虹膜分割算法评价基准
2020-02-19王财勇孙哲南
王财勇 孙哲南
(中国科学院大学人工智能学院 北京 100049) (模式识别国家重点实验室(中国科学院自动化研究所) 北京 100190)
生物特征识别是指依赖人体固有的、独一无二的生理特性或者行为特征通过计算机进行身份认证的一种技术,具有方便性、普适性、安全性、唯一性,被认为是未来身份认证的趋势[1].典型的生物识别技术包括:指纹识别、人脸识别、虹膜识别、掌纹识别、步态识别等.
在众多的生物形态中,虹膜被认为是最稳定和最可靠的,并且由于虹膜是眼睛中一个外部可见的内部器官,因此虹膜识别系统对用户来说是非接触式的,这些使得虹膜识别成为一种最有前途的身份识别方法[2].图1(a)展示了眼睛中的虹膜和其他眼周结构.
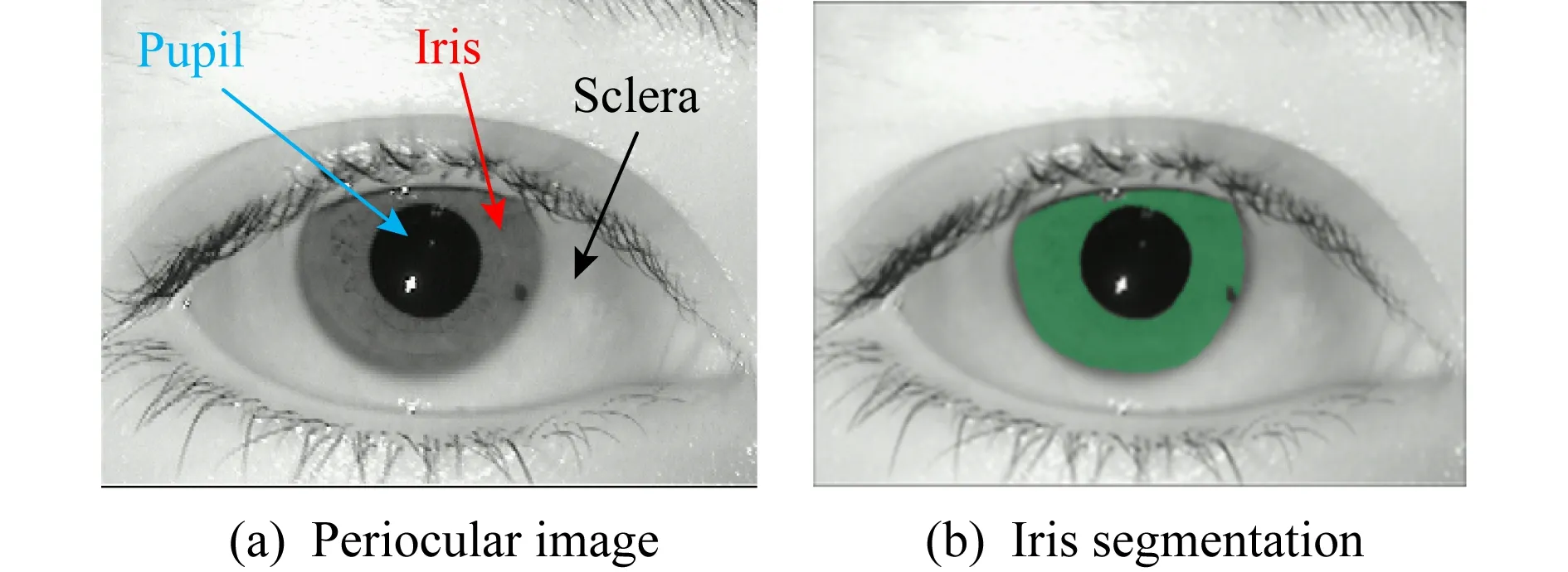
Fig. 1 Periocular image and iris segmentation图1 眼周结构与虹膜分割
通常一个完整的虹膜识别流程包含虹膜图像获取、虹膜预处理、虹膜特征提取、虹膜比对.其中虹膜分割处在预处理阶段,虹膜分割结果的好坏将直接影响虹膜识别的精度.虹膜分割可以由广义和狭义之分,狭义的虹膜分割是指提取有效的未被噪声干扰的虹膜纹理区域,提取的结果是一个二值掩模,其中1表示有效的虹膜像素,0表示其他区域,因此狭义的虹膜分割也可以看成是二类的语义分割在虹膜图像的应用[3];广义的虹膜分割除了包含狭义的分割之外,还包含了虹膜的内外边界定位,用于进行虹膜的归一化操作.本文主要讨论狭义的虹膜分割,对于虹膜定位,我们将在结尾处进行讨论.图1(b)展示了狭义的虹膜分割的结果.
由于虹膜是处在人眼的黑色瞳孔与白色巩膜之间的圆环状区域,很容易受到睫毛、阴影、光斑、镜框的干扰.传统的虹膜分割技术往往带有很强的假设,需要经历复杂的预处理操作或者人工设计特征,这些方法在虹膜图像质量较好(如在近红外光照条件下拍摄的高清图片)的情况下具有较好的性能,但是对于成像质量较差的图像则性能下降.这些反映了传统方法具有较弱的鲁棒性.
近年来,深度学习技术发展突飞猛进,极大地提高了生物特征识别的精度.深度学习技术是一种机器学习技术,源于人工神经网络的研究.不同于传统的基于边缘检测、模板匹配等手工设计特征的方法,深度学习技术基于大量的数据样本,可以自动地从数据中提取特征,已经广泛应用在语义分割、目标检测等领域.由于虹膜分割可以看成是二分类的语义分割,因此基于深度学习的语义分割框架可以直接应用到虹膜分割上.例如,文献[3]第1次提出使用全卷积网络来进行虹膜分割,最终结果显示其精度全面超过了传统的方法.
当前提出的各类虹膜分割算法在不同的数据集上使用不同的评价指标进行了评估,证明了其有效性,然而由于没有建立一个统一的基准对各类算法进行全面、公平的比较,妨碍了各类算法的大规模应用.另外,我们也需要对各类算法的一般规律进行总结,以便更好地提升算法的性能.基于以上目的,我们提出了一个公开的虹膜分割评价基准,在充分考虑算法的泛化能力和应用场景的前提下,选取了3个有代表性的含有人工标注的公开数据集,并建立了一个统一的评价指标.然后我们选取了若干有代表性的虹膜分割算法,包含传统的虹膜分割算法和基于深度学习的虹膜分割算法,在选取的3个数据集上进行了实验,实验揭示了基于深度学习的虹膜分割算法的巨大优越性.最后我们也思考了基于深度学习的虹膜分割算法存在的问题,为后续的研究工作指明了方向.
1 虹膜数据库
虹膜图像是虹膜分割研究的数据基础,尤其是基于深度学习的虹膜分割算法,需要大量的标注数据进行监督学习.这里的标注是指人工标好的虹膜二值掩膜.另一方面,我们需要对分割后的结果进行评价,最直观有效的评价方式就是与分割标注进行比对,因此带有分割标注的虹膜图像数据库对于发展虹膜分割算法具有重要的意义.
本文将介绍3个重要的虹膜数据库.这3个数据库分别涵盖了近红外近距离、可见光远距离、可见光移动端3种不同的拍摄情形,可以用来评估虹膜分割算法在不同环境下的鲁棒性,且这些数据库都带有像素级标注,可公开获取.
1.1 中国科学院自动化研究所虹膜数据库
中国科学院自动化所虹膜数据库(CASIA iris image database, CASIA-Iris)[4]是由中国科学院自动化所免费提供给国外内研究者使用的大型虹膜数据库.自2002年发布CASIA-IrisV1后,截至2018年6月共有4个版本,并且新增了移动端的虹膜图像数据库.CASIA 虹膜数据库包含了从近距离到远距离拍摄、从高质量图像到低质量图像、从近红外光到可见光等各种情形.目前最新的CASIA-IrisV4共有6个子数据库,分别是CASIA-Iris-Interval,CASIA-Iris-Lamp,CASIA-Iris-Twins,CASIA-Iris-Distance,CASIA-Iris-Thousand,CASIA-Iris-Syn.
1) CASIA-Iris-Interval数据库特点是虹膜图像质量高,虹膜的细节特征清晰可见,近距离、近红外光下拍摄.
2) CASIA-Iris-Lamp数据库有意引入了环境光照变化,获取了具有非线性形变的虹膜图像数据,且该数据库虹膜大部分来自东方人,因此上下眼皮与睫毛的遮挡比较严重,很适合检测虹膜分割算法对于形变的鲁棒性,在可见光下拍摄.
3) CASIA-Iris-Twins是第1个公开的双胞胎虹膜库.
4) CASIA-Iris-Distance数据库特点是远距离拍摄,且拍摄对象移动.
5) CASIA-Iris-Thousand数据库是第1个包含超过1 000个对象的虹膜数据库.
6) CASIA-Iris-Syn数据库是第1个合成的数据库,可以用于虹膜活性检测.
由于CASIA虹膜数据库只提供了虹膜图像,而没有提供分割标注.为此,文献[3]从CASIA-Iris-Distance中选取子集并使用Photoshop和GrowCut[5]软件手动进行了标注.该子集共有400张虹膜图像,分辨率是640×480,均为黑白图片.根据文献[3],我们可选取来自前30个对象的300张图像进行训练,后面10个对象的100张图像被用来测试.图2(a)展示了CASIA-Iris-Distance中的一些样例图片.
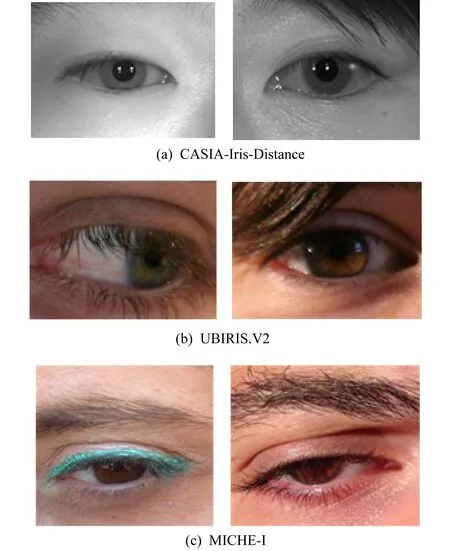
Fig. 2 Examples of images from three databases图2 三大数据集上的样例图片
1.2 葡萄牙贝拉地区大学噪声可见光虹膜数据库
葡萄牙贝拉地区大学噪声可见光虹膜数据库(University of Beira Interior noisy visible wave-length iris image databases, UBIRIS)[6]是由葡萄牙University of Beira Interior的SOCIA Lab(Soft Computing and Image Analysis Group)收集,于2004年公开发布,主要是为了促进较少约束条件下的带噪声的虹膜图像识别.UBIRIS数据集分为2个部分:UBIRIS.V1与UBIRIS.V2.其中UBIRIS.V1的特点是:引入了多种噪声,如运动模糊、镜面反射、眼皮遮挡、闭眼等,是在近距离可见光下拍摄.相比UBIRIS.V1,UBIRIS.V2使用了远距离拍摄,且允许拍摄对象缓慢移动,因而UBIRIS.V2引入了更多的噪声,如离焦模糊、隐形眼镜遮挡、头发遮挡等.
为了促进虹膜识别的发展,葡萄牙University of Beira Interior发布了噪声虹膜挑战评估赛(Noisy Iris Challenge Evaluation, NICE[7-8]).NICE共举办了2次,其中NICE.I[7]主要侧重于虹膜分割,NICE.II[8]主要侧重于虹膜特征提取和比对.NICE.I比赛使用的数据集来自UBIRIS.V2,训练集和测试集各有500张图片,分辨率是400×300,均为彩色图片.这里需要说明的是,我们从NICE.I组织者下载的测试图像中缺失了55张,因此共有445张,但总的来说不影响虹膜分割算法的性能评估.图2(b)展示了NICE.I比赛中使用的部分样图.
1.3 移动端虹膜挑战评估数据库
移动端虹膜挑战评估(mobile iris challenge evaluation, MICHE)[9]数据库是为移动端虹膜挑战赛[10]而收集.该比赛同NICE比赛一样,也分成了2部分:第1部分,即MICHE-I,主要任务是移动端虹膜图像分割;第2部分,即MICHE-II,主要任务是移动端虹膜图像识别.目前公开可得的MICHE数据集是MICHE-I,该数据集主要用于MICHE-I以及MICHE-II的训练环节.
MICHE-I虹膜数据库是由3部移动装置iPhone5(IP5),Galaxy Samsung IV(GS4),Galaxy Tablet II(GT2)拍摄,分别包含1 262,1 297,632张图片,此外还包含40张合成图像,113个使用移动设备拍摄的虹膜视频.MICHE-I数据库主要特点是使用移动设备获取,包含了更多的现实噪声,且大多数图像都是在无约束条件下获得,因此更接近现实情况,有利于移动端虹膜识别的研究.由于该数据库仅仅提供了虹膜图像,没有提供分割标注,幸运的是Hu等人[11]从IP5和GS4中随机选取了一部分图片,并进行了眼睛区域的提取,生成了一个包含569张图片的子集,然后进行了手动虹膜分割,其中140张图片用来进行训练,余下的429张图片进行测试.为了加速虹膜分割进程,所有图像的宽度缩放到400,高度缩放到与原始图像保持相同的比例,最终的图像尺寸大致在400×400,均是彩色图片.图2(c)展示了MICHE-I的部分样例图片.
注意:为了方便起见,后文统一将CASIA-Iris-Distance简称为CASIA,UBIRIS.V2简称为UBIRIS,MICHE-I简称为MICHE.
2 评价指标
合适的虹膜分割性能评价方法对于发展高效鲁棒的虹膜分割算法至关重要.一般来说,评价虹膜分割算法有2种主要的方法:第1种就是直接评价虹膜分割的效果,通过将标记过的虹膜掩模与预测得到的虹膜掩模按照某种指标进行比较;第2种就是间接进行比较.由于虹膜分割的主要目的是为了进行虹膜识别,因此我们可以通过比较虹膜识别的性能来间接得到虹膜分割算法的性能指标,但是由于这种比较方法涉及到了一些额外的中间操作过程,如归一化处理等,所以这里不作为主要的评价指标进行测试.另外我们还需要考虑虹膜分割的时间以及占用的运行内存,所以一个全面的虹膜分割评价指标应该覆盖这些方面.下面我们介绍虹膜分割评价指标.
指标1.来自NICE.I比赛[7],包含2个评价指标E1和E2[12].假定Ii表示输入图像,O(c′,r′)表示预测得到的虹膜掩模,C(c′,r′)表示标记过的虹膜掩模.3个图像必须大小相等,并且为了计算简单,O(c′,r′)和C(c′,r′)都取为二值图像.因此第i幅图像的分割错误率ei可以被计算为预测虹膜掩模与标记虹膜掩模之间不一致的像素占全体像素的比例,即
(1)
其中c′和r′是预测虹膜掩模与对应的标记虹膜掩模的坐标,r和c相应地表示为图像的行数和列数,⊗为逻辑异或操作.整体的识别率E1可以看成是所有测试图像错误率的平均.
(2)
E2是为了弥补图像中虹膜像素与非虹膜像素占比不均等的缺点.它平衡了假阳性率fp和假阴性率fn,如图3所示,计算如下:

(3)
同理,E2为所有测试图像错误率的平均.
(4)
这2个测度的值位于[0,1]之间,其中1和0分别表示最差和最好的情况.
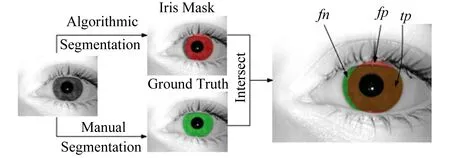
Fig. 3 Example of calculation of fn,fp,tp for iris segmentation[13]图3 计算虹膜分割指标fn,fp,tp的示例[13]
指标2[13].文献[13]提出了一种新的评价指标,即利用来自信息检索领域公认的标准:准确率P、召回率R和f1-测度F1,其中用到了真阳性率tp、假阳性率fp和假阴性率fn,如图3所示,准确率定义为
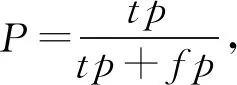
(5)
其度量了预测得到的虹膜像素为真实的虹膜像素的比例.
召回率定义为
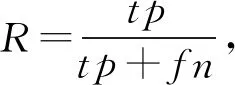
(6)
其度量了标记的虹膜掩模中,虹膜像素被正确识别的比例.另外为了平衡2个测度,我们定义F1为P和R的调和平均值,即:
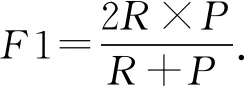
(7)
这3个测度的值位于[0,1]之间,0和1分别表示最差和最好的情况.另外这里计算的是每一幅图像的测度,为了评价整体的性能,我们需要计算各个测度的均值μ和方差σ.显然均值越高,方差越小,算法性能越好.
指标3.来自一般的语义分割领域,即计算mIOU,用来表达分割的准确率.其中IOU可以计算为预测掩膜与标记掩膜的交集与并集之比.延续指标2的标记,IOU可以表达为
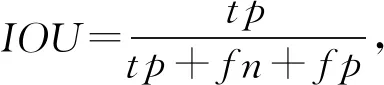
(8)
则mIOU为全体测试图像IOU的平均,即:
(9)
mIOU位于[0,1]之间,其中0和1分别表示最差和最好的情况.
指标4.比较平均的运行时间.由于传统方法一般运行在CPU上,而深度学习方法需要联合运行在CPU与GPU上,加之程序语言和算法优化的程度不同,也会导致运行时间有所差异,所以这里的运行时间仅作为一个参考.
指标5.比较模型的存储空间和参数数量.考虑到基于机器学习的方法会生成参数模型,因此我们可以比较模型的存储空间和参数数量,以此评估在各平台使用的可能性.一般地,模型占用存储空间越小,使用的参数数量越少,越有利于模型的实际应用,例如将算法部署在移动端.
指标6.跨库评估.为了考察算法的泛化性,通常可以将在某个数据库上训练学习得到的模型直接在另外的数据库上进行测试.对于泛化能力比较强的模型,由于其学习到了真正的图像特征,因此可以得到高性能的分割结果,可以更好地部署在实际的系统中.
指标7.极端图像的定性比较.由于上面大部分评价指标都是统计意义上的,因此很难评估算法对于极端难例的鲁棒性,因此我们可以选取各个数据库中具有代表意义的困难样本,进行算法的定性比较,以此得到一个较客观全面的评价.
以上7种指标全面考虑了虹膜分割算法的准确性、运行时间、模型大小以及鲁棒性、泛化性.我们将在后面的实验中使用这些指标比较不同的算法性能.
3 传统的虹膜分割算法
传统的虹膜分割算法大致可以分为2类:基于边界的方法和基于像素的方法.前者主要通过定位虹膜的内外边界、上下眼皮以及去除睫毛遮挡、镜面反射等来得到孤立的虹膜区域,最典型的工作要属Daugman[14]的积分微分算子和Wildes[15]的圆形霍夫变换.这2类方法都假定虹膜内外边界是圆形,且像素灰度值在虹膜边界上变化很大.其中积分微分算子通过计算沿圆心边界上的径向灰度变化之和,寻找最大值来确定虹膜内外圆参数.Wildes首先使用基于梯度的边缘检测算法(如canny边缘检测[16])检测虹膜边缘点,然后基于得到的边缘点进行Hough变换,从而得到虹膜内外圆参数.以上2类方法在比较理想的清晰虹膜图像上获得了较好的分割结果,然而对于远距离、可见光下获得的虹膜图像效果不佳,另外上下眼皮以及镜面反射等噪声未进行检测.
基于以上2类算法,陆续出现很多工作来改进分割的性能.He等人[17]提出了一系列鲁棒的操作实现了虹膜分割,包括基于Adaboost-cascade的检测器用于虹膜粗定位、基于推拉算法的内外圆定位以及三次样条插值的非圆虹膜边界拟合用于处理非圆的边界和一系列新颖的方法用于眼睑、睫毛、阴影检测.该方法在非理想的虹膜图像上获得了鲁棒而准确的分割结果,并且运行速度很快.Tan等人[18]提出了基于聚类的方法用于虹膜粗定位以及噪声区域检测,并且使用积分微分星座图方法改进了原始的积分微分算子,提升了其速度和准确性,该方法在NICE.I虹膜分割比赛获得了冠军.Sutra等人[19]使用了Viterbi算法用于虹膜分割.Viterbi算法被用在2个分辨率的虹膜梯度图像上:高分辨率图像用于定位精细的虹膜内外轮廓,从而获取分割掩膜;低分辨率图像用于定位粗糙的轮廓,从而获取内外圆.文献[20]提出了一种新颖的全变差模型,使用l1范数正则化鲁棒地压制噪声,生成了边界清晰的图像,并使用改进的圆形霍夫变换在生成的图像上进行内外圆定位,获得了准确的检测结果,除此以外,一系列新颖的后处理操作被用于准确地获得虹膜的二值掩模.文献[21]是一种无监督的分割方法,专门用来处理噪声图像,在移动端虹膜挑战赛MICHE-I中获得了最好的分割结果.该方法通过一系列预处理操作如反射矫正、使用修改的积分微分算子进行内外圆检测、归一化处理、上下眼皮定位等方法确定了虹膜的大致位置,然后将虹膜纹理建模成一个多光谱的空间概率模型,并使用自适应的阈值方法检测噪声像素,从而间接得到有效的虹膜区域.作者还在NICE.I数据集上进行了测试,以0.012 4的E1错误率名列第1名,超过了NICE.I比赛的冠军算法,充分证明了该算法的鲁棒性和准确性.除了将内外边界建模成圆形外,文献[22]提出了测地线主动轮廓算法用于获取虹膜的内外边界.文献[23]考虑使用测地线主动轮廓算法来估计虹膜的内外边界曲线,然后在得到的曲线上进行椭圆拟合获取虹膜内外边界,此外图割算法被用来获取分割掩膜.文献[24]使用了一种新的测地线主动轮廓算法将内外边界曲线建模成自由封闭曲线,而后使用非圆的归一化操作,并进行了识别实验,证明了该方法的有效性.
另一类基于像素的方法则直接根据像素点附近的外观特征,比如颜色、纹理、边缘方向等,来决定是否属于虹膜区域.例如文献[25]在像素点邻域提取位置和颜色特征后,使用神经网络来判别像素点是否是虹膜.文献[26]则提取像素点附近的Zernike矩作为特征,然后使用SVM进行分类.与前面2类不同,文献[27]则将分割分为4个阶段:第1阶段对图像进行对比度增强;第2阶段使用HOG描述子和SVM方法定位虹膜位置;第3阶段对定位后的虹膜区域使用GrowCut算法进行虹膜像素的提取;第4阶段使用后处理移除瞳孔、阴影和反射.这类方法通常需要手工设计特征,且特征提取和分类器训练是分开的,因此在应对复杂场景下的虹膜分割面临着很大的挑战.
总的来说,传统的虹膜分割算法包含了大量的预处理和手工操作,因此算法的准确性很容易受到这些中间处理的影响,进而也影响了算法的鲁棒性.因此在完善传统方法的基础上,我们需要发展新的虹膜分割思路.
4 基于深度学习的虹膜分割算法
近年来,得益于计算机计算能力的提高和大数据的应用,深度学习方法尤其是CNN在自然图像分类、识别、检测、分割以及三维重建等经典的计算机视觉问题大放异彩,广泛应用到生物特征识别、医学图像处理、遥感图像处理等各个领域.深度学习的巨大成功也促进了虹膜识别的飞速发展,很多基于深度学习的虹膜分割[3]和特征提取算法[28]等陆续提出.本节主要侧重于虹膜分割,总结了2类经典的基于CNN的虹膜分割算法:一类是基于像素块的滑窗图像分割框架;另一类就是当前流行的全卷积网络(fully convolutional network, FCN)[29].事实上,基于深度学习的虹膜分割算法一般可以看作2类的语义分割问题,因此基于深度学习的虹膜分割算法的发展是伴随着一般的语义分割算法的发展.
4.1 基于像素块的滑窗分割框架
CNN最早应用在图像分类、检测领域,后来有人尝试将CNN应用在语义分割上[30-32].主要的思路就是基于像素块的分类.具体是:将整个图像从上到下、从左到右依次扫描像素点,然后选取像素点附近一定大小的邻域块使用判别网络比如VGGNet[33]等进行判别,从而得到该像素的类别,最后所有的像素类别汇总在一起输出分割的结果.这类方法的优点就是成功地将分类网络的丰富成果应用到语义分割领域,最终产生的分割结果也超越了很多传统的语义分割方法.但缺点也很明显:一是各个像素块之间重叠区域被进行了重复的前向和后向运算;二是像素块大小的选取比较困难,因为较大的像素块可以捕获更多的全局信息,忽略细节,而小的像素块可以包含更多的细节,但是也带来了很多噪声.
尽管如此,基于像素块的滑窗分类框架仍然促进了语义分割领域新的发展.在虹膜分割领域,也有工作尝试着基于这种方法发展了新的虹膜分割方法.文献[3]提出了一种多尺度的分层卷积神经网络(HCNNs)用于虹膜分割,该网络选取了每个像素点附近3个不同尺度的邻域块,将其送进分类网络中,提取不同尺度的特征,在结尾使用全连接层进行多尺度特征的融合,并最终决定该像素是否属于虹膜.HCNNs部分解决了前面所提到的基于像素块的语义分割框架的第2个缺点,成功地将多尺度的特征进行了融合,然而各个像素块重叠区域依然进行了重复的计算,3个尺度的选取也并非是最优的,最终的结果表明该方法获得了较好的准确率,但仍然在一些噪声虹膜图像上效果较差.文献[34]考虑到整个虹膜图像包含了头发、眼睑、镜框、眉毛等类似于虹膜的区域,因此CNN模型很可能会将它们看成虹膜,因此作者提出了一种2阶段的处理方法:第1阶段使用各种图像处理方法定位大概的虹膜边界区域;第2阶段在粗定位的虹膜区域使用训练好的VGG模型进行逐像素的判别.结果显示,在UBIRIS.v2和MICHE-I数据集上都获得了较好的效果,部分解决了镜框等遮挡问题.然而该方法在第一阶段需要大量的预处理,占用了很多时间,因此在应用上依然存在不少的问题.
总的看来,因为需要大量的重复计算,且不能做到端到端的训练和测试,基于像素块的滑窗分割框架在语义分割中已不再占优势,另外一种基于全卷积的语义分割网络正在如火如荼地兴起.基于全卷积的分割网络接受整幅图像输入,最终也可以输出整个图像的分割结果,整个网络可以端到端地训练,且允许挖掘多尺度的上下文信息,计算上不再重复,因此较好地解决了基于像素块的滑窗分割框架的问题,并广泛应用于医学图像处理、遥感图像处理、虹膜分割等领域.
4.2 基于全卷积网络的分割框架
2015年Long等人[29]第1次提出使用全卷积网络(FCN)进行语义分割,随后涌现出各种各样的框架改进语义分割的效果,他们的共同点是整个网络都使用全卷积层,不包含全连接层,因此我们将这类网络统称为基于全卷积网络的分割框架(全卷积分割网络).
受文献[35]的启发,我们把基于全卷积网络的分割框架分为编码模块与解码模块,其中编码模块一般选取用于图像分类的特征提取网络,例如VGGNet[33],ResNet[36],MobileNet[37],ShuffleNet[38],解码模块用以细化提取的特征,并将提取的特征进行上采样,得到最终的分割结果.这里我们将解码模块归为4类:Feedforward,Skip,Decoder,Dilation,如图4所示:
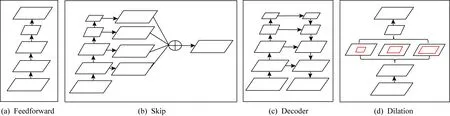
Fig. 4 Different decoder frameworks图4 不同的解码框架
Feedforward框架是最简单常用的一种分割框架,最早见于FCN32s[29].此类框架通常调整一般的分类网络,将编码层后面的全连接层改成1×1的卷积层,并使用转置卷积上采样特征图到原始的分辨率大小.该框架可以很方便地利用在ImageNet上预训练的特征,计算代价小,主要的缺点是得到的分割结果比较粗糙.
Skip框架来自FCN8s[29],是FCN32s的一个变种.此类框架利用了编码层的多阶段侧边输出,并通过连续的卷积操作细化特征,同时减少各阶段特征图的数量,然后使用转置卷积上采样多尺度的特征图到原始的分辨率大小,最后将各层输出使用逐元素相加法进行结果融合,输出分割的结果.相比Feed-forward框架,这类结果将高层高语义特征与低层高细节特征进行融合,得到了较准确的分割结果.
Decoder框架是性能最好、最常使用的一类分割框架,应用在著名的U-Net[39],SegNet[40],Deconv-Net[41],RefineNet[42-43]等分割网络中.它们的共同点是渐进式地从高层特征上采样到原始输入大小,同时融合同阶段编码层的信息.其中U-Net框架最早用于生物医学图像分割,整个框架形成一个U形的对称结构.U-Net的编码层与解码层在各个阶段是相互对称的,其解码层逐阶段地上采样,然后与同阶段的编码层进行汇总,并使用3×3的卷积操作进行特征的融合,输出最终分割结果.该类框架广泛应用于二值语义分割,尤其在医学图像分割、遥感图像分割以及Kaggle各类比赛中应用广泛.SegNet也是一个对称性的网络框架,与U-Net不同,该网络并没有直接融合编码层的特征,而是利用了来自编码层的池化索引结果,逐阶段地上采样高层特征为原先的2倍,然后同编码层相对称地使用等量的卷积、Batch Normalization和ReLU操作,最后输出分割的结果.DeconvNet同SegNet结构类似,也使用了上池化操作,同时解码层为编码层的镜像,所不同的是其在解码层使用转置卷积取代普通的卷积.
Dilation框架利用了空洞卷积[44].传统的网络在编码层使用步长大于1的池化操作扩大感受野,增强网络的不变性,提升网络的特征提取能力,但同时也导致特征图变小.空洞卷积在原始的卷积操作上注入了空洞,即设置了卷积核的间隔数量,称之为 空洞率,正常的卷积,其空洞率为1.一般地,空洞率越大,感受野也越大.空洞卷积可以在保持同池化操作相同的感受野的同时不丢失特征图的分辨率,又可以有效地利用在ImageNet等上预训练好的特征,已经作为一个标准的操作应用在语义分割中,如著名的Deeplab系列、ParseNet[45]、PSPNet[46]等.Deeplab系列是由谷歌的研究人员推出,目前共有4个版本,其中Deeplab V1[47]框架类似于Skip结构,在每一个编码阶段的最后一层连接了一个MLP层,然后将各阶段的输出汇合在一起,使用逐像素的加和进行融合,输出分割结果.Deeplab V1将pool4和pool5的步长由2变成了1,然后紧接着使用了空洞卷积以取代普通的卷积操作,使得特征图为输入大小的18.Deeplab V1还引入了全连接的条件随机场操作用于细化分割的边缘.由于Deeplab V1在编码层的每一阶段都连接了大量的卷积层,导致参数过大,为了克服这个缺点,使网络更加精炼,又推出了Deeplab V2[48].Deeplab V2的最大特点就是ASPP(atrous spatial pyramid pooling)结构.ASPP是一种“桶形” 结构,由多尺度的空洞卷积组成,用来捕获不同尺度的感受野,后面连接着2个1×1的卷积用于细化特征,同时减少特征图数量,然后通过逐像素的加和进行融合,输出预测的分割结果.Deeplab V3[49]借鉴了ParseNet和PSPNet的思想,进一步地将全局的上下文信息融合到ASPP中,同时使用1×1的卷积操作取代大尺度的空洞卷积.为了进一步地细化分割边界效果,Deeplab V3+[50]引入了Decoder结构,结合了来自底层的特征进行,2次上采样,逐步将分割结果恢复到原始的分辨率大小.
总的来说,目前的语义分割框架并不是严格独立的,很多新的分割网络融合了不同框架的优点,从语义分割的发展趋势上看,一个好的语义分割网络往往朝着4方面努力:
1) 扩大感受野,挖掘不同尺度的信息[51].相关方法大致可以分为3类,分别是:Deeplab系列采用的多尺度空洞卷积;ParseNet,PSPNet等采用的全局平均池化操作;使用不同大小的卷积核[52].
2) 将语义较强的高层特征与细节较强的低层特征进行融合,或者借助低层的池化索引上采样高层特征,例如Skip框架和Decoder框架.
3) 设计辅助任务,增强语义分割网络的特征提取能力,进一步地提升分割精度.例如文献[53]在语义分割任务的基础上增加了边缘检测的任务,增强了类外的差异性.文献[54]在语义分割网络中增加了全局的分类任务来寻找和语义分割最相关的类别,以此增加全局的上下文信息,提升分割的准确率.
4) 使用更好的基底网络,例如当前更多的语义分割网络使用ResNet[46,49-50]取代VGGNet提取特征,也有人开始将更先进的DenseNet[55]应用于语义分割.
表1汇总了部分经典的全卷积分割网络的特点.
最早将全卷积分割网络应用于虹膜分割的来自文献[3],其提出了多尺度的全卷积网络(multi-scale fully convolutional networks, MFCNs)用于虹膜分割,该网络采用了类似于Deeplab V1的结构,高层特征和底层特征进行了有效的融合,提升了分割的性能.作者使用来自前面介绍的UBIRIS.v2和CASIA.v4-distance的子数据集,分别进行了训练,然后在对应的数据集上进行了测试,结果显示,相比传统方法,该方法可以明显提高分割的精度,但在黑色皮肤和没有眼睛的图像上该方法出现了错误,作者提到主要的原因是样本缺少.文献[56]提出了轻量级的DeconvNet,该网络总共有6层,3层卷积层和3层转置卷积层,每一层后面紧跟着一个Batch Normalization层和ReLU层,整个网络没有池化操作和全连接层,相比原始的DeconvNet,该网络使用了较大的卷积核,参数比较少,在CASIA-IrisV3-Interval 数据集上获得了不错的效果,不过由于该数据集比较小,虹膜形态比较单一,因此需要验证其在更有挑战性的数据集(如UBIRIS等)上的效果.文献[57]使用了修改后的Deeplab网络用于虹膜、巩膜、瞳孔与背景区域的分割,并且使用了自己收集和标定的虹膜图像进行训练,值得注意的是该标定是一个粗糙的标定,没有考虑到将睫毛、光照等分离出去.文献[58]将SegNet的3种变体:Original,Basic,Bayesian-Basic应用到虹膜分割上,作者使用了5个数据集进行了实验,并且与传统的方法进行了比较,结果显示Bayesian-Basic的效果最好.这里Bayesian-Basic不同与原始的SegNet实现,它在Encoder和Decoder的最深的2个卷积层后面增加了额外的Dropout层,并且在测试阶段使用Monte Carlo Dropout sampling去产生像素类别标签的后验分布和最终的分割结果.文献[59]提出了基于注意力机制的改进U-Net模型用于虹膜分割,作者在原始U-Net的Encoder末尾增加了边界框回归子网络用于获取虹膜的注意力掩膜,随后该掩膜作为一个权重函数与Decoder部分的特征层融合促使模型更加聚焦于有效的虹膜区域的分割.SegDenseNet[60]是目前第1个将DenseNet应用在虹膜分割上的网络.SegDenseNet仿照FCN32s[29]将DenseNet去掉全连接层,改造成全卷积网络,并使用Skip结构融合不同层的输出,最后使用转置卷积上采样输出到原始大小.作者将SegDenseNet用于白内障病人的术前和术后虹膜分割,取得了较好的效果,相似的网络还包括IrisDenseNet[61].为了减少分割网络的参数,文献[62]设计了基于Encoder-Decoder的全残差分割网络FRED-Net,在获得很高的分割精度的同时保持轻量级的大小.
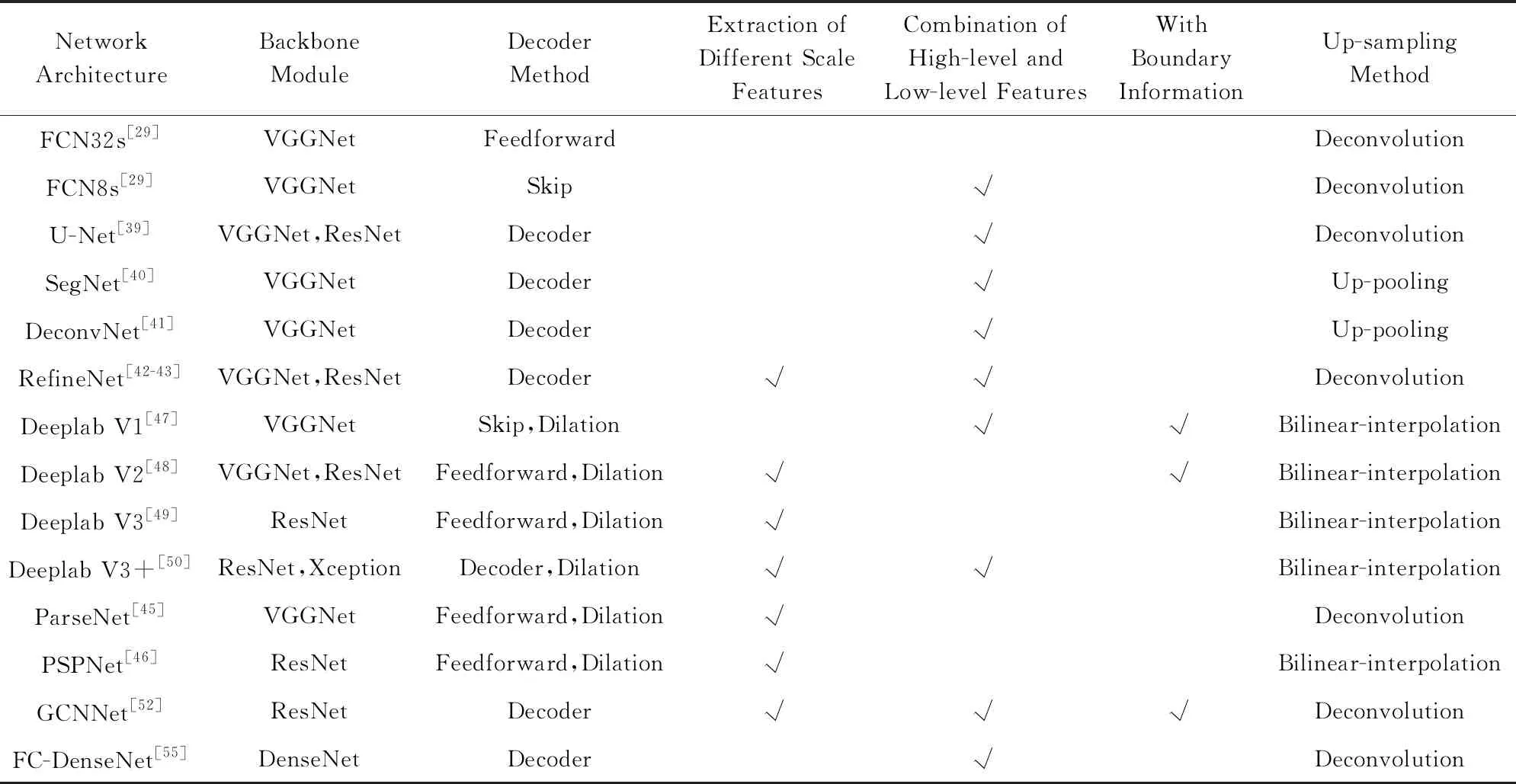
Table 1 Classical Fully Convolutional Segmentation Networks表1 经典的全卷积分割网络
总的来说,大多数现有的虹膜分割网络都源自一般的语义分割网络,且在各种数据集上进行了测试,验证了算法的有效性.表2列举了部分传统虹膜分割方法和基于深度学习的虹膜分割方法的比较.
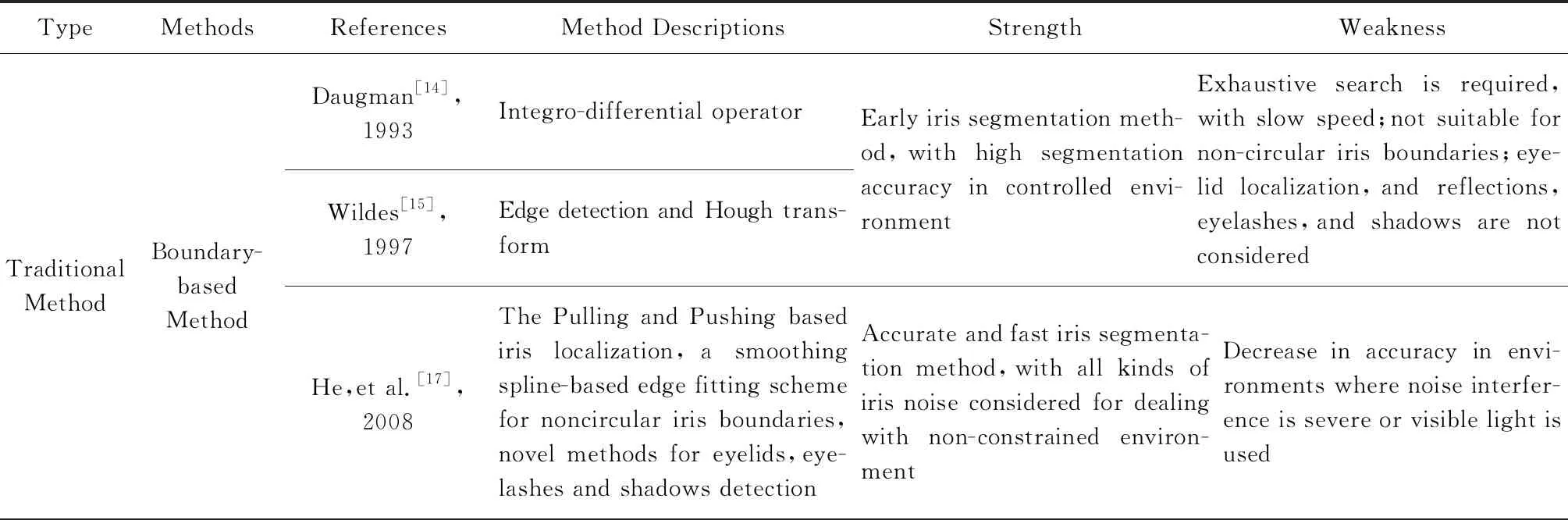
Table 2 Comparison Between Traditional and Deep Learning Based Lris Segmentation Methods表2 传统方法和基于深度学习的虹膜分割方法的比较
Continued (Table 2)
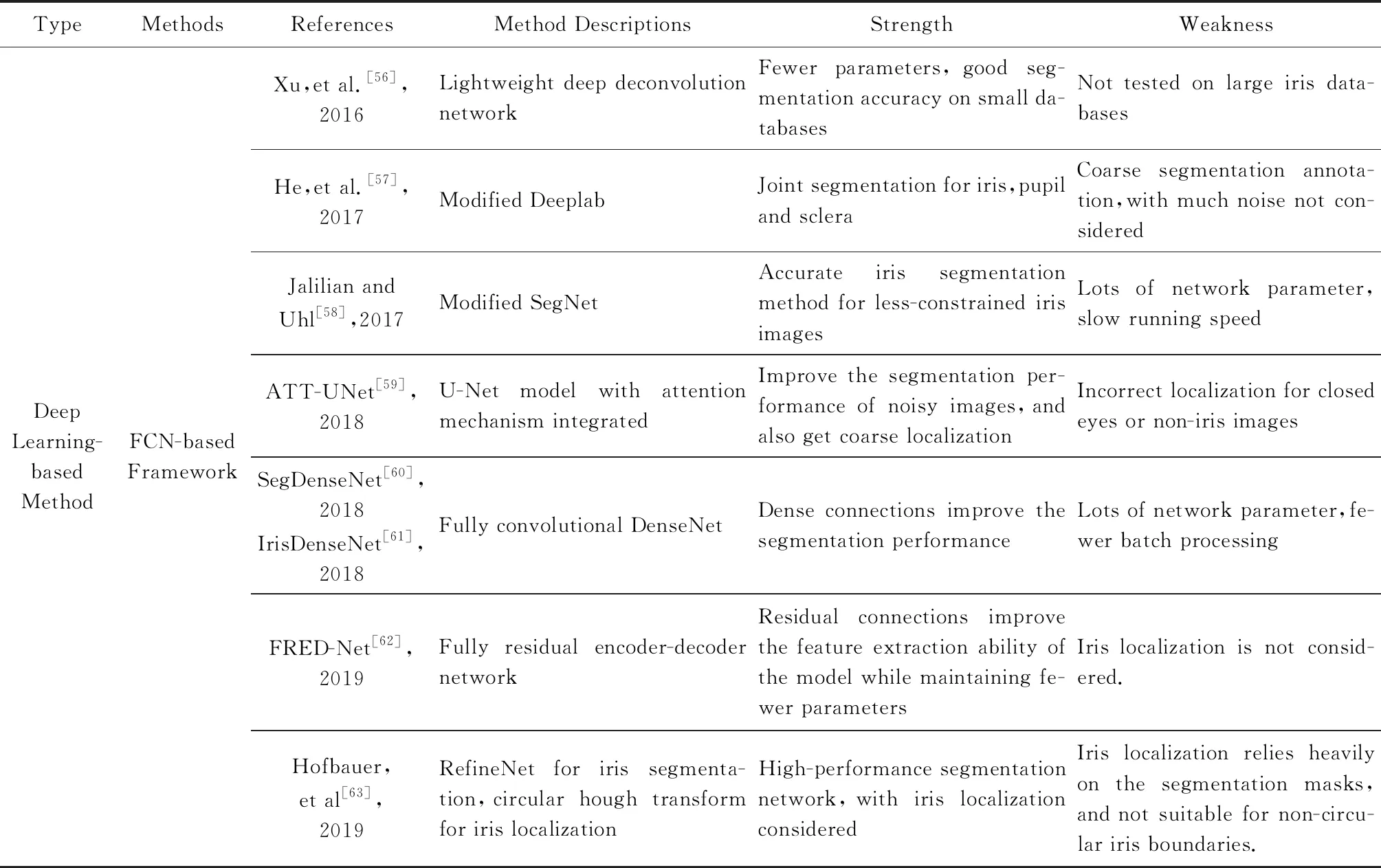
Continued (Table 2)
Note: ① http://nice1.di.ubi.pt/; ② https://github.com/5455945/Iris_Osiris; ③ https://www4.comp.polyu.edu.hk/~csajaykr/tvmiris.htm;④ https://ars.els-cdn.com/content/image/1-s2.0-S0167865515000604-mmc1.zip
5 实验设计与评估
5.1 实验设计
为了建立一个公平的虹膜分割算法基准,我们选取了一些经典的全卷积分割网络,在三大数据集上进行了训练和测试,同时使用提出的评价指标进行了评估.我们的评估模型和相关代码将会在github(1)https://github.com/xiamenwcy/IrisSegBenchmark上开源,因此欢迎更多的研究者使用我们的方法提交评测的结果.
实验选取的网络包括FCN8s[29],U-Net[39], SegNet[40],Deeplab V1[47],Deeplab V2[48],Deeplab V3[49],ParseNet[45],PSPNet[46],覆盖了提出的4种分割解码框架.另外为了与传统的方法进行比较,我们选取了2种性能最好的传统分割算法[20-21]作为对比,这2种方法在各类数据集的测试中取得了很好的效果,因此具有很强的代表性,且有公开的源代码或者可执行程序.
实验过程中,首先对于所有的全卷积网络,都采用在ImageNet上预训练的VGG-16网络的前5个卷积模块作为编码层,然后将解码层的分割类别调整为2,其中一个类别表示背景,另一个表示虹膜区域.网络训练过程中,使用交叉熵损失函数作为优化的目标函数,使用的数据为带有人工标注的CASIA,UBIRIS,MICHE这3个数据集,并且我们对数据进行了扩充.扩充方法是:对于每一张训练图片,首先将其缩放为原来的0.5,1,1.5倍,然后对于每个尺度的图片,旋转16个不同的角度,并进行左右翻转,这样就可以将数据集扩充为原来的96倍,最后CASIA,UBIRIS,MICHE训练集的总样本数为28 800,48 000,13 440.
实验使用开源框架Caffe[64]来实现网络模型,模型的参数设计保持同原文献一致.我们先在扩充后的数据集上进行网络训练,然后使用训练好的模型在测试集上进行测试.整个实验使用单块12 GB的GTX Titan GPU进行.
5.2 实验结果
表3~5分别展示了2种传统的虹膜分割方法和若干种全卷积分割网络在3种不同的数据集上的分割结果.我们在评测中使用了前面所述的评价指标,立足于产生一个较全面的评价结果.
从表3来看,文献[20]在各种评价指标上都表现出一致较好的性能,而相比之下,文献[21]性能较差,这与其论文中表述的性能似乎不符.需要注意的是我们这里使用的是作者提供的可执行程序,由于没办法调参,所以这里得到的结果也许并不是最优的.另外文献[21]运行时间较长,主要原因是作者提供的程序不仅仅用来做虹膜分割,也提供了虹膜归一化处理等其他操作,另外程序本身没有进行优化.
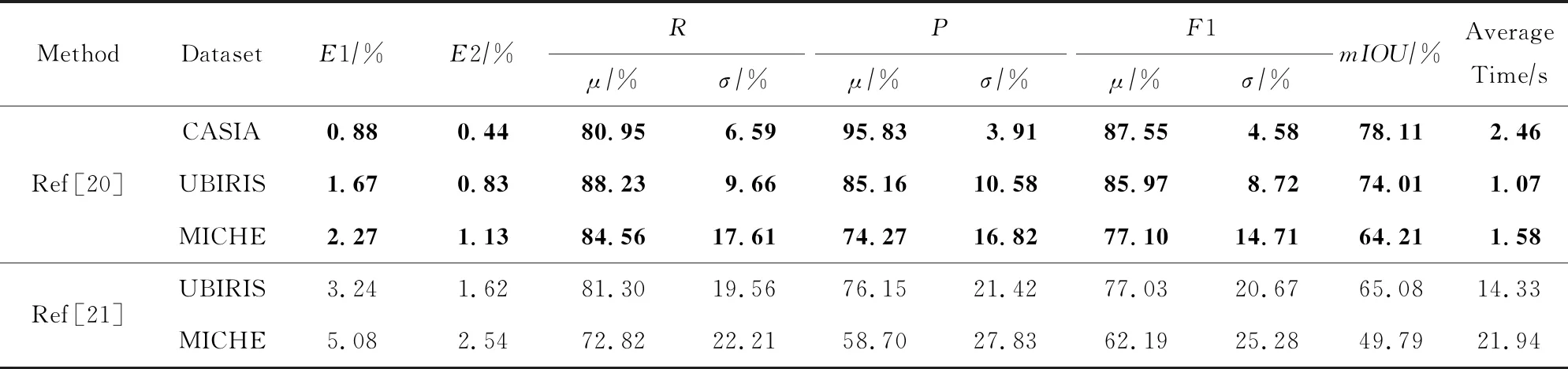
Table 3 Comparison of Traditional Iris Segmentation Methods on Different Datasets表3 传统虹膜分割方法在不同数据集上的比较结果
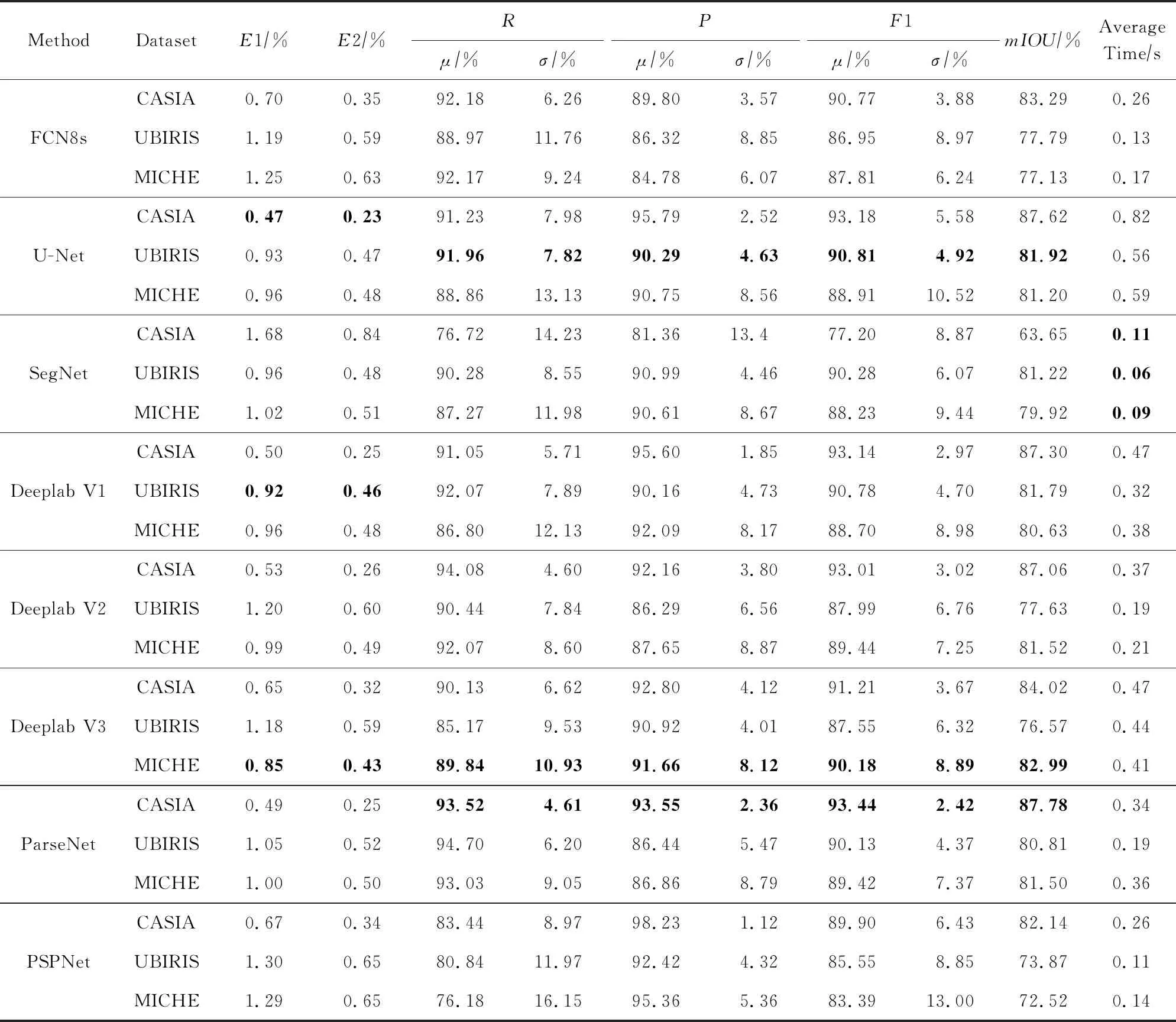
Table 4 Comparison of Different Fully Convolutional Segmentation Networks on Different Datasets表4 各种全卷积分割网络在不同数据集上的比较结果
Table 5Comparison of Different Fully ConvolutionalSegmentation Networks on Computational Complexity
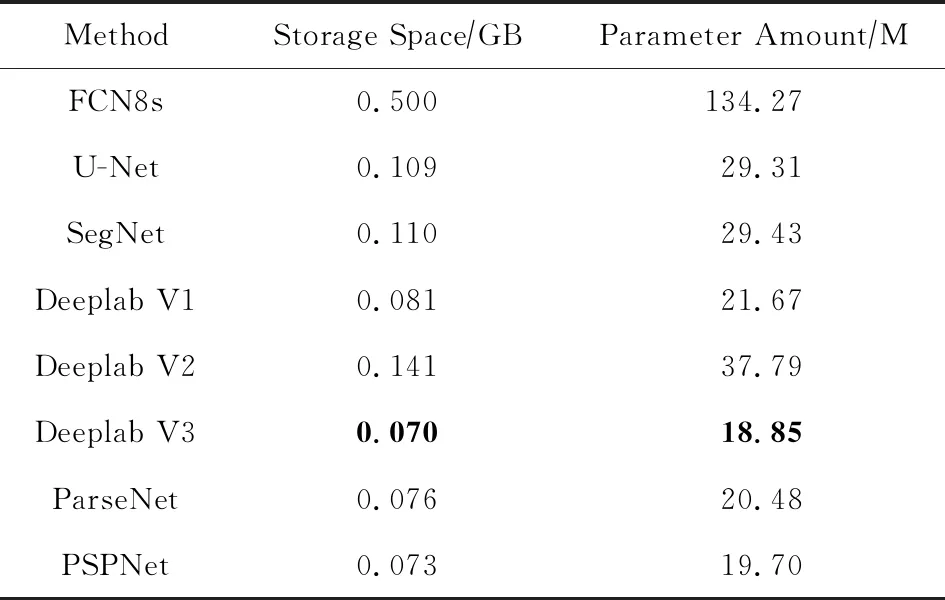
表5 各种全卷积分割网络在计算复杂性上的比较结果
我们在全卷积分割网络的实验中分别使用了单尺度和多尺度的方式进行测试.单尺度是指对于一幅输入图像,仅使用原图得到分割结果.多尺度是指将一幅输入图像分别缩放为0.5,1.0,1.5倍,然后将得到3个结果进行融合,得到最终的分割结果.从测试结果上看,多尺度的方式得到的分割精度高于单尺度,因此这里汇总为多尺度的分割结果.由于SegNet只支持固定输入,所以这里只呈现其单尺度的测试结果.
由表4和表5可得如下实验结论:
1) 各评价指标之间存在一定的一致性,但并不是严格单调的.以U-Net为例,将在CASIA和其他2个数据集的结果进行比较发现,其在CASIA数据集上的E1和E2指标最低,相应地,其F1值和mIOU也表现较高.但是,和ParseNet相比,尽管其在CASIA数据集上的E1和E2指标低于ParseNet,但是F1值和mIOU却不如后者高,但是相差不大.实际使用中,我们需要根据实际的需求来确定,如果更加关注错误率,例如将虹膜识别应用在安防等更加关注安全的领域,在此情况下,较低的错误匹配是更好的,则应该使用E1和E2指标;如果更加关注正确检测率,例如将虹膜识别应用在手机解锁等领域,在此情况下,更高的匹配成功率是需要的,则应该使用F1值和mIOU指标.一般学术上,更加关注E1和E2指标.
2) 以E1和E2指标排序,U-Net,Deeplab V1,Deeplab V3 在CASIA,UBIRIS,MICHE的分割性能最好,分别比文献[20]低0.41%(0.21%),0.75%(0.37%),1.42%(0.70%).其中括号外面指的是E1,括号里面指的是E2.以F1值和mIOU指标排序,ParseNet,U-Net,Deeplab V3在CASIA,UBIRIS,MICHE的分割性能最好,分别比文献[20]高5.89%(9.67%),4.84%(7.91%),13.08%(18.78%).其中括号外面是F1的均值,括号里面是mIOU.另外从整体来看全卷积分割网络一致地超过了传统的虹膜分割方法,反映了深度学习方法的优越性.
3) 除SegNet外,其他算法均一致性地在CASIA数据集上表现最佳.这主要源于CASIA数据集含有较少的噪声,是高质量的近红外图像,而SegNet框架比较适合处理RGB图像.
4) 从模型的存储空间和参数数量上看,FCN8s占用最多,主要由于FCN8s网络是将原始的VGGNet的全连接层直接改成了卷积层,其参数数量并没有减少,而其他的网络或者使用空洞卷积或者直接去掉了原始的全连接层,因而模型的参数数量较少,占用存储空间较小.但是在整个FCN类网络中,最小的模型占用存储空间也在0.07 GB(72 MB左右),参数数量达到了18.85 M,因此有必要进行模型的裁剪和压缩.
5) 得益于GPU的高性能运算,使用FCN类网络进行测试时平均运行时间在1 s以内,然而没有达到实时的处理速度,因此如结论4),必要的网络压缩或者轻量级的分割网络是虹膜分割的发展趋势.
根据评价指标6,我们对全卷积分割网络进行了跨库评估.根据表4的分割结果,我们选取了在3个数据集上性能一致较好的Deeplab V1和U-Net进行了实验.表6展示了跨库评估的结果.具体的实验步骤为:将网络分别在UBIRIS和MICHE数据集上进行训练,然后在剩余的2个数据集上直接进行测试.
从实验结果上来看,对于CASIA数据集,2个网络泛化性能都不好,甚至说已经退化.主要原因在于UBIRIS和MICHE数据集都是在可见光下拍摄的,而CASIA数据集是近红外下拍摄的,尽管CASIA数据集图像质量比较高,但网络的学习能力依然很差,并不能很好地进行迁移.而在UBIRIS和MICHE数据集上测试的效果比较好,其原因是UBIRIS和MICHE 都是在相似的环境下拍摄,服从相似的数据分布,因此表现的泛化能力较好.
此外整体来看,在UBIRIS训练的网络比在MICHE训练的网络性能较高,主要原因在于UBIRIS训练集数量(48 000幅)远超MICHE数据集(13 440幅),因此涵盖了更多的噪声种类和虹膜形态,也充分说明了数据对于深度学习的重要性.
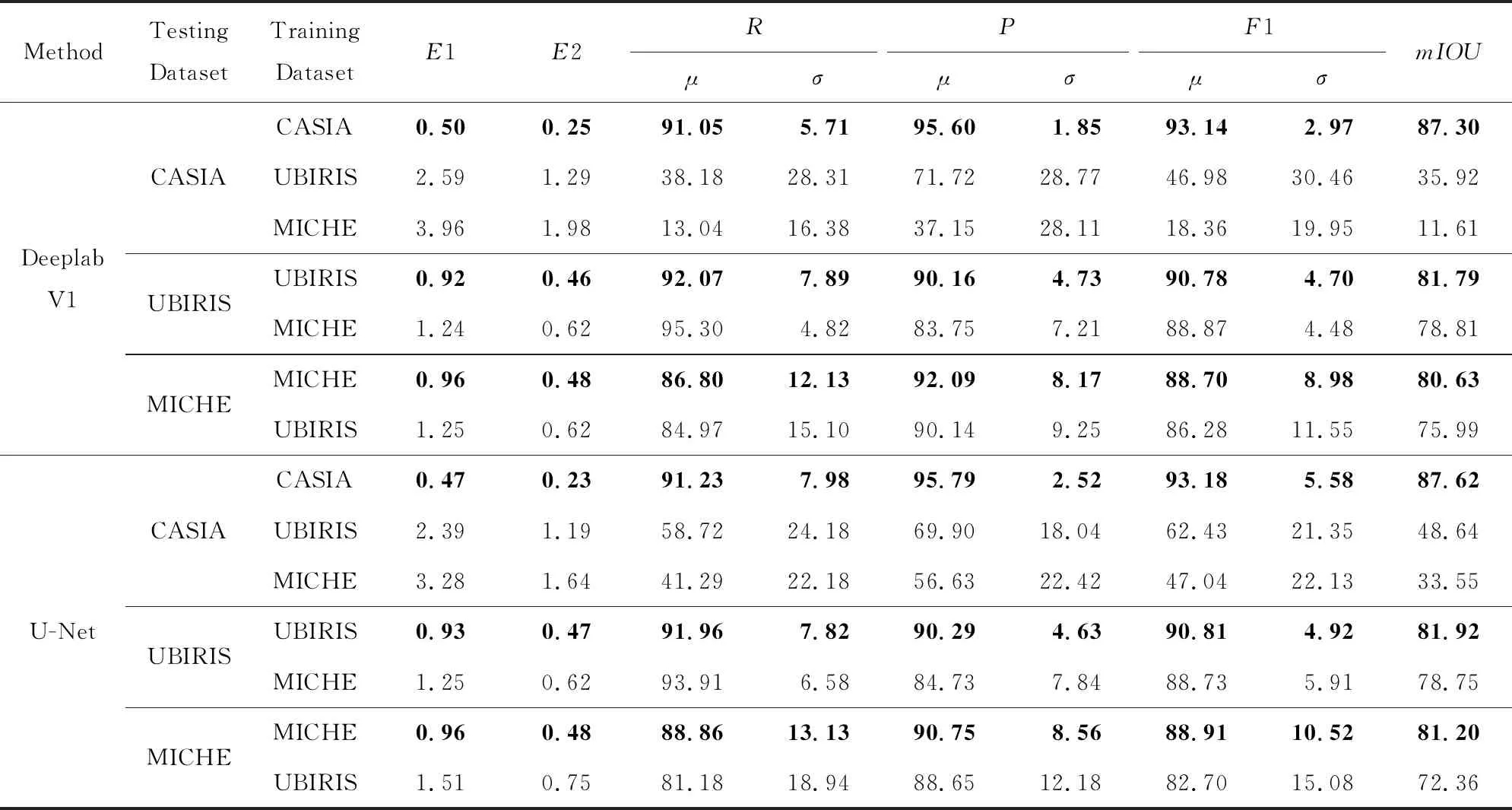
Table 6 Segmentation Results of Cross Database Evaluation表6 跨库评估的分割结果 %
为了对比各种算法在困难样本的表现,我们从3个数据库中随机选取了一些带有镜面反射、眼皮遮挡、闭眼、黑色皮肤、睫毛遮挡、头发遮挡等困难样本共9幅(其中每个数据库为3幅),并使用目前最好的3个算法进行了测试,包括1个传统方法和2个基于深度学习的方法,即U-Net和Deeplab V1.表7展示了对比结果,其中红色标注了错误拒绝的像素点(即该点被标记为虹膜而算法却识别为非虹膜像素),绿色标注了错误接受的像素点(即该点被标记为非虹膜而算法却识别为虹膜像素).
从最终的视觉效果来看,在面对有挑战性的困 难样本时,深度学习方法表现得更加鲁棒,其可以比较准确地识别出真实虹膜的位置,尤其是表6最后一幅图像,即使不存在虹膜区域,深度网络也能准确地识别出来,但是传统方法会显示更多的误判点.当然我们也发现,基于深度学习的方法,表现出错误拒绝的像素点个数要高于错误接受的像素点个数.这表明深度学习方法对于有争议的虹膜像素倾向于将其识别为背景像素,我们将其称为类内的不一致性问题,间接反映了深度网络欠缺学习到一个有区别力的虹膜特征表示.

Table 7 Segmentation Results of Hard Examples表7 困难样本分割结果

Continued (Table 7)
6 思考与展望
综上所述,相比传统方法,基于深度学习的分割模型,尤其是全卷积分割网络能够从大量的数据中自动学习特征,进而可以进行准确的虹膜分割,为虹膜识别打下良好的基础,因此是虹膜分割的首选算法.但是当前基于深度学习的虹膜分割技术仍然存在很多问题,这也是未来可以研究的开放命题.
1) 当前的虹膜分割网络可以得到逐像素的预测结果,但是不能直接得到虹膜的内外边界定位,因此无法进行后续的归一化处理,也就无法进行虹膜识别.一种间接的处理方法是从分割好的虹膜掩模中提取虹膜的内外边界(通常是内外圆),如文献[63,65],但是由于虹膜区域经常面临很多的噪声遮挡,得到的虹膜掩模并不是完整的圆环区域,导致这类方法往往会失败.因此我们需要发展多任务的分割框架,既能得到分割的掩模,也能得到内外边界参数.
2) 当前的虹膜分割网络尽管在分割精度上超越了传统的方法,但是其模型占有空间较大,运行时间较慢,因此需要设计高效的轻量级神经网络,或者采取网络压缩和裁剪等方法.
3) 虹膜、巩膜、手、耳朵等都是人体的生物特征,均可以用来进行身份识别.其识别过程都经历了检测、分割[66-68]以及归一化处理等阶段,尤其是分割处理,本质上都是二分类的像素级分割,也都会面临被各种噪声遮挡的问题.因此可以统计其一般规律,提出统一的生物特征分割网络框架,用于这类图像的分割处理.
7 总 结
本文建立了虹膜分割算法的评价基准,选取了3类有代表性的虹膜分割数据库,并定义了完整的评价指标,然后总结了传统的虹膜分割算法和基于深度学习的虹膜分割算法,最后选取了一些经典的算法在选取的虹膜数据库上进行了详细的实验和比较分析,实验结果充分表明了全卷积分割网络在虹膜分割中的优越性,同时结尾也指出了当前全卷积分割网络存在的一些问题,这些问题的解决将促进虹膜识别新的发展.
