基于3A-RCNN网络的说话人识别研究
2020-02-03李建文赵统军
李建文 赵统军
(陕西科技大学电子信息与人工智能学院 陕西省西安市 710021)
1 概述
说话人识别也叫声纹识别,是根据说话人的语音判断其身份的技术。由于每个人在说话时使用的发声器官,如声带、口腔、舌头、牙齿、口腔、鼻腔等在尺寸和形态方面有着生理上的不同,并且每个人说话时对于这些器官的使用程度也有着习惯上的差异,这些特点使得每个人的语音都有着明确的个人信息。说话人识别的任务就是提取语音中说话人特征,以此来区分不同说话人,达到识别说话人的目的。
在早期,说话人语音数据不足,计算机性能有限,传统的GMM-UBM 模型[1],对说话人身份进行建模,先使用大量的非目标用户数据训练UBM,再利用MPA 自适应算法和目标人数据更新局部参数,建立说话人模型。该模型一般选择经过预加重、分帧、加窗、傅里叶变换等步骤获得的MFCC 特征向量作为输入。后来出现了特征更加紧凑的I-vector 矢量[2],用来表征说话人特征。
随着计算机性能的提升,深度学习也开始在特征提取方面显示出优势,最开始Google 提出d-vector 特征向量[3],将语音信息输入DNN,将最后一层的数据作为特征用于代替之前的I-vector,开启了深度学习时代。DNN 的使用更加促进了深度学习网络的应用,之后出现了性能更好的x-vector[4]。而随着在图像处理领域有着良好效果的卷积神经网络CNN 的加入,包含更多信息的梅尔语谱图也更加适合作为语音的特征输入,有人尝试使用混合CNN 网络[5]提取特征,结合LSTM[6]。不过CNN 在增加过多深度的同时会引起梯度爆炸或消失的现象,随后出现了基于ResNet[7]的改进ResCNN[8],通过使用残差结构,使得卷积网络模型设计更加多层数的同时,避免出现梯度爆炸等现象。在图像处理领域中,Attention注意力机制[9]提出了针对重要信息突出的想法,把任务中需要的特征信息进行强调,不需要的其他信息进行抑制。有人尝试将传统TDNN[10]中加入注意力模块,提升了传统模型的效果。Google 也在注意力机制上进行了探索,用于对上下文相关信息的LSTM[11]模型进行改进。之后也出现了一些权重分配的其他方案[12,13],尝试与其他传统模型进行结合[14,15],但仍未将语音信息中说话人相关信息充分提取。
目前注意力机制被运用在其他领域居多,在运用时只在单一维度进行使。在说话人识别中也未能进行深入探索,因此,本文提出了3A-RCNN 网络模型,运用注意力机制在通道维度、时间维度、频率维度三个维度进行权值自分配,结合深度残差CNN 网络对特征的充分提取能力,从中筛选出说话人身份信息。
2 模型基本架构
2.1 通道维度注意力机制
在卷积神经网络模型提取说话人特征时,对于卷积核提取出来的通道空间特征,总是等权重的进行传递,而实际中不同卷积核提取出不同通道,包含的身份特征信息并不相同。为了能加深重要权重通道的影响力,本文提出,将通道维度注意力机制引入卷积模型的残差结构中,通过对提取出的通道空间进行权重分配,使得更重要的空间特征获得更高的权重。由于神经网络的卷积核个数通常较大,为了提高模型的泛化能力,所以通道维度的注意力机制使用较为复杂的设置方式,同时进行全局平均池化和全局最大池化,之后的时间和频率维度注意力机制则使用较为简洁的设置方式。引入的注意力机制框架如图1 所示。

图1:通道注意力机制

图2:时间注意力机制

图3:频率注意力机制

表1:3A-RCNN 参数设置

表2:不同残差块个数对模型的影响

表3:不同模型性能对比
通道维度注意力机制连接在传统残差结构的后面,以残差结构作为输入。输入的特征图为其中M 表示输入的特征图,F 表示频率维度,T 表示时间帧数,C 表示通道维度,表示学习到的通道维度权重。
首先,残差块输入的特征图M 分别输入Globalaveragepooling层和Globalmaxpooling 层,得到两个维度为通道维度C 的特征图,之后并列叠加,维度变为(2,C),继续传入Dense 层,通过Relu激活函数进行激活,再传入Dense 层,之后将通道维度求和并输入Softmax 激活函数进行激活,通道权重映射在0 到1 之间,Softmax激活函数公式为:

其中ei代表第i 个通道的权值,Si就是第i 个通道在所有通道C 中的权重,激活之后就得到表示通道权重的之后将特征图M 各个维度与通道权重Ac相乘,得到经过通道权重分配的新特征图M1,通道维度注意力机制运算公式如下:

将计算出的特征图M1向后传递到下一个处理单元。
2.2 时间维度注意力机制

图4:残差结构
语音信息相比于其他数据,特殊点在于具有时间维度,不同的时间帧中包含的说话人之间的差异信息,为了增加特定时间帧的权重,本文提出将注意力机制作用于时间维度,具体框架如图2 所示。
时间维度注意力机制连接在通道维度注意力机制后面,输入为特征图M1,时间注意力机制运算过程如下:
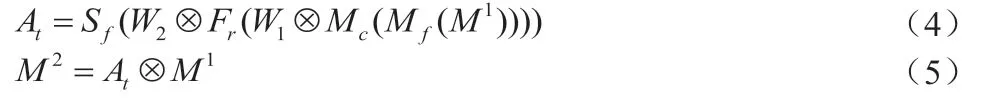
其中,Mf()和Mc()分别表示在特征维度和通道维度计算平均值的过程,表示学习到的时间维度权重,其余符号意义和公式(2)相同。
将计算出的特征图M2向后传递到下一个处理单元。
2.3 频率维度注意力机制
对于不同频率的特征,同样需要进行权重分配,本文提出将特征注意力机制作用于频率维度,具体框架如图3 所示,运算过程如下:
频率维度注意力机制连接在时间维度注意力机制后面,输入为特征图M2,频率注意力机制运算过程如下:

其中,Mt()表示在时间维度取平均值的过程,表示学习到的频率维度权重,其余符号意义和公式(2)相同。
计算出特征图M3,完成权重分配。
2.4 3A残差结构
在ResNet 中,残差块可以有效解决深层网络的梯度消失问题,具有强大的特征学习能力,图4(a)为传统的残差结构,图4(b)为本文提出的3A 残差结构。
输入数据经过原始的残差结构后,连接上文提出的3A 残差结构,这样会让每次残差结果都进行了3A 注意力的权值分配。3A 残差结构如图4 所示,不同层的残差结构相同,参数不同。
3 3A-RCNN网络模型
3.1 网络结构
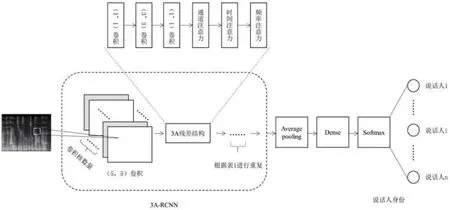
图5:3A-RCNN 网络结构

图6:准确率和损失值随迭代次数变化
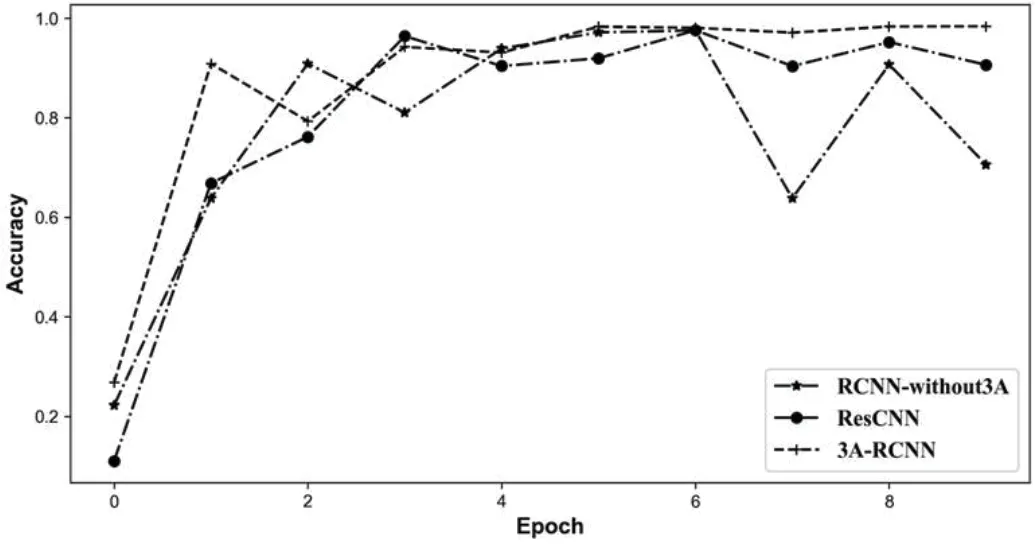
图7:不同模型准确率随迭代批次的变化

图8:不同模型损失值随迭代批次的变化
基于3A-RCNN 网络的声纹识别模型如图5 所示,网络的输入端使用的是声纹识别中常用梅尔语谱图,不仅保留了足够多的说话人身份信息,又能模拟人耳将信息进行了过滤,以图片的形式输入神经网络中,其大小为128×376,128 为频率维度,376 为时间维度,图中明亮程度代表能量大小,能量越大,亮度越大。
当数据进入3A-RCNN 网络,按照表1 所示,先进入conv64卷积层,卷积核大小为(5,5),卷积核个数为64,步长为(2,2),得到特征图X,之后进入3A_01 残差结构,其中包含4 个3A 残差块,每个3A 残差块运算过程见第1 节。之后按照表1 后续的层级设计和参数设置依次向后传递,最终将提取出的特征进行average pooling,再输入全连接Dense 层,得到最终的说话人特征。
最后,将说话人特征输入Softmax 分类器中进行分类,Softmax分类器的计算如下:
假设所有输入语音数据有n 个说话人,对于给定某条语音x,每一个说话人类别j 的输出概率值为p(y=j|x),用n 个向量表示n 个说话人输出概率值,则Softmax 函数为:

其中,hθ(x)为Softmax 分类的输出,θ 为模型参数,x 为输入的某条语音这一项对概率分布进行归一化,使得所有说话人概率之和为1。
3.2 损失函数
本文对输入数据的标签进行独热编码,损失函数为交叉熵损失函数,其表达式为:
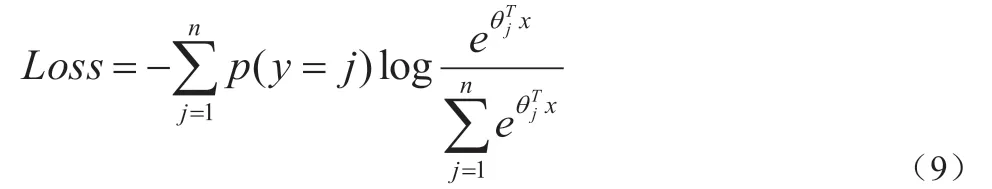
其中p(y=j)表示某个数据真实标签y 中属于第j 个说话人的概率,表示数据的预测标签在属于第j 个说话人的概率。
4 实验与比较
4.1 实验环境
本次实验所使用的计算机配置如下:处理器型号为Intel (R) Core (TM) i5-9600KF CPU @ 3.70 GHz;内存大小为16GB;操作系统为Windows10 专业版64 位操作系统;GPU 为GeForce RTX 2070s;深度学习开发平台为TensorFlow 2.0.0。
4.2 实验数据
本次实验所使用的数据集为Free ST Chinese Mandarin Corpus,该数据集为免费的公开中文数据集,其中包含855 位说话人,每人包含120句语音,每句语音时长2到8秒不等,总共有102600句语音,语音采样率均为16000Hz,语音均为标准普通话,语音清晰。本文首先将该数据集中的语音进行去除静音操作,之后使用截取固定3秒钟的语音片段,再将语音数据提取梅尔语谱图作为模型的输入,维度大小为128×376。在实验中,划分数据集中的80%作为训练集,20%作为测试集,两组数据相互不包含。
4.3 评价指标
本文使用在说话人识别中常用的准确率ACC(accuracy)和用于描述真实值和预测值差别的损失函数Loss(Loss function),其中损失函数Loss 的计算公式如公式(9)所示,准确率公式如下:

其中,TPj表示第j 位说话人中分类正确的个数,FNj表示第j位说话人中分类错误的个数。准确率越高,分类器效果越好,损失值越小,预测值与真实值越接近,效果越好。
4.4 3A残差块深度性能分析
实验测试中发现,不同深度的选择对模型的性能有不同程度的影响,为了使模型达到最佳效果,实验对比了不同深度的3A 残差块的性能差异,在模型训练完成后,记录模型在测试集上的损失变化情况,实验结果如表2 所示。
从表2 中可以看到,随着残差块个数的增加,模型收敛后的平均准确率会逐渐上升,最小损失值也会不断下降,其中每个残差块数量为4 时,效果达到98.0%,损失达到0.061,达到最优。
4.5 3A残差结构提升分析
为了验证3A 残差结构带来的提升,本文将提出的模型与不加入3A 残差块的原有RCNN 模型进行对比,通过50000 次迭代,观察两个模型的收敛速度与性能。迭代结果点数有50000 个,为了便于显示,将显示数据进行平滑处理,便于进行观察,结果如图6 所示。
图6 表示3A-RCNN 和不增加3A 残差块的RCNN 两个模型随着网络迭代次数变化在训练集上的损失值变化情况和两个模型随着网络迭代次数变化在训练集上的准确率变化情况。从图中可以看出,3A-RCNN 模型在收敛速度上明显快于RCNN 网络模型,在迭代大约达到11000次之后,3A-RCNN开始收敛,损失值稳定在0.044左右,准确率也稳定在98.9%,而原本的RCNN 则需要在迭代约20000 次后才趋于稳定,说明使用3A 残差块的卷积网络能够更好在更短的时间内提取出相应的身份信息,从而在更少的训练次数下获得更好的结果。
而在模型的性能提升上,本文将不同模型在相同测试数据集上的表现进行展示,与3A-RCNN 模型进行对比,结果如图7 图8 所示。
可以看出,没有注意力机制的RCNN 网络,波动幅度较大,最终在较大范围内波动。文献[8]提出的ResCNN 模型较为稳定效果有所提升,但在最终收敛后的准确率为95.4%,损失值为0.097。本文提出的3A-RCNN 模型相比于其他模型,准确率上升平稳、最终稳定值高、且波动小。损失值下降平稳、最终稳定在很低的水平,波动小。
本文将上述模型以及近期相关模型结果进行汇总,其结果如表3 所示。
从表3 可以看出,3A-RCNN 收敛后的平均准确率达到了98.0%,收敛后平均损失值下降到了0.061,这表明通过对时间维度、通道维度、频率维度三个维度进行权重的自分配,再将信息通过全连接层及分类器进行分类,可以重点捕获到需要提取的相关身份信息,屏蔽掉无关信息,表明了多重注意力机制嵌入残差块末端的有效性。
5 结束语
本文将语音信号转化为梅尔语谱图,将神经网络在图像处理领域的新思想与新方法引入说话人识别领域。并且提出一种新的3A注意力机制,并且嵌入每个残差快的末端,与本文设计的ResCNN相结合,强化特征提取模型的专注性,搭建了新的模型3A-RCNN模型。多重注意力机制与残差结构深度的结合,扩展了注意力机制在维度上的运用,并且增强了每个残差快的特异性提取功能,可以有针对性的捕获到语音中与说话人相关的特征,并且提升模型性能。下一步将引入文本内容与说话人识别结合,以达到辅助提升识别性能的目的。
