面向电耗与网络同步代价优化的数据副本放置研究
2020-02-19樊玉琦王伦飞
樊玉琦,张 蓓,王伦飞
(合肥工业大学 计算机与信息学院,合肥 230601)
0 概述
为满足数据密集型应用的需求,数据中心需要存储大规模数据和来自数亿终端用户的大量数据访问请求[1-2]。应用程序将用户的访问请求指派到一组不同地理位置的数据中心以提供服务,这些数据中心通常由网络连接。对于多数应用程序而言,延迟是一个重要的性能指标[3]。高用户访问延迟已被证明具有负面的经济效应,用户和应用程序都需要较低的网络延迟。与数据中心的排队延迟或处理延迟相比,对于数据密集型应用程序,端到端的网络延迟更加能够反映用户的感知延迟[4-5]。
为满足用户延迟需求并实现数据的可用性和可靠性,云服务提供商通常将一个数据的多个副本同时放置在多个数据中心。如果其中一个副本被修改或者更新,则需要通过数据中心间的网络来同步放置在不同数据中心的多个数据副本。放置在数据中心的这些数据副本会消耗云资源,包括数据中心中存储数据的服务器和不同数据中心之间的网络带宽[6-8]。因此,数据放置到数据中心会产生数据放置代价,包括数据中心服务器所需的电耗代价和数据中心之间数据传输的网络通信代价。
用户通常从距离自己最近的数据中心访问数据,因此,为使用户得到更好的访问延迟性能,应尽可能将数据放置到多个数据中心。然而,多数据副本增加了数据放置代价,因此,假设每个数据具有有限的副本数,不同的数据副本存储位置对数据中心的电耗、数据中心间的网络传输和用户访问延迟具有不同的影响。云服务提供商需要选择合适的数据中心来放置数据副本,以最小化放置代价。
本文假设每个数据具有相同的副本数,在满足用户延迟需求的同时,以最小化电耗代价和网络传输的同步代价为目标,研究云数据中心多副本数据的放置问题,提出一种基于数据组划分和数据中心划分的数据放置算法DDDP。将数据进行分组,并按用户访问数据的延迟要求将数据中心划分成数据中心子集,为每个数据选择满足延迟要求且能最小化放置代价的数据中心子集,以降低数据中心存储数据所引起的电耗和网络传输代价。
1 相关工作
近年来,有学者研究数据放置时的用户访问延迟、数据中心电耗、网络传输代价以及同步代价问题。其中,一些研究关注数据放置对用户访问延迟的影响。文献[9]研究了将数据对象分配给多个存储设备的问题,其目的是最小化访问所有对象的每个请求产生的总处理延迟。文献[10]在满足数据中心处理延迟要求的同时,最小化数据放置代价,并使用混合整数线性规划(MILP)来确定数据放置结果。
部分学者通过综合考虑数据中心的电耗和用户访问延迟来改善系统性能。文献[5]利用不同时间和空间的碳足迹变化,综合考虑电耗代价、服务水平协议(SLA)要求和碳排放减排预算。文献[11]提出了一种包含电价和动态用户请求率的自适应数据放置代价优化框架,并设计了一种近似算法,以最大限度地增加用户被接受的请求数量,该算法不仅考虑了请求均衡分配,而且满足了用户和云服务提供商之间的各种SLA,即响应用户请求的最大延迟。文献[12]提出了一种多数据中心系统电耗最小化的请求路由方案。针对多区域电力市场,文献[13]对文献[12]方案进行了改进,以更好地捕捉波动的电价,从而降低了电力代价。
另有一些学者关注数据放置的网络传输代价以及同步代价优化问题。文献[14]提出了一种计算数据放置策略以最小化网络通信成本,并将数据放置问题规约到经典的图划分问题。文献[6]提出了一种根据社交网络用户的社交关系划分社区的方法,用于社交网络用户数据的放置,其综合考虑数据中心的能耗和数据同步,目的是最小化数据中心的能耗代价和网络同步代价。
从上述研究可以看出,用户访问延迟、数据中心电耗和网络传输的同步代价均对数据放置结果产生影响。但是,在将数据放置到不同地理位置分布的数据中心时,多数现有解决方案[1,6,9]没有同时考虑用户与数据中心之间的端到端延迟、电耗代价和网络同步代价这3个因素。
2 问题描述
设一个分布式云数据中心由N个不同地域分布的数据中心组成,数据中心通过网络进行互连。假设每个数据中心存储容量有限,且数据中心中的服务器同构。将时间段划分为多个时隙,令Q(t)为时隙t的用户请求集合,每个请求由(ri,m(t),wi,m(t))表示,其中,ri,m(t)、wi,m(t)分别表示用户i在时隙t访问数据m的读、写率。为使放置的数据具有高可用性和可靠性,假设每个数据放置K个副本,且副本分布在不同的数据中心,数据放置的位置应该满足用户访问数据的延迟需求。为不失一般性,如果用户的写请求更新其中一个数据副本,则该数据的其他副本也需更新。假设数据副本之间保持弱一致性,即副本之间不一定总是保持一致,但最终会实现一致。无论读或写,数据的放置都会引起服务器的电耗代价。此外,用户的写请求还会引发数据副本更新所需的数据中心间的网络通信代价。
2.1 服务器电耗代价模型
服务提供商需要在数据中心中部署大量服务器以提供数据存储服务,从而导致了数据中心的巨大电耗。数据中心中运行速率为μ的服务器的电耗可以由aμρ+b来估算[5],其中,a、b分别是与服务器巅峰负载状态电耗和空闲状态电耗有关的因子,ρ(ρ≥1)是由经验值确定的参数。数据中心j在时隙t开启的服务器数量为:

(1)
这些服务器的实际服务率为:
(2)

(3)
2.2 网络传输代价模型
当用户i对数据进行写或更新时,数据中心之间的数据同步将引起网络通信代价。当其中一个数据副本被更新时,其他副本也需被更新,以保持多副本之间的数据一致性。更新数据传播路径采用组播树进行数据同步,使更新的数据量在每个所需的网络链路上只传输一次。所有数据的网络通信代价为:
(4)

2.3 数据访问延迟模型
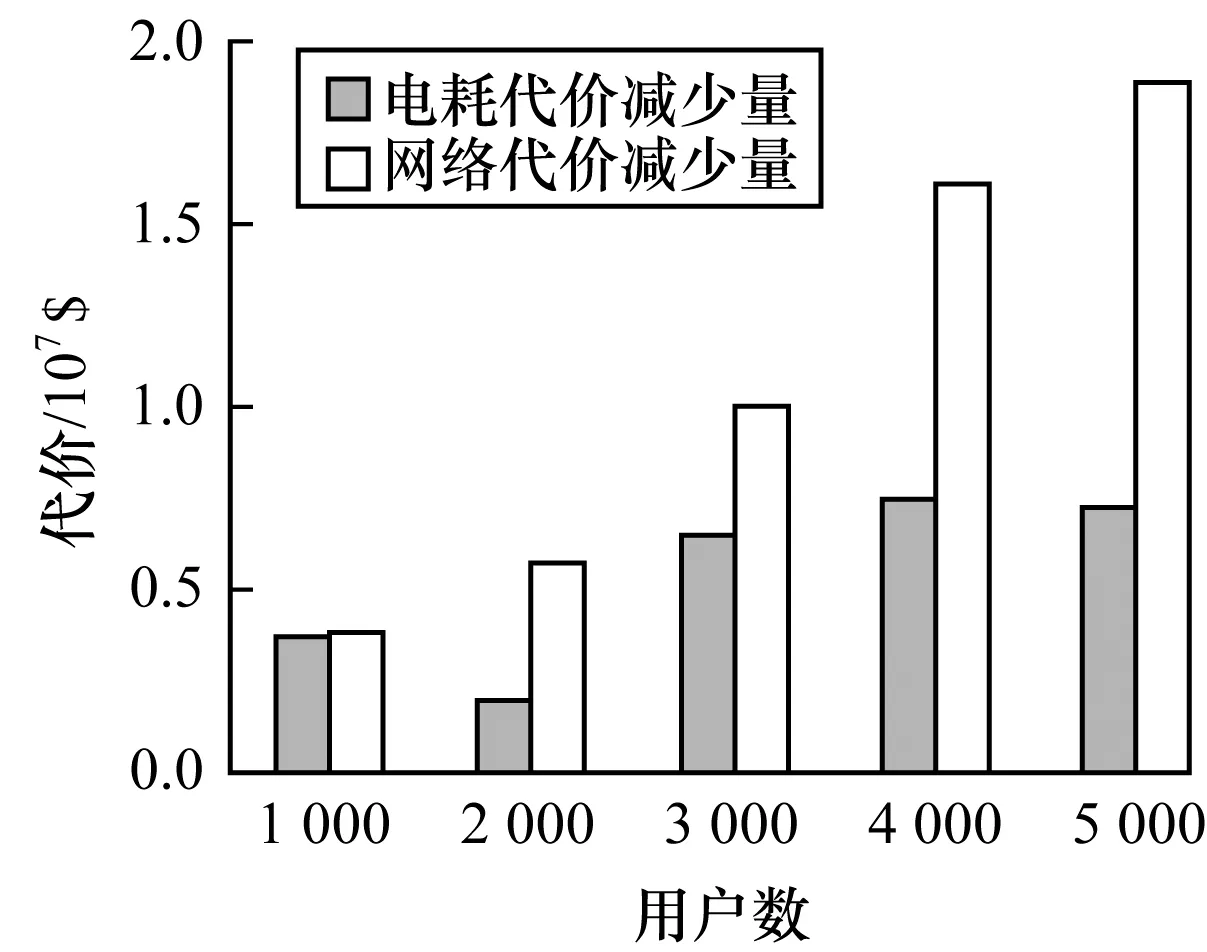
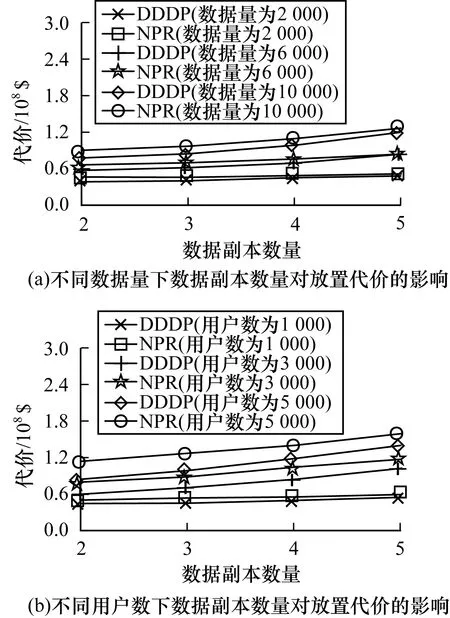
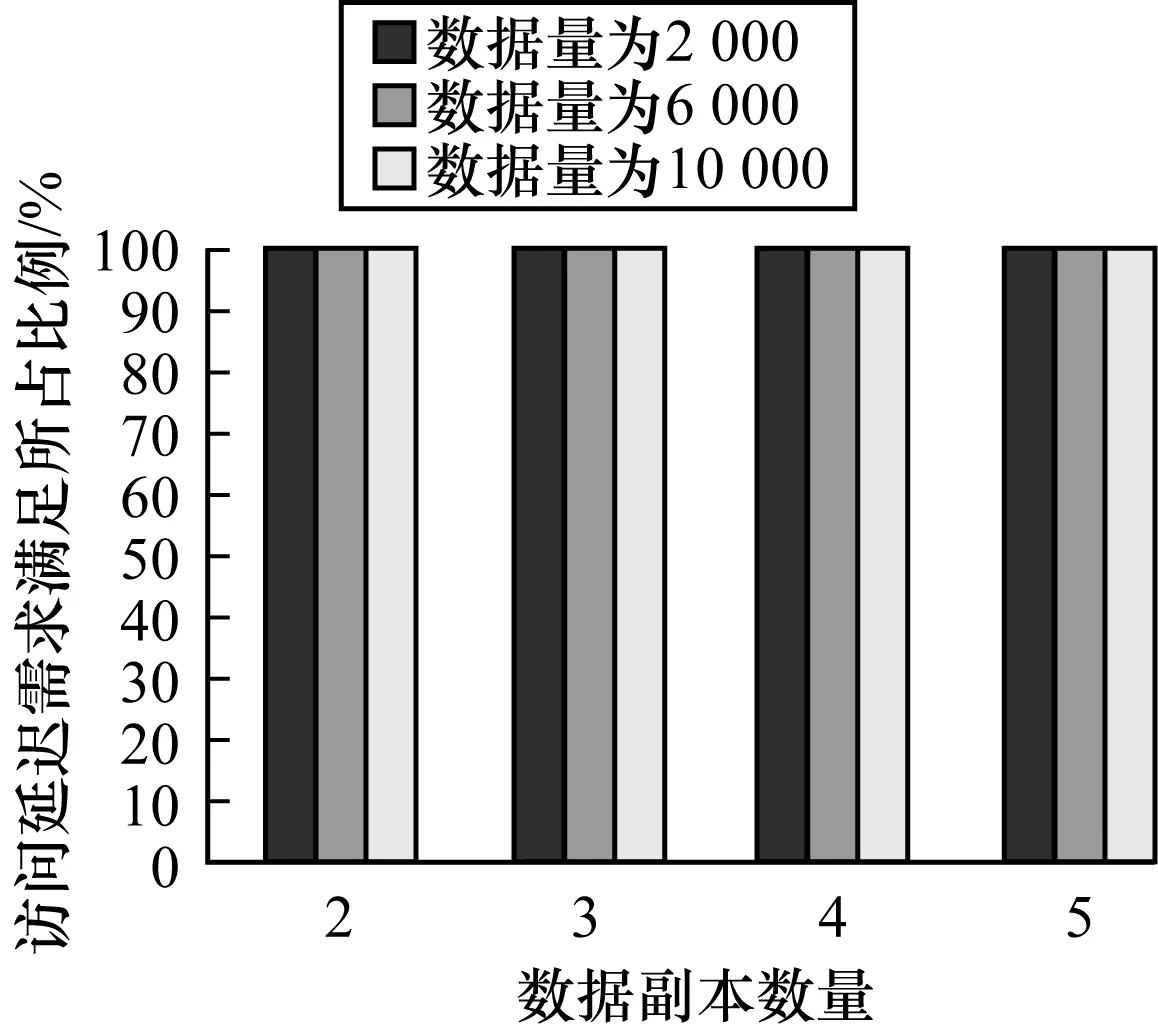
用户通常将请求发送到附近的数据中心,以获得较低的访问延迟。每个用户对不同数据可能具有不同的SLA需求,对于相同的数据,不同用户也具有不同的SLA需求。假设Lq表示用户对数据的访问延迟需求等级,其中,L1 (5) 其中,di,j为用户i到数据中心j之间的端到端延迟。 在SLA延迟需求和数据中心存储容量约束下,将每个数据的K个副本放置在不同的数据中心中,以最小化由数据中心服务器电耗和数据中心之间网络通信代价构成的数据放置代价。对于时隙t,假设K≤N,数据放置问题可以表示为如下模型: MinΨe(t)+Ψw(t) (6) s.t. (7) (8) xi,m,j≤ym,j,∀i,m,j (9) (10) (11) xi,m,j,ym,j∈{0,1},∀i,m,j (12) 式(7)表示存储在数据中心中的数据总大小不能超过数据中心的存储容量。式(8)确保用户与数据中心之间的访问延迟不能超过SLA需求。式(9)表明用户访问数据的数据中心时必须存储该数据的一个副本。式(10)要求每个数据放置在不同的K个数据中心。式(11)确保每个用户对每个数据的访问请求分配给唯一的一个数据中心。式(12)表示用户、数据和数据中心之间的映射关系由二进制变量表示。 针对大规模数据的放置问题,本文提出一种基于数据分组和数据中心子集划分的数据放置算法DDDP,该算法同时考虑用户访问延迟、数据中心服务器电耗和网络传输代价等因素。DDDP算法由3个阶段组成: 1)根据数据读写率将数据集D划分为多个数据分组,将具有相似读写率的数据放入同一组中。 2)读写率高的数据会导致高放置代价,因此,将多个数据分组按读写率的非升序进行排序,优先放置读写率高的数据分组中的数据。 3)根据用户访问某数据的延迟要求将数据划分成由K个数据中心组成的数据中心子集,以满足访问该数据的所有用户的SLA延迟需求。 DDDP算法以迭代的方式进行运行,在每次迭代中,放置某数据组中的一个数据到一个数据中心子集中,数据的放置应能最小化数据放置代价,上述迭代过程一直持续到所有数据被放置结束。 本文根据数据读写率的相似度来进行数据分组。读请求会产生数据中心的电耗代价,而写请求不仅产生电耗代价,还产生用于数据副本同步的网络通信代价。具有相似读写率的数据会产生相似的放置代价,从而使数据放置结果相同。因此,本文将数据集划分为多个数据分组,使得每组数据的访问率相似。在确定数据分组时,可以通过比较待分组的数据的读写率与数据分组中的平均读写率是否相似,以判断待分组数据是否放入到该数据分组中。 假设数据A、B的读写率分别为dA=(r1,w1)、dB=(r2、w2),计算2个数据项的曼哈顿距离DdistM(A,B)来定义数据A和B之间的相似性,即DdistM(A,B)=|r1-r2|+|w1-w2|。曼哈顿距离越小,数据之间的相似性就越高。值得注意的是,如果读和写的请求量相同,写请求对放置代价的影响要大于读请求。因此,为读请求和写请求分别分配权重α和β,其中,0<α<β。用加权曼哈顿距离来表示数据之间的相似性,即数据m和组g的相似度L(m,g)为: (13) 假设相似性阈值Δ>0,从数据集D中随机选取一个数据作为初始数据组g,对于每一个剩余数据m,计算该数据与数据组g之间的相似度L(m,g),并从所有数据组中找出使L(m,g)最小的一个数据分组,记为g*。如果L(m,g)<Δ,则将数据m添加到组g*中;否则,数据m不属于任何已有数据分组,而是单独生成一个数据分组。 每个数据都需要放置到K个数据中心,这K个数据中心构成一个数据中心子集。对于一个数据中心子集,如果数据m放置在该子集的数据中心中导致部分用户的访问延迟需求SLA不能被满足,则数据m不能放置在该数据中心子集中,即该数据中心子集不能作为数据m放置的候选位置。反之,如果数据m放置在该子集的数据中心中时,所有访问数据m的用户访问延迟需求都能被满足,则该数据中心子集中的数据中心是数据m的一个候选位置。 (14) 利用贪婪策略选择一个θj值最大的数据中心j,然后从U中移除其服务的用户,并在选定数据中心j的基础上,考虑网络传输代价,计算余下数据中心的权重,随后选择下一个数据中心直至找到K个数据中心。用图1示例表示上述过程,其中,黑点表示用户,圆角框表示5个数据中心的用户集合U′j。假设用户数为14,每个数据中心的权重分别为1、2、2、2、1。对于所有的数据中心,用向量V表示每一个数据中心的用户集合在每个阶段包含的单位权重未被服务的用户数θj,如果数据中心子集大小为3,则最佳解为数据中心1、2、5,总代价为4。数据中心子集划分过程如下:选择数据中心1,原因是数据中心1的θ在V={7/1,7/2,8/2,4/2,2/1}时最大;选择数据中心2,原因是数据中心2的θ在V={·,7/2,4/2,2/2,1/1}时最大;最后,选择数据中心5,原因是数据中心1、2可以服务所有用户,在选择第3个数据中心时,只需要在V={·,·,0/2,0/2,0/1}中选择θ分母最小的数据中心。 图1 数据中心子集划分过程 DDDP算法的伪代码描述如算法1所示。 算法1多副本数据放置算法DDDP 输入数据集D,数据中心集合DC,用户集U 输出数据放置方案ym,j 1.将数据集D划分为数据分组; 2.根据数据组的平均读写率进行数据组排序; 3.对每一个数据分组g 4.将数据组中的数据按s(m)大小进行非降序排列; 5.对每一个数据m∈g 7.更新子集中每个数据中心的存储容量; 8.ym,j=TRUE; 9.返回ym,j; 为了在延迟和容量约束下将不同数据组的数据放置到数据中心,本文提出了一种数据组排序方法,该方法综合考虑读写请求对放置代价的影响。每个数据组g有一个排序值Ω(g),由如下公式确定: (15) DDDP算法将数据组按Ω(g)值进行非升序排序,原因是写率高的数据产生的放置代价大,因此将高Ω(g)的数据组中的数据优先放置。在放置数据组g中的数据到数据中心时,考虑最小化数据中心的单位存储容量放置代价,则对于数据组g中的数据m,按照数据大小s(m)的非降顺序依次放置到能够最小化放置代价的数据中心子集,并同时满足所有访问数据m的用户的延迟需求以及数据中心的存储容量约束。 在本文实验中,分布式云由10个位于不同地理位置的数据中心组成,通过网络链路E相互连接[6],这些数据中心分布在8个地区[10]:美国东部(弗吉尼亚州),美国东部(俄亥俄州)(2个数据中心),美国西部(北加州),美国西部(俄勒冈州)(2个数据中心),加州中部,欧洲西(爱尔兰),亚洲东南(新加坡),亚洲东北(东京)。使用GT-ITM工具[15]生成30个具有不同拓扑结构的云,其中,任意2个数据中心之间有一条概率为0.4的边。假设对于每个数据中心,传输1 GB数据的代价是[$0.05,$0.12]范围内的随机值[6]。每个时隙t的持续时间为10 min[16],延迟需求分为5个级别(q=5),分别为15 ms~19 ms[17]。用户和数据中心的端到端网络延迟由它们之间的地理距离表示[17]。根据文献[6,18],所有用户对所有数据总的读/写率的比例约为0.92/0.08。每个用户的读写率在[10,20]范围内,每次数据写更新产生256 MB的数据量[6]。采用层次分析法(AHP)确定权重α、β,以衡量读写请求对放置代价的重要度。根据文献[19],最终得到α=0.17,β=0.83。 表1列出每个数据中心的重要参数[4-5]。数据中心的能耗使用效率(PUE)在[1.3,1.7]范围内随机生成,服务器的最大服务率表示每秒处理的平均请求数,其范围为[20.0,32.5]。式(3)中参数ρ设置为2,参数a、b分别在[0.18,0.30]、[100,125]中取值。数据中心1 MWh的平均电费p在$10~$30之间,数据中心的存储容量范围为[50 TB,200 TB]。表2所示为不同大小的数据所占的比例。 表1 数据中心的重要参数 表2 不同大小的数据所占的比例 式(6)中的目标函数为非线性,式(7)~式(12)中的约束为线性,xi,m,j、ym,j是二值变量,因此,数据放置问题是典型的0-1非线性规划问题。为评估DDDP算法的性能,本文采用了一个广泛应用的基准算法,将整数变量松弛到连续约束[9,20],在仿真中称为NPR,该基准算法由3个阶段组成:1)通过将变量值xi,m,j、ym,j松弛到[0,1]范围内,将0-1规划问题转化为连续优化模型;2)求解连续优化模型,然后迭代修正最接近1的变量固定为1,用固定变量代入原方程,重复模型求解和变量固定过程,直到解中的所有变量固定为0或1;3)连续优化模型产生的数据副本数可能不是K,则添加或删除数据副本以保证其数目为K。 本节从数据放置总代价、电耗代价和网络传输代价(分别表示为性能1、性能2和性能3)3个方面对算法进行评估和研究。 4.2.1 数据量对代价的影响 假设用户数为1 000,通过改变数据量来对DDDP和NPR算法的性能进行评估。从图2可以看出,数据放置总代价、电耗代价和网络传输代价均随着数据量的增加而增加,原因是随着数据量的增大,需要更多的服务器来容纳数据访问请求以及更多的网络传输来进行数据同步。在3个性能指标上,DDDP算法的数据放置代价(性能1)优于NPR算法9.8%~14.9%,DDDP算法的电耗代价(性能2)、网络传输代价(性能3)分别约为NPR算法的8%~23%、7.5%~29%。DDDP算法的代价均优于NPR算法,前者将数据划分为多个数据组,并对所有数据组进行排序,读写率高的数据优先级高,首先放置较高优先级的数据组的数据,并依次为数据选择最小化放置代价的数据中心子集,这些数据中心电耗低,并且数据中心之间通过最短路径传输更新数据,降低了数据传输的网络代价和放置代价。NPR算法松弛了整数变量约束,并通过变量固定最小化代价,然而,松弛连续优化问题的最优解通常差于整数规划问题的最优解,而且变量固定过程会导致数据副本数目不为K,因此,为了满足数据副本数量约束,其需要增加或删除数据中心,这将导致代价增加。 图2 数据量对放置代价的影响 4.2.2 用户数对代价的影响 假设数据量设置为3 000,研究用户数对不同算法性能的影响。从图3可以看出,当用户数从1 000增加到5 000时,算法的数据放置总代价、电耗代价和网络传输代价都增加,原因是来自用户的大量请求需要更多的服务器以及会产生更多的数据同步传输,从而增加了电耗和网络通信代价。DDDP算法的性能1、性能2和性能3均优于NPR算法。与NPR算法相比,DDDP算法将数据按数据组的非升序排列,访问率较高的数据优先放置。此外,随着用户数的增加,与NPR算法相比,DDDP算法的网络通信代价(性能3)减少程度要大于电耗代价(性能2),网络通信代价和电耗代价的减少程度分别如图4所示。数据的访问率随着用户数的增加而增加,高访问率的数据的访问率会更高,因此,用户数对数据分组排序的影响较小。DDDP算法中计算用户读写请求对放置代价的影响权重,当写请求的数量随着用户数的增加而增加时,由于写请求的权重大于读请求,写率高的数据将放置到较近的数据中心,使路由路径变短,但数据中心的电耗可能变高。 图3 用户数对放置代价的影响 图4 不同用户数下DDDP算法的电耗和网络代价减少量 4.2.3 数据副本数量对代价的影响 本节研究数据副本数量K对算法放置代价的影响。图5所示为在不同数据量和用户数条件下,当K从2增长到5时数据副本数量K对算法性能的影响结果。其中,数据量分别为2 000、6 000和10 000,用户数分别为1 000、3 000和5 000。 图5 数据副本数量对放置代价的影响 从图5可以看出,随着数据副本数量的增加,DDDP算法和NPR算法的数据放置代价都会增加,原因是数据副本的增加相当于数据量的增加,因此,需要更多的服务器来容纳数据副本以及更多的网络传输来保持数据副本更新的一致性。相比NPR算法,DDDP算法的放置代价较小,当K=3时,DDDP算法的放置代价比NPR算法分别降低约29%和26%。然而,随着数据副本数量的增加,DDDP算法数的性能没有K=3情况下的性能好。原因是,当K较小时,排序值高的数据分组中的数据副本首先被放置,可以被具有较低电费且网络传输路径较短的数据中心所容纳,当K很大时,由于数据中心存储容量约束,随着数据副本数量的增加,高访问率的数据将被放置到放置代价小的数据中心子集,其他数据可能被放置到具有较低电价但距离较远的数据中心。 4.2.4 数据副本放置对用户访问性能的影响 图6、图7分别说明在不同数据量和用户数条件下,当K从2增长到5时数据副本数量K对用户访问性能的影响。从图6可以看出,在用户数为1 000,数据量分别为2 000、6 000和10 000情况下,访问延迟需求满足的百分比基本持平,稳定在100%,即DDDP算法产生的数据放置策略可以满足100%的用户访问数据延迟需求。DDDP算法在为每个数据采用贪心策略选择数据中心时,以满足延迟需求为限制条件,使得选择的数据中心的放置代价最小化,同时满足所有用户的延迟需求,从而保证了用户访问性能。此外,在用户数不变的情况下,随着数据副本的增加,数据会被放置到离用户较近的数据中心,从而减小了用户访问延迟并满足用户的延迟需求。从图7可以看出,在数据量为3 000,用户数分别为1 000、3 000和5 000情况下,随着数据副本数量和用户数的增加,访问延迟需求满足的百分比保持在100%。随着数据副本的增加,数据会被放置到离用户较近的数据中心,用户通常访问最近的数据中心,从而满足了其延迟需求。同时,数据放置到多个数据中心,扩大了用户的服务范围,即使用户数量增加,数据中心也可以在很大程度上满足其延迟需求。 图6 不同数据量下数据副本数量对用户访问性能的影响 图7 不同用户数下数据副本数量对用户访问性能的影响 大规模的数据密集型应用程序通过将服务请求指派到位于不同地理位置的数据中心,以为终端用户提供服务。在数据中心存储应用所需的海量数据时,常为每个数据维护多个副本,从而产生高额的电费和数据中心之间的网络传输费用。本文假设每个数据都有K个副本,以最小化多副本数据放置代价为目标,建立数据放置问题模型,并提出一种基于数据组和数据中心划分的DDDP算法。仿真结果表明,相对NPR算法,DDDP算法能有效降低数据放置代价。在实际应用中,用户访问数据的读写率是动态变化的,即数据放置的最佳位置会发生变化。因此,下一步将考虑每个时间段的读写率变化对数据放置的影响,根据需要来动态调整部分数据的放置位置,以降低数据访问引起的能耗和网络传输代价。2.4 数据放置模型
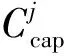
3 基于分组与中心子集划分的数据放置算法
3.1 数据组划分

3.2 数据中心子集划分
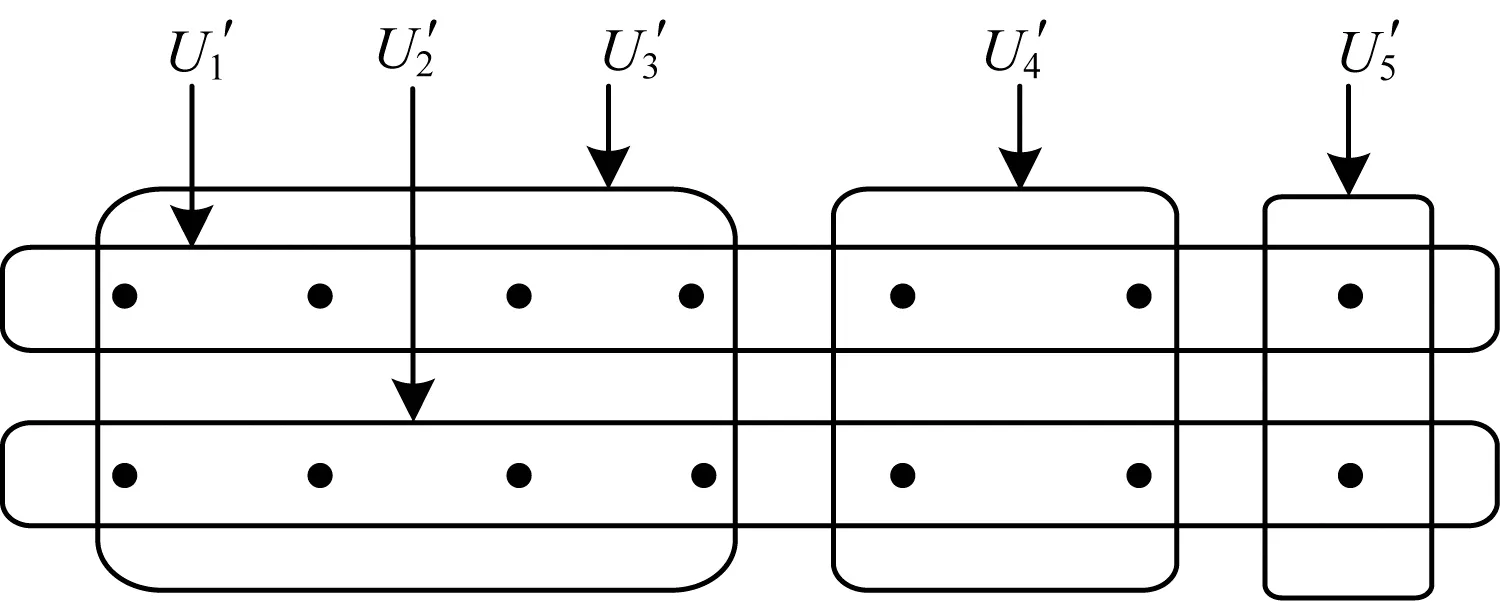
3.3 数据放置算法DDDP

3.4 算法时间复杂度分析
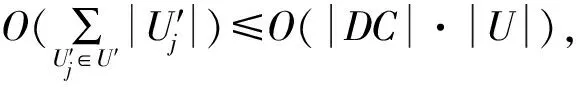
4 性能评估
4.1 模拟配置


4.2 性能评估结果



5 结束语
