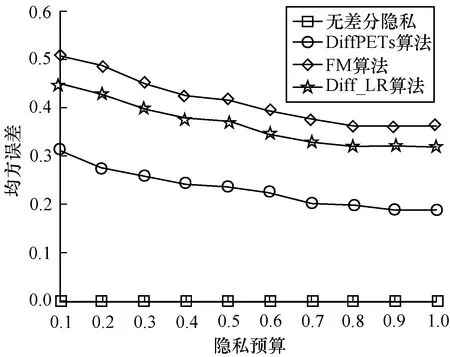
图5 WineQuality数据集的均方误差
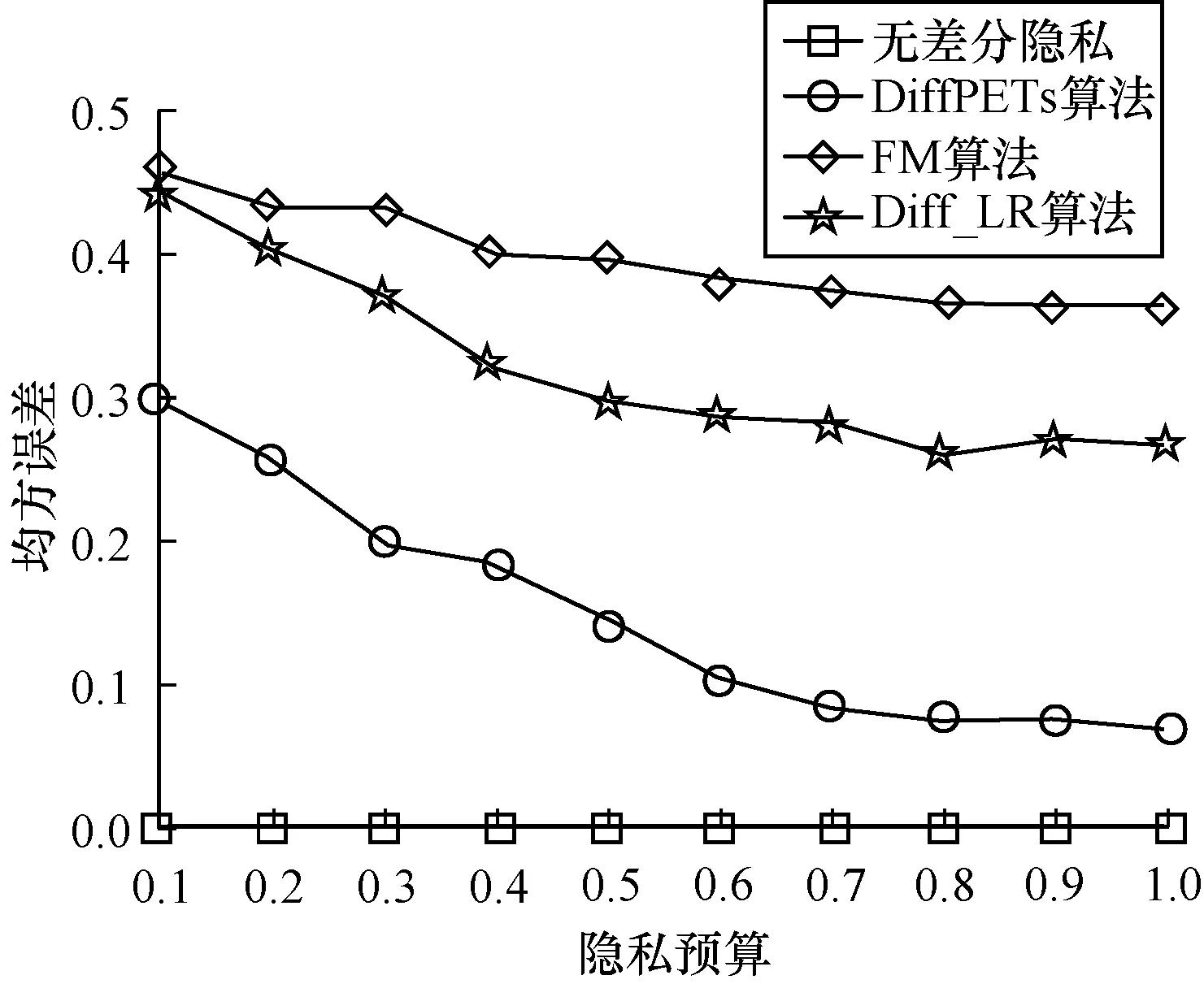
图6 Daily_Demand数据集的均方误差
从图5、图6可以看出,在同等隐私预算ε的条件下,本文DiffPETs算法相比于FM和Diff_LR均方误差更小。随着ε的增加,DiffPETs算法的均方误差与未加噪声的模型逐渐接近。此外,可以看出,没有添加噪声的模型产生的均方误差与隐私预算ε的大小无关。
4 结束语
本文提出一种基于ExtraTrees的差分隐私保护算法DiffPETs,并将其应用于分类和回归分析。在决策树分类时,采取随机的方式选择特征使算法的泛化能力得到有效提升。在回归中,算法的全局敏感度与所添加的噪声均较低,回归预测的结果更准确。实验结果表明,DiffPETs算法具有较高的可行性与准确性。下一步考虑将本文算法应用于交通、医疗等大数据问题。
