Matlab平台下水书文字特征提取与分类方法实现研究
2020-02-03丁琼
丁琼
(贵州工业职业技术学院 贵州省贵阳市 550008)
水族是我国五十六个民族中拥有自己传统文字的十七个民族之一,其文字被称为“水书”。水书与纳西族的东巴文一起被誉为象形文字的活化石,然而目前对水书的研究依然还处于手抄翻译及抢救整理阶段,所以完成水书文字的机器识别能够帮助相关学者研究水族的社会历史宗教文化及进一步的研究水书的精髓。
图像特征提取是指从对象本身获取各种对于分类有用的度量或属性。按特征提取所得的特征向量给每个对象赋予一个类别标记,得到n 类分析样本,同一类别的样本具有类似特征。
1 水书字符特征
字符特征提取是文字识别的第一步,通过人工提取待分类图像特征放入常用分类器(如SVM、决策树,随机森林)中进行分类,得出各类的概率值,从而判断出待分类图像属于哪一类。对于字符识别而言,提取的特征包括:区域特征、灰度特征、灰度值和灰度投影,以水书中的四个字符为例,我们提取出的特征值如表1 所示。
由于水书文字属于象形文字,为非标准化文字,在所收集的水书样本中,几乎都是手写的水书资料,同一个字不同的人写出来差别可能很大,这对字符特征提取与分类算法提出了较高的要求。
2 基于MLP神经网络模型的水书文字特征提取与分类
自九十年代以来,基于反向传播学习的多层感知器MLP 遭遇了支持向量机的强劲竞争,然而近年来,由于深度学习的广泛应用,MLP 又再次得到了关注。作为典型的前馈网络,MLP 信息处理方向为输入层到各隐层,各隐层再到输出层,MLP 神经网络模型如图1 所示。
隐含层节点数,隐含层到输出层的连接权值和输出层的阀值是MLP 神经网络需要确定的参数。每个神经单元和输入值进行权重相乘:
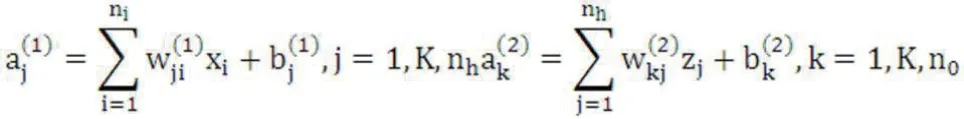
相乘的结果作为隐藏层结果:
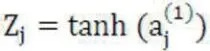
输出结果为:
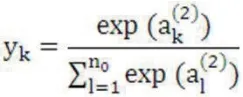
我们尝试人工提取了水书文字中6 个字符的特征值,在Matlab中实现三层神经网络对这6 个水书字符的识别。首先分割出这6 个水书字符,即分为6 个类别,由于每个类别只有一个样本,故而需要样本的扩充,利用每个类别的第一个样本,对其进行旋转、平移、腐蚀膨胀效果、高斯噪声,椒盐噪声等等不同操作使得一个样本生成制定大小和数量的多个样本,代码如图2 所示。
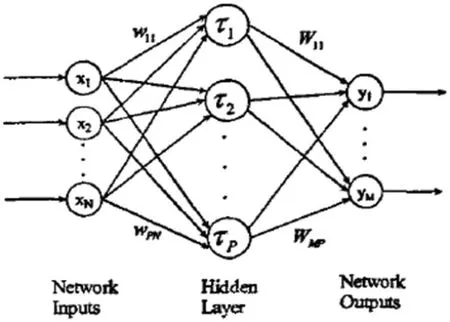
图1:MLP 神经网络模型

图2:定义扩充字符样本并生成矩阵x 的函数picTovec()
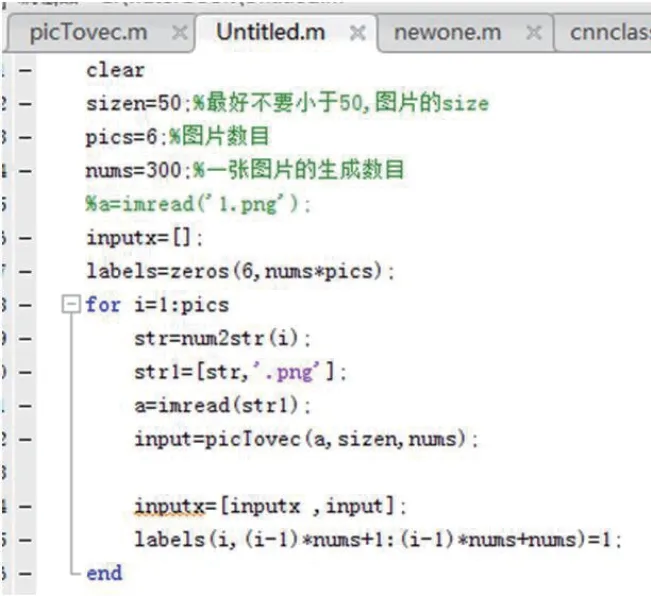
图3:使用picTovec()函数处理6 个字符样本
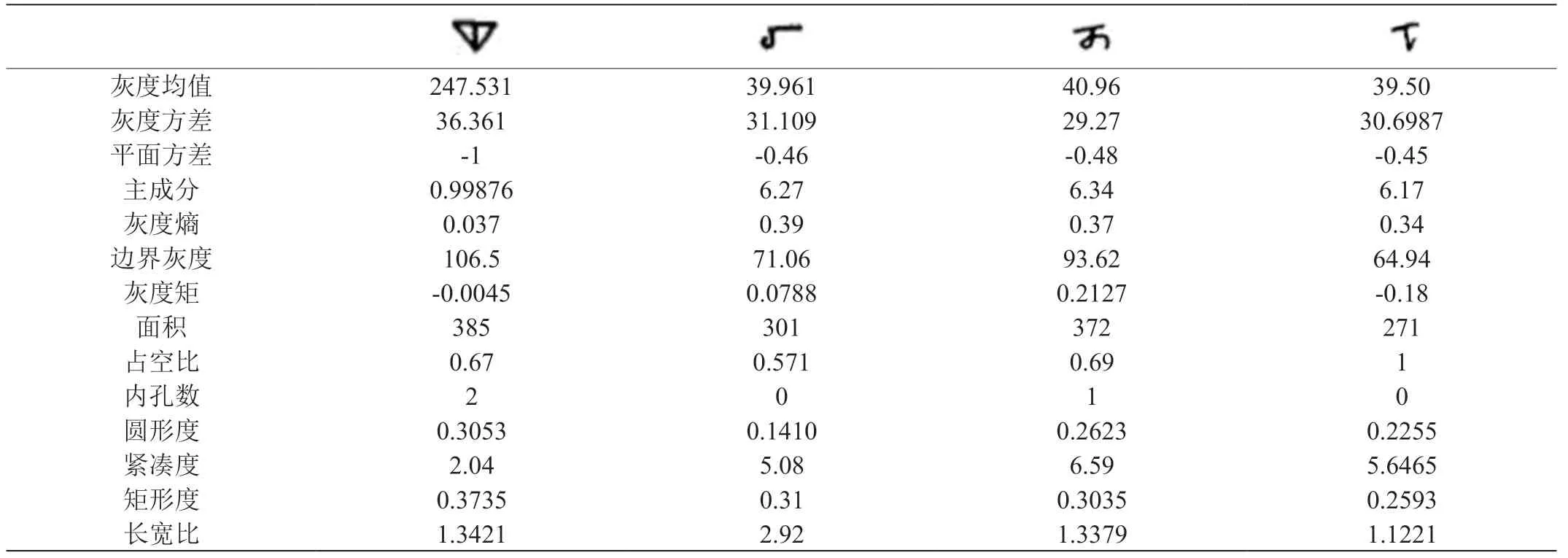
表1:水书字符特征值示例
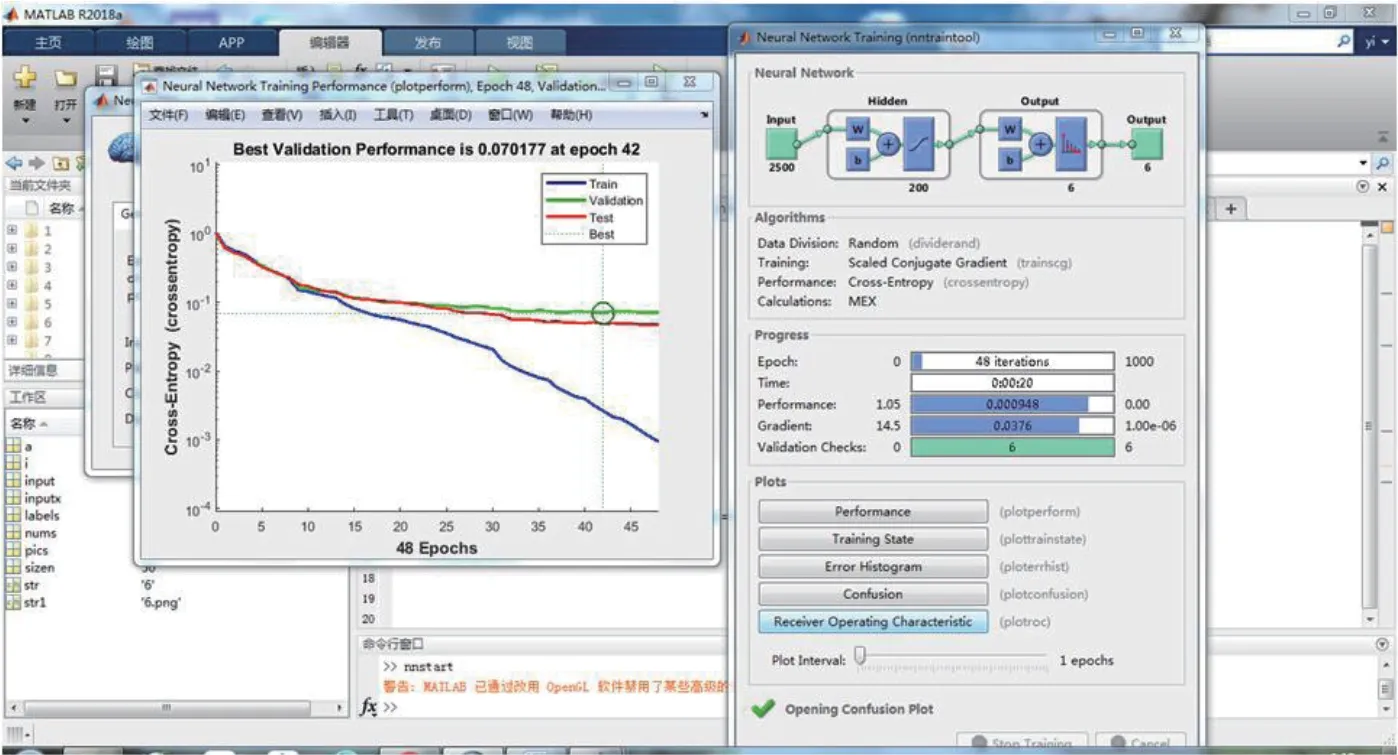
图4:训练结果
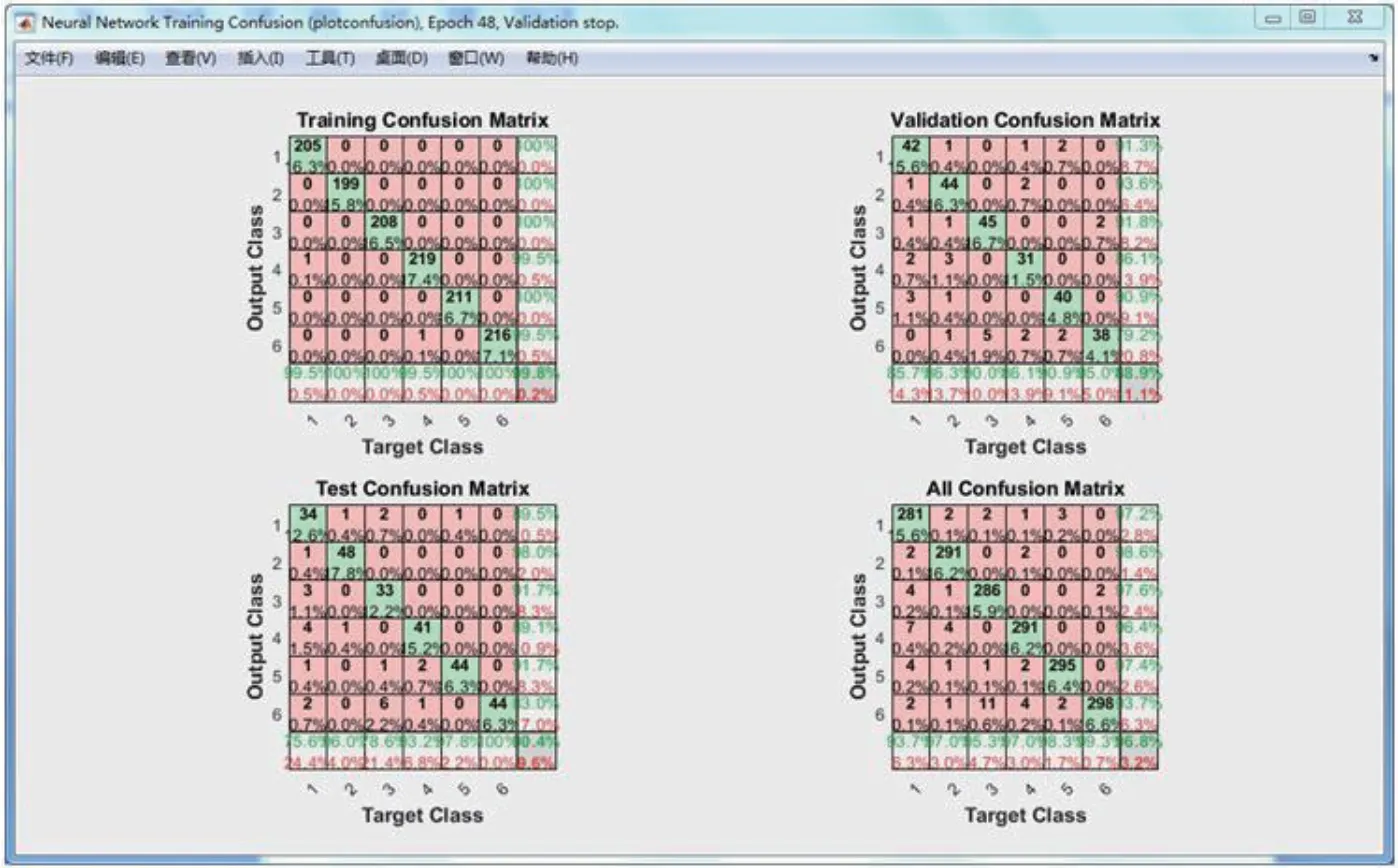
图5:训练状态
以上将一个图片变成了sizen*sizen 行nums 列的矩阵x,其中每一列为一幅图片的按列展开。然后再将六张图片都用函数picTovec()生成矩阵,并且将六个矩阵横向拼接。同时生成对应的labels,其每一列采用one-hot 编码对应于图片的类别,其代码如图3所示。
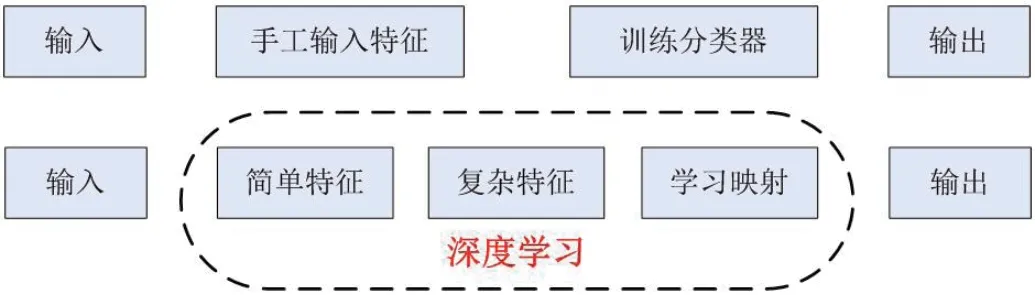
图6:机器学习与深度学习模型对比

图7:建立CNN 网络

图8:设置训练参数

图9:训练网络和测试网络
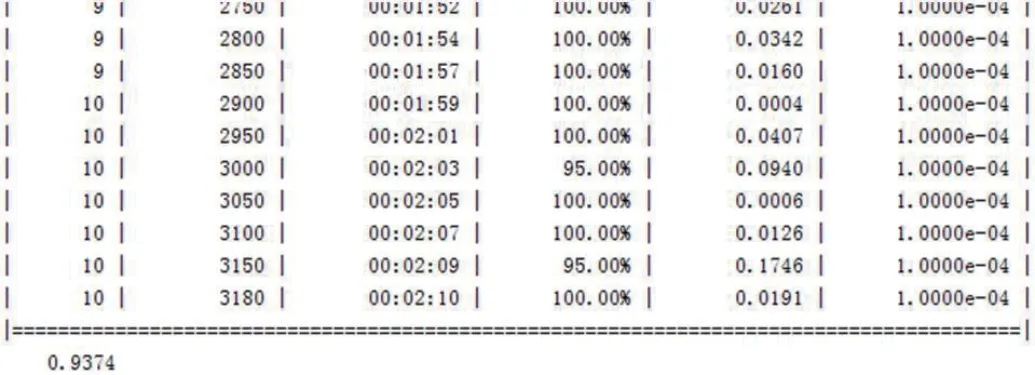
图10:十次迭代后测试结果
以上得到了输入数据Inputx,和对应的labels。Inputx 的每一列为一个50*50 的图像的展开,每一类别生成了300 张图,共有6个类别,所以有1800 列,对应的labels 也是1800 列。
在命令行输入nnstart,在出现neural network 窗口,选择第二项Pattern Recognition app,即模式识别和分类应用;点击next,将输入选择为Inputx,
targets 选择为labels,表示神经网络的输入和对应的标准输出;后续将number of hidden neurons 设置为200,其余采用默认设置。三层神经网络对6 个类别、1800 个样本的水书字符进行训练,训练得到结果如图4 所示。
可以看到Matlab 自动在48 次迭代时停止训练,此时validation的loss 是最小的,如果继续训练,train 的loss 虽然会变小,但validation 的loss 变大证明已经产生过拟合现象了。
点击training state,发现在训练集上准确率为99.8%,但在测试集上准确率为90.4%,如图5 所示。
此训练状态说明该三层神经网络已经出现了一定的过拟合。其原因在于我们的样本较为单一,且网络结构只有一层隐藏层,其泛化能力不足。
3 基于CNN模型的水书文字特征提取与分类
为了解决MLP 网络泛化能力不足的问题,我们引入了CNN 网络模型。
作为一种特殊的深层神经网络模型,卷积神经网络(CNN)是将BP 和深度学习网络相结合产生的一种新型网络,它可对旋转、倾斜、平移等变形保持高度不变性。近年来,CNN 模型的深度神经网络就获得了业界的关注,成为图像和视频深度学习的最流行算法之一,CNN 模型下的深度学习与普通的机器学习区别如图6 所示。
CNN 结构利用了图像的空间信息,增强了图像中的特征,同时,由于共用权值,大大减少了参数量,使得CNN 结构在训练时更能减少过拟合现象,提高了模型的泛化能力。在验证CNN 网络究竟能否解决MLP 网络在水书字符识别过程中所表现出的泛化能力不足问题时,我们用Matlab 创建一个简单的CNN 网络,对水书字符进行识别。
首先需要准备数据集,选用17 个水书字符做分类,将每一个字符扩充为500 个,存放在对应文件夹下,将图片保存为50*50*1的指定格式,做成待训练的数据格式并划分训练集与测试集。然后建立网络,代码如图7 所示。
在这里只建立了一层卷积网络,卷积核尺寸为3*3,数量为20个,经过relu 激活函数后进行maxpooling,继而接入全连接层进行分类。训练参数设置代码如图8 所示。
最后训练网络并显示准确度,具体如图9 所示。
在10 个epoch 后得到准确度为93.74%,具体如图10 所示。
考虑到该CNN 网络结构较为简单,且分类目标也仅为17 个,相比于MLP 网络对6 个字符分类的准确率90.4%,此结果表明使用了CNN 结构对分类性能有较大的提升。同时,对训练的超参数的修改和生成样本的改进还可以使准确率进一步提升。
一般来说,较大的网络结构需要较大的数据量和较长的训练时间,我们可以选择在预训练好的基础网络上进行调整,即选择一个合适的训练好权值的网络,改变其全连接层的结构,利用前面的权值作为初始值接着训练。
4 结束语
人工提取特征是传统机器学习方法的问题所在,它将直接影响最终分类结果的效果。CNN 模型的引入可以解决普通神经网络在水书字符识别过程中所表现出的网络泛化能力不足问题,提高水书文字识别系统的识别率。
