基于宽浅稠密网络的无人驾驶汽车交通标志牌识别*
2020-01-15邓涛李鑫汪明明邓彪
邓涛 李鑫 汪明明 邓彪
(重庆交通大学,重庆 400074)
主题词:无人驾驶 交通标志牌识别 深度学习 深层卷积神经网络 稠密网络
1 前言
无人驾驶汽车环境感知技术中的一个重要环节是交通标志牌的检测与识别,自动交通标志牌检测和识别(Automatic Traffic Sign Detection and Recognition,TSDR)系统由此开始应用。21世纪,计算机的发展和人工智能的兴起为交通标志识别技术指明了发展方向。TSDR系统主要根据交通标志牌的颜色、形状等特征来检测识别交通标志。RGB颜色分割[1]是一种基于颜色特征的检测方法,但该方法鲁棒性较差。针对该缺点,相继出现了HIS(Hue,Intensity,Saturation)颜色分割[2]、HSV(Hue,Saturation,Value)多阈值分割[3]等改进算法,提高了鲁棒性,但计算耗时较长。基于形状特征的检测方法有Hough变换、梯度方向信息、Canny边缘检测等方法,但这些方法受限于形状匹配的模板,也存在鲁棒性差的问题。
为了克服传统检测识别方法的缺点,机器学习的方法被广泛研究,如支持向量机(Support Vector Machine,SVM)[4-5]、AdaBoost[6-7]、深层神经网络[8]等,而卷积神经网络(Convolutional Neural Networks,CNN)应用最广。Habibi[9]提出了一种基于轻量级卷积神经网络的交通标志检测方法,提升了模型准确率和鲁棒性;Zhu等[10]提出了一种基于深层卷积神经网络的交通标志分类框架,缩小了标志牌搜索范围,实现了快速准确的检测和识别。但随着网络层数不断加深,网络越来越难以训练,甚至出现退化的现象。何凯明[11]团队提出残差网络(Residual Network,ResNet)方法,网络训练收敛速度提高,有效地解决了网络逐渐加深时的退化现象。在此基础上,Huang等[12]提出稠密网络(Dense Network,DenseNet)方法,其具有强化特征传播、支持特征重用、大幅度减少网络数据量等优点,进一步解决了梯度消失的问题,且计算量更小,模型识别准确度更高。
因此,本文基于稠密网络建立无人驾驶汽车交通标志牌识别模型,同时改进网络结构,设计宽浅稠密网络,以提升模型收敛速度和识别精度。
2 宽浅稠密网络模型
2.1 预处理网络
预处理网络的主要作用是粗略地对数据集进行颜色空间转换,提取图像特征,为特征提取层做准备。如图1所示,输入端输入32×32×3的图片数据集,第1层为批规范化(Batch Normalization,BN)层,即每次使用随机梯度下降解析器时,通过小批量数据对相应的激活层进行规范化操作。第2层、第4层分别为3×3×8、1×1×8的卷积层(Convolutional Layer),用于提取和转换图像特征集。第3层、第5层的参数化修正线性单元(Parametric Rectified Linear Unit,PReLU)激活层用于增加网络的非线性。
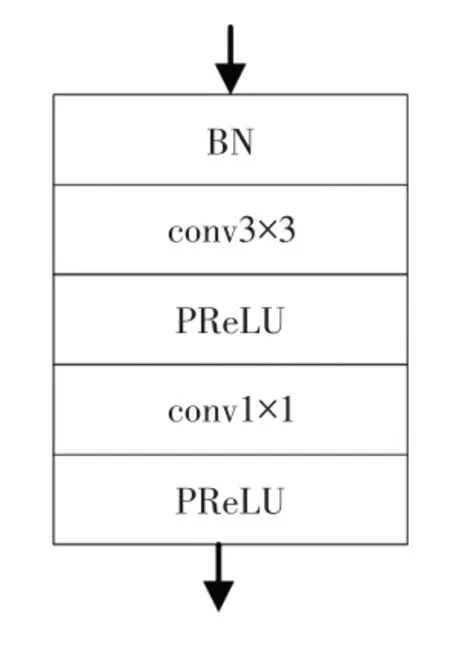
图1 预处理网络
2.2 宽浅稠密特征提取网络
根据DenseNet稠密块构建方法和宽浅残差网络[13]的设计思想,为缩短训练时间,减少内存占用,本文增加稠密块宽度K,减少网络层数L,提出宽浅稠密网络,并重新设计网络结构。
特征提取网络结构如图2所示。conv1为5×5×32的卷积层,加上批规范化层和修正线性单元(Rectified Linear Unit,ReLU)激活层。稠密网络结构采用3个稠密网络块,每个稠密网络块由4个Conv-BN-ReLU连接层组成,各连接层由Concat(Concatenation)层进行拼接。卷积层conv3×3的宽度为k,Dense-block2~4对应的k取值分别为16、24、32。区块之间插入最大池化层(Max Pooling),以减小输入激活层的特征映射尺寸。
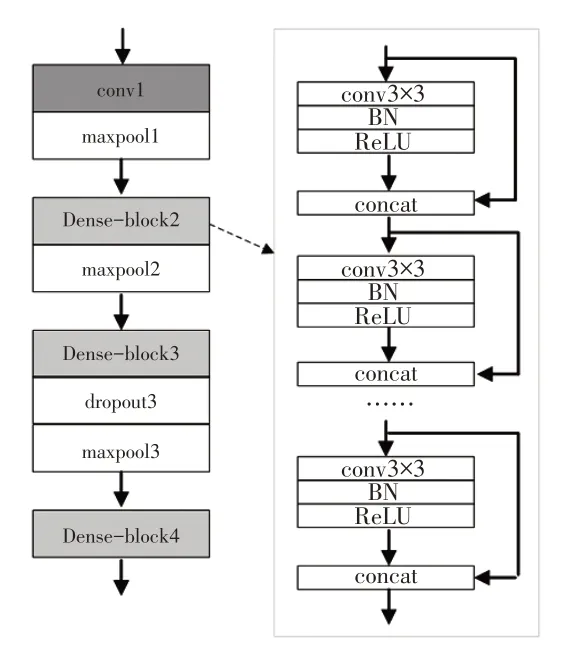
图2 特征提取网络
为验证增加稠密块宽度,减少网络层数方法的有效性,设计3类宽浅稠密网络(Wide-DenseNet1~3)和1类深度稠密网络(DenseNet)的对比试验,在CIFAR-10+、CIFAR-100+数据集上进行测试,结果如表1所示。

表1 宽浅稠密网络与深度稠密网络
显然,在与DenseNet达到近似准确度的情况下,Wide-DenseNet1迭代时间和内存占用更少;在与DenseNet迭代时间和内存占用相近时,Wide-DenseNet2达到的准确度更高。因此,该方法是可行的。
2.3 分类网络
分类网络采用平均池化层(Average Pooling),中间插入一层dropout层,以减少网络数据量并降低计算量,避免网络产生过拟合。如图3所示,conv4为1×1×43的卷积层,结构为Conv-BN-ReLU,分类网络输入格式为4×4×320特征图,输出1×1×43逻辑矢量。
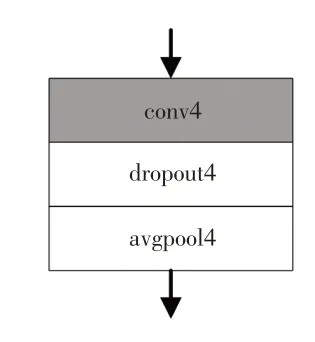
图3 分类网络结构
2.4 整体模型及网络参数
由此,建立交通标志牌识别宽浅稠密网络整体模型如图4所示,相关网络参数如表2所示。
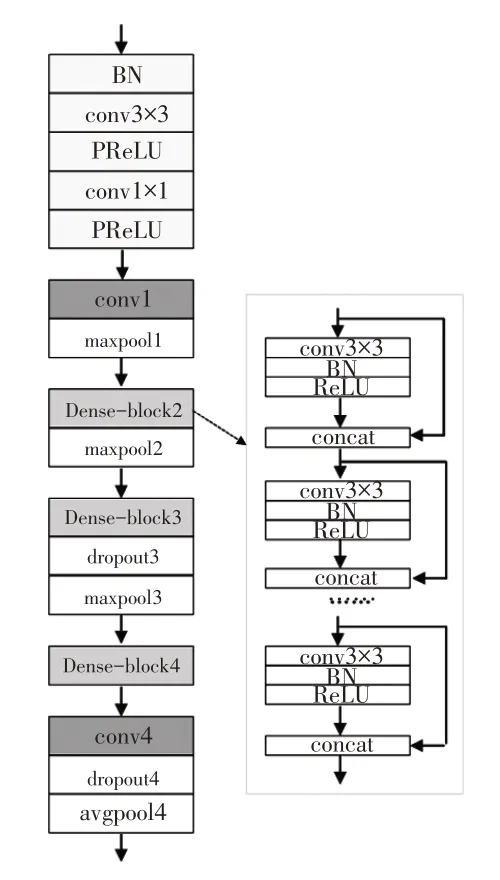
图4 交通标志牌识别整体模型
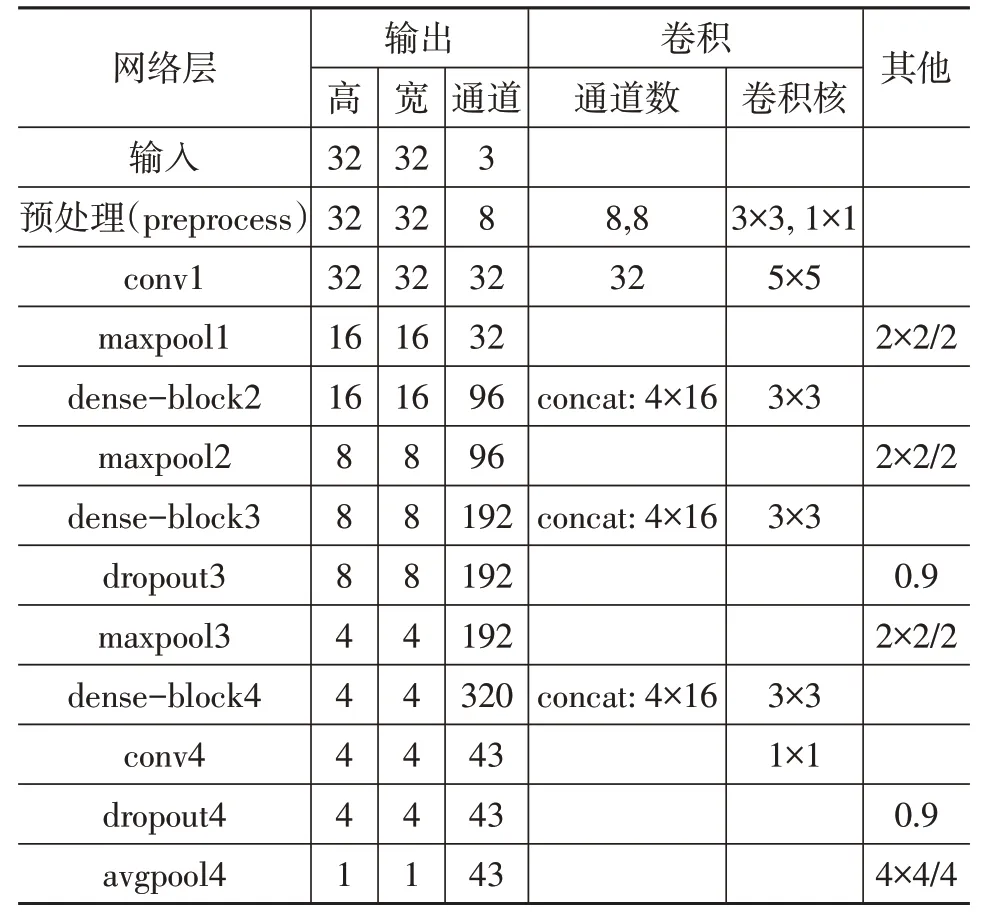
表2 模型参数
3 标志牌识别模型数据集扩增处理
考虑到国内目前还没有较为完善的交通标志识别数据集,本文采用德国交通标志牌数据集(German Traffic Sign Dataset,GTSD)[14]来训练和验证模型。该数据集包含43种交通标志类型,图片超过50 000张。
3.1 训练集
由于GTSD训练集中各交通标志类型图片数量并不均衡,因此,在训练集中每个交通标志类型随机选取5张图片。
3.2 训练集扩增
为防止模型训练过程中出现过拟合现象,通过对图片进行翻转操作和数据增强操作扩充训练集数量。翻转操作包括水平、竖直翻转,和先水平翻转再竖直翻转;数据增强操作包括形态、视角、亮度、对比度、裕度等变换。
经过翻转操作,训练集图片数量达到62 259张。为了保持各类型图片数量均衡,重采样训练集,使得每类图片为20 000张。数据扩增后训练集数量增至860 000张,图5所示为部分扩增处理后的图片。

图5 训练集部分扩增图片
3.3 验证集
GTSD验证集中各交通标志类型图片数量也不均衡,因此在验证集中每个交通标志类型图片随机选取5张。综上,数据集图片数量及格式如表3所示。
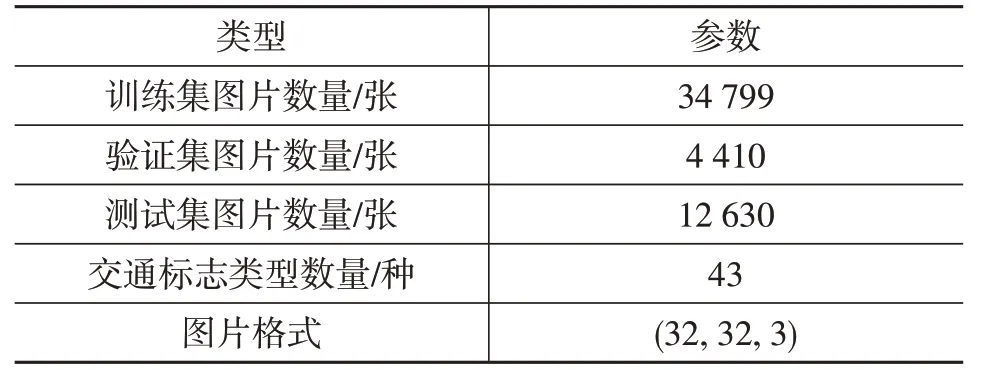
表3 数据集数量及格式类型
4 训练与性能验证
4.1 模型超参数设置
4.1.1 损失函数
本文损失函数包含SoftMax分类交叉熵损失和L2正则损失。损失函数优化解析器采用随机梯度下降(Stochastic Gradient Descent,SGD)算法,批大小设为128,遗忘因子设为0.9。
4.1.1.1 SoftMax函数
设SoftMax函数ς的输入为C维向量z,输出为C维向量y。y中的元素值在0~1范围内,定义如下:

对于给定的输入z,每个分类的概率可表示为:
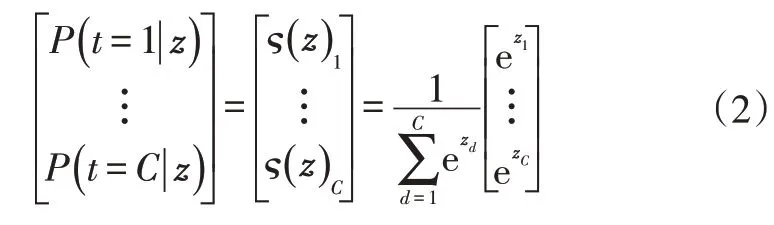
其中,P(t=c|z),c=1,…,C为给定输入z时输入数据是c分类的概率。
定义:

设i,j=1,…,C,对yi求导,有:
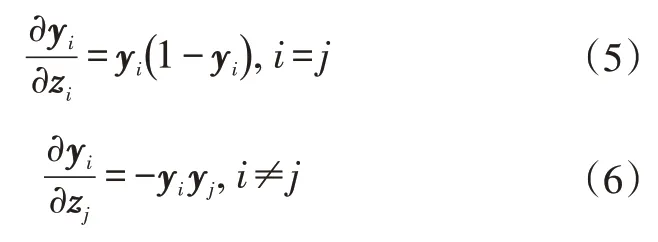
损失函数ζ对zi的导数,即交叉熵损失函数为:
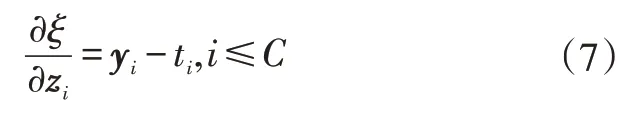
式中,ti为真实的分类结果。
4.1.1.2 L2正则损失函数
L2正则化公式为:

其中,C0为原始代价函数;第2项为L2正则化项;w为权值参数;n为训练集样本数量;λ为正则项系数,用于权衡正则项与C0项的比重。
4.1.2 动态数据扩增策略
训练样本扩增后,为使网络适应训练数据的变化,在模型训练时采用动态数据扩增策略。随机动态选择80%增强操作处理后的图片和20%未进行增强操作处理的图片混合成新的训练样本。
设模型迭代R次,每次迭代过程中使用混合样本进行E次SGD损失函数优化。本文分别取R=9、E=24,则全部迭代次数为216次。
4.1.3 学习率变化策略
训练网络时,学习率越大,网络中坏死的神经元越多,同时,为了避免不断改变的网络数据对后层网络输入分布产生过大的干扰,应采用较小的学习率。本文学习率变化策略如图6所示。
4.2 模型训练
4.2.1 数据集预处理结果
预处理激活层32×32×8格式图片的可视化结果如图7所示,在图7a~图7c中,输入由扩增训练集样本随机产生,图7d的输入由测试集样本随机产生。
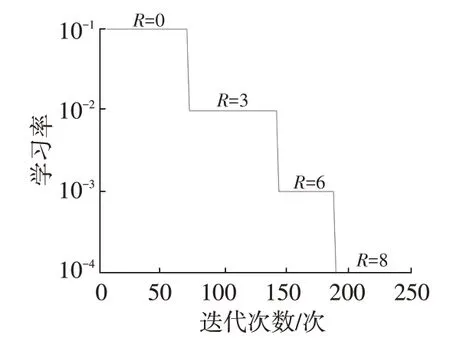
图6 学习率变化策略

图7 训练集样本和测试集样本预处理可视化
输出的8通道图像对蓝色和红色敏感,不受亮度变化影响。部分通道的激活效果较差,导致图像稍复杂时特征显示不明显。
4.2.2 训练结果
图8所示为训练集、验证集损失随迭代次数的变化曲线。显然,随着迭代次数增加,模型损失值下降。且验证集损失低于训练集,这是由于验证集图片没有进行增强操作处理,样本扰动小。
图9所示为训练集、验证集准确度随迭代次数的变化曲线。随着迭代次数的增加,模型准确度快速提高。在迭代80次后,验证集准确度稳定在99.9%以上。该结果表明模型的收敛性好,没有出现过拟合现象,且识别准确度高。

图9 训练集、验证集准确度
数据集测试结果如表4所示。
将本文构建的标志牌识别模型与当前性能表现优异的其他模型进行识别准确度对比,如表5所示,除了比工业级模型识别准确率稍低以外,该模型准确率高于其他识别模型。
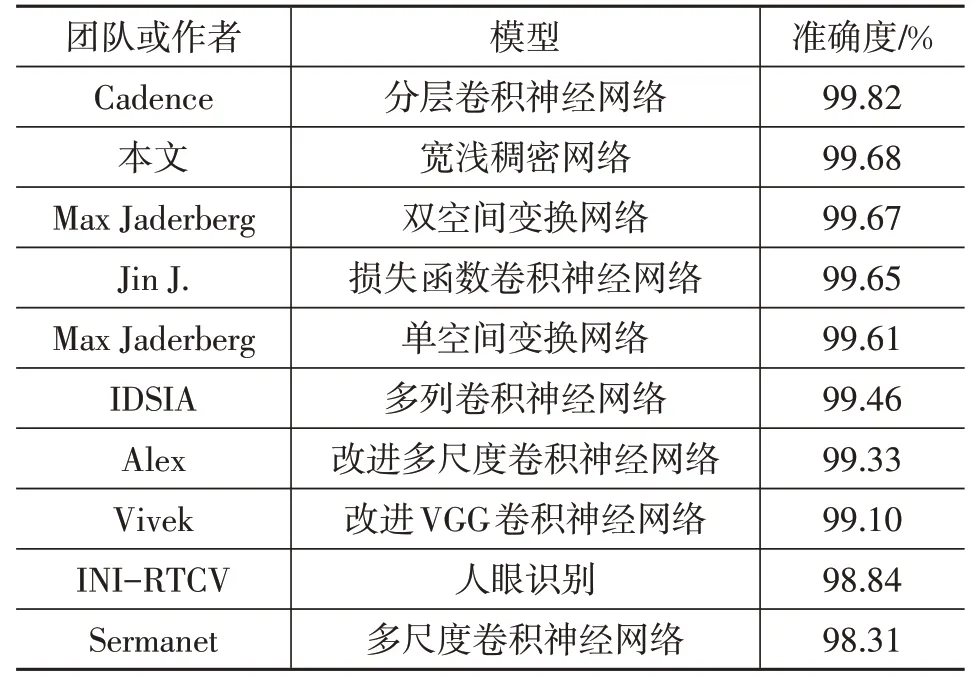
表5 交通标志牌识别模型对比[14-16]
4.3 性能测试
4.3.1 图像检测
选取德国常见的部分交通标志牌验证模型的实际检测识别效果。表6中标志牌原始图像表面无遮挡,颜色鲜明、图像清晰、外型完整,用于测试模型在一般环境下的识别效果;表7中标志牌原始图像在雨雪、大雾天气下拍摄,存在光照较弱、表面遮挡、褪色模糊、外形残缺等问题,用于测试模型在特殊环境下的识别效果。考虑到模型的实用性,将完整的采集图像导入网络,采用像素级判断和边框回归[17]相结合的方法在图像中定位标志牌。

表6 德国交通标志牌清晰图

表7 德国交通标志牌模糊图
图像检测结果表明:一般环境下,本文所构建、训练的模型能准确检测到图像中标志牌的位置,有其他相似标志牌干扰的情况下未出现误检,多个标志牌同时存在时无漏检,如01.jpg、06.jpg、07.jpg。特殊环境下,当标志牌被不同程度落雪覆盖、部分标志牌未进入图像时(如09.jpg、13.jpg),该模型依然能准确检测到图像中的标志牌。试验表明,本文所构建的模型抗干扰能力强、鲁棒性好。
4.3.2 图像识别
模型检测到交通标志牌后进行分类识别,针对模型识别性能,本文给出置信度前5位的标志牌识别预测结果,如表8、表9所示。
由表8可知,在一般环境下,标志牌外形清晰、颜色鲜明且无缺损,模型能准确判断出标志牌类型。05.jpg中“13:减速让行”和“40:环岛行驶”识别置信度轻微降低,是由于标志牌距离较远,采集到的图像信息相对较少,对模型的分类判别稍有影响,但仍能分别以0.994 975和0.972 131的高置信度识别标志牌类型。
由表9可知,在雨雪等恶劣环境下,标志牌表面模糊不清或部分不全,对模型识别准确度有较大的影响。
09.jpg中“30:路面结冰”标志牌被雪覆盖只显示出一半图像,模型将一半的图像信息提取特征后,除与真正的标签图像特征相匹配外,还与其他4种具有相似特征的图像进行匹配,最终以0.817 231的置信度正确识别标志牌类型。表明该模型提取图像特征能力强,在只出现部分图像特征信息时,也能以最大置信度正确识别。11.jpg和13.jpg的结果也证明了该性能,这是由于在扩增训练数据集时对图像进行了上、下、左、右4个方向的偏移、移动后,空余部分像素置为0,这一操作增强了模型的特征提取能力和抗干扰能力。
10.jpg、12.jpg标志牌完全被雪覆盖,图像模糊不清,其中“9:禁止超车”标志牌被雪严重覆盖,人眼也难以辨别清楚,因此模型识别失败,“30:路面结冰”“3:限速60 km/h”被雪覆盖程度较轻,虽然对模型识别产生了一定的干扰,但最后仍能正确识别。这表明本文设计的宽浅稠密网络模型泛化能力强,即使在图像信息被破坏的情况下,仍能提取出关键特征,在特殊环境下,模型均以最大置信度正确识别标志牌。
该模型优异的性能主要依赖于两点:稠密网络结构具有优异的特征提取能力,能高效获取图像主要特征;进行了数据集扩增处理,使模型抗干扰能力增强。
5 结束语
本文基于稠密网络设计了交通标志牌识别模型,通过预处理网络粗略提取图像特征,并以宽浅稠密网络设计特征提取层。同时,对数据集进行了扩增处理以增大训练集样本数量,训练中采用动态数据扩增策略以增强网络适应能力。训练结果表明,模型收敛性好,无过拟合现象,在测试集上识别准确率达99.68%。在一般和特殊环境下验证了模型的检测识别效果,该模型表现出良好的鲁棒性和泛化能力,抗干扰能力强,识别准确度高。
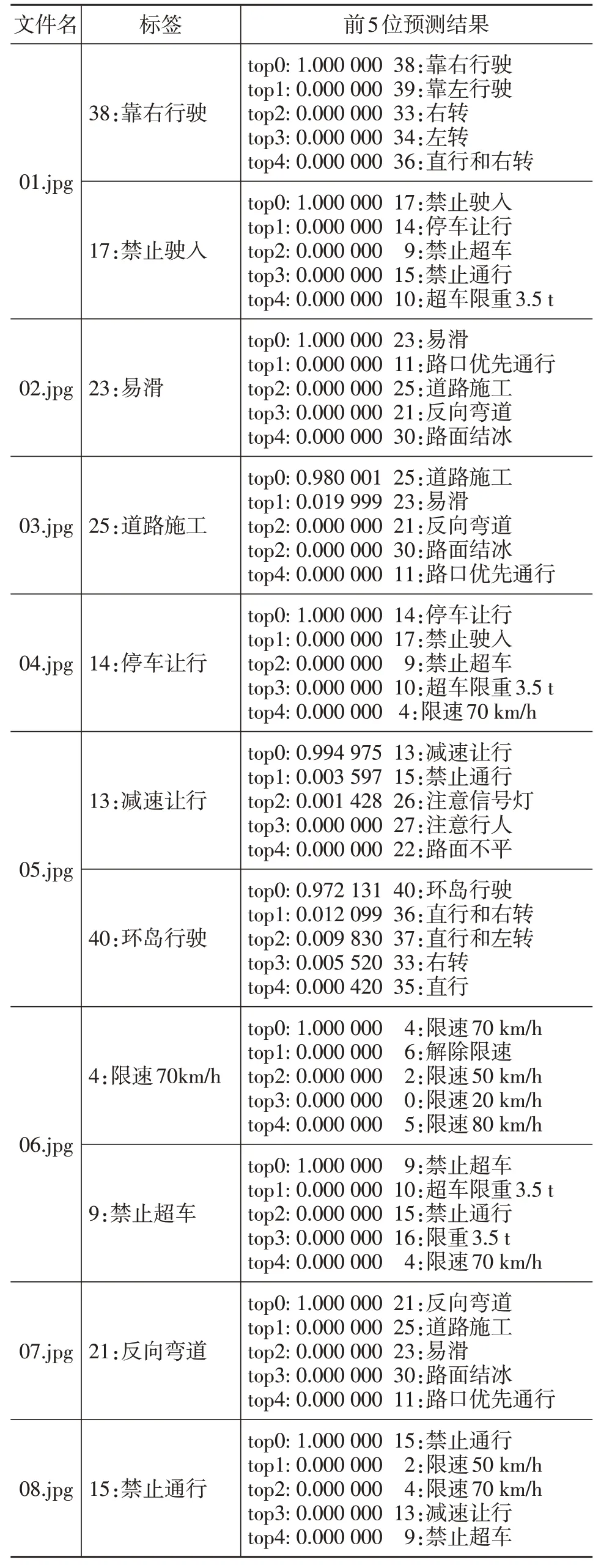
表8 一般环境下标志牌识别结果

表9 特殊环境下标志牌识别结果
本文模型在台式机上进行测试,而实际的TSDR系统运行在嵌入式平台上,硬件平台的不同可能影响模型的实时性与准确度。因此,基于嵌入式平台的模型优化是需要进一步考虑的问题。
