基于时间交互偏置影响传播模型的弱连接重叠社区检测
2020-02-19许小媛李海波
许小媛,黄 黎,李海波
(1.江苏开放大学 信息工程学院,南京 210017; 2.南京航空航天大学 计算机科学与技术学院,南京 211106)
0 概述
目前,社交网络已经成为人们日常生活的重要组成部分,如脸谱网、Twitter和LinkedIn等。约68%的在线用户拥有社交信息,用以获取新闻或与其他人进行联系,大量用户加入到在线社区中,使得社区检测成为社会网络挖掘领域中的一项热门工作[1-2]。社区内的用户之间具有紧密的连接关系,社区检测指在给定网络中对所有社区进行识别,其具有较多重要的现实应用,包括有效的信息传播、目标市场识别和感染控制等[3]。
传统的社区检测方法,如Louvain方法、infomap方法、标签传播或Newman主要特征向量方法等[4],主要关注用户之间的关系连接,采用连接关系强弱量化指标。这些方法将网络表示为具有稳定连接的静态结构,原因是这些连接将持续很长时间。文献[5]基于Louvain方法提出一种不相交重叠社区检测方法,其考虑具有可接受时间成本的社会网络中的图分割过程实现方式。文献[6]引入加权社区聚类度量,采用infomap指标实现了大规模图社区模型的可扩展社区检测,该指标的设定依赖于社区中的三角结构。文献[7]基于标签传播算法模型,采用PageRank方法,提出一种大规模社区检测过程中解决处理器负载均衡问题的方法。文献[8]基于Newman主要特征向量方法将社区检测过程优化为一个NP难优化问题,然后采用启发式搜索算法实现对社区结构的有效检测。上述算法均取得了良好的效果,但是,在Twitter数据集中的实验结果表明,多数用户不依赖他们的用户关系连接进行交互操作。
社区边缘携带的关系可提供更有意义的信息,并更准确地反映关系的强度,这些关系可以通过边缘权重的分配来量化,从而提升社区的时间交互测量性能。在社区信息提取中关注动态结构而非静态结构,能提高聚合性度量的准确性并识别出更有意义的社区。
本文研究动态加权图模型社区检测问题,通过预测有影响力的用户未来的活跃趋势,构建一种影响传播模型,以确定用户的高频率相互作用并度量其对邻近用户的影响。同时,为提高社区检测的准确率,针对图社区划分过程引入一个目标函数,并行处理这些分区划分过程以求解影响传播模型。在此基础上,提出一种时间交互偏置(TIB)社区检测方法,以对重叠社区进行检测。
1 问题描述
本文研究一个加权无向简单图G=(V,E,W),其中,V表示节点集合,E表示边缘集合,W是权函数集,ω∈W[8-9]。针对每个边e=(u,v)⊂E,权重w(e)=∑(IInteractions)≥0表示随机选择的时间间隔为t的节点u和v之间相互作用的总频率。例如,在Twitter数据集中,权重为w(e)=∑(@+IRTs),其表示在给定时间间隔t内交互作用的总和,@表示上一时刻交互作用总和,IRTs表示当前时刻的交互作用。表1所示为本文相关数学符号的定义。

表1 数学符号定义
问题1(时间交互偏置问题) 寻找社区C(V,E,W)⊆G,其为k个连通群落集,使得:1)∀e∈E,其中,e是活跃或者半活跃边;2)活跃偏密度度量指标ρ(C)最大化。
为求解连接的k群落约束,首先给出clique的定义:clique是一个完全连通的子图,PC是相邻clique集,这意味着两者共享k-1个节点。例如,对于k群落,如果k=3可视为三角形,则k=3情形下的PC可以被可视化为连接三角形。
在已有研究中,边缘的相关性权重表示网络边缘的活跃程度。在Twitter网络中,边缘加权为40,意味着它含有40个交互过程,并且很可能被视为活跃边缘。但非活跃边缘也有可能是重要边缘,比如其多数邻居是高度活跃边缘的情况。本文定义了一个邻居顶点的活跃边缘,称为偏置活跃边缘。在以往研究中,边缘加权值3通常认为是不活跃的,然而,如果其具有活跃邻居,则它可能成为偏置的活跃边缘,因为该边缘将通过传播这些邻居的权重来重新定义加权值。
在检测时间交互偏置的社区检测背景下,可以认为弱连接边非常重要。虽然在当前时间间隔中其影响很小,但是在后续社区检测过程中,其影响可能被放大,即如果它们的邻域节点高度交互,它们可能在一定时间之后变得活跃。因此,本文提出一种影响传播模型来解决第1个约束,即e可以是活跃的或接近活跃的边缘,它决定边缘的潜在权重并重新定义活跃边缘。
2 时间交互偏置社区检测传播模型
考虑图的每个边缘e,本文模型通过2个步骤确定边缘的权重。第1步基于以下标准对边缘e的权重w(e)进行归一化[10-11]:
(1)
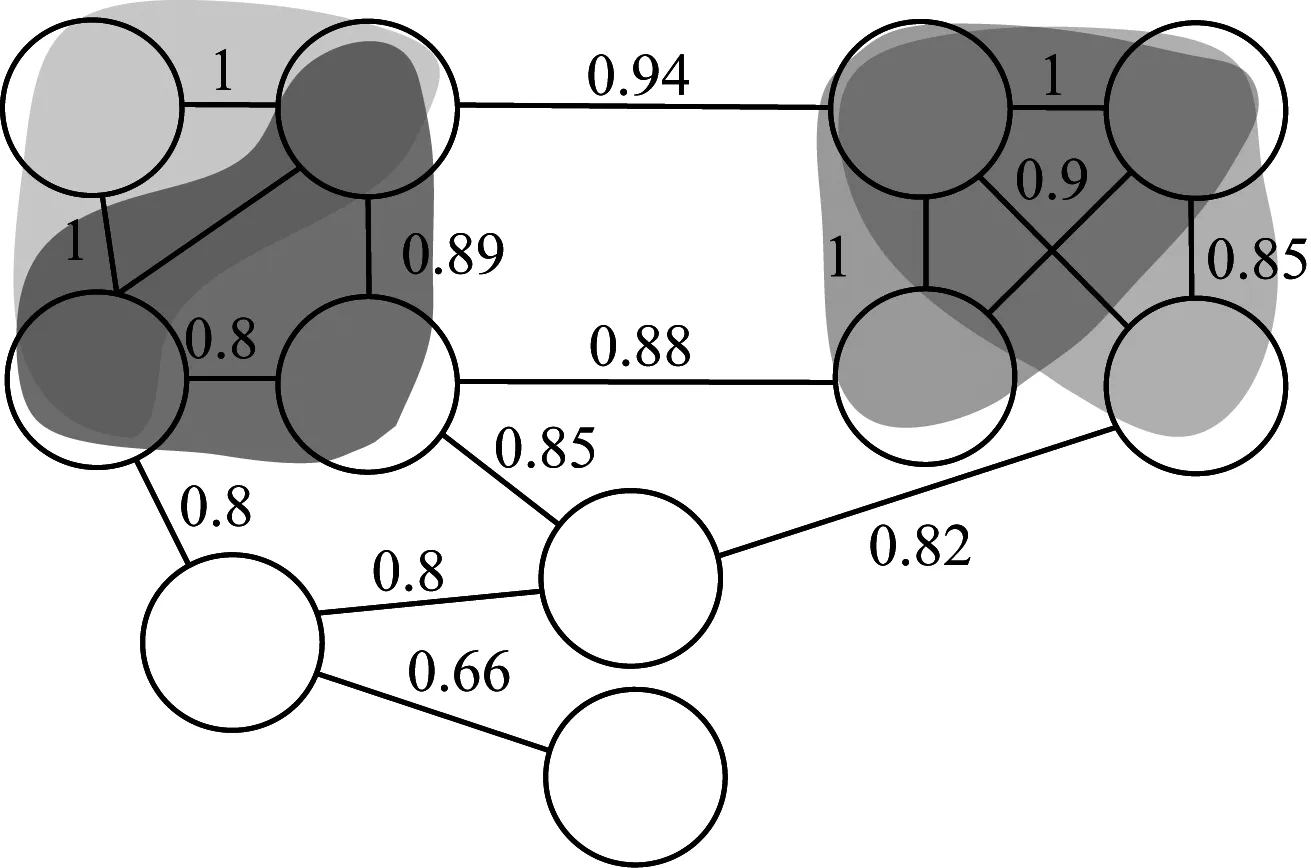
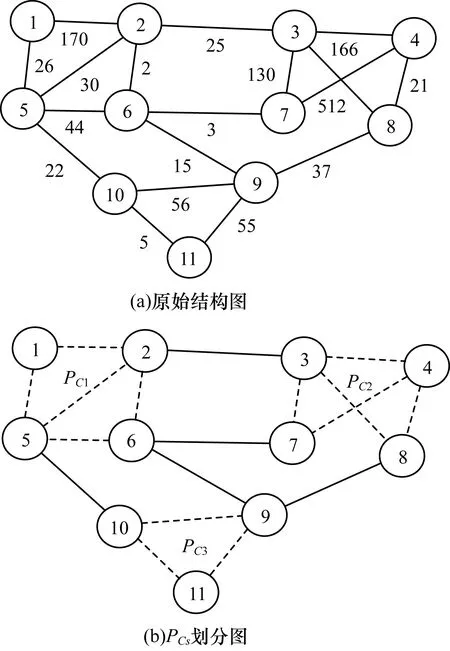
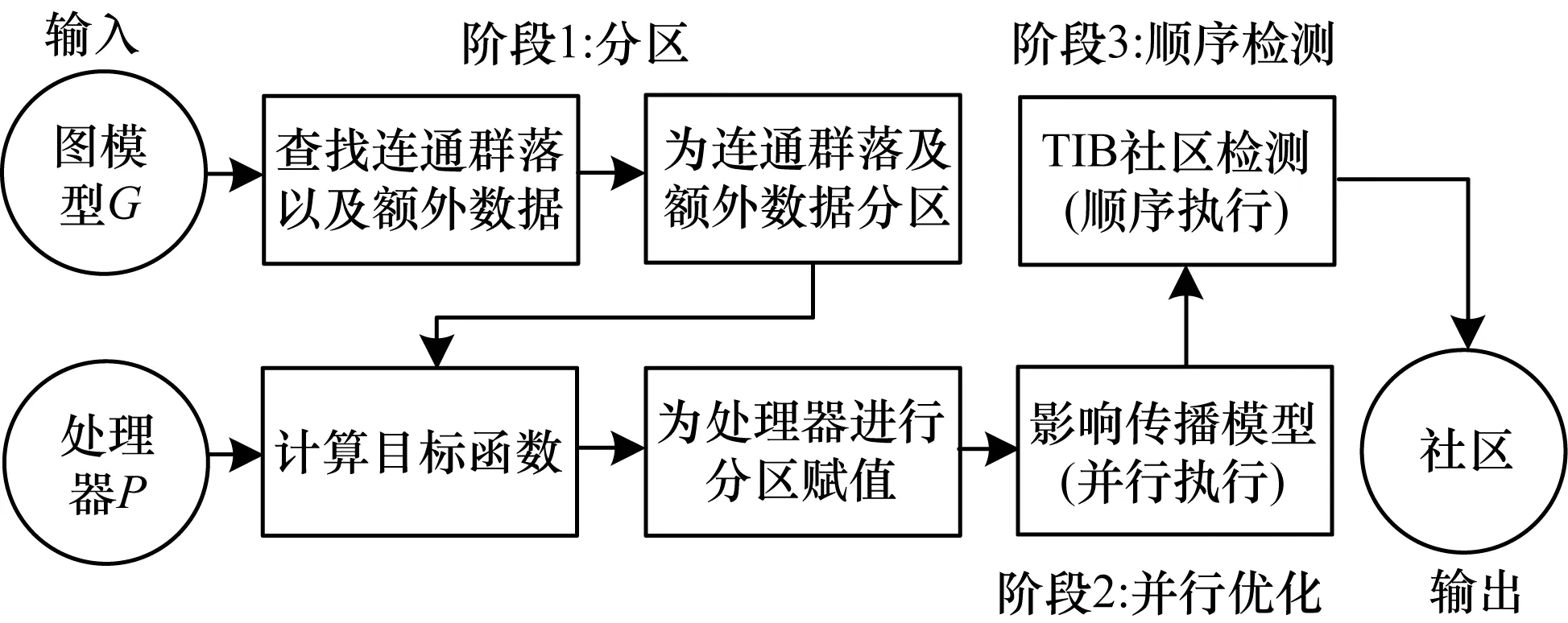
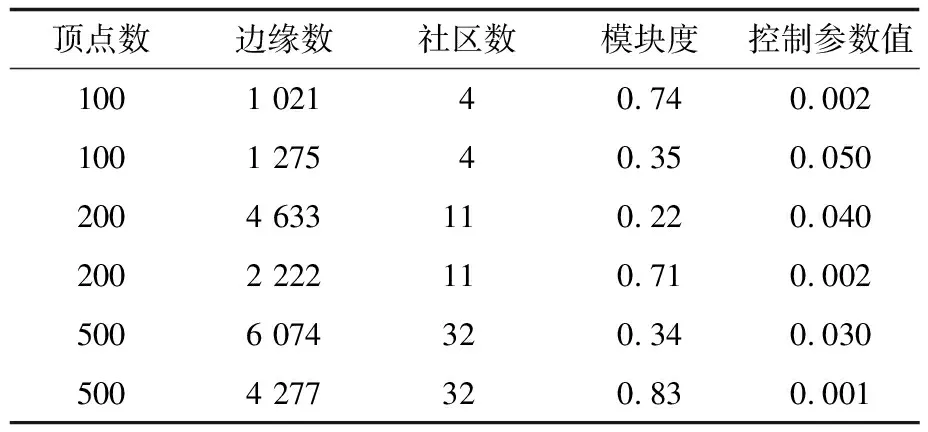
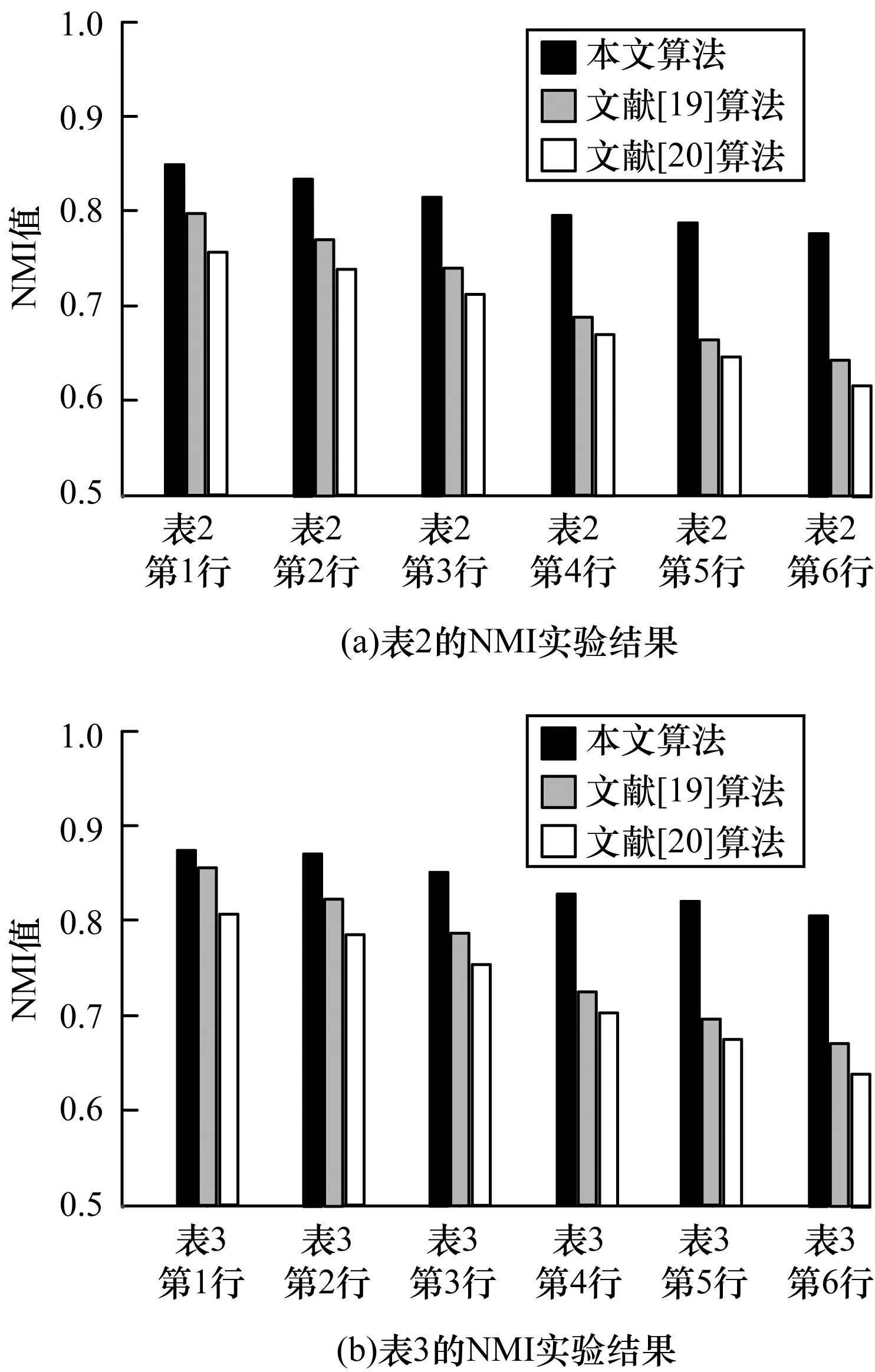
其中,0≤N(e)≤1,非零值参数表示不同的活跃程度。当N(e)=1时,表示边缘的活跃程度为100%。式(1)中的参数m和n是实数,且满足m 定义1(活跃边缘ei) 当N(e)=1时,社区的边缘ei称为活跃边缘[12]。 定义2(近似活跃边缘) 活跃边缘ei在h跳内的相邻边缘称为近似活跃边缘。 本文模型中的第2步是基于活跃边缘ei向其邻居节点e传播归一化权重,过程如下: U(e)=λh·N(ei) (2) 其中,λ(0<λ<1)是一个衰减因子,h是当前边缘和其邻居节点之间的跳数,N(ei)是ei活跃邻居的权重。对于边缘ei的h跳内的下邻域边缘,重复计算U(e),然后,将U(e)的结果存储在一个散列表中,该散列表被用来计算边缘e的最终权重f(e),表示为[13]: (3) f(e)将哈希表中的值相乘,以确定边缘e的新权重。 该学习模型考虑边缘的邻居节点,有助于基于邻居的活跃度来重新定义边缘权重。此外,通过非活跃边缘的相邻边缘权重来计算时间交互的边缘权重,因此,其不仅考虑当前时间间隔,而且关注相邻边缘的影响概率。 示例1考虑图1所示的具体示例,其中,线上数字表示权重,方框中数字表示归一化权重。图1(a)所示为原始加权图。利用N(e)从0到1重新定义权重,当执行式(3)(∀e∈E∧N(e)≠1)时,将结果存储在哈希表中,如图1(b)所示,此处省略了一些细节以避免混乱。使用哈希表来计算每个边的最终权重,如图1(c)所示,其中,采用f(e)进行计算。本文考虑k群落的基本定义以检测重叠社区。 图1 权重赋值示例 定义3(活跃偏置密度) 活跃偏置社区的密度指标可表示为: (4) 活跃偏置社区的密度为社区内权重的总和除以社区的大小|C|,可基于阈值限制群落来评估社区的质量。因此,基于C群落可进行社区发现,其中,ρ(C)可实现最大化。 示例2考虑图2所示的示例,设有一个重构的加权图,在图中找到所有的群落并利用式(4)计算它们的偏置密度值。然后,利用式(4)计算PCs的偏置密度值,结果如图中线上数字。PCs仅在其偏置密度得分高于每个社区的偏置密度分数时形成一个社区;否则,每个群落本身就是社区。图2给出2种情况:左侧的2个PCs在联合时具有较小的密度值,右侧部分是交互作用情况。颜色深浅表示密度值大小。 图2 社区偏置密度值 问题2(基于群落的图划分) 查找社区集R,其中,∀r∈R包含2个约束:1)节点和边属于群落结构;2)分布在处理器组(P)上的均衡数据(节点和边缘)负载。 上述问题中的第2个约束是对处理器上的分区进行平衡,并确保每个处理器具有可接受的数据量。该问题是NP难问题,可采用启发式算法进行求解。本文分配每个PC到一个分区,分区数量等于处理器的数量,每个分区将被分配给处理器。 定义4(目标函数J) 如果满足如下3个条件,可将PCs均匀分配到可用分区:1)分区R的数量大于处理器P的数量,即R≥P;2)每个分区r∈R⊂G具有几乎相同数量的PCs;3)目标函数J取值最小。 为满足上述3个条件,为每个未赋值的参数pc∈PCs进行如下的赋值计算: (5) (6) (7) 示例3考虑图3(a)所示的示例。为对该图进行分割,首先找到群落然后查找PCs,其中,PCs见图3(b)虚线部分所示。假定处理器数量P=2,需要2个分区,每个处理器分配一个分区。为将3个PCs尽可能均匀地划分为2个分区,需要计算目标函数J。首先将PC1分配给分区1,将PC2分配给分区2,而对于PC3的分配,将根据目标函数J的取值进行设置。当添加PC3到分区1中的PC1时,目标函数J的计算结果为54。当添加PC3到分区2中的PC2时,目标函数J的计算结果为44。基于该计算结果,PC3的分区方式将采取后一种情形,将其分配给处理器2。 图3 PCs图分割过程示例 图4所示为本文算法框架,该算法分为3个阶段:1)基于PCs和目标函数J进行图分割,此处不属于群落的节点和边缘将被消除;2)计算每个分区的影响传播模型;3)利用TIB社区检测方法检测社区。算法开始时,输入社区检测的图模型G=(V,E,W),并给定处理器的数量,输出是社区划分集。 图4 本文算法框架 本文社区检测算法各阶段的详细过程如下: 1)图分割,该过程的计算步骤如算法1所示。算法输入是无向加权图、邻域跳数以及处理器P的数目。首先,查找群落(第1行)和PCs(第2行)。然后,收集PCs中每个边缘h跳范围内的邻域节点(第3行~第7行),以计算影响传播模型。接着,分配一些PCs到分区,如果有6个分区,则分配6个PCs(第9行)。随后,基于目标函数J的计算结果,将剩余的PCs分配到分区中(第10行~第13行)。当所有PCs在分区上被平均分配时,算法的分区划分过程结束(第14行~第15行)。 算法1图分割算法 1.输入:G(V,E,W),hops,P 2.C←FindCliques(G); 3.PC←FindPercolatedCliques(C); 4.h←1; 5.for e∈PCand h 6.NP←FindNeighbours(e); 7.h←h+1; 8.end for 9.repeat 10.将n个PCs分配给n个处理器Ps; 11.if PCi未赋值给Pithen 12.J(Pi,PCi+n); 13.将具有最低评估值的PCi赋值给Pi; 14.end if 15.until 所有PCs赋值给Pi; 16.return P集合 算法2影响传播模型计算算法 1.输入:集合P 3.for all e∈E do 4.P(e)←w(e); 5.end for 6.for 所有e满足P(e)<1 do 7.h←1,N←{ }HashTable={ }; 8.while h<4 do 9.N←FindNeighbours(e); 10.HashTable←U(e); 11.h←h+1; 12.end while; 13.end for 14.for all U(e)∈HashTable do 16.end for 3)TIB群落检测。该过程计算算法输入为社区图模型G=(V,E,W),算法基于连通群落识别重叠的社区结构。如图2(a)所示,首先获得一组不能进一步扩展到超出大小k的所有最大群落。在文献[10]中,考虑共享k-1个节点的所有相邻群落,群落选取的标准是密度指标I(G)大于阈值θ,I(G)计算如下: (8) 该函数允许k群落包含比阈值弱的连接,因此,所产生的社区包含强度大于I的k群落。 TIB群落检测的计算过程如算法3所示。本文采用前述ρ(C)指标替代I(G)进行算法设计,偏置密度测量指标可找到不一定相连的TIB社区群落。然后,计算PCs的密度值ρ(C)并作为最大可达的k群落(第3行~第8行)。同时,计算ρ(pli),∀pli∈PL,通过密度比对确定最终的TIB社区识别结果(第9行~第17行)。 算法3TIB群落检测算法 2.CL←{ },PL←{ }; 3.CL←FindClique(G,k); 4.for all cli∈CLdo 5.D←ρ(cli); 6.if cli∪cl(i+1)do 7.PL[pli]←cli∪cl(i+1); 8.D←ρ(pli); 9.end if 10.for all cli∈pcido 11.if D[pli]≥D[cli]do 12.C←pli; 13.else 14.C←cli,cl(i+1); 15.end if 16.end for 17.end for 18.return TIB社区集C={C0,C1,…} 本文选取的社区检测质量评价标准为标准化互信息(NMI)评价指标和F1评估指标。NMI可评估检测社区的相似性,F1可对社区检测精度进行评估。 本文选取的实验对象生成方法是MMSB和LFR,具体生成策略可见文献[14]。根据网络参数的设定,对生成网络的稀疏程度进行调整,以获得不同特性的网络,具体如下: 1)MMSB对象生成方法:该社区生成方法的基础是概率理论,得到p和q间的社区连接,其具有Y(p,q)分布特性[15]: (9) 其中,参数β为社区检测过程中所使用的交互矩阵,Z为社区检测过程中所呈现出的分布形式,其具有多项式特性[16]: (10) (11) 其中,参数α的作用是对生成模型社区的重叠度进行控制。根据实验结果,如果要获得稀疏的重叠社区网络模型,可将模块度指标调整为大于等于0.5;反之,如果要获得稠密的重叠社区网络模型,可将模块度指标调整为小于0.5。表2所示为采用MMSB方法生成的网络实验对象的属性数据。 表2 采用MMSB方法生成的网络对象属性 2)LFR对象生成方法:该社区网络生成方法同MMSB对象生成方法相似,可基于模块度参数的设置控制社区网络模型的稀疏度,其参数设定如表3所示。 表3 采用LFR方法生成的网络对象属性 图5所示为实验对象模型结构,其中,图5(a)、图5(b)分别对应表2的第1行和表3的第3行参数。 图5 实验对象模型结构 利用F1评价指标对社区发现过程进行质量评估,其指标形式为[17-18]: (12) 其中,参数FP是真实网络中为正值但社区检测结果为负值的比例,参数FN是真实网络中为负值但社区检测结果为正值的比例,参数TP是真实网络中为正值且社区检测结果为正值的比例,P表示社区检测的准确率,R表示社区检测的召回率。 为验证算法的有效性,本文选取文献[19-20]中的2种重叠社区检测算法作为对比。F1评估指标实验结果如图6所示。在通常情况下,F1评估结果取值区间在0~1之间,该指标取值越大,表明算法的稳定性越高。从图6可以看出,本文算法的F1值优于文献[19-20]2种对比算法,这表明本文算法的社区检测稳定性更优。同时,在F1评估实验结果的变化趋势上,3种对比算法均随着社区数量的增加而呈现出逐渐降低的趋势,这说明3种算法在进行社区检测的过程中,其稳定性与社区数量存在一定的关联性,社区数量越多,算法稳定性越差。 图6 3种算法的F1测试结果对比 对算法的社区检测准确性进行实验分析,选取NMI作为评估指标。对于社区A和B,NMI具体定义为: (13) 其中,参数N表示社区检测网络中的顶点数,参数C表示社区检测模型所形成的混淆参数矩阵,Ci表示i顶点所在社区检测模型形成的混淆参数矩阵,Cj表示j顶点所在社区检测模型形成的混淆参数矩阵,参数Ci.(C.j)表示矩阵C中顶点数之和,参数Cij表示同时属于不同类型社区的顶点数。CA和CB是社区划分数量。NMI值越大,表示社区相似度越高。仍然选取文献[19-20]中的2种重叠社区检测算法作为对比,实验结果如图7所示。 图7 3种算法的NMI测试结果对比 从图7可以看出,随着网络顶点数量的增加,3种算法的社区识别精度均呈现出下降的趋势。对于相同规模的网络,网络越紧密表示网络的重叠情况越严重,本文算法NMI精度虽然随着顶点数量的增加而下降,但是降低的幅度不大,即该算法的社区检测精度和稳定性更强。 利用API网络数据爬取工具进行真实数据集构建,数据采集平台为新浪微博,在网络中设定一定量的种子账户,获取网络的数据特征,具体过程为:1)选取5个相邻的账户作为种子账户;2)基于深度搜索策略对新浪微博中的相邻顶点进行关注主题的抓取;3)基于基准网络对抓取过程中的参数进行调整。 通过上述数据抓取过程构建的新浪微博网络主题为78组,顶点为900个,微博数据交互信息为5万多条。实验程序选取Java语言进行模型构建,对比算法仍然选取文献[19-20]中的2种重叠社区检测算法,算法性能的评价指标为准确率、召回率及F1值。 对于由网络数据爬取工具获得的新浪微博数据,其边缘数高度依赖于数据爬取的稀疏度,文献[19-20]算法以及本文算法对所抓取数据的检测结果如图8所示。 图8 3种算法对新浪微博数据的检测结果对比 从图8可以看出,在低密度社区检测情况下,3种算法的检测结果差别不大,特别是和文献[20]算法相比,本文算法优势并不明显。但是,随着社区稀疏度的增加,社区之间的重叠和交互程度提升,本文算法因为考虑到了弱连接重叠社区的时间交互偏置影响传播问题,所以其综合性能上升速度较快,而文献[19-20]算法性能变化幅度较小。上述实验结果验证了本文算法在社区发现上的性能优势。 为提高弱连接重叠社区的检测识别准确率,本文提出一种基于时间交互偏置影响传播模型的社区检测算法。通过设计图分割问题的目标函数对计算资源进行均衡优化,同时构建一种影响传播模型,以提高对弱连接用户的识别能力,实验结果验证了该方法良好的社区检测性能。下一步将对用户交互过程中的时间间隔模型进行研究,结合影响传播模型和时间间隔参数,以提高密集活跃社区的检测识别性能。


3 算法框架
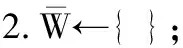
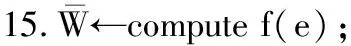
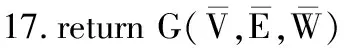

4 实验结果与分析
4.1 实验对象生成

4.2 稳定性对比结果

4.3 准确性对比结果
4.4 真实社区网络检测结果

5 结束语
