基于语音比对的远程面试身份认证
2020-01-11林晓勤毛敏宫玲玲吉理
林晓勤 毛敏 宫玲玲 吉理

摘要:用简易实时通信软件进行的远程面试有替考漏洞.为此,本文提出了一种基于语音对比的简便远程身份认证方案:接受面试者只需要使用通用的通信软件,不需要安装特殊的软件或特殊硬件系统,这对于接受面试者在边远地区或国外尤其便利.主考官在电脑上安装音轨抓取和录屏截屏软件,当面试者被录取后,采集现场无损音视频资料,将此资料和远程获取的同一面试者的音视频资料进行人工比对,实现以声纹认证为主的身份认证.为了验证方案的可行性,本研究进行了两轮实验,采集了来自7个不同国家的远程语音数据.通过一系列软件分析和人工比对,实验结果表明,本方案身份认证准确率较高,为后期的全计算机认证打下了基础.
关键词:远程面试;身份认证;声纹;语谱图;语音对比
中图分类号:TP391.4,H11
文獻标志码:A
文章编号:1000-5641(2020)06-0164-08
0引言
面试是现代人才测评中采取的一种主要的方法,它有着其他测评形式不可替代的优点,因此,面试在人才测评与选拔中日益受到人们的重视.随着互联网技术的飞速发展和实时音视频通信技术的成熟,远程面试因为具有节省双方资源的优势也被广泛应用.同时,“一带一路”带动下的国际合作日益紧密,跨国跨地区的远程面试也时常举行.由于在远距离面试中一般都采用公开网络通信系统,如skype或微信等进行,在客户端无法安装特定的身份鉴别设备,造成被试者身份认证有漏洞存在,出现“替考”现象.为解决这个问题,本文设计了一系列简单易行的方法,并通过实验验证了这个方法的可行性.
1身份认证技术在远程面试上遇到的困难(见表1)
身份认证有3种要素:
(1)根据用户所知道的信息,预先输入用户名+密码来证明身份的合法性.
(2)根据用户所持有的物件,可以证明身份的实体物件,比如居民身份证.
(3)根据用户本身的特征,人脸识别技术、声纹认证技术、签字认证等.其他高安全的身份认证技术如数字签名等在本研究的特定条件下不方便使用.
为了便于讨论,定义:面试官是测试者、主考官;考生为受试者、应聘者或者是应试人员,他们在远程端.为了在远程面试中远程验证考生的身份,防止替考,无法让考生预先输入用户名和密码,因为这个用户名和密码是考生主观记忆的,如果考生主观意愿替考,密码一定失效.可以证明身份的实体物件也是同样道理.剩下的只有考生本身的特征值得考虑用在我们的新方案中.
1.1人脸识别技术
人脸识别技术往往需要有一张或多张高清照片作为识别基准,然后提取被识别者的脸部特征数据,在远程面试中进行比对.但是在防替考的应用场景中,这个识别基准一般无法取得,除非是有案底的罪犯.只有在面试过程中尽可能清晰地将面试过程录制下来,以备将来可以使用这些录像资料进行后期比对.
1.2签字认证
签字认证过程需要被试者在主考官或者第三方公证人员的见证下签字,在录取后再次当面签字作为身份认证资料.对于本文所述的远程认证需求而言,预先获取签字很难实现.
1.3基于语音的身份认证
基于语音的身份认证,这是本文的重点,一般面试都可以评估考生的某些能力,而这些能力都是通过语言直接表达的,如果考生自己可以流畅表达就没必要找替考者了.当考生本身的语言能力和某个经济利益直接挂钩,语音认证就显得更加必要.然而目前常见的声纹认证系统需要预先录下高质量音频作为验证数据库的标准样本.技术领先的讯飞开发平台也需要先录制5遍动态音频作为先期数据保留.特定人的二字词识别需要10个特定词录音10遍,对于本文所述的远程认证需求而言,预先录制高清动态数据或特定词很难实现.
1.4语音身份认证原理
语音身份认证也称声纹,原理主要基于在电子学科、信号处理、声学等领域有着广泛应用的傅里叶变换原理,即不管多么复杂的电声信号,总是能表示成若干个(或无穷个)正弦信号的组合。因此,语音作为信号的一种,也可以被分解为一系列不同频率谐波的组合,在实验语音学理解中,通常情况下,具有最低频率及最大振幅的被称为基频,其他各次谐波从小到大依次被表述为第一、第二、第三共振峰,共振峰理论上有无限多个.这些基音频率和共振峰是语音的最基本的信息,可以被专业工具(如PRAAT)抓取,它们是反映发音人声学特征的重要参数.同一个发音人,这些参数是一致的,对于工程应用而言,前几个共振峰一致就足以判断了。
第一轮实验证明(见第3章),经过远程传输压缩的语音信号不会损坏声纹的主要特征,在考生录取后获取无损语音信号,可以进行声纹认证.
2防远程代考的解决方案
对于防代考型身份认证,在考官端安装音轨抓取软件和录屏软件,同步记录面试的全过程,面试官可以在需要时按下截屏开关,记录面容清晰的截屏图像、签字图片,保存到数据库中.
当一部分考生被录取后,可以用高清摄像录音设备录制考生资料图像和特征音频.对有疑问的考生运用下面的操作进行进一步的身份认证.
首先调出视频中的人脸图像进行比对,其次对视频中的签名图像进行比对,最后用声音比对.由于人脸和签名都是图像信息,数据量大,远程传输后容易丢失,声音文件的相对数据量就小很多,当比对结论汇总后就可以得出身份认证的结论.
声纹认证过程中,在远程面试中取得的声音文件是“有损”的,也就是经过考生端的设备压缩和网络传输损失了音频中的不少高次共振峰.在第3章中第一轮实验证明了经过压缩的声音在现场无损录音的帮助下仍然可以作为声纹鉴别使用.第二轮实验我们选取了7个国家12位留学生的声音资料进行人工听辨,表明结果有效.
3声纹身份验证实验及结果
到目前为止,人耳仍然是最佳的语音识别器,但是我们还需要用实验语音学的实验给予证明:先录制压缩有损音频(网络音频)后录制无损音频,可以用于声纹认证.这是第一轮实验.同一发音人的声音同时用两套录音设备录制,其一是无损录音机,就在发音人旁边,其二是经过网络远端被压缩传输的微信语音,使用电脑录制,如图1所示.
3.1第一轮实验音源采集
观察通过网络传递的压缩语音信号和现场高保真设备录制的信号,并分析其中的语音要素.实验方法:随机选取12个发音人,男女各半,年龄在20~40岁,发音人同时面对一台苹果手机和一台专业录音设备,其中苹果手机登录微信语音聊天和远端的电脑联机,电脑端录制通过微信传输的对话音频;发音人身边的高质量录音设备录制现场声音,其过程如图1所示.录制了12对音频资料,有效的11组数据完整记录了同一个说话人在同一个时刻说同几句话的音频资料.
高品质音频录音采样频率44Khz,24bit采样深度,网络音频在100kbit/s的码流MP3格式.
由于网络传递声音为了降低流量都采用有损压缩形式传输,主要格式和MP3接近.在传输过程中,主要运用人耳的掩蔽效應动态调整音频带.在传输MP3格式的音频文件时,使用“知觉编码”技术,其中包括最少听觉阈限(theminimal audition threshold)、屏蔽效果(themasking effect)、字节蓄积(the reservoir of bytes)、接合立体声4项技术,目标是减少传输文件的体积和码流.
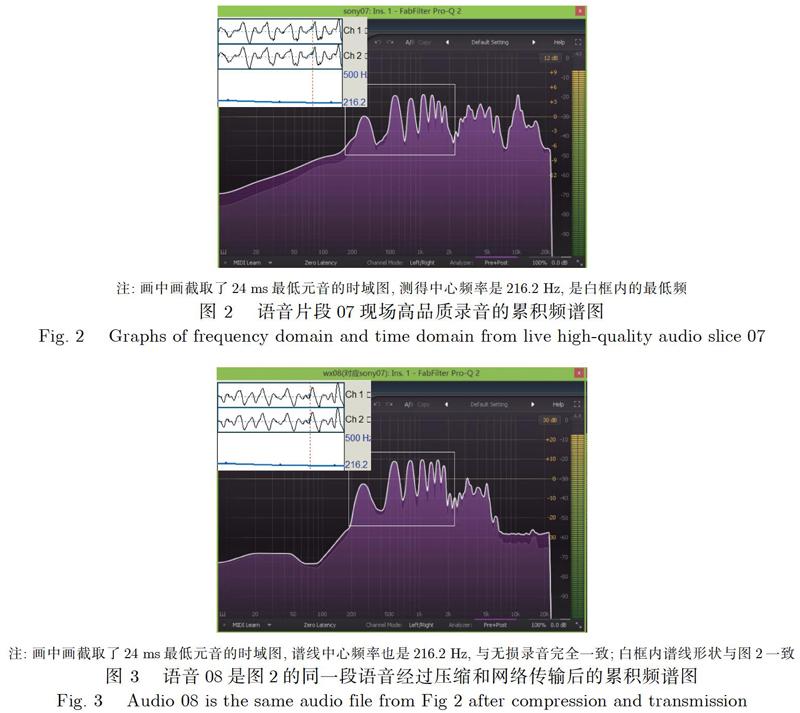
图2所示累积频谱图是采样率44K、比特深度24bit的cubase软件分析结果截图.图3所示为同一说话者语音片段07经过压缩和网络传输后的累积频谱图.与图2相比,2.5Khz以下的7个特征频率点几乎完全相同,100hz以下和3Khz以上的7个特征频率点都有明显的衰减,对于现场录音中10Khz的大干扰信号,压缩后几乎消失.但白线框内的谱线形状一致、幅度不同,表明发音人特征一致.
图4和图5分别是语音片段07高品质录音约0.6s语音瞬时的频谱抓取和同一说话者语音片段07经过压缩和网络传输后0.6s的瞬时频谱图.注意图5垂直虚线处的4条共振峰,和图4几乎完全一致.
3.2第一轮实验结论
(1)同一个说话者通过远程传输和现场收声两种方式采集的声音基本不影响听辨内容,听感音质有所区别.
(2)通过远程网络传输的声音累积频谱图发现,其中中频部分相比现场收声保留度较完整.但200hz以下的低频和3Khz以上的高频由于压缩和传输的原因损失很大,语音的要素都基本保留,图中白框内.
(3)分析Praat软件抓取的瞬时共振峰(谱图)发现在5K以下几乎完全一致,5K以上的成分因为对听感和意义听辨关系不大,软件不做分析.
所以,先期用有损信号,后期再用无损录音进行声纹验证的技术是可行的.下面进行了第二轮实验.
3.3第二轮实验数据采集
为了使防替考方案更完善,第二轮实验的目的是用人工听辨的方式在3个以上干扰项中区分出同一发音人.
为模拟远程面试场景,这次的远程数据收集来自7个国家:尼泊尔、孟加拉、韩国、俄罗斯、泰国、乌兹别克斯坦、印尼,语音数据来自2017年留学生暑假回国期间所交的口语作业.作业形式,通过微信语音聊天形式,在留学生的家乡和在中国的汉语教师进行通话交流,在交流过程中,留学生被要求用中文说一段话,实验者记录这段语音.这段语音资料在下文中被称为微信声W,如W3为第三位学生的微信声音资料.
当这些学生回中国上课后,实验者再用高保真录音设备现场采集这些留学生的声音资料,请这些学生朗读一段语音.下文将这些音频称为现场声X,同样,X3为第三位留学生的现场录音资料.
收集留学生的声音资料,分为微信声和现场声,通过人工听辨选出相匹配的声音,来测量人工听辨的匹配率.人工听辨没有要求说话者在微信音和现场声中说同样的话,因而不适合机器分辨.
3.4第二轮实验方法
(1)截取声音源 微信声比较长,约10min,单声道声音.每个学生的声音可以截取5段,如W4-1是第四号学生的第一段语音,1min左右;W3-4就是第三个学生的第四段语音.
(2)制作测试文件夹 测试文件夹命名为TB文件夹,按照编号递增.每个TB文件夹内包含一个现场声和5个微信声(微信声选取5个同性别不同的学生的录音,必须包含和现场声匹配的微信声,其他4个为干扰声),微信声不重复使用.再制作两个干扰组,不含和现场声匹配的微信声,比如6组,X6在组内,但W6不在组内.将TB文件夹中选取的微信声重新进行编码,每个文件夹中用P1-P5表示5个微信声.测试文件夹如图6所示.
(3)制作听辨记录表 记录每个听辨文件夹的听辨结果.记录听辨人的编号、年龄和性别,听辨人如果听到结果认为P2和X是同一人,就在P2下写下听辨结果,可以分档95%、85%、75%、65%、不确定.如果确定文件夹内没有相同的说话人,则勾选“没有相同的说话人”.听辨结果表示:如果结果是P2,100%,说明听辨者100%确信X和P2是同一人.测试记录表如图7右侧所示.
3.5第二轮听辨实验数据分析
本研究的第二轮实验制作了听辨结果表,如图7所示,每位听辨人都要在听辨过程中填表.
3.5.1熟人听辨
熟人听辨选取了3位国际汉语文化学院的教师,他们都教过样本留学生课程,对学生们的声音较为熟悉.让他们用头戴式耳机仔细听音频,并填写听辨记录表.
熟人听辨组的实验结果如图8所示,所有小组听辨正确率均为100%,且听辨者对自己的选择结果很有信心,每组都有90%以上的把握认为自己选择正确.本组实验数据说明,通过熟人听辨的方法可较为准确地辨别出不同音源是否属于同一个人,熟人听辨在语音匹配中可行性较高.
3.5.2陌生人听辨
听辨人随机选取,和录音学生互不相识.每组选6个听辨者,用头戴式耳机仔细听,并填写听辨记录表.听辨过程是双盲法.
听辨记录结果如图9所示.图9呈现的数据显示,第1、2、5、7、10组陌生人可以很容易地选择出相匹配的音源,而第9组和第11组陌生人全部选择错误,同时图9显示仅有5组听辨者认为有50%以上的把握选择正确.这说明在听辨实验中,采取陌生人听辨的方式成功匹配音源的概率不是很高,误差也很大.
选择错误的原因分析:课题组对第9组和第11组的音频材料进一步分析表明,这两组微信音频的共同特点是有效电平很低,导致输出只能勉强听到语音内容,信号噪音比很差,而表达声音特征的音色差异都集中在中高频区域,导致听辨过程中实验人无法确定声音的音色.后期访谈发现第9组和第11组发音人可能使用了免提功能,话筒离发音人太远,在数据采集过程中面试官也没有及时提醒.
而熟人组听辨者都是这些留学生的语言课教师,他们除了熟悉发音者的音色外,还对发音人的汉语语用、语音缺陷十分敏感.访谈表明,正是这些缺陷和音色的组合,使汉语老师可以有把握确定发音人的身份.
4声纹验证实验总结与展望
4.1可采用熟人听辨来对远程语音面试进行声纹认证
从实验数据中可以看出,熟人听辨的准确率非常高,且听辨成功的把握也非常大.通过陌生人听辨,实验者发现,在远程传递声音过程中,传输音质会发生一定损失,使音频失真,导致陌生人难以正确听辨.而由于熟人对音源的音色、音质以及相应的语音缺陷较为熟悉,即使在声音信噪比小的情况下,熟人也可以根据声音的一些特质来辨别出音源.因此远程语音面试之后,选择熟人听辨的方法对声音进行辨别,可较为准确地识别出音源是否相互匹配.
4.2在远程语音面试中合理指导考生
考官可以在调试音频系统的过程中要求每个考生念几个特定音节的词组或短句,本研究过程中是请发音人在远程对话和近程高清录音中念同一段唐诗,以便留下相同语音内容作为比对证据.
在远程音频传递过程中,网络带宽、录音设备、编码方式等均会影响音频的质量.在远程面试中,本研究发现,最大的音质破坏来自最初的录音阶段,一般在使用手机录音或交谈过程中不注意发音人和话筒的距离,有人几乎咬着话筒,而另一些人喜欢打开免提.咬话筒的人往往造成录音过载失真,而免提则非常容易产生录音电平不足和信噪比变差的情况.
面试官要指导考生合理运用设备,比如话筒和发音人的嘴巴距离25cm左右,不用免提功能,并在环境安静的地方录音和接受面试.
4.3机器识别设想
本研究的目的是在探究远程端无法安装身份认证设备和软件的情况下,审查远程面试是否存在替考行为,实验证明是经济可行且准确率相当高的方法.缺点是最后的鉴别仍需要人工参与.目前已经有研究者利用人工智能深度学习的方法自主提取语音特征進行自动认证,人工智能的介入将大大提高鉴别效率.
