列车司机疲劳驾驶监测中的人脸定位方法研究
2020-01-18陈忠潘迪夫韩锟
陈忠,潘迪夫,韩锟
(中南大学 交通运输工程学院,湖南 长沙410075)
近年来,随着我国铁路营业里程、列车运行速度与行车密度等不断攀升,列车司机的工作强度也在不断加大,疲劳驾驶成为威胁铁路运输安全的重大隐患。因此,除不断完善机务部门的监管与乘务制度外,通过现代技术手段实时准确地监测列车司机驾驶状态对于保障铁路运输安全具有重要意义。目前,学术界和产业界普遍采用基于机器视觉的非接触式方法监测列车司机的驾驶状态,并选用以PERCLOS[1](Percentage of Eyelid Closure Over Time)参数为代表的眼部疲劳参数、哈欠频率[2]和点头频率[3]等作为列车司机疲劳程度判断的重要指标。获取点头频率需要预先定位人脸,检测人眼、嘴巴等细小区域也需要预先定位人脸以缩小检测范围、降低误检与检测时间。因此,构造一种快速准确的人脸定位方法是实现司机驾驶状态实时监测的前提和基础。Jayanthi 等[4]直接采用肤色检测的方式定位驾驶员脸部区域,无法排除脖子、手掌等非面部肤色区域的干扰,误检率高;李强[5]结合YCbCr 高斯肤色模型和Adaboost 算法共同获取列车司机的脸部位置,虽然误检有所抑制,但当列车司机头部摆动或转动角度过大时其脸部区域无法有效定位;贺德强等[6]结合Adaboost 和Camshift 算法定位列车司机的脸部位置,提升了侧脸和倾斜角度人脸的定位能力,但Adaboost 在图像背景复杂时容易发生误检,误检会导致Camshift 跟踪无效,且文中每隔20帧机械地启动Adaboost 重定位人脸以减小误检和跟踪失效对结果的影响,却无法在跟踪失效时及时重定位人脸。本文根据疲劳监测实际应用场景及其应用需求,提出一种融合检测与跟踪算法的人脸定位方法。首先,利用肤色模型筛选图像中的人脸候检区域;若有候检区域产生,启动AdaBoost 作为主分类器在候检区域中快速定位人脸,若未产生候检区域,则直接利用AdaBoost 在整幅图像中搜索人脸;当AdaBoost 未定位或定位出多个人脸时,使用SVM 分类器检测漏检或排除被误检的人脸;在准确获取人脸位置后,启动fDSST 算法进行跟踪,并利用Fmax和APCE(average peak-to correlation energy)2 个指标对算法的跟踪置信度进行判定,以决定是否需要对列车司机的脸部进行重定位。
1 肤色检测筛选人脸候检区域
摄像头安装在正对司机的驾驶台上,它所采集到的视频图像中除列车司机的脸部外还包含司机室内的复杂背景。若直接运用AdaBoost 或SVM 在图像内定位脸部,容易产生误检。由于肤色对于人脸姿态、表情变化鲁棒性强,且和司机室内的背景颜色存在差异,所以首先利用肤色检测筛选出人脸候检区域,减小分类器定位司机脸部区域的搜索范围,抑制误检。
1.1 建立H-CgCr 肤色模型
肤色检测的首要环节是肤色建模,建模需要选定好颜色空间。目前常见的颜色空间有RGB,YCbCr,YCgCr和HSV等[7]。由于肤色像素在YCgCr和HSV 空间中聚类性能更好,且与非肤色重叠部分少。此外,亮度与色度在YCgCr 和HSV 空间中相互分离,能有效降低光照因素对检测效果的干扰。因此,本文融合HSV 与YCgCr 空间肤色建模。
建模前首先准备30 张包含肤色像素的彩色图片,这些图片涵盖不同的种族、肤色及照明条件;接着提取图片内的肤色与非肤色像素并将其转化到YCgCr 和HSV 空间中进行统计分析。在YCgCr空间中,发现肤色像素的Cg 和Cr 均聚集于固定区间内,且其分布基本不会受到亮度Y 的影响。HSV空间中,发现肤色像素在H-S 和H-V 子空间具有十分相似的分布规律,色调H 能显著区分肤色与非肤色像素。统计YCgCr 和HSV 空间中肤色像素的分布如图1所示。
由图1结果可知,Cg,Cr 分量和H 分量均能有效区分肤色与非肤色像素。由于阈值模型简单直接,在保证肤色检测效果的同时具有更快的检测速度[8],因此本文融合Cg,Cr 和H 3 个分量建立H-CgCr 肤色阈值模型。在H-CgCr 肤色模型中,肤色像素满足以下规则:
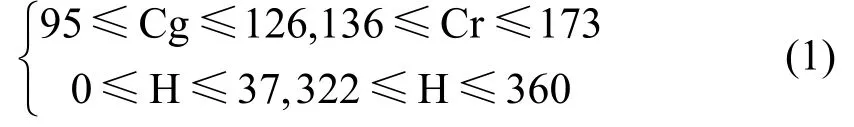
1.2 筛选人脸候检区域
列车行驶过程中司机室内的光照条件会不断发生改变,因此在肤色检测前先利用参考白方法[9]对图像进行光照补偿,结果如图2(b)所示;接着使用本文H-CgCr 模型对图像进行二值化操作,结果如图2(c)所示;肤色二值图像中仍然含有假肤色像素及眼睛、嘴巴等形成的孔洞,接下来对H-CgCr结果进行形态学处理(腐蚀膨胀等操作)以得到一个纯净的肤色区域,如图2(d)所示;纯净肤色区域中除包含人脸外可能还含有手臂、手掌等不属于脸部的元素,所以还可根据区域长宽比(根据人脸长宽比取0.8~2.4),区域中肤色像素数与图像总像素数的比值r,区域长度l与宽度w进一步筛选人脸候检区域。
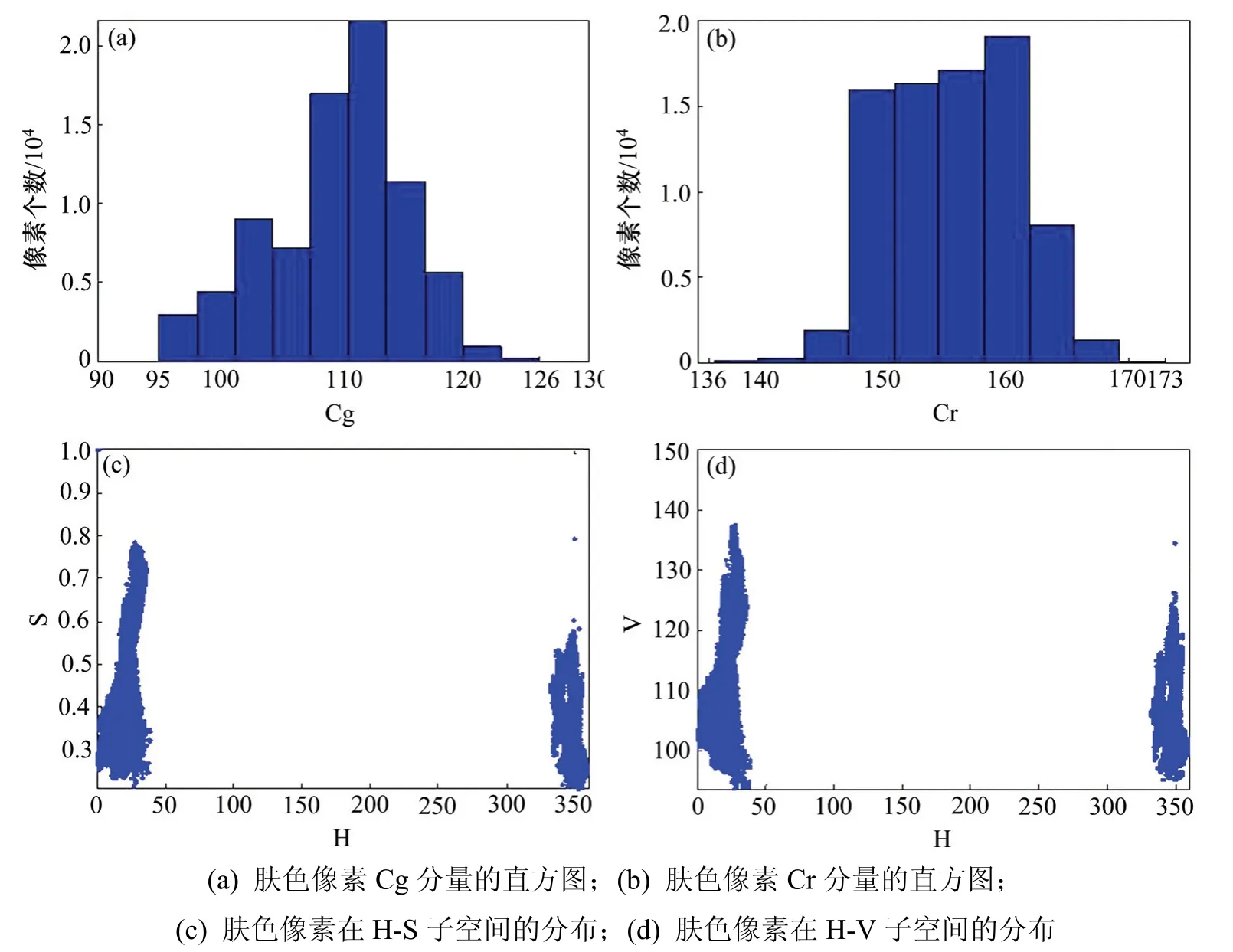
图1 YCgCr 和HSV 空间中肤色像素的分布Fig.1 Distribution of skin color pixels in YCgCr and HSV color space
由于肤色检测的实质是利用肤色模型逐一对图像内全部像素点进行肤色判别,故检测速度较慢。为此,本文提出一种肤色加速检测方法:首先利用最临近插值法将图像尺寸缩放至原图的1/n,然后使用H-CgCr 模型检测缩放后图像内的肤色区域,最后将检测结果放大n倍即为原图中的肤色区域。r,l,w和n的取值与图像分辨率或司机脸部在图像中的占比有关,原则上图像分辨率越高,肤色像素的识别效果越好,但随之检测耗时也会大大增加;若图像分辨率偏低,又会影响后续眼部状态判别的可靠性。故本文经综合比对后选用分辨率为640*480 的摄像头拍摄列车司机驾驶视频,且由于司机脸部在图像中的比例不会太小,基于此,取r为0.012,l和w为60,n为4,直接剔除r小于0.012,l和w小于60 的区域。利用H-CgCr 模型筛选人脸候检区域的结果如图2(e)所示,利用H-CgCr 采用加速方法的筛选结果如图2(f)。
2 AdaBoost 和SVM 双分类器精确定位人脸
由于筛选出的人脸候检区域可能为误检或含有脖子等非人脸元素,因此还需要进一步定位人脸。AdaBoost 对于正脸检测率高,然而列车司机在值乘过程中需要瞭望轨旁信号和观察线路环境,头部时有偏转,其脸部不总以正面状态呈现,如果利用Haar 特征训练AdaBoost 多视角人脸分类器,除需收集大量的多姿态脸部图像外,还需对Haar 特征进行扩展,不论是计算复杂度、训练耗时还是检测耗时都会成倍增加。此时利用LBP 特征训练出具有旋转不变性的SVM 分类器定位被AdaBoost 漏检或误检的人脸,进一步提升列车司机的脸部定位性能。
2.1 利用Haar 特征训练AdaBoost 主分类器
AdaBoost 算法最先由Viola 和Jones[10]将其用于人脸检测领域,由于其检测率高、实时性好,应用最为广泛。这主要得益于3 个关键因素:1)使用一种十分简单有效的矩形Haar 特征,并且采用积分图的方式计算特征值,方便快速;2)利用AdaBoost 算法从海量Haar 特征中筛选出样本区分能力最佳的若干个组成强分类器;3)将强分类器串联成级联分类器,并提出一种由粗到精的检测思路,大大提升了检测速度。利用Haar 特征训练AdaBoost 人脸分类器的流程如图3所示。
2.2 利用LBP 特征训练SVM 辅分类器
LBP 是由Ojala 等[11]设计的一种具有灰度不变性的局部纹理特征算子,这种传统LBP 算子的邻域半径恒定,很难适应各种不同的应用场景。后来Ojala 将邻域由传统的方形变换为圆形,提出可自由设定邻域半径大小的圆形LBP,用LBP(P,R)表示,其中P为采样点个数,R是邻域半径。当P和R大小选定之后,转动圆形邻域可获取一组LBP 值,每次都将最小值设定为最终的特征值,此时的LBP 具有旋转不变性,称之为旋转不变LBP 特征[12]。本文利用旋转不变LBP 特征构造一种新的融合LBP 特征,并对特征进行归一化处理,运用SVM 训练出具有旋转不变性的人脸分类器。
2.2.1 构造新的融合LBP 特征
由于提取LBP 特征时普遍先对整幅图像进行分块化操作,此时即便是采用旋转不变LBP 特征进行特征提取,得到的特征向量对于整幅图像而言也不再具备旋转不变属性。对此,本文通过不断调整旋转不变LBP 特征的P和R值不分块直接对整张图提取特征,从中挑选出若干个样本分类能力最佳的旋转不变LBP 特征融合成一个新的特征向量,新特征向量的构造过程如下(以80*80 的图片为例)。
Step 1:将图片尺寸依次归一化为5*5,10*10,15*15,…,80*80;
Step 2:调整P和R值,其中P=8:2:24,R=1:1:4;
Step 3:分别在不同图片尺寸下根据不同的P和R值直接提取整幅图片的旋转不变LBP 特征,并利用该特征训练SVM 分类器,再对其分类能力进行测试;
Step 4:多次实验从中挑选出若干个样本分类能力最佳且性能稳定的旋转不变LBP 特征,将所有特征串联成最终的特征向量,即为新的融合LBP 特征。
本文采用5 个测试集验证各个特征的分类能力,并从中筛选出不同图片尺寸下的共计31 个最佳旋转不变LBP 特征组成最终的融合LBP 特征。由于每个单独LBP 特征对于整幅图片而言都具有旋转不变性,所以由它们融合而成的新特征也完全不受图片旋转角度的影响,因此利用新特征训练出来的人脸分类器可以很好地定位头部存在倾斜的脸部区域。训练分类器时,在训练样本中添加足够的侧脸样本,则分类器还能对侧面人脸具有很好的识别能力。
2.2.2 训练SVM 人脸分类器
支持向量机(SVM)是一种具有较强泛化能力和分类能力的机器学习算法,对于处理小样本、非线性和高维数据问题具有显著优势[13]。本文构造的融合LBP 特征维数高达606 维(训练图片尺寸为80*80),选用适用范围广、可调参数少的RBF 作为SVM 的核函数。SVM 分类器的训练步骤如下,基于SVM 的人脸检测流程如图4所示。
Step 1:构建训练样本集。选用FERET 人脸库和手工截取的正脸及侧脸图片共2 000 张组成正样本,选用互联网收集、列车司机室背景等2 000 张非人脸图片组成负样本;
Step 2:提取训练样本的融合LBP 特征;
Step 3:对特征向量进行归一化处理;
Step 4:训练生成SVM 人脸分类器。

图4 基于SVM 的人脸检测算法流程Fig.4 Face detection algorithmic flow based on SVM
3 fDSST 算法人脸跟踪
基于相关滤波的fDSST[14](fast Discriminative Scale Space Tracking)跟踪算法是KCF 算法的改进版本,该算法设计了2 个相对独立的滤波器:位置滤波器用于当前帧目标的定位、尺度滤波器用于估计目标尺度,同时利用PCA 降维与QR 分解对两者进行加速,算法具有跟踪精度高、实时性强等优点。由于fDSST 在分类器训练过程中利用循环矩阵特性实现密集采样,区分前景和背景时可信度更高,因此鲁棒性会比Kalman 滤波、Camshift 这类生成式跟踪方法更好。本文在获取列车司机的脸部位置后,采用fDSST 算法进行跟踪,进一步提升人脸定位速度。fDSST 进行目标跟踪的流程如图5所示。
本文融合Fmax与APCE 2 个指标对算法的跟踪置信度进行判定,Fmax是指位置滤波器的最大响应值,而APCE 值体现响应图的整体波动情况,计算公式如下:
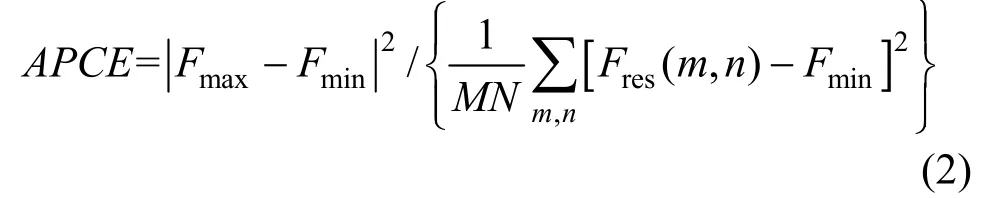
式中:Fmax,Fmin和Fres(m,n)分别指大小为M×N的响应图中的最大响应值、最小响应值以及每一像素点所对应的响应值。在当前帧,若Fmax与APCE 均以一定的比例超过其历史帧均值时,如式(8)所示,可认为算法此时置信度高、跟踪效果好,若不满足要求,则认为算法在该帧跟踪置信度低,可能出现跟踪失败情况,此时需要重新对列车司机的脸部进行定位。β1和β2分别设为0.6 和0.4。
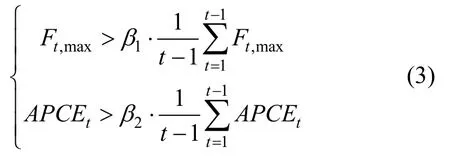
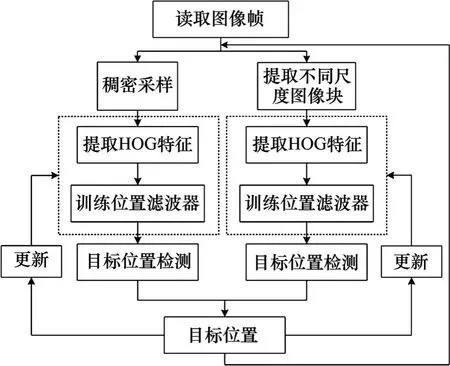
图5 fDSST 算法进行目标跟踪的流程Fig.5 Flow of target tracking based on fDSST algorithm
4 实验结果分析
为验证本文H-CgCr 模型、肤色加速检测方法的性能及本文列车司机脸部定位方法的合理性与有效性,在CPU 为Intel Core i5,主频为2.70 GHz,8 GB 内存的计算机中编程开展实验。
4.1 肤色模型性能对比
从Color FERET 人脸库中抽取500 张人脸图片(分辨率为512*768),这些图片的背景较为单调,但包含不同的肤色、年龄阶段、光照、姿态及表情变化。分别使用YCgCr 和HSV 阈值模型、文献[5]YCbCr 高斯模型、文献[15]YCbCr 阈值模型、本文H-CgCr 模型及本文H-CgCr 模型的加速方式筛选经参考白光照补偿后的500 张图片内的人脸候检区域,结果如表1所示。
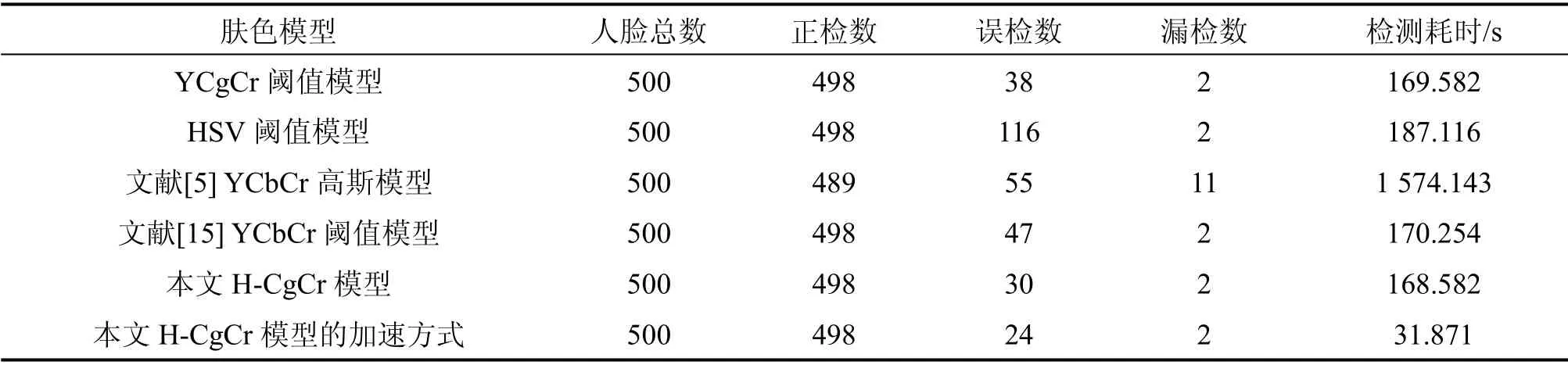
表1 不同模型筛选脸部候检区域的性能对比Table 1 Performance comparison of face regions screened by different skin color models
由实验结果可知,融合模型(本文H-CgCr)比单一模型(YCgCr、HSV)性能更佳,能有效降低误检;与其他主流模型相比,本文H-CgCr 模型也更具优势;利用H-CgCr 模型采用加速方法(n取4)筛选人脸候检区域,由于缩放后图像内的像素点数目大幅减少,使得候检区域筛选耗时降低81.09%,误检进一步得到抑制;肤色对图片尺寸、姿态及表情变化鲁棒性强,但肤色模型的共同缺陷是其检测性能易受光照因素的影响。为此,本文在肤色检测前先对图像进行参考白光照补偿处理,其次选用亮度与色度信息相分离的HSV 和YCgCr 空间建模,最大限度降低光照因素产生的干扰,所以本文模型在光照变化时也表现出不错的鲁棒性。
4.2 人脸定位方法的合理性与有效性验证
根据列车司机疲劳驾驶监测应用需求及列车司机驾驶特点,提出一种先检测后跟踪的人脸定位方法,具体流程如图6所示,接下来对流程的合理性与有效性展开验证。
4.2.1 “加速H-CgCr+AdaBoost/SVM”检测列车司机脸部区域
考虑到列车行驶过程中司机室内的光照条件会不断发生改变,司机的头部也会时有偏转,而头部姿态、光照条件均是公认的影响人脸检测算法性能的因素[15]。接下来,构造3 个图片集对不同人脸检测方法的性能进行测试,实验结果如表2所示。图片集1:500 张正常光照与正常姿态的人脸图片;图片集2:300 张正常姿态但偏暗或偏亮的人脸图片;图片集3:300 张正常光照条件下头部存在转动或摆动(转角或摆角存在,但均小于45°)的人脸图片。(正检率=正确检测的人脸数目/人脸总数;误检率=检测结果中的非人脸数目/人脸总数)
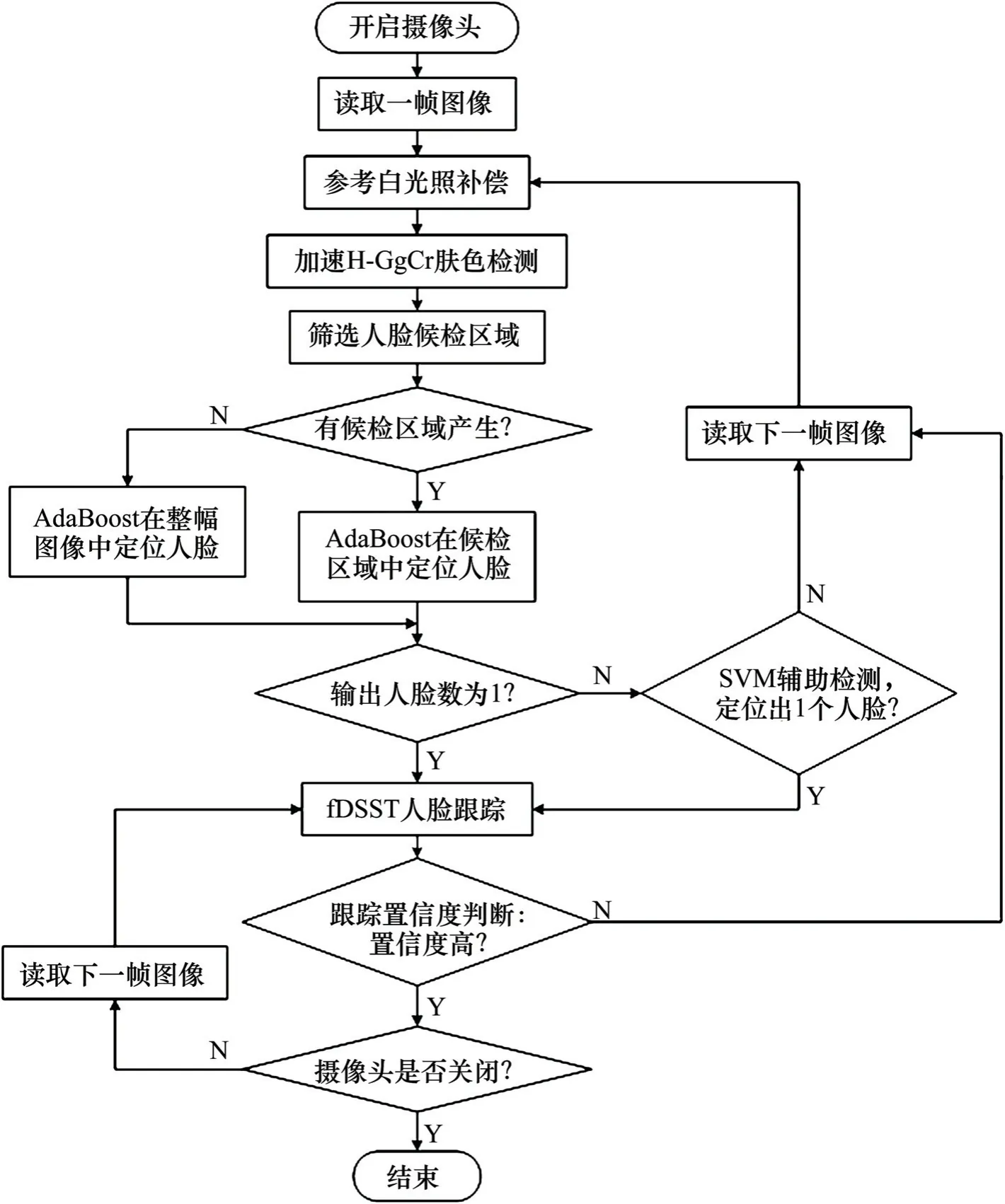
图6 本文列车司机脸部定位算法流程Fig.6 Flow of train driver’s face location algorithm

表2 不同人脸检测方法的性能对比Table 2 Performance comparison of different face detection methods
观察实验结果,发现肤色模型筛选人脸候检区域具有较高的检测率,但当图像背景复杂时容易发生误检。此外,本文H-CgCr 模型虽已最大限度降低光照因素产生的影响,但当光照偏差严重时,其性能还会一定程度下滑;AdaBoost 定位人脸基本不受光照变化影响,但其对侧脸和倾斜角度人脸不敏感;将H-CgCr 模型与AdaBoost 相结合用于脸部定位,与仅利用AdaBoost 直接在整幅图像内检测人脸相比,虽正检略有下滑,但其对于误检的抑制程度大于正检的下滑程度;SVM 定位人脸也不受光照变化影响,且由于训练SVM 分类器时所用的融合LBP 特征具有旋转不变性,所以训练出的SVM 对于倾斜和偏转的人脸仍具有很好的检测能力。本文将H-CgCr 模型与AdaBoost 和SVM 双分类器融合进行人脸检测,在提升正检的同时能有效抑制误检,且当光照条件及头部姿态发生变化时其性能依旧稳定,鲁棒性强,能有效确保列车在行驶过程中司机的脸部区域被准确定位。
利用本文方法检测人脸,部分结果如图7所示。其中,图7(a)和7(c)为H-CgCr 加速方法筛选出的人脸候检区域。图7(a)为正脸图片,利用AdaBoost可直接定位,由于未出现漏检和误检,此时无需启动SVM 辅助定位;图7(c)为头部倾斜图片,Ada Boost 未成功定位脸部,此时启动SVM 在候检区域中成功定位。可知本文方法能进一步提升列车司机的脸部定位性能。

图7 本文方法人脸检测结果Fig.7 Results of face detection based on our method
4.2.2 fDSST 算法跟踪人脸
利用分辨率为640*480 的摄像头在SS8 型电力机车和HXD3C 型电力机车司机室内采集多段视频并转化为图像序列,分别使用不同方法实现脸部定位并对比定位速度,如表3所示。

表3 不同方法获取人脸位置的速度对比Table 3 Speed comparison of different face location methods
根据表3统计结果可知,由于摄像头帧率一般为20~30 帧/s,若采用纯检测的方法定位人脸,显然无法满足疲劳驾驶监测实时性要求。而本文在利用“加速H-CgCr+AdaBoost/SVM”获取脸部位置后,启动fDSST 算法进行跟踪的人脸定位方法,能将人脸定位平均速度提升至45 帧/s,大大节省了脸部定位时间,满足实时性要求。
图8为在2 段连续视频内采用本文“加速HCgCr+AdaBoost/SVM”方法获取脸部位置后启动fDSST 算法进行跟踪的结果,发现fDSST 在头部摆动或转动、脸部区域存在部分遮挡、尺度变化、光照变化时仍然具有很好的跟踪效果,跟踪精度高、鲁棒性好。

图8 fDSST 算法人脸跟踪结果Fig.8 Results of face tracking using fDSST algorithm
5 结论
1)提出的先检测后跟踪的人脸定位方法,能兼顾检测率、误检率、检测耗时综合达到最优,当列车司机头部发生摆动、转动或部分遮挡时,其脸部区域均能被准确定位。
2)本文H-CgCr 模型综合性能较为优越,提出的肤色加速检测方法能将人脸候检区域筛选耗时降低81.09%;利用融合LBP 特征训练出具有旋转不变性的SVM 分类器,能在AdaBoost 定位人脸的基础上进一步降低漏检和误检;获取人脸位置后启动fDSST 算法进行跟踪,能将人脸定位平均速度提升至45 帧/s。
3)本文方法实时性好,鲁棒性强,可为列车司机疲劳驾驶监测提供理论和实践参考,且能迁移应用到汽车驾驶员疲劳驾驶监测场景。
