个性化推荐系统综述
2020-02-03张宇航姚文娟姜姗
张宇航 姚文娟 姜姗

摘要:随着信息时代的不断发展,信息过载是目前互联网用户面临的一个严重问题,个性化推荐系统就是解决这一问题的重要工具。为了解国内对个性化推荐领域的研究现状与发展趋势,通过对相关文献进行收集处理并借用VOSviewer、Excel对发文量、发文期刊、发文作者、关键词进行现状分析,同时对个性化推荐系统的关键技术用户兴趣模型和推荐算法进行阐述介绍。最后指出了未来个性化推荐系统的挑战与研究重点。
Abstract: With the continuous development of the information age, information overload is a serious problem faced by Internet users. The personalized recommendation system is an important tool to solve this problem. In order to understand the research status and development trend of the domestic personalized recommendation field, through the collection and processing of related documents and borrowing VOSviewer and Excel to analyze the current situation of the volume of publications, publications, authors and keywords, and at the same time, the personalized recommendation system key technology user interest models and recommendation algorithms are presented. Finally, the challenges and research priorities of the personalized recommendation system in the future are pointed out.
關键词:个性化推荐;用户兴趣;推荐算法
Key words: personalized recommendation;user interest;recommendation algorithm
中图分类号:TP18 文献标识码:A 文章编号:1006-4311(2020)02-0287-06
0 引言
随着信息技术和互联网的发展,人们逐渐从信息匮乏的时代走入了信息过载的时代。在这个时代,无论是信息消费者还是信息生产者都遇到了很大的挑战:信息消费者,从大量信息中找到自己感兴趣的信息是一件非常困难的事情;对于信息生产者,让自己生产的信息脱颖而出,受到广大用户的关注,也是一件非常困难的事情。推荐系统就是解决这一矛盾的重要工具。推荐系统的任务就是联系用户和信息,一方面帮助用户发现对自己有价值的信息,另一方面让信息能够展现对它感兴趣的用户面前,从而实现信息消费者和信息生产者的双赢[1]。文章对国内个性化推荐领域的发展进行阐述,帮助读者了解个性化推荐的研究现状及发展趋势。
1 相关研究
一个完整的推荐系统主要由三个模块组成:用户建模模块,推荐对象建模模块和推荐算法模块[2]。其中推荐算法是整个系统的核心部分。
对于个性化推荐研究最早开始于上个世纪90年代,随着互联网发展,该项技术被逐步应用于不同行业。当简单引擎搜索结果并不能够满足用户对信息的需求时,路海明等人提出一种基于Agent技术的web主动信息服务的研究应用,利用bookmark中的信息,建立用户agent,实时跟踪用户兴趣改变,及时将用户潜在感兴趣的内容进行推荐[3]。这一类方法在一定程度上依赖与用户互动,如果用户没有添加url进入bookmark或者对于agent推荐的url不做评价,对其推荐精度有一定影响。
在电子商务中,个性化推荐帮助解决用户选购问题,大大推进电子商务进一步发展,这也对于推荐系统的推荐精度以及实时性造成一定影响。邓爱林通过改进推荐算法,提出了基于项目评分的预测IRPRec的协同过滤算法和基于项聚类的ICRec协同过滤推荐算法,有效缓解上述问题[4]。
近年来,上下文感知推荐系统成为新的研究领域,不同于一般的推荐系统,仅在基于用户-项目二元关系基础上进行推荐,而是考虑到上下文信息(如时间、位置、周围人员、情绪、活动状态、网络条件等等),在环境因素下,生成推荐,大大提高推荐的准确性[5]。
为了缓解推荐系统中的冷启动和稀疏性问题,一种社会化推荐方法被提出[6]。建立用户的社会关系网络图,通过用户之间的信任度,根据已有的兴趣模型,对新用户进行推荐。
2 数据来源与处理
2.1 数据来源
《中国学术期刊(网络版)》是世界上最大的连续动态更新的中国学术期刊全文数据库。文章以中国知网(CNKI)的中国学术期刊网络出版总库为数据源。以“个性化推荐”为主题,时间范围设置为2000年1月1日-2018年12月31日,剔除无关文献,共检索得到相关文献2604篇。
2.2 数据处理
VOS(visualization of similarities)viewer是在CWTS资助下开发完成的科学图谱工具,支持大规模数据处理。VOSviewer可以用于生成多种基于文献计量关系的图谱:如作者或期刊的共引关系图,关键词共现关系图。与其它可视化软件相比,其主要特点为图形化展现的方式较为丰富,显示清晰,使得文獻计量学的分析结果易于解释。文章利用VOSviewer可形象地对个性化推荐发展现状进行分析展示,以便得出有用结论供读者参考。数据处理具体操作步骤如下:①将在数据库中检索得到的文献以EndNote格式导出,由于VOSviewer无法识别由CNKI直接获取的所有文件格式,所以要将导出的.txt文件进行转换。②将得到的.txt文件导入到文献管理工具EndNote中,对文献进行粗略筛选,删去重复文章,将筛选后的文献选中以RIS格式导出,此时则变成VOSviewer可识别的文件格式。③将得到的RIS文献导入VOSviewer中,统计作者发文数和关键词数并进行相应的图形绘制得到可视化图谱。④借用Python程序,将得到的.txt文件转换为.xls文件,使用Excel对发文量和发文机构进行相关分析。
3 研究现状
3.1 发文量分析
2000年至2018年,在CNKI的中国学术期刊数据库中,关于个性化推荐的文献总量为2064篇(年度分布和变化趋势如图1所示)。如图所示,2000年~2018年,在个性化推荐领域发表论文数量逐年增高,大致呈现线性上升趋势。其中,自2009年后,年发文量均在100篇以上,2009年至2018年的发文总量是2000年至2008年发文总量的6.8倍。这种现象的出现,与2009年7月,我国首个个性化推荐系统科研团队北京百分点信息科技有限公司成立密不可分。在标榜着多人贡献的Web2.0时代,信息过载尤其明显,于是催生了一系列解决方法,人们对于个性化推荐的研究论文数量的逐年递增,也正说明国内对于信息过载解决方法的不断探索,个性化推荐系统受到了越来越多的关注和研究。
3.2 发文期刊分析
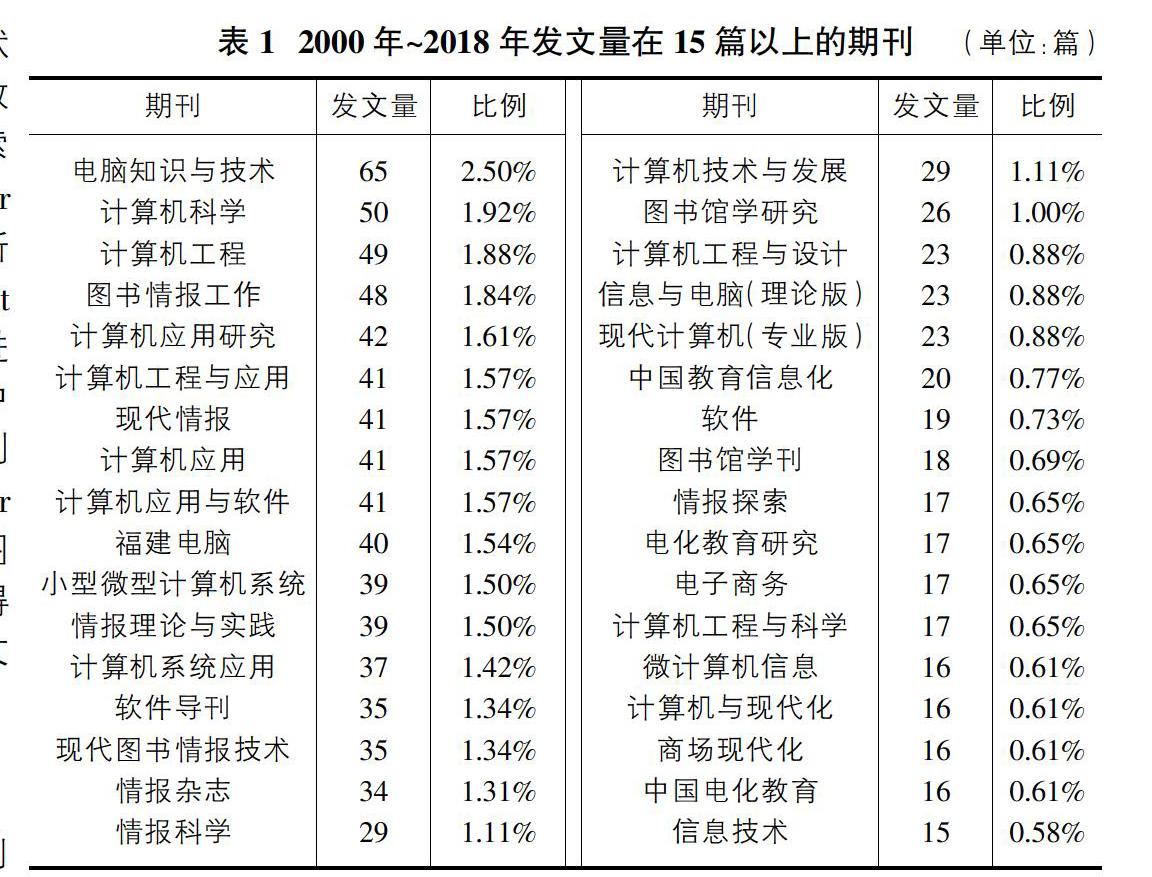
分析文献期刊来源可以了解到一个研究领域的核心关注群体所在。由分析结果可知,到目前为止,共有749种期刊发表了个性化推荐的相关论文。期刊种类大致属于计算机技术领域,占到了总体的90%以上。由表1可知《电脑知识与技术》、《计算机科学》、《计算机工程》、《图书情报工作》、《计算机应用研究》等为个性化推荐研究的热门期刊。在个性化推荐领域,国内发文高产前三名分别为:《电脑知识与技术》、《计算机科学》、《计算机工程》。其中计算机科学与计算机工程期刊均为核心期刊,在计算机中文核心期刊的影响因子分别为:0.61和0.492。由此可见,国内不少研究者一直都在关注着个性化推荐给信息过载带来的契机与变革。
3.3 作者分析
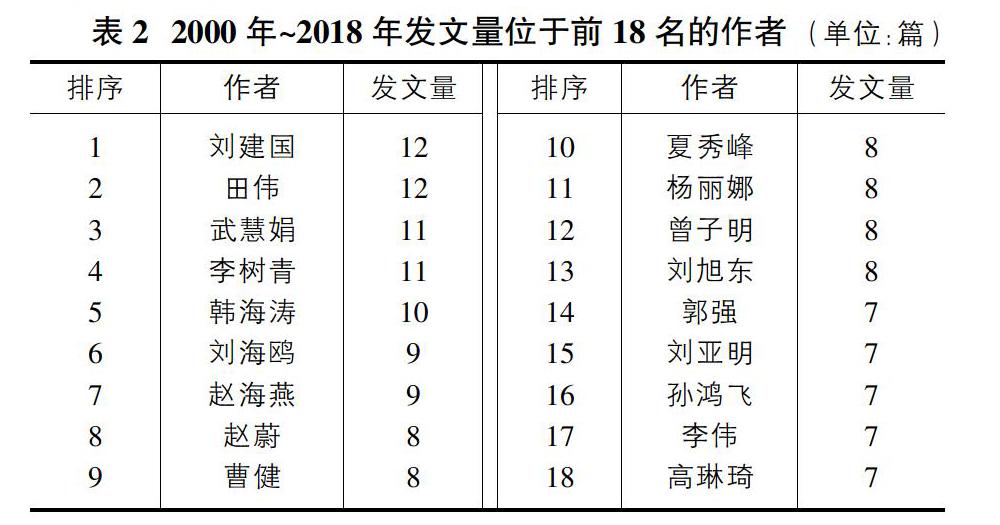
由图2可看出作者群呈现的一种分布状态,高发文作者之间具有强合作关系,合作群中的作者人数多且发文量多。代表作者是刘建国(12篇)和郭强(7篇),这两位作者不仅发文量多,并且由他们构成的群体也有着密切的联系。虽然在网络中,周涛、程学旗、张亮等人的发文量少,但他们所在的小群体通过他们与高发文作者所组成的合作群建立了间接的关联。以高发文作者为核心,合作群众作者人数少,在网络中不与其他作者群相连,代表作者有田伟(12篇)和韩海涛(9篇)。此外,分析可以发现,高产作者如:刘建国、李树青、田伟、武慧娟、韩海涛等人文献的主要产出重要集中在2015年以前。因此,除了继续支持关注他们的作品外,亦可以关注近几年来在个性化推荐研究领域新生的作者群体,这样更有利于推动个性化推荐研究的发展。
3.4 关键词分析
利用VOSviewer软件统计2000年至2018年刊发的2064篇文献,关键词出现总频次为3850次(词频在100次以上的见表3),关键词共现网络如图3所示。
从整体上看,关键词共现网络构成的词簇十分集中,大多数节点之间都存在直接的关联关系,这表明个性化推荐领域的相关论文关注的研究热点之间联系紧密,研究的系统性与集中度较高。个性化推荐首次出现在期刊中是2000年路海明、卢增祥和李衍达在《计算机科学》杂志上刊登的《基于多Agent混合智能实现个性化网络信息推荐》他们提出将单信息Agent的智能与多信息Agent合作形成的智能进行结合,形成混合智能,将有利于信息Agent智能水平的提高,提高个性化服务质量[7]。到2018年的2064篇文献,研究关注内容仍以个性化推荐的技术优化与实现为主,个性化推荐系统的推荐算法模块依旧是个性化领域的研究重点和热点。
4 用户兴趣模型
用户兴趣模型的准确性直接影响了个性化推荐结果的精确度,因此用户兴趣模型的优劣对个性化推荐至关重要。通过对相关文献的筛选,最终选取了81篇具有代表性的重点文献,并对这些文献进行系统梳理。文章将从获取用户偏好信息和用户兴趣建模两方面进行梳理和总结。
4.1 获取用户偏好信息
用户的偏好信息的获取方式主要有两种:显式获取和隐式获取。
显式获取:显式获取主要通过获取用户注册时主动填写的信息或者是用户对于特定网络资源的显式反馈;显式获取的用户偏好信息直接反应了用户对特定网络资源的兴趣描述,这种获取方法直接、简单,用户偏好信息的准确率和可用率较高。但这也增加了用户的负担,用户也有可能为保护个人隐私而不选择填写或填写虚假信息。用户的兴趣可能随着时间的推移发生改变,此时用户偏好信息需要手动更改,因此这一方法的准确性和及时性难以保证。
隐式获取:隐式获取主要利用web数据挖掘和其他数据挖掘技术用来获取用户的隐式反馈信息,例如用户页面浏览行为、内容,用户的眼动跟踪数据。隐式获取不需要用户参与,可以减少由用户参与带来的系统噪声,能够获得更多用户偏好信息。但因为不是用户主动填写的信息,这会导致得到的用户信息存在一定随机性和不确定性,造成用户偏好信息收集出现误差,而且隐式获取需要进行大量计算。
两种获取方式各有利弊,若两种获取方式综合应用能够得到更加准确、可用的用户兴趣偏好信息。因此一般情况下研究人员会选择同时应用两种方法。
4.2 用户兴趣建模
用户兴趣建模是进行个性化推荐的重要组成部分,用户兴趣模型的建模过程分为兴趣模型的建立和更新。
4.2.1 用户兴趣模型的表示
比较常用的用户兴趣模型的表示方法包括关键词列表法,主题法、基于本體论表示方法和基于向量空间模型表示法。其中基于向量空间模型表示方法是该领域经典和广泛应用的计算模型。关键词列表法是通过提取用户对资源的兴趣偏好的关键词来描述用户兴趣的模型。主题表示法只是以用户偏好信息的相关主题来表示用户兴趣模型。基于本体论表示方法是通过对本体的描述来表示用户的兴趣喜好的领域;基于向量空间模型表示方法是以文本内容中的关键字或主题作为向量,加权计算得出频率,选定权值高的前几个关键字或主题作为空间向量。
4.2.2 用户兴趣模型的建立
用户兴趣模型的建立是对面向算法的、具有特定数据结构进行的形式化描述[8]。国内外传统常用的建立用户兴趣模型方法包括加权矢量模型,层次结构模型、基于本体论和基于向量空间模型。其中最为广泛应用,最受欢迎是基于向量空间模型表示法,基于本体论的用户模型也被广泛应用。基于本体论的用户模型是基于向量空间模型的一种完善和扩充,这种用户模型相对于基于向量空间的用户模型能够获得用户更准确的偏好信息。以基于标签向量空间模型为基础,构建用户层次兴趣模型,首先根据用户的标签频率和其他相关数据,将用户兴趣分为具有两个层次的标签树形结构,分别为兴趣主题层,兴趣标签层[9]。这种模型不仅可以准确地反映各标签之间,标签用户之间的关系,也可以从中看出用户对于各主题的偏好。
4.2.3 用户兴趣模型的更新
由于用户兴趣并不是一直不变的,随着时间推移,用户兴趣会发生改变。例如产生新的兴趣,对原来的兴趣加强或减少,用户的某些兴趣会从最初的兴趣模型里剔除。同时有可能在获取用户初始偏好信息时因某些原因导致信息采集不准确。因此用户的兴趣模型需要在一定的时间周期内进行更新以保证个性化推荐的有效。目前比较常用的几种更新方法有:窗口控制法、信息增补法、遗传控制法、神经网络法[10]。
兴趣模型的更新可分为显式更新和隐式更新。显式更新会强制用户对目前的兴趣信息进行反馈,这种更新方式最为有效、直接,但由于会影响用户的一些正常浏览行为,因此使用范围很小。隐式更新通过跟踪用户浏览行为,搜索词和操作行为来获取用户兴趣。通过这些来获取最新的用户偏好信息来不断更新用户兴趣模型。这两种更新方式主要是根据用户偏好信息获取的不同方式进行区分。
以上是关于用户兴趣模型各个部分的简单介绍,上面介绍的用户兴趣模型并未考虑多个社交网站的信息整合和社交网路中其他中有用的知识源[11]。
5 推荐算法
在个性化推荐系统平台中,对相关推荐算法的挑选十分的重要通过阅读相关资料对下列四种个性化推荐算法进行分析:基于内容的推荐算法、基于协同过滤的推荐算法、基于网络结构的推荐算法、混合型推荐算法。
5.1 基于内容的推荐算法
基于内容推荐算法主要应用于文本推荐,最初应用在Fab系统中解决个性化推荐问题;而后逐步应用于音乐推荐系统,电子商务推荐系统、新闻推荐系统等,但仅从文本内容考虑个性化推荐,并不适用于图片、音频、视频等多媒体数据进行推荐。王嫣然等人将基于内容的推荐算法中应用在科技文献的推荐系统中,在传统的基于内容的推荐算法中,引入时间的权重函数和文献重要度的方法,解决了传统推荐算法无法考虑用户信息动态变化的问题,并且在一定程度上对于文献的质量进行区分[12]。利用用户浏览记录和购买的产品,不能给出较为明显项目分类时,容易导致预测推荐结果不能达到理想的目标,闫东东等人在传统的个性化推荐系统中,加入用户的特征文件,根据最终目标用户与项目间相似性进行推荐[13]。耿立校等人利用余弦值和匹配度值改进原有的内容过滤模型,进行推荐,能够有效提高运算效率和推荐精度[14]。
5.2 基于协同过滤的算法
协同过滤算法主要分为两类,一类是基于用户的协同过滤算法,另一类是基于项目的协同过滤算法。即使协同过滤算法目前被广泛应用于图片、音频、视频等数据来源的个性化推荐系统,但是仍然存在一些不可避免的问题,使其推荐准确度有待于进一步提高,如以下几点:
5.2.1 数据稀疏性
2018年零售商销售业绩63%的交易均来自于线上购物。在一些大型购物网站,例如淘宝在2018年双十一成交额就有2135亿元,而用户评价数目却远小于项目成交数目。缺少用户评价,容易导致用户-项目评分矩阵极度稀疏,进而影响推荐系统的质量。针对这一问题,解决方法有多种,最简单的是将一个固定的数值填入评分矩阵的为评分项,数值可以是评分均值或者众数[14]。在大规模数据库,这种方法就存在一定缺陷,容易使用户或者项目失去特性。邓爱林等人通过项目间相似性,预测未评分项目评分,计算用户间相似性[15]。周军锋等人利用条件概率提出一种优化算法,求解top-n集[14,16]。徐德智等人利用云模型的相似性度量方法,预测未评分项目的评分,解决数据稀疏条件下,用户之间共同评分项目少的问题[17]。贺怀清等人将Support Vector Regression与IBCF算法结合解决评分项目缺失的问题[18]。李远博等人依据主成分分析法本质是保留大部分方差的维度特征,去除项目空间中不明显的特征,从而实现降维[19]。
5.2.2 冷启动
当项目进入系统获得较少评价或从来没有被评价过,由于缺乏有效信息,而不能精确的推荐给某类用户,就属于新项目问题。当用户第一次进入某个社交媒体软件,系统没有记录过用户任何一次评价信息,缺少足够的信息去获取用户的兴趣爱好,则无法将用户划分到某一类中,就属于新用户问题。新项目和新用户问题,均属于冷启动问题。目前大部分系统通过让新用户注册时,在指定的类别范围中选取感兴趣的项目,将用户归分到某一类并进行推荐,这种方法对于用户可选择数目是有一定限制,并且只是一定程度上解决新用户问题,并没有解决新项目问题。孙小华利用平均数、众数和信息熵分别代替新项目预测值进行推荐[20]。郭艳红等人提出基于内容预测未被用户评价过的项目评分,过滤掉不准确的数据并产生推荐[21]。李改等人考虑项目特征与用户属性,从特征向量角度出发,运用基于矩阵分解的ALS-WR协同过滤算法解决冷启动问题[22]。上述几种方法,都是建立在拥有一些用户对项目的评分信息基础上优化算法,并不是完全针对一个全新项目(不存在任何一个用户对项目进行过评价),于洪等人结合项目属性和用户评价时间信息提出解决新项目冷启动问题的CUTATime个性化推荐算法[23]。随着技术革新,机器学习也逐步被运用于改进协同过滤算法,解决新用户和新项目推荐问题,肖文杰利用k-modes聚类算法将用户进行分类,根据新用户注册信息判断其所属类别,基于同类用户的评分信息对其进行推荐[24]。
5.2.3 实时性(一种对软件系统计算处理能力的设计指标)
大数据时代下信息爆发,用户和项目数据激增并且一直处于动态变化状态。传统的个性化推荐系统面对海量数据处理,运用knn在用户空间寻找目标用户最近邻居集是一个大工程,其运行效率也会大大降低。如何提高算法运行效率,是个性化推荐算法目前主要问题之一。目前,最常用的解决方案是利用聚类算法优化协同过滤算法,大部分聚类算法具有伸缩性较高,适用于数值型或混合型数据,时间复杂度较低等优点,能够在一定程度上提高推荐的效率。邓爱林等人运用K-Means聚类算法将项目按照相似性进行聚类,依据聚类结果中与目标项目最相似的聚类,产生top-n集[25]。张海燕等人基于项目的属性特征利用模糊聚类算法的等价关系产生模糊相似矩阵,对项目进行分类,然后与用户项目评分空间结合为目标用户推荐项目[26]。李涛等人提出一种基于用户聚类的协同过滤推荐算法,首先在离线时,根据已有用户数据信息处理后,得到用户之间相似性,运用聚类算法将其分类,然后,根据已有类别通过KNN寻找目标用户最近邻居集产生推荐[27]。上述方法均是基于项目或者用户间相似性进行聚类,没有将项目和用户结合聚类产生产生推荐。何建民根据用户和项目相似性利用K-Means聚类算法,将用户和项目分别进行聚类产生推荐[28]。关志芳等人利用加权 Slope One 算法对项目和用户聚类结果产生的类别进行预测产生推荐[29]。除了聚类算法,分布式算法也被逐步用于优化推荐算法,不仅在模型预测精度取得一定成效,也进一步提高推荐的实时性。李文海等人将分布式平台应用在电子商务的个性化推荐,设计出一种融合MapReduce和多种推荐技术的推荐模型,提高推荐系统运行效率[30]。
5.3 基于网络结构的算法
近年来,将网络结构的推荐算法应用于个性化推荐系统成为一个新的研究方向。这类算法优点是无需考虑用户和内容的属性特征,而把它们看成抽象的节点,利用其关系中所包含的信息。但是该算法在一定程度上仍无法解决冷启动问题。对于该领域研究,周涛等人基于用户-项目二分图提出一种资源分配的算法,本质是将目标用户没有选择过的项目按照其喜欢的程度进行排序并且把排名靠前的那些项目推荐给目标用户,该算法并没有有效解决冷启动问题[31]。吴效葵等人加入项目特征属性,通过项目间的相似性计算资源配额矩阵,与改进后的初始资源向量结合,形成最终的资源分配向量并进行推荐,在一定程度上解决新项目推荐的问题[32]。肖扬等利用加权的项目-用戶-标签三部图,在三部图网络模型基础上提出一种新的网络结构的推荐算法[33]。随着推荐系统研究深入,物理学逐步应用于推荐算法中,张子柯等人基于热传导的原理,将目标用户比较喜欢的项目看做温度较高的点,不喜爱的项目看做温度较低的点,推荐过程的本质就是平衡节点间的温度[34]。胡吉明等人在热传导算法基础上,提出一种与物质扩散通过加权方式结合的推荐算法[35]。不同于大部分算法推荐较为热门项目,张子柯,胡吉明等人的算法能适当地向用户推荐不够热门的项目[34-35]。
5.4 基于混合型推荐的算法
单一推荐算法有各自的优点,但也存在一定缺陷。基于内容推荐算法利用产品内容信息进行推荐,对大量信息处理,容易降低推荐的实时性,而协同过滤算法长期以来存在稀疏性、冷启动等问题。为了更好解决上述问题,一种混合型推荐的算法成为新的研究方向,将不同算法结合,优势互补,避免缺点存在。混合型推荐算法,可以通过以下方式结合:加权、场景切换、结果混合与重排序、特征组合等等。具体混合模型如下:
①独立算法相互结合的推荐系统,分别单独使用协同过滤算法、基于内容或基于网络结构的推荐算法,再将几个算法的预测结果混合进行推荐。混合方法主要分为两种,一是将预测结果线性组合,二是设定标准,将推荐结果进行对比,选择评价较高算法下的推荐结果。曹毅等人分别利用内容过滤和协同过滤算法得出的预测推荐结果,进行加权求和,形成最终的推荐[36]。DailyLearner系统依据算法可信度,对预测结果进行选择。
②基于一种推荐算法,将用户-项目评分空间未评分项目进行预测,在新的评分矩阵上使用另外一种推荐算法,产生推荐结果。郭艳红和曾艳等人,基于内容推荐算法,对用户-项目未评分项目进行填充,在修改后的评分矩阵上,运用协同过滤算法产生推荐[21,37]。
③独立推荐算法中,融入其它的推荐算法。李忠俊等人通过协同同过滤算法求出目标用户最近邻居集,再利用内容过滤算法滤去可信度低的邻居进行推荐[38]。覃容等人提出一种基于协同过滤和内容的用户需求混合推荐算法,利用用户的特征,通过内容过滤算法寻找目标用户相似性最高邻居集,运用协同过滤算法产生推荐结果[39]。
6 结束语
个性化推荐技术虽已进入了成熟阶段,但依旧面临着很大的挑战,如:数据稀疏性、冷启动问题、大数据处理实时性问题、多样性问题、推荐系统效果评估等,如何解决这些问题是研究者需要关注的热点。随着互联网发展,近年来,人们对于推荐系统研究热情更加高涨。人工智能时代,深度学习的应用、知识图谱的应用、强化学习的应用、用户画像和可解释推荐将会成为如何搭建推荐系统未来研究热点和方向。
参考文献:
[1]戴世超.基于图计算模型的矩阵分解并行化研究[D].浙江理工大学,2016.
[2]蒋新宇.基于Spark平台分层协同过滤算法研究[D].河北工业大学,2016.
[3]路海明,卢增祥,徐晋晖,等.基于Agent技术的个性化主动信息服务[J].计算机工程与应用,1999(6):12-15.
[4]邓爱林.电子商务推荐系统关键技术研究[D].复旦大学,2003.
[5]王立才.上下文感知推荐系统若干关键技术研究[D].北京邮电大学,2012.
[6]孟祥武,刘树栋,张玉洁,等.社会化推荐系统研究[J].软件学报,2015,26(6):1356-1372.
[7]路海明,卢增祥,李衍达.基于多Agent混合智能实现个性化网络信息推荐[J].计算机科学,2000(7):32-34.
[8]周雪芳.个性化推荐系统用户偏好获取及兴趣建模[J].知识经济,2012(18):106.
[9]秦勤.基于用户标注兴趣模型的个性化信息推荐研究[D].山西医科大学,2018.
[10]熊回香,杨雪萍,高连花.基于用户兴趣主题模型的个性化推荐研究[J].情报学报,2017,36(9):916-929.
[11]张珏,杨振华,王世琪,等.社交网络大数据环境下的用户兴趣层次化模型研究[J].教育观察(上半月),2016,5(8):127-129,132.
[12]王嫣然,陈梅,王翰虎,等.一种基于内容过滤的科技文献推荐算法[J].计算机技术与发展,2011,21(2):66-69.
[13]闫东东,李红强.一种改进的基于内容的个性化推荐模型[J].软件导刊,2016,15(4):11-13.
[14]耿立校,晋高杰,李亚函,等.基于改进内容过滤算法的高校图书馆文献资源个性化推荐研究[J].图书情报工作,2018,62(21):112-117.
[15]邓爱林,朱扬勇,施伯乐.基于项目评分预测的协同过滤推荐算法[J].软件学报,2003(9):1621-1628.
[16]周军锋,汤显,郭景峰.一种优化的协同过滤推荐算法[J].计算机研究与发展,2004(10):1842-1847.
[17]徐德智,李小慧.基于云模型的项目评分预测推荐算法[J].计算机工程,2010,36(17):48-50.
[18]贺怀清,计瑜,惠康华,等.一种基于稀疏分段的协同过滤推荐算法[J].现代电子技术,2019,42(9):90-94.
[19]李远博,曹菡.基于PCA降维的协同过滤推荐算法[J].计算机技术与发展,2016,26(2):26-30.
[20]孙小华.协同过滤系统的稀疏性与冷启动问题研究[D].浙江大学,2005.
[21]郭艳红,邓贵仕.协同过滤系统项目冷启动的混合推荐算法[J].计算机工程,2008,34(23):11-13.
[22]李改,李磊.一種解决协同过滤系统冷启动问题的新算法[J].山东大学学报(工学版),2012,42(2):11-17,44.
[23]于洪,李俊华.一种解决新项目冷启动问题的推荐算法[J].软件学报,2015,26(6):1395-1408.
[24]肖文杰.一种基于k-modes的冷启动问题解决算法[J].福建电脑,2018,34(8):28-29,78.
[25]邓爱林,左子叶,朱扬勇.基于项目聚类的协同过滤推荐算法[J].小型微型计算机系统,2004(9):1665-1670.
[26]张海燕,丁峰,姜丽红.基于模糊聚类的协同过滤推荐方法[J].计算机仿真,2005(8):144-147.
[27]李涛,王建东,叶飞跃,等.一种基于用户聚类的协同过滤推荐算法[J].系统工程与电子技术,2007(7):1178-1182.
[28]张娜,何建民.基于项目与客户聚类的协同过滤推荐方法[J].合肥工业大学学报(自然科学版),2007(9):1159-1162.
[29]关志芳,孟海东.融合用户聚类与项目聚类的加权SlopeOne算法[J].控制工程,2018,25(7):1297-1302.
[30]李文海,许舒人.基于Hadoop的电子商务推荐系统的设计与实现[J].计算机工程与设计,2014,35(1):130-136,143.
[31]Zhou T, Ren J , Medo, Matú?, et al. Bipartite network projection and personal recommendation[J]. PHYSICAL REVIEW E, 2007, 76(4):46115-0.
[32]吕善国,吴效葵,曹义亲.基于网络结构的推荐算法[J].实验室研究与探索,2012,31(7):278-280,368.
[33]肖扬,王道平,杨岑.基于三部图网络结构的知识推荐算法[J].计算机应用研究,2015,32(2):386-390.
[34]张子柯,周涛,张翼成.Tag-aware Recommender Systems: a State-of-the-art Survey[J]. Journal of Computer Science & Technology, 2011, 26(5): 767-777.
[35]胡吉明,林鑫.基于热传导能量扩散的社会化小众推荐融合算法设计[J].情报理论与实践,2016,39(4):119-123.
[36]曹毅,贺卫红.基于用户兴趣的混合推荐模型[J].系统工程,2009,27(6):68-72.
[37]曾艳,麦永浩.基于内容预测和项目评分的协同过滤推荐[J].计算机应用,2004(1):111-113.
[38]李忠俊,周启海,帅青红.一种基于内容和协同过滤同构化整合的推荐系统模型[J].计算机科学,2009,36(12):142-145.
[39]覃容,陈建峡.基于协同过滤和内容的用户需求混合推荐算法[J].企业技术开发,2018,37(2):67-69.
