自适应边距损失用于车辆外观分割方法
2020-01-17秦征骁李振兴
肖 尧,秦征骁,李振兴
1.上海眼控科技股份有限公司 人工智能研究院,上海200040
2.公安部交通管理科学研究所 道路交通安全公安部重点实验室,江苏 无锡214151
1 引言
随着人工智能技术的发展,智能交通成为了一个十分热门的领域。在交通场景中,摄像头通过对场景图像的分析和理解,能够获得场景中道路、车辆、行人和交通指示灯等信息,再将这些信息加以组合利用,进而解决一系列交通问题。其中,车辆作为交通场景的主体,其外观、状态、位置等信息是十分重要的。虽然不同品牌车辆的外观千变万化,但其结构和组成部分是共通的,比如车辆的外观基本上包括:车轮,车门,车窗,车牌,前盖,后盖等等。在某些应用场景中,需要对车辆的结构进行精确分割,比如在违章检测中,需要对车轮进行定位;在事故分析中,需要对车辆各部分进行定损;在车辆年检中,需要对各部分的完整度进行评估。由于车辆结构的共通性和一致性,语义分割方法成为车辆外观分割的最佳解决途径。
语义分割这个问题在近20年来被计算机视觉研究者广泛地研究过了。图像语义分割是指基于图像语义内容,将图像分割为若干具有不同语义标识的区域。这个问题是一个密集分类问题,难点在于需要给每个像素分配一个语义标签,既需要抽象出高层语义信息,同时需要兼顾低层图像分割的准确性。在深度技术普及之前,传统视觉方法,如基于马尔科夫随机场[1]和低层特征池化[2]的分割方法往往无法获得很好效果。主要原因是低层特征无法很好表征图像整体的语义信息。近几年随着深度学习技术的火热发展,基于深度神经网络的语义分割方法不断涌现。文献[3]中提出一种全卷积网络(FCN),其端到端的训练方式在解决密集预测问题上得到普及。Seg-Net[4]和U-Net[5]在反卷积结构中添加了跳跃连接来充分利用中间层的特征。然而由于网络容量的限制,输出图像的分辨率较低,细节信息丢失较多。为了解决这个问题,很多工作把关注点放在了扩大滤波器感受野上面。文献[6]中提出了一种金字塔池化模块,通过将不同尺度池化层得到的特征相结合,增加了感受野的维度。Deeplab[7-8]提出了一种新的空洞卷积核,通过在卷积核中添加空洞位,来多尺度扩大卷积核的面积,从而提高感受野的范围。
对于车辆表面分割,一个比较重要的问题就是,不同类别所占的表面积差距十分大。比如车身和车窗面积较大,而车灯和车牌等部位面积较小。这个问题可以归为样本不均衡问题。样本不均衡在机器学习领域中是一个由来已久的难题,由于某些类别的训练样本过少导致分类难度提高,准确率降低。传统的解决方法,如给予样本不同权值等方法无法很好解决。在本文中,提出一种新的自适应边距损失函数,来替代softmax 损失。边距(margin)是指在分类问题中,分类平面距两边数据的间隔距离。SVM的原理即为寻找一个最大边距分类器,使得分类平面到两个类别样本的距离相等。在深度学习中,尤其是人脸识别领域,一系列基于边距的损失函数被提出来以提高分类器的性能。大边距损失[9]、附加边距损失[10]和大边距余弦损失[11]等方法基本上都是将原始的softmax损失通过特征归一化而变换成余弦损失,并在余弦空间中添加一个边距。这个边距的作用是在分类器训练中使得决策边界到训练样本的距离最大化,从而提高分类能力。
然而现有的边距损失函数都是固定边距,即分类平面到两侧的样本距离相同。如果取消这个约束,并使得边距能够对训练样本的难度自适应调整,这样就可以对样本更少的类别和更难区分的类别增加更多的关注,提高其在损失函数中的比重。因此提出一种新的自适应边距损失函数,使得边距对不同类别做出对应调整,样本较少的类别得到更高的权重,一定程度上缓解了分类样本不均衡问题。本文的工作可以概括为:(1)设计了一个车辆外观分割网络模型;(2)提出一种新的自适应边距损失函数并应用到模型中;(3)构建了一个车辆外观分割数据集。
2 自适应边距损失
2.1 softmax损失
softmax损失是在深度学习多分类任务中使用最为广泛的损失函数。其实际上是由softmax函数和交叉熵(cross-entropy)损失组合而成,原因是两者放在一起数值计算更加稳定,且求导简单。softmax函数,或称归一化指数函数,可以将输入映射到(0,1)区间中,从而得到属于某个类别的概率。其定义为,令z 为softmax 层的输入,f(z)为softmax的输出,则第k 类的概率为:
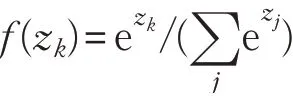
softmax损失的定义为:

其中,y=(y0,y1,…,yn),yi∈{0,1}为类别标签。通常的多分类问题中y 只有一个元素值为1,其他都是0,所以假设zi标签中只有yi=1,则:

2.2 附加边距损失
在神经网络中,损失函数层之前通常连接一个全连接层,即softmax 损失的输入一般为一个全连接层的输出。令x 为全连接层的输入,W 为全连接层的系数矩阵,则zj可表示成,这里为W 的第j 列,θj(0 ≤θj≤π)为向量Wj与x 之间的夹角。在文献[10]中,作者对系数和特征都做了归一化,即同时为了提高模型分类能力,cos(θj)被替换成了cos(θj)-m ,即在余弦空间中附加了一个边距m(m >0)。这背后的原理可以这样理解:损失函数的作用是对分类进行约束。如果p 代表正确的类别,那么需要强制,即cos(θp)>cos(θq)。这里即使将cos(θp)替换为cos(θp)-m,那么以下不等式也是成立的:
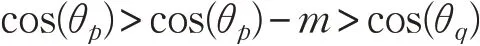
这样做会使分类正确的条件变得更加严苛,但是模型训练收敛后的分类能力会得到加强。最终附加边距损失的形式为:

其中s 为尺度系数。
2.3 自适应边距损失
文献[9-12]等方法都是嵌入了一个固定的边距。这个边距能够使训练的特征更加紧凑和中心化。然而在很多分类问题中,存在着简单和困难样本。由于样本不均衡现象,样本数较少的类别会更加难以分辨。另外一些相近类别的分类难度也会比其他的更大。此外,困难样本在总数里占的比例较小,大部分样本属于简单样本,这样会造成一个问题就是困难样本的损失会淹没在简单样本之中,使得最终损失完全被简单样本统治[13]。从图1(b)与(c)可以看到,尽管加了边距后类内更加紧凑,类间距离增大,但仍然有一些数据点散落在类间的空间并混合在一起,这部分困难数据是影响分类准确率的主要因素。
为了衡量样本的分类难度,使用softmax 输出的归一化指数概率来作为指标:

p 代表的是样本被正确分类的概率。那么自适应边距(adaptive margin)被定义为:
这里α 为边距上限。本文的自适应边距函数具有两个性质:(1)若一个难样本距离类别中心较远并被错分类,那么p 则较小,使得边距m 趋近于最大值α,导致分类正确条件更加严苛,并对错分产生一个更大的惩罚。反之对于简单样本,p 趋近于1,则边距趋近于0,使得损失等价于softmax损失。(2)这里的参数γ 可以平滑地控制简单和困难样本之间的边距效应。当γ=0 时,mA变成了固定边距。γ 若增长则边距效应随之增长。值得注意的是mA是由p 来决定的,对于不同的样本mA各不相同,即样本间的自适应性。在本文实验中设定γ=2。
这样将附加边距替换为自适应边距得到损失函数为:
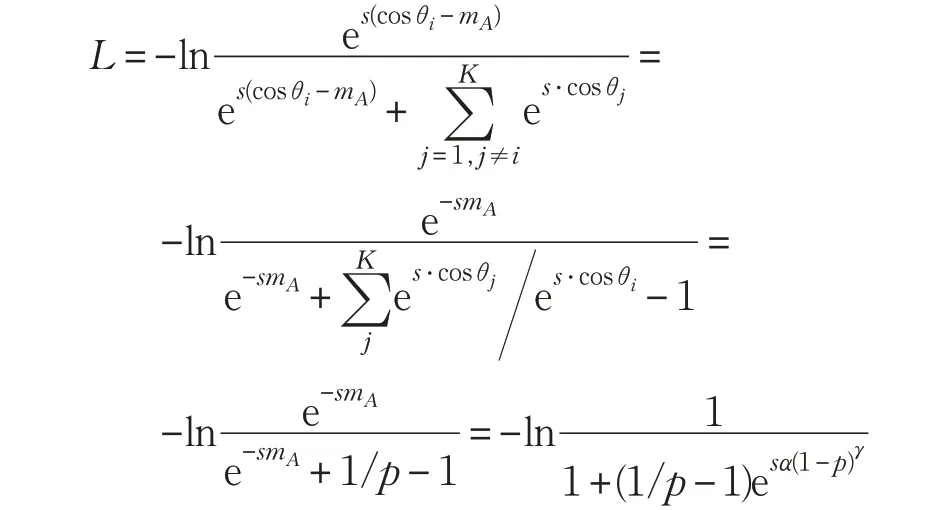
在实际训练中α 并不是一个固定的值,而是随着迭代次数增加而递增的sigmoid 函数。也就是说,在训练的开始阶段,损失函数近似等于原始softmax 损失。而随着训练的进行,迭代次数增加,边距效应影响逐渐增大。这样可以保证训练的稳定性,加速收敛。
3 分割网络
基于refinenet[14]设计了本文的车辆外观分割网络,网络结构如图2所示。
3.1 多分辨率融合结构

图1 不同损失函数特征比较

图2 网络结构
为了使模型能够同时抽取整体结构和局部细节的特征,采用多分辨率特征融合的结构。如图2 中所示,两条侧边链接跨越了网络的前段和后段,将低层和高层的特征进行融合。在特征融合之前,高层特征首先通过上采样来统一分辨率,接着通过eltwise 操作,对应元素相乘获得融合之后的特征,最后输入到残差卷积单元与链式残差池化单元。网络由25 层构成,特征下采样倍数最高为16倍。
3.2 残差卷积单元(RCU)
该单元为ResNet[15]中卷积单元的简化版本,由两个卷积层和激活层级联,保留了恒等快捷连接(identity shortcut connection),去掉了批量标准化[16]层。该单元主要目的是从不同尺度的图像中抽取底层特征。结构如图3所示。此模块保留了较好的特征提取能力,能够满足分割网络的需求。

图3 残差卷积单元(RCU)
3.3 链式残差池化单元(CRP)
低层抽取的特征最后会输入到链式残差池化单元之中,目的是使网络能够抽取高层语义特征,抓取全局信息,区别前景和背景。如图4 所示,CRP 模块由多层池化卷积层级联,可以整合不同尺度特征,并通过卷积加权整合到一起,从而获取背景上下文信息。在网络的末尾使用一个1×1 的卷积层来代替全连接层。实验证明这样可以在不损失效果的情况下减少训练参数,减低训练负担。最后特征通过提出的自适应边距函数来计算损失。
4 实验分析

图4 链式残差池化单元(CRP)
实验以caffe 作为开发框架,计算机硬件主要配置为一块Nvidia GTX1080,16 GB RAM。模型训练了一天左右趋于收敛。
4.1 车辆外观分割数据集
基于车辆年检的图像数据,构建了一个车辆外观分割数据集,包括各种大车和小车的外观及分割标签,标签类别共23 种(包含背景),原始数据包含7 116 张图片,被分为6 404 张训练集与712 张测试集。在原始图片上,标注人员对车辆外观进行分割标注。图5中展示了部分标注结果。在训练之前会对数据进行扩充处理,扩充方式包括:添加随机噪声、数据归一化处理、去均值、随机镜像,和以目标区域为中心,对输入图像做多尺度处理。
4.2 性能比较
这里选择pspnet[6]、segnet[4]和deeplab v2[7-8]作为对比算法。性能指标上采用mIoU 来衡量分割效果。mIoU(平均交并比)的定义为,假设A,B 为算法分割区域和真实标注区域,则IoU指相交区域面积与合并区域面积的比值:

取所有样本平均值即为mIoU。表1 中对比了4 种算法的mIoU 和显存占用。从表1 中可以看到,pspnet、deeplab v2与本文方法在相同输入图像大小的情况下,计算量和显存占用比较相似。Segnet 的模型计算量远超其他方法,所以mIoU 与本文方法最为接近。本文方法在较小的计算量情况下,获得了最高的mIoU,在同类方法中处于领先地位。同时比较了使用本文提出的自适应边距损失和原始softmax 损失的指标,实验显示新的损失函数能够将mIoU提高2.3个百分点。

图5 车辆外观标注数据

图6 车辆外观分割结果

表1 分割方法性能比较
另外还进行了不同损失函数的性能对比实验,见表2。这里选择原始softmax 损失、大边距损失、附加边距损失和自适应边距损失进行对比,在相同的网络结构下,本文的自适应损失能够获得较大提升,显著优于其他损失函数。

表2 不同损失函数比较
4.3 分割效果
图6 中选择了部分分割结果图进行对比展示。从视觉效果上来看,各方法的优缺点如下:(1)segnet 模型对小目标分割效果比较好,但由于感受野的限制及encoder-decoder 模式,导致获取有限的上下文信息,对目标分割较敏感,容易导致误分割。(2)pspnet模型对结构、颜色相似的目标分割效果不是很好。(3)deeplab 模型对小目标、相似目标分割效果不理想,主要是deeplab以VGG16 为骨干网络,下采样16 倍,后面接一个ASPP结构对特征图做对尺度处理,后面再接一个双线性插值上采样操作,得到与输入图像相同大小的特征图,在该过程中会丢失许多细节信息,对小目标分割效果相对来说较差,且对结构、颜色相似的目标分割效果不理想。(4)本文方法网络对小目标,结构、颜色相似的目标分割效果较理想,在局部细节上,尤其是面积较小的类别的分割效果要远远好于其他方法,且能够适当处理类内不一致的问题。
5 结束语
本文提出了一种新的自适应边距损失函数,并构建了一个卷积神经网络用于车辆外观分割。为了解决样本不均衡问题,设计的边距函数能够针对样本难度做自适应调整,使得样本少和难分类样本在最终损失中获得更高的权重,进而增加特征的紧致程度和可分辨性,提高分类准确率。并且构建了一个车辆外观分割数据集,用以模型的训练和测试。经过在测试集上的实验验证,本文提出的方法在低显存占用的情况下取得了最高的mIoU 指标,并且视觉上优于所有同类算法。后续的研究,将会尝试将网络层数加深,使用更加复杂的模型以提高特征提取能力,进而获得更高的mIoU 指标和分割精度。
