基于深度学习的偏光片缺陷实时检测算法
2020-02-06刘瑞珍孙志毅王安红孙前来
刘瑞珍,孙志毅,王安红,杨 凯,王 银,孙前来
(太原科技大学 a.材料科学与工程学院,b.电子信息工程学院,太原 030024)
在偏光片生产过程中,由于加工工艺限制、设计水平不足,生产设备故障和生产条件恶劣等因素,在工件内部极易形成不均匀的区域,这些区域通常表现为气泡状的残胶、裂缝、夹杂物、污渍、划痕等缺陷。这些缺陷通常是通过人工检查来完成的,主要是通过在生产线上对偏光片进行视觉扫描,将有缺陷的产品分类出来以便后续处理。然而,在大批量生产过程中,检测精度和速度易受检测人员主观因素及经验的影响,难以满足现代装配线的要求。因此,需要开发高精度、高速度以及自动有效的图像分类技术来检测这些缺陷,以确保生产线中偏光片的质量。
传统的机器视觉检测缺陷[1]主要通过对被检物图像进行处理,在图像处理过程中,需要人工定义和选择能够准确识别图像中缺陷的特征表示。但是在工业环境中,当出现新的问题时,必须手动设计新的特征,由于缺陷区域位置随机性,形状多样性和复杂性,因此用于描述缺陷的标准特征描述符往往导致分类结果不准确,很难满足实际工业要求。
近年来,随着深度学习的兴起与发展,深度卷积神经网络克服了手动重新定义每个新缺陷的特征表示的困难,显著提高了图像分类[2-3]、目标分割[4-5]、目标检测[6]和其他视觉任务[7-8]等应用中的检测性能,其中具有代表性的分类网络主要有AlexNet[2],VGG[9],GoogLeNet[3]和ResNet[10]。然而,这些经典的分类网络构建的越来越深,模型大小也在不断增加,在许多实际应用如人脸识别和汽车自动驾驶中,需要在计算受限的平台上实时地执行识别任务,因此,在尽量不影响网络效果的前提下,模型压缩和简化设计成为了一个很重要的研究方向。
为了减少深度学习网络模型在移动设备上运行所占用的存储空间,2015年,HAN et al[11]在不影响分类准确率的前提下,通过修剪网络中不重要的权重连接,将深度学习网络所需要的存储和计算量减少了一个数量级。2016年,HAN et al[12]将网络剪枝、量化和霍夫曼编码相结合来扩展他们以前的工作,提出了一种称为“深度压缩”的方法,将AlexNet压缩了几十倍,极大地减少了模型的存储空间。2017年,IANDOLA et al[13]设计了一个不同于传统卷积层的Fire模块,并构建了一个名为SqueezeNet的小型卷积神经网络结构,分类正确率和AlexNet相同的情况下,参数量比AlexNet减少了50倍。MobileNet[14]网络使用深度可分离卷积来构建高性能的轻量级神经网络模型,有效地减少了网络的参数量,并能很好地与移动和嵌入式可视化应用的设计要求相匹配。ShuffleNet[15]网络是专门为计算能力非常有限的移动设备而设计的,主要采用了两个新的操作,即逐点组卷积和信道混合,既保持了分类准确率,又大大降低了计算成本。因此本文将图像分类与模型压缩相结合,搭建了一个轻量级的偏振片缺陷实时检测网络,在不降低分类准确率的前提下最小化训练模型及加快检测速度,以达到实际工业的实时需求。
1 基于深度学习的偏光片缺陷实时检测算法
1.1 偏光片缺陷分类网络设计
本文提出的偏光片缺陷分类网络是基于并行模块和并行非对称卷积模块设计的,如图1所示,该网络主要由一个标准的3×3卷积层(卷积层1),5个并行模块和1个并行非对称卷积模块组成。在并行模块2、3、4和并行非对称卷积模块之后,我们分别使用最大池化层来减少特征映射的维数和参数。LIN et al[16]的工作中用全局均值池化层代替全连接层,以减少网络的参数量,同时克服了全连接层容易过拟合的缺点,提高了整个网络的泛化能力。本文利用全局均值池化层的上述优点,在并行模块5之后使用一个全局均值池化层来增强特征映射与类别之间的对应关系,使卷积结构保留的更好,分类更准确;此外,全局均值池化层与全连接层相比,无任何参数需要优化,大大地减少了网络的参数量及计算量。最后,网络经过Softmax层对输入的偏光片图像进行分类,得到分类结果。本文提出的偏光片分类网络为了加速网络训练的收敛速度并提高网络的泛化能力,除最大池化层外,网络每层后面都添加一个批量归一化(Batch Normalization,BN)层对输入数据做归一化处理,同时为了增加各层之间的非线性关系,在BN层之后添加激活层,所使用的激活函数为ReLU函数。

图1 偏光片缺陷分类网络结构
1.2 并行深度可分离卷积模块
经典的分类网络如AlexNet,GoogLeNet和ResNet,由于其网络层数越来越深,模型越来越大,占用内存不断增加,实时性差,因此很难应用于偏光片在线检测系统中。考虑到工业中对于实时性和准确性的要求,本文参考经典深度压缩模型MobileNet[14]中利用深度可分离卷积代替传统卷积以减少网络参数量的思想,主要对深度可分离卷积进行了改进与优化,得到并行深度可分离卷积模块用来构建偏光片缺陷分类网络。
图2给出了本文设计的并行深度可分离卷积模块的结构,与深度可分离卷积不同,该并行模块混合了不同尺寸的卷积滤波器,这种设计不但能够更好地融合不同尺度的特征,还能提取到更丰富的缺陷特征,使后续的缺陷分类操作更准确。利用该模块搭建的偏光片缺陷分类网络可以显著地减少网络参数量和MACCs,这将会在实验部分得到充分的验证。
图2中实线框1代表的是本文提出的并行深度可分离卷积模块。首先,使用1×1的卷积滤波器来减少输入到虚线框2的通道数,即特征图个数;其次,虚线框2是由1×1卷积滤波器和点划线框3混合而成,即采用不同尺寸的卷积滤波器(1×1和3×3)来提取偏光片中缺陷特征;最后,将1×1卷积滤波器和点划线框3的输出连接到一起,作为网络下一层的输入。点划线框3代表的是深度可分离卷积。该并行模块中所有的卷积操作后都执行BN和ReLU操作以加速收敛,提高模型的泛化能力和防止梯度消失问题。
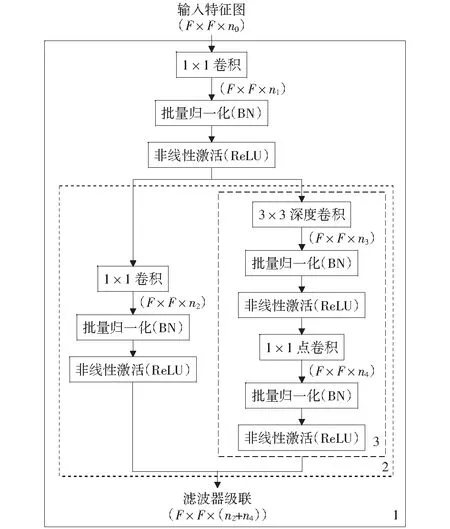
图2 本文提出的并行深度可分离卷积模块结构
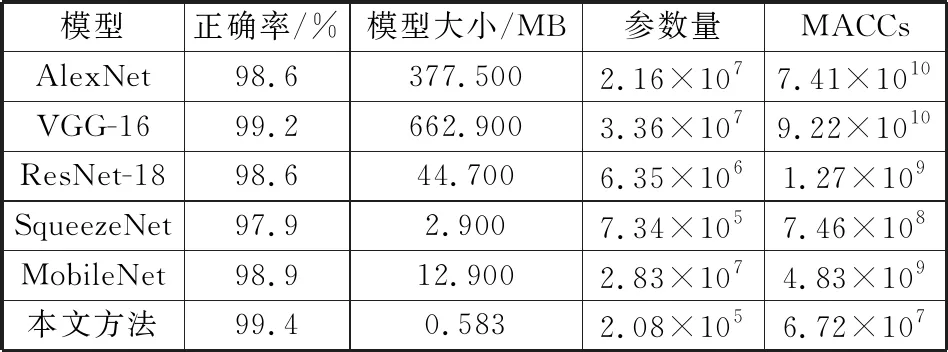
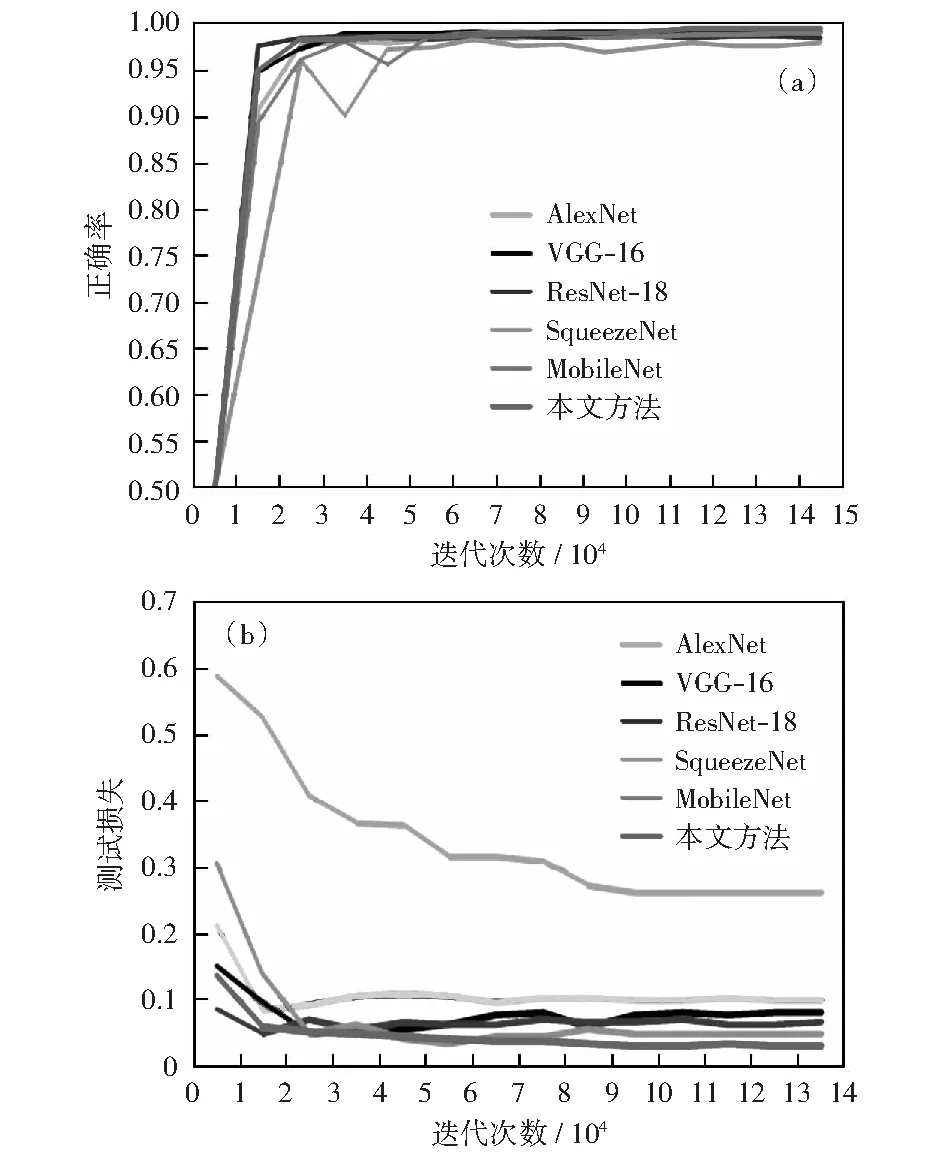
在图2中,有4个可调参数:n1,n2,n3,n4和2个固定参数F和n0,F和n0分别指输入到并行模块的特征图的宽度(或高度)和特征图的个数。n1表示并行模块中虚线框2上方1×1卷积滤波器输出的特征图个数,n2表示虚线框2左侧的1×1卷积滤波器输出的特征图的个数,n3和n4表示点划线框3中卷积滤波器的输出特征图个数。在本文设计的网络中使用并行模块时,n1 GoogLeNet Inception V3中将n×n的卷积拆分为1×n+n×1的非对称卷积用以节约网络参数量,加快运算及减轻过拟合,同时非对称卷积还能处理更多、更丰富的空间特征,增加特征的多样性,扩展模型的表达能力[17]。所以为了进一步减少网络的参数量,本文利用非对称卷积的上述优点,对1.2节中提出的并行深度可分离卷积模块中的深度可分离卷积进行改进,即将图2中点划线框3中的3×3深度卷积(图3(a)所示)用1×3+3×1卷积替代(图3(b)所示)以构成并行非对称深度可分离卷积模块,利用1×3+3×1的卷积核对特征图进行卷积的感受野和利用3×3的卷积核进行操作的感受野是相同的,不同之处在于1×3+3×1的卷积核将网络分成两层进行滑动卷积,增加了网络的深度,随着网络层数的增加,网络提取特征的能力也随之提高,所以这种空间结构的拆分能够提取到更加丰富的缺陷特征,使训练得到的网络模型的分类正确率得到提高。 图3 (a)深度可分离卷积,(b)深度可分离非对称卷积 对于中等网络尺寸,在m×m的特征图上,当12 表1列出了并行模块与并行非对称卷积模块的参数量及分类正确率,若图1中偏光片缺陷分类网络是由标准卷积层与6个并行模块组成,则第五个并行模块的参数量为86 016,训练得到的模型分类正确率为98.9%.将第五个并行模块用并行非对称卷积模块代替之后,此模块的参数量为73 728,参数量减少了14.3%,模型的分类正确率为99.4%,正确率提高了0.5%.所以在网络输出特征图大小在12到20范围内,用并行非对称卷积模块代替并行模块之后,既增加了网络的深度,减少了参数量,也提高了分类准确率。 表1 并行模块与并行非对称卷积模块参数量及分类正确率比较 从电子二厂获得了某一批次产品的偏光片图像数据集,并将图像分为三类:无缺陷图像、污渍图像和缺陷图像(如图4所示),实验部分将利用此数据集来评估该系统的性能。该数据集共有5 000张200×200×3偏光片灰度图像,其中无缺陷图像共1 000张,污渍图像和缺陷图像各2 000张。将这5 000张图像随机地按3∶1∶1的比例分配为训练集、校验集和测试集。本文实验过程中,需要检测偏光片图像中是否存在污渍和缺陷,并能将其与无缺陷图像进行正确的分类。 图4中,第一行代表无缺陷图像;第二行代表污渍图像,红色矩形框代表污渍部分,其对应于生产过程中偏光片表面有污渍的样品,它们需要被正确分类出来,并将污渍清洗干净后可再次投入使用;第三行代表缺陷图像,红色矩形框内不规则的圆圈或半圆代表的是在偏光片的生产过程中由特定的编码装置喷涂在偏光片表面的特殊记号,这类缺陷样本被正确分类出来后将不能再次进行使用。从图中可以看出,红色矩形框的位置和大小都不一致,即缺陷的位置不固定,形状多种多样。 图4 偏光片图像数据集 本实验环境为Linux Ubuntu 14.04操作系统,8 GB内存,NVIDIA GeForce 1080显卡,并用Caffe深度学习框架进行训练。训练过程和校验过程中的mini-batch大小分别设置为20和10.动量因子设置为0.9,权重更新量设置为0.000 2,初始学习率设置为0.001,且采用随机梯度下降方法进行训练,网络的最大迭代次数设置为140 000次。 为了验证本文方法的有效性,将其与现有的深度学习经典算法AlexNet[2]、VGG-16[9]、ResNet-18[10]、SqueezeNet[13]和MobileNet[14]进行了比较。表2给出了本文方法与上述5种经典算法在校验集上的实验结果比较,从表2可以看出,本文方法得到的模型分类正确率分别比AlexNet,VGG-16,ResNet-18,SqueezeNet和MobileNet高0.8%;0.2%,0.8%,1.5%和0.5%.模型大小分别减少了647.8,1 137.6,76.7,4.98和22.1倍;参数量比AlexNet,VGG-16和MobileNet减少了两个数量级,比ResNet-18减少了一个数量级。MACCs比AlexNet和VGG-16减少了三个数量级,比SqueezeNet减少了一个数量级,比ResNet-18和MobileNet减少了两个数量级。因此,本文方法可以在不降低分类准确率的情况下大大减小模型的尺寸,并且在分类准确率、速度和存储器使用方面目前均可满足行业对偏光片缺陷的在线实时检测的要求。 表2 不同模型在校验集的实验结果比较 图5显示了6种不同方法训练得到的模型在校验集上的分类正确率和损失函数曲线。本文用140 000次迭代中每1 000次迭代的平均正确率和损失率共14个点来绘制正确率和损失函数曲线。从图中可以清晰地看到本文方法能得到更高的分类正确率和更低的损失率。另外,从图5(a)可以看出本文方法收敛速度明显高于AlexNet,VGG-16,SqueezeNet和MobileNet这四个经典分类模型。 使用测试集来验证本文方法的有效性及泛化能力,测试集中偏光片图像共有1 000张,其中无缺陷图像有200张,污渍图像和缺陷图像各400张,此测试集既没有参与网络的训练,也没有参与网络的校验过程。测试结果如表3所示,可以得出,本文方法比其他五种经典算法能获得更低的分类错误率,充分验证了本文方法的有效性。表3最后一列列出了6种算法在测试过程中每张图片的测试时间,从表中可以看出,与AlexNet,VGG-16,SqueezeNet,ResNet-18和MobileNet相比,本文方法将每张图片的分类时间分别缩短了303.1,2 471,280.4,17.1和116.7 ms.所以无论是从分类精度和速度,本文方法均满足工业中偏光片缺陷实时监测的需求。 图5 (a)校验集上分类正确率的比较,(b)校验集上损失函数的比较 表3 不同模型在测试集上的试验结果比较 图6显示了6种不同的方法训练得到的模型准确率,模型大小和在测试集上针对每张图片的测试时间的比较结果,图中1,2,3,4,5,6分别代表AlexNet,VGG-16,ResNet-18,SqueezeNet,MobileNet和本文方法,图6和表2相结合可以得出,本文方法可以获得更高的准确率,训练得到的模型最小,同时测试速度最快,充分证明了本文方法的有效性。 图6 六种模型的正确率,模型大小和在测试集上的测试时间的比较 本文主要设计了一种基于深度学习的偏光片缺陷实时检测算法,首先,设计了一个并行深度可分离卷积模块来构建偏光片缺陷检测网络,该并行模块有两个优点:一是利用不同尺寸大小的卷积滤波器来提取更加丰富的缺陷特征;二是该并行模块中采用深度可分离卷积替代传统的卷积,显著减少了网络的参数量及MACCs;其次,将并行模块中的3×3深度卷积用非对称卷积替代得到并行非对称卷积模块,进一步减少网络的参数量;最后,网络最后使用全局均值池化层最大限度地减少网络的参数量。实验结果表明,本文方法在分类精度、速度及内存消耗方面均优于现有的方法,达到了工业实时检测缺陷的要求。未来还可以通过其他模型压缩的方法进一步减少模型占用空间,提高模型分类速度及精度。1.3 深度可分离非对称卷积结构


2 实验结果及分析
2.1 数据集介绍

2.2 实验结果与分析


3 结束语
