基于二次排序Top-N算法的呼叫中心文本识别方法
2020-02-05思永坤刘娟许婧
思永坤 刘娟 许婧
(中移在线服务有限公司云南分公司 云南省昆明市 650221)
近年来,随着互联网,特别是移动互联网的发展,引发了数据爆发式增长,大数据正日益对企业竞争能力提升、产品创新、客户市场发展等产生重要影响。而当前大数据平台中存贮的数据分为结构化和非结构化两类组织形式。据统计,企业中80%以上的业务相关的信息都来源于非结构化数据文本[1]。
1 中文分词和语义分析
1.1 中文分词
分词技术是语义理解的首要环节,是文本分类,信息检索,机器翻译,自动标引,文本的语音输入输出等领域的基础。而由于中文本身的复杂性及其书写习惯,使中文分词成为分词技术中的难点[2]。
1.1.1 通信行业分词难点
首先,专业术语与自然表述方式矛盾,例如,“家庭套餐”4字术语在中文中由“家庭”、“套餐”两个词组成,“家庭”、“套餐”又分别有其自有的自然语言定义,将“家庭套餐”分割为特定专业术语,就是中文分词在特定行业应用的一个难点。
其次,词的语义需要根据上下文关联性判断,例如,“还欠费200 多元”,可分割为“还(huan)/欠费/200 多元”和“还(hai)欠费/200 多元”。
1.1.2 常见分词方式
目前较为常见的分词方法有:基于机械切分的分词方法、基于统计的分词方法和知识分词方法。
1.2 语义分析
语义分析指运用各种方法,学习与理解一段文本所表示的语义内容。一般来说,词汇级语义分析关注的是如何获取或区别单词的语义,句子级语义分析则试图分析整个句子所表达的语义,而篇章语义分析旨在研究自然语言文本的内在结构并理解文本单元(可以是句子从句或段落)间的语义关系[3]。
按照研究策略的不同,现有每层次语义分析研究都大概可分为基于知识或语义学规则的语义分析和基于统计学的语义分析[4]。
2 呼叫中心文本识别面临的问题和解决思路
2.1 呼叫中心文本的特点
呼叫中心的文本数据大部分来源于录音文件的语音识别转写。不同于书面语言,呼叫中心的文本内容几乎都是客户与客户代表之间的口述交互,其作为真实数据的记录,数据可能不完整、有噪音,且不一致[5]。因此,呼叫中心的录音文本在识别过程中会存在以下问题:
2.1.1 录音文本准确度问题
受限于录音文件转写平台,录音文本存在转写准确性的问题,导致标准化的字典分词难于适用。例如,“4G”录音转写过程转译为“四季”、“四区”、“四哥”;“移动MM”录音转写为“移动妹妹”等。
2.1.2 客户表达存在个性化差异
对于同一需求,由于客户的个性化表达的差异,存在录音文本关键信息的较大差异。例如,对于取消业务的诉求,客户的表述会有“关一下”、“关掉”、“不要了”、“退掉”、“停止”等多种个性化表达。
2.1.3 业务术语与自然语言差异
部分业务的标准化业务名称与客户来电口头表述有较大差异,甚至存在较大偏离。例如,“已开通收费业务”这一标准业务术语,客户的表达为“收费的业务”、“有些什么业务”、“开通了些什么”、“扣费的业务”、“月租”等。
2.1.4 区域性语言(方言)表达差异
2.1.5 多诉求对话
一通对话录音文本中,客户诉求可能会有多个。例如,客户表述“查询话费较高的原因”,从而衍生出“取消某些不需要的业务”;或者客户分别需要“取消彩铃”和“开通来电提醒”。
2.1.6 业务范畴变动频繁
通信行业面向客户提供的业务、产品(含营销活动)、服务并不是一成不变的,对应的业务标签每月、每周、每天都有可能出现新增或下线,所以客户交互信息也会频繁变化。
2.2 呼叫中心文本识别算法解决思路
基于录音转写、客户表达、区域方言、多诉求、业务变动等原因,通信行业的客户服务录音文本分析,具有典型的行业特征。目前比较热门的基于深度学习的文本识别算法,虽能够在有效的训练后达到较高的准确度,但由于其前期需投入大量训练数据,且对于新增标签反应滞后,不能完全满足通信行业呼叫中心对于客户录音文本分析的需求。于是,依赖于经验和语料库的基于统计学和概率性的语义分析策略相较来说,更适合那些内容范畴相对统一、模型迭代快速、业务术语较多的文本挖掘领域。算法需重点研究和解决:
2.2.1 文本完整性校验
录音文件转写为语音文本,由于以下因素可导致文本可用信息缺失:
5例硬膜下积液自行吸收,7例演变为慢性硬膜下血肿;前者的积液量少于后者[(26.4±14.6)mL vs(80.0±52.3)mL, P=0.002]。演变为慢性硬膜下血肿的7例患者中,5例因血肿厚度>1.5 cm、出现颅高压或神经功能障碍而进一步行钻孔引流术;钻孔手术平均于夹闭术后(9.1±3.8)个月(4~20个月)进行。进一步分析发现,硬膜下积液量越大,其演变为慢性硬膜下血肿的比例越高,慢性硬膜下血肿后须行钻孔引流手术治疗的比例也越高(表2)。
(1)通话录音本身业务元素缺失。例如,交互过程中的异常挂机。
(2)由于录音转写文本准确性问题,导致文本业务元素缺失。
2.2.2 分词规则与业务对应
(1)专业术语的识别。例如,“和彩铃”、“和多号”等业务名称,在分词过程不能分割为“和/彩铃”、“和/多号”,而应做为统一整体进行分词。
(2)客户化表述的识别。例如,客户需要办理“国际漫游”,但在交互过程的用语为:“出国上网”、“国际流量”、“港澳台流量”、“外国漫游”等。
(3)短语描述的识别。例如,“呼叫转移”表述为“把电话转接到别的手机上”。此类情况非字典字词,也非标准业务名词,但需在分词规则中进行词组的定义。
2.2.3 关键诉求判定
(1)在整通来话录音文本中,通常存在客户多诉求表达。例如,一次来话有查话费、查流量、办套餐等诉求。
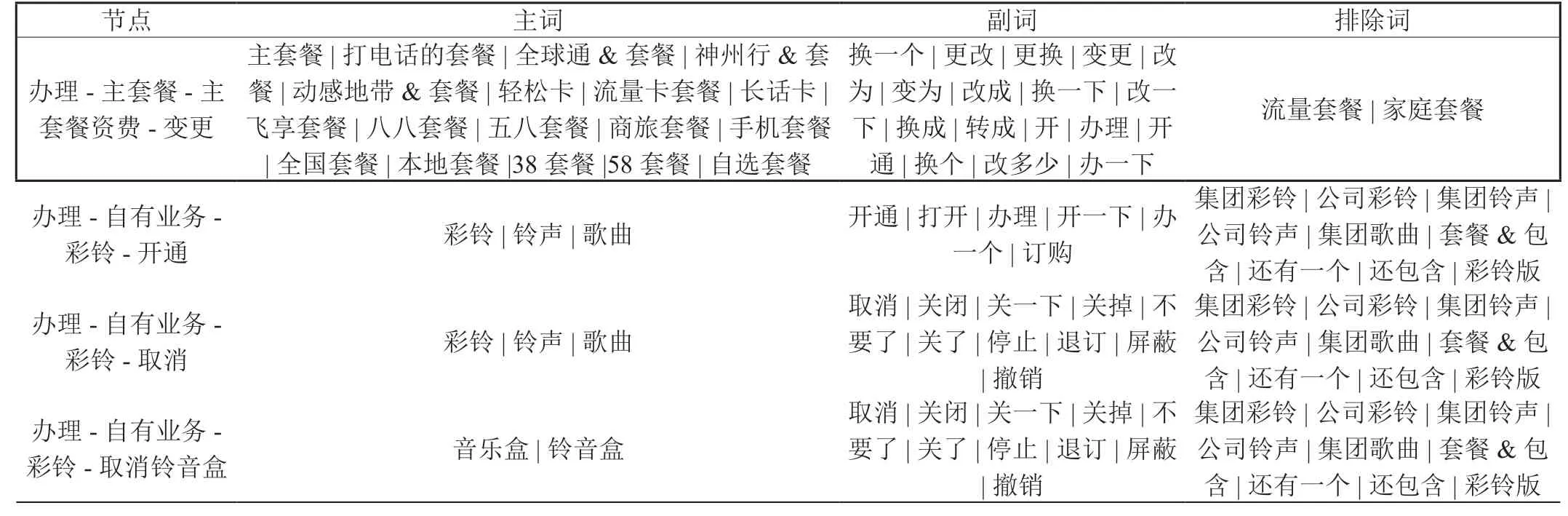
表1:文本识别语料库(样例)
(2)有客户诉求与业务定义存在语义缠绕的问题,例如,客户表述中出现“上不了网”,有可能是指手机流量上网问题、宽带上网问题、WLAN 上网问题,其由此产生的需求,有可能是开通相关业务,也有可能是投诉业务故障。
3 呼叫中心文本识别算法实现
3.1 建立文本识别语料库
如表1 所示。
3.2 文本识别算法流程
基于上述呼叫中心录音文件文本还原准确性、分词规则、语义分析、关键诉求判定等现实问题,本文提出“基于二次排序的Top-N 语义分析算法”,算法流程如图1 所示。
“基于二次排序的Top-N 语义分析算法”包括检测模块、获取模块和确定模块。其中:
检测模块,用于对录音文本(非结构化数据)进行完整性检测;
获取模块,用于当录音文本确定为完整的非结构化数据时,将录音文本与预存储的关键词进行匹配,获取与录音文本相对应的待确定标签;
确定模块,用于根据预设的匹配规则,在待确定的标签中确定与录音文本最终匹配的标签。
4 总结和展望
通过对真实录音文本的语义识别结果进行全量测算检验,本算法文对于通话时长低于60 秒的录音文本,识别准确率达到93.67%,识别准确率达到业界较高水平。算法中涉及的报错阀值、排序TOP 值均为配置参数,可根据实际情况进行调整,算法的流程化设计思想,也可支持在遇突发事件、文本内容较大变动、表述习惯改变的情况下,调整特殊节点,甚至快速优化算法流程,增减筛选环节,有效提高了算法对外部环境的适应性。
后续,该算法的应用和优化仍有一定空间。除了单纯文本内容外,将静音、音量、语速、声道等录音属性也加入语义分析模型,可支持捕捉性格特征、语境、情绪等更具体明确的语义内容。也可将本算法输出结果作为训练集,将无规则的深度学习算法和有规则的本文所述算法结合起来,开创探索新的算法迭代模式,实现语义判定内在算法的自主学习和优化。

图1:“基于二次排序的Top-N 语义分析算法”流程图
