改进的Simhash算法在文本查重中的研究及应用
2020-02-19庞宇,张倩,韩凯,肖彬
庞 宇,张 倩,韩 凯,肖 彬
(北方工业大学信息学院,北京 100144)
随着数据爆发时代的到来,复杂度高、冗余度高的数字化信息逐渐在各行各业带来了问题。例如网页上大量的相似性文档使用户无法精确获取想查询的信息,所需的巨大存储空间也会影响文件处理效率并导致成本急剧增加。
在文本相似度计算方面,Simhash算法是目前比较准确且高效的方法之一。其主要思想是降维,将高维的特征向量映射为一个F位的指纹,通过比较两篇文本指纹的汉明距离来确定其相似度。文中就Simhash算法进行研究和改进,以期在保证Simhash算法本身高效性的前提下,优化其效率和准确率,并设计系统实现文本查重。
1 传统Simhash算法分析
Simhash算法中,定义一个N维空间,在其中定义每个特征向量,然后结合向量本身的权值进行加权、求和等过程,得出一个和向量作为结果,最后对其进行降维处理,形成最终的F位二进制签名。其具体步骤如下:
(1)分词及预处理:将文本分词且去掉停用词,形成单词序列,并为每个词加上权值(weight)。
(2)生成hash值:通过hash算法把每个词变成hash值,此为降维过程。
(3)加权:根据hash值,按照单词的权值形成加权数字串,1为weight,0为-weight。
(4)合并:将各单词计算出的序列值累加,形成一个序列串。
(5)降维:将上述序列串转换为01串,大于0记为1,小于0记为0。
算法流程如图1所示。

图1 Simhash指纹生成
在信息论中,汉明距离指的是,在一个码组集合内,两个码字对应位码元取值不同的位数。即d(x,y)=∑x[i]⊕y[i]。在本例中,两个文本的Simhash指纹a,b,其汉明距离通过a XOR b运算得出。
传统Simhash算法通常将特征词出现的次数设为其权值,这就易于造成信息丢失,降低最终指纹的准确性。同时,它不表现出词汇分布信息,关键特征词顺序变化后,指纹不受影响。
2 改进的Simhash算法
为解决上述问题,本文使用TF-IDF算法计算权值。TF-IDF是一种统计学算法,其主要思想是:特征词的权重与其在文件中出现的次数成正比,与其在语料库中出现的频率成反比。
特征词tj在文本dk中的TF-IDF值记为tfidf(tj,dk),用tf(tj,dk)表示tj在文本dk中出现的频率,记为

式中,分子表示特征词tj在文本dk中出现的次数;分母表示文档dk中所有特征词的个数。
用idf(tj,dk)表示逆向文件频率,记为
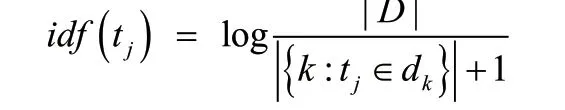
式中,分子表示文本库中总文档数;分母表示其中包含特征词tj的所有文档。
特 征 词 的 权 值tfidf(tj,dk) = tf(tj,dk) * idf(tj)。因 此,TF-IDF算法可以有效过滤常见词,保留重要词。
3 系统设计与实现
本实验采用Django搭建web项目实现文本查重系统。系统划分为3个功能模块:文件格式转换、文本相似比对、检测结果查看。工作流描述如下:
(1)用户上传本地txt、word或pdf等文件格式的文本。
(2)服务器接收文件后统一转换格式为txt。
(3)服务器将形成的txt文件输入到模型中进行查重。
(4)模型输出分析结果返回给服务器。
(5)通过用户设定的阈值显示检测报告。
在文件格式转换模块,需要将pdf、word格式的文本转换为txt格式,利于文本查重时对文件的打开、读取等操作。
文本比对模块是本系统的核心功能。目标文档输入后端已经建立好的模型后,以自然段落为执行单位,经过预处理形成词组,根据TF-IDF算法计算各词的权值,再依次经过Simhash算法中生成hash值、加权、合并、降维等过程,最终形成目标文档的Simhash指纹。经过与已经形成的库文档各指纹的对比,查找到与目标文档汉明距离最小的某库文档中的某段落,将其文本内容添加到结果数组中,最后由服务器返回至浏览器,用户此时可以查看生成的检测报告。
