基于大数据技术的图书馆PDA采购资源应用架构的研究与实践
2020-02-02吕娜娜
吕娜娜
(广州医科大学 图书馆,广东 广州 511436)
21世纪大数据已经成为了不同研究领域,如生物医学工程、计算智能、信息融合和人文社会科学的热点问题.2012年3月,奥巴马政府提出了“大数据研究和发展计划”[1],其中将美国国家医学图书馆作为计划的重要组成部分,不仅重视图书馆中各类数据的收集、存储、保护、管理和分析,而且提供大数据归档、保存、传播以及其他数据的基础设施服务.2015年,Saunders分析了63个高校图书馆的战略计划,发现40%的高校图书馆强调了数据服务[2].近年来,国内外图书馆已经将大数据技术应用于馆藏资源建设及创新服务.通过运用不同的大数据框架,如Apache的Hadoop,将大数据技术和高效的机器学习算法相结合,建立以读者决策为中心,将用户数据进行存储、分析与挖掘,为科研评价和重塑资源采购的馆藏文献资源新模式提供了决策性的帮助.开放的信息资源、评价指标的完善、科学的数据对重构图书的文献资源体系是难得的机遇[3].
1 图书馆采购资源的环境
1.1 图书馆资源管理系统
图书馆管理系统是图书馆应用信息技术服务于读者的支撑平台,大多数的图书馆仍然使用集成自动化系统,用于管理纸质资源和电子资源的编目.电子资源管理系统用来协助电子资源的选择、订购、访问权限控制和购买预算等工作,或者将目录和链接解析器合并到一个图书馆服务平台的系统中,使这些不同的系统协同工作并保持更新同步.随着数字化、网络化、移动化技术以及大数据的产生,图书馆业务的外部技术环境和社会环境发生了根本性的变化,新出现了图书馆自动化服务平台(Library Services Platform s,LSPs).它能在一个平台上统一管理各种类型的文献资源,实现图书馆所有资源的统一管理[4].
1.2 图书馆相关的标准和规范
20世纪70年代以来图书馆广泛使用机读编目标准格式编制书目信息. MARC的相关记录对于图书馆目录来说是必不可少的,通常它由出版商提供,从而使目录内容更易于被访问.但是由美国国家信息标准组织(NISO)和UKSG共同发布的知识库与相关工具(Knowledge Bases and Related Tools standard)也同样重要.KBART是一种向链接解析器知识库提交元数据的推荐格式,它可以从定制的数据包中获得准确的书目信息.据NISO发布的消息称,自第I阶段实践发布以来,超过75个出版社与内容供应商已签署KBART,KBART第I阶段实践针对的是期刊,第II阶段扩大到了开放获取出版物、电子书和会议录,并且特别针对提交联盟订购电子资源订制包清单的方法作出了规定[5].
大数据不同于传统数据, 它是数字化时代下产生的非结构化数据和半结构化数据.图书馆在文献资源构建的过程中产生的大数据主要来源有以下几种:(1)图书馆馆藏文献数据,如图书馆自身馆藏资源、自建数据库、固定资产、馆舍情况等;(2)读者行为数据,如读者访问数据库的数据、借阅数据、读者社交网络数据、读者需求为主导采购的数据等;(3)图书馆外部的数据,如馆际互借数据、出版商数据等.
图书馆、出版商和学术交流社团需要共同协商建立一个正式标准的数据规范,通过采集到的大数据规范到图书馆采购文献资源平台系统,利用大数据技术实现资源的匹配和分析,从而开发大数据的价值,以优化现有的文献资源管理体系,更好地为读者服务.
1.3 图书馆订购的文献资源内容
图书馆在订购馆藏文献资源时,需要重视本馆的馆藏发展建设政策制定的要求,结合所在院校学科发展的需求,完善馆藏文献资源的质量.不同类型的高等院校有不同的规划馆藏文献资源建设发展的方向.医学院校对于提供考试学习指南的资源非常感兴趣,如医疗案例、图片分析、课程与教师同步的课堂学习,同样医药、化学等学科领域订购的学术资源也很丰富,由视频和多媒体资源组成的新医疗资源,绝对是读者的需求.不同学科订购的资源也有所差异,如STEM是最早采用电子资源的采购,主要侧重于期刊内容,而人文社会科学学科主要购买的是纸质资源,因为它的电子资源更新较慢.
随着信息时代的发展,图书馆不仅仅只是购买纸质和电子书刊,还包括了一些多媒体资源如遗传学软件工具、教学视频、移动应用等.其中移动应用和多媒体平台是电子资源的关键元素,许多图书馆员需要花费大量的时间跟出版商协商授权使用资源的许可和管理这些资源的访问.这些新资源不在传统的图书馆订购的采购文档中,但对于图书馆读者而言是必不可少的,也是图书馆需要的一部分.
2 读者决策采购推动图书馆资源建设的变革
读者决策采购(Patron-driven acquisition)简称PDA,是数字化时代图书馆采用的以读者需求为主导,满足读者个性化、精细化服务的文献资源建设新模式.近年来,国内外许多图书馆开展了PDA项目,例如加拿大安大略图书馆联盟的PDA项目[6],加利福尼亚州立大学图书馆PDA项目[7],内蒙古图书馆“彩云服务”[8],江苏大学与新华书店的PDA合作项目,广州医科大学“你选书、我买单”,等.
图书馆PDA项目自使用以来,已采集到大量的书目信息,读者检索偏好数据、读者地理位置等结构化数据、半结构化数据和非结构化数据,通过运用大数据分析技术,可以更加有效地评估读者对各种资源的阅读偏好、学科需求、与图书馆的交互情况等,为PDA项目的经费额度、采购参数文档的设定、读者群体细分、重点学科建设、出版商的选择等提供辅助决策,并能预测读者新的知识服务需求,为文献资源建设提供科学合理的荐购服务.
2.1 优化采访工作流程,提高服务效益
图书馆传统的采购工作流程较为繁琐,一本书从下单到上架与读者见面,这一过程往往长达2-3个月,有时甚至更长.因此及时满足读者的需求,可以提高图书馆服务的效益.纸质资源的读者决策采购可与书店合作,优先将新书放置在图书馆新书借阅处,读者识别身份后可以直接借阅,当图书归还后再进行数据的加工.例如佛山市图书馆[9]、江苏大学的“新书借阅处”,内蒙古图书馆的“彩云服务计划”.电子资源的读者决策采购,即当读者点击浏览相关电子资源的链接,达到图书馆预设的浏览次数、试读次数等量化指标后会自动触发图书馆向出版商租用或购买.据调查,全美已实施PDA的图书馆大约占到了65%,且主要运用于电子资源的采购,香港中文大学、香港科技大学[10]也针对电子图书展开了PDA实践,实践结果表明PDA模式可以有效补充馆藏文献资源的建设,降低馆藏文献采购成本,提高读者的满意度.
2.2 利用统计相关工具,及时推送消息服务
图书馆通过PDA项目的实施可以获取读者访问数据库的数据、借阅数据、感兴趣的学科范围以及读者社交网络数据等,从而充分利用电子资源使用统计和分析数据,例如COUNTER、大数据的统计分析挖掘功能、Google Analytics等,对读者的行为数据进行统计以及分析其行为习惯和偏好,挖掘出潜在价值,对读者推荐的文献在指标和研究分析上通过影响因子、特征因子、Altmetrics等做资源评估.图书馆因此实现了个人化、个性化、精确化和智能化地向读者推广服务和推送及时消息,为改善图书馆的服务质量、资源优化配置、学科服务、知识挖掘、资源评估等工作提供决策性的帮助.
2.3 改变图书馆资源采购模式,提高馆藏文献资源质量
读者决策采购与大宗交易不同,PDA按点击次数、按篇、按试读量等方式进行采购,打破了以往的捆绑式和整库采购方式.但是国内的中文电子书商如超星、中国知网、万方等均采用整库销售的方式,图书馆在采购电子图书时不能实现按册或按种采购.但是当读者决策采购模式出现后,图书馆可以跟当当网、中国亚马逊、京东书城等零售商合作PDA项目,对传统捆绑式的出版商形成一种压迫,使其改变原有的销售模式,积极开展电子资源的PDA项目.读者决策采购可以在多媒体文献资源的单个采购中发挥大用途.例如会计、医学、外语、法律、建设工程等视频库、图片资源库和考试题库等多媒体文献资源,根据读者的需求从而设定采购新模式.改变图书馆传统的资源采购模式,以读者为中心、读者需求为驱动的PDA采购新模式可以提高采购文献质量,加强馆藏文献检索.
3 构建PDA文献资源架构体系
知识挖掘、资源优化、数据分析等增值服务的需求已逐渐出现在用户行为中,因此大数据应用在图书馆领域时,应加强图书馆与出版商、数据库供应商、资源平台、各联盟之间的联系,将读者阅读的偏好、资源使用情况、读者需求等数据进行存储、加工和管理,根据大数据的分析与挖掘将读者群体细分化,最终为不同特征的读者群体定制有针对性、个性化、精确化的推荐和推送消息.大数据挖掘图书馆的价值是以用户需求为主导,有利于降低购买成本,发掘新的需求,提高服务质量,提高图书馆利用率.
大数据环境下构建PDA的文献资源总体架构由大数据采集层、大数据预处理层、大数据存储层、大数据分析层、读者决策采购执行层系统组成,如图1所示.
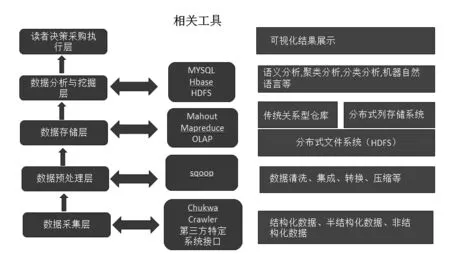
图1 大数据环境构建PDA文献资源总体架构
3.1 大数据采集层
图书馆大数据的采集是对图书馆的馆藏资源数据、读者行为数据、读者社交网络数据、出版商数据等实时接收.传统数据主要来源于结构化数据,其中存储、管理和分析数据量相对大数据而言较小,大多采用关系型数据库和并行数据库处理,而图书馆大数据是对所有类型数据的整合,所以数据采集采用一些通用分布式大数据工具.系统日志采集采用数据采集平台Hadoop的Chukwa.它能够满足每秒数百兆的日志数据采集和传输需求.读者社交网络数据是读者访问移动图书馆、微博、微信、博客等平台产生的数据,可以通过网络爬虫(crawler)或网站公开API等方式从网站上获取数据信息.对于采购参数文档、采购触发参数、读者权限数据、读者学科研究数据等保密性要求较高的数据,可以通过与出版商、数据库商、信息资源共享平台等研究机构合作,使用特定系统接口等相关方式采集数据.
3.2 大数据预处理层
采集完成的数据集存在着数据属性不一致、重复、不完整、含噪声等问题,在导入数据前需要对这些数据进行预处理,去掉数据中的噪声和无关数据,纠正不一致的数据,删除重复数据等.通过Sqoop将多个数据源中的数据进行预处理,把原始数据转换成适合数据分析挖掘的形式,并加载保存到HDFS分布式文件系统中,如图2所示.图书馆大数据预处理过程要根据实施PDA项目计划的需求,合理选择数据中关联字段,去除读者触发产生的重复数据,进而得到更精准的数据集.
3.3 大数据存储层
在大数据时代,由于数据集变得更加庞大,传统的数据仓库已经不能满足大数据的存储需求.图书馆可以根据不同的数据类型选取不同的存储方式.馆藏文献资源数据是结构化数据,可以用传统关系型仓库MYSQL进行存储.读者数据、图书馆外部网络数据是半结构化数据和非结构化数据,可以用Hbase数据库存储,将Hbase中的所有数据文件都存储在HDFS分布式文件系统上.
3.4 大数据分析与挖掘层
大数据处理、分析和挖掘是为了获取海量数据潜在的知识内容.Hadoop是目前较为成熟的分布式处理开源框架.Hbase存储的数据可以采用Hadoop的Mapreduce进行分布式并行运算.通过Mahout分析读者的行为数据,将读者群体进行细分,根据不同读者的借阅行为、浏览记录、触发购买行为等数据进行关联,挖掘不同读者群体特征的偏好.依靠数据可视化的分析对读者使用各种文献资源和需求的程度,做出一些前瞻性的判断,为以读者为主导的图书馆资源采购提供精确的辅助性决策,更好地满足读者的需求.对于存储于传统关系型仓库MYSQL数据,可以通过数据仓库系统进行联机分析处理(OLAP),如图3所示.

图3 数据分析与挖掘模块
3.5 读者决策采购执行层
图书馆根据分析与挖掘的数据可以对读者决策采购服务定制验证,评估项目的实施成果.通过数据掌握学校重点学科的建设,对不同群体特征的读者设置权限阈值,与出版商沟通调整提供的采购参数文档,修改PDA采购触发的参数,定期对PDA项目执行过程进行数据监控,保障预存经费有序合理利用,提高文献的流通率.

图2 大数据预处理模块
4 基于PDA项目实施中的问题
大数据分析的内容和挖掘潜在的价值为图书馆服务提供了很好的方向.当前我国大数据产业正处于起步阶段,用大数据实施PDA项目时面临着大数据人才的缺乏、读者隐私、大数据技术处理复杂等问题.
4.1 大数据人才的缺乏
近年来我国大数据产业迅速发展,由于成熟的人才培训体系尚未建立,直接导致各领域大数据人才短缺.大数据需要复合型的人才,其能够对统计学、数据分析、数据挖掘可视化工具、自然语言处理等多方面知识综合掌控.因此图书馆采用大数据技术实现PDA项目,需要一批数据馆员,能够具备开发分析应用程序模型的技能,实现依靠大数据重建图书馆的知识管理服务体系.
4.2 读者隐私泄露
大数据信息安全问题主要是指大数据进行预处理、存储、分析及预测时出现的用户隐私泄露.图书馆利用大数据技术整合读者数据,推断读者身份特征;通过社交网络分析揭示读者社交关系;利用语义分析推断读者的态度;读者聚类分析发现读者所在群体;分类分析,预测判别读者偏好推荐消息等.实际上这些分析挖掘的数据已经侵犯到读者的隐私,威胁到读者的隐私安全.为了保护读者的隐私,应建立健全法律法规,加强行业自我管制,采取社交网络匿名保护监控等相关措施.
4.3 大数据技术处理的复杂性
传统的数据库的算法已无法单独分析、挖掘处理大数据的内容.以Hadoop为核心融合技术在大数据行业中被广泛应用.大数据的架构比较复杂且在不断的发展,其中MepReduce不适应实时应用的需求,Hadoop的工作流系统Oozie和数据传输系统Sqoop都需要单独开发人员来部署,大数据技术本身内部的融合性与传统数据仓库技术的融合度也不是太好,如何用好大数据每项技术是个难题.
5 结论
目前国内外使用大数据技术应用于PDA图书馆文献资源采购模式的研究正处于初期阶段,其中资料重组、资料标准化和数据建模需要做大量的工作,存储和处理的数据也日益增长,图书馆数据的复杂性,给图书馆馆员带来了新的挑战.基于大数据技术搭建的PDA架构需要出版商、政府、图书馆界及广大读者等多方积极的参与和配合.如何搭建图书馆大数据PDA平台,如何有效利用图书馆联盟共享PDA服务带来的效益,如何培训数据馆员,树立大数据思维,加强数据素质,是日后图书馆发展需解决的问题.
