基于门控循环单元模型的在线路网匹配算法
2020-01-11陈良健许建秋
陈良健 许建秋


摘要:路网匹配是道路网轨迹数据分析领域的一项关键技术,一个快速且准确的路网匹配算法能够为上层应用提供良好的技术支持.随着轨迹数据的爆炸式增长,现有的在线路网匹配算法存在延时的现象,尤其是在低频轨迹数据的环境下,无法快速地对轨迹数据进行路网匹配.神经网络和深度学习的发展为解决这些问题提供了新的方法.提出了一种利用门控循环单元(Gated Recurrent Unit,GRU)模型快速定位轨迹采样点的候选路段、从而加速在线路网匹配计算的方法,并将此方法和最新的在线路网匹配算法进行了实验比较.结果表明,基于GRU模型的在线路网匹配算法能够有效地加快匹配过程,提高匹配效率.
关键词:在线路网匹配;移动对象;门控循环单元模型
中图分类号:TP392
文献标志码:A
文章编号:1000-5641(2020)06-0063-09
0引言
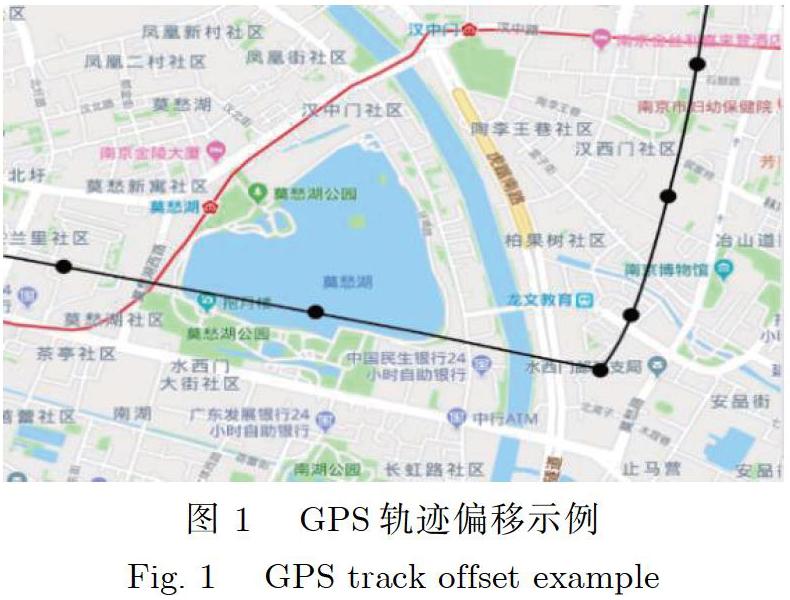
近年来,随着位置感知技术的发展以及定位系统(如GPS、北斗系统)的普及,出现了越来越多的位置感知类应用,如网约车、共享单车等.这些应用在系统使用过程中跟踪和记录移动对象的位置信息,产生大量的时空轨迹数据.但是由于设备精度或地理环境因素,收集到的轨迹数据与真实的路线存在一定的偏差.如图1所示,GPS轨迹采样点并没有落在移动对象实际行驶的道路上,存在一定的空间偏移.这对位置感知类应用的服务质量和轨迹数据分析带来一些挑战.路网匹配技术就是根据轨迹的采样点分布,并结合路网信息推断移动对象实际行驶路径的过程.路网匹配技术是交通管理、路由规划、实时导航等应用中的基础技术,已被广泛地运用于城市计算与智能交通领域.
现有的路网匹配算法按照运用场景一般分为两大类:离线匹配和在线匹配.离线匹配针对的是历史轨迹数据,即在得到移动对象产生的一条完整的轨迹之后再推断移动对象实际行驶的路径.离线匹配在匹配时可以充分考虑轨迹的上下文信息.相反地,在线匹配算法针对的是实时数据,在接收到移动对象的最新位置信息时,立即返回移动对象所行驶的路径,这种情况下只能获得移动对象在当前采样点及其之前的轨迹信息,而无法获得完整的轨迹信息,所以具有一定的难度.例如(见圖2),如果利用在线匹配算法,在匹配到t3采样点时,因为t3距离路段2较近,且路段2的道路宽度更宽,表明从路段1到路段2的转移概率较大,所以按照目前的许多在线匹配算法,很可能就匹配到了错误的路线上.而离线匹配算法在匹配t3采样点时可以获取到t4采样点的信息,能够直接匹配到正确的路段3,从而获得更高的匹配准确率.但是,实际生活中的很多应用,如汽车实时导航、交通实时监测系统,这些与位置有关的应用需要在接收到移动对象的位置信息后立即计算匹配结果,并对其做出响应,所以需要采用在线路网匹配技术.而且随着智慧城市以及智能交通系统等概念的提出和推广,在线匹配算法的应用场景将变得越来越广泛且重要.
常见的在线匹配算法一般采用时间窗口技术,即存储最近一段时间的轨迹采样信息,当满足一定的收敛条件时推测出的最可能路段序列,这种算法在一个采样点到达之后并不能立即计算得到移动对象目前行驶的路段,而是需要达到一定的收敛条件,所以存在一定的滞后性.并且这种算法需要在两个连续采样点之间计算所有可能的路径,算法代价较大.最近几年出现了一系列基于隐含马尔科夫模型(Hiddenmarkovmodel,HMM)的在线路网匹配算法,但是基于隐含马尔科夫模型的算法复杂度较高,仍然存在一定的延时,在稀疏的轨迹数据集上表现不好;且现有的路网匹配算法在计算候选集时一般借助空间索引比如R-tree或者Quad-tree来剪枝,搜索效率不高,不适用于大规模实时数据并发的场景.
近年来随着神经网络和深度学习的发展,人工智能技术渗透到数据处理领域的方方面面.在处理时间序列数据时,循环神经网络(Recurrent Neural Network,RNN)以其特殊的结构拥有一定的记忆能力,是处理时间序列数据的一个很好的工具.但是直接利用RNN进行路段预测在轨迹过长的情况下会带来长程依赖问题.基于此,本文提出了一种基于RNN变体——门控循环单元(GRU)的路网匹配加速算法,在计算候选路段时,根据轨迹之前的信息和目前收集到的轨迹采样点直接定位最大概率的候选路段,不需要对道路网建立空间索引,减少了根据时空位置计算候选路段集以及搜寻所有可能路径的过程,加速了路网匹配计算过程.测试结果表明,基于GRU模型的在线路网匹配算法在匹配效率上远高于目前的在线匹配算法.
本文结构如下:第1章简要介绍路网匹配,尤其是在线路网匹配的研究现状;第2章定义在线路网匹配问题;第3章介绍基于GRU模型的路网匹配算法过程,包括路网模型的建立、GRU模型的构建和优化目标的提出;第4章将本文提出的算法与现有的在线路网匹配算法进行分析和比较;第5章总结全文.
1研究现状
路网匹配算法主要分成基于几何的匹配算法、基于拓扑结构的匹配算法、基于概率的匹配算法以及其他先进匹配算法.基于几何的路网匹配算法利用路网和GPS轨迹的几何形状特征进行匹配,包括点到点(point-to-point)匹配、点到曲线(point-to-curve)匹配、曲线到曲线(curve-to-curve)匹配.基于拓扑结构的匹配算法利用路网的拓扑结构信息,如路段之间的相连、相交等关系,再结合历史数据和车辆速度等信息来对候选匹配路段进行剪枝.如Brakatsoulas等利用道路网的几何拓扑信息及GPS数据之间的各项相似性标准进行路网匹配,并采用弗雷歇距离(Frechet distance)来衡量两者的匹配程度.其他先进的路网匹配算法包括卡尔曼滤波、模糊逻辑模型、隐含马尔科夫模型(HMM)、机器学习等.这些算法利用先进的技术手段或数学模型,匹配准确度较高,但是当采样频率较低时,效果仍然不佳.高文超等和Ta等对目前的路网匹配算法做了全面的分类、总结和分析.
3.3模型优化目标
路网匹配可以视为一个多分类(Multiclass Classification)问题,每一个GPS采样点可能匹配到整个路网中的任意路段.所以对于损失函数的选择,一种朴素的方案是直接使用交叉熵.具体地,1条GPS序列可以看作1个样本,单个样本的交叉熵损失Lossi定义为
然而,在路网匹配任务中,路段之间存在拓扑结构.采用这种简单的方法无法捕获路段之间的位置关系,对预测错的路段不管距离远近都施加同样的惩罚,导致模型无法感知路网空间距离,训练时收敛较慢,而且容易带来过拟合问题.例如,假设有如图4所示的道路网,移动对象行驶路线如图中带箭头黑色实线所示,其正确的匹配路径结果应当为①②③④,当其行驶到②路段时,产生一个在图中黑点所示的轨迹采样点,如果模型错误地匹配到⑤,那么实际上和错误地匹配到⑥产生的惩罚效果是一样的,但是在实际应用中,人们更能接受算法将其匹配到⑤,而不是毫不相关的⑥.
为了在模型预测的结果中同时考虑路网之间的位置信息,对原损失乘一个距离乘数k,给实际路段偏差较大的预测结果施加更大的惩罚因子,这样就可以让模型感知到路段之间的空间距离,从而加快模型收敛速度.具体地,定义损失函数
上述目标可以通过梯度下降法进行优化.模型训练完毕后,即可对新样本进行预测.预测过程的简要流程见算法1.
算法1首先初始化隐藏状态(行1).对于每次接收到的移动对象的采样点ti,算法将对其进行归一化处理得到输入向量ui(行3),随后,模型对输入向量进行预测并输出结果oi(行4),根据输出结果直接定位当前的预测路段,然后采用最短路径连接上一回合的预测路段和当前预测路段,直到移动对象产生一条完整的轨迹序列.
4实验结果分析
4.1实验数据
实验的路网数据采用南京市的路网数据.轨迹数据采用南京出租车产生的真实GPS轨迹数据.在训练过程中,采用离线路网匹配算法HMMM对轨迹采样点所在的路段进行标记.在实验中,分别测试不同采样频率下各个算法的准确率和性能,不同采样频率的轨迹是在原始轨迹下通过二次采样产生的.实验数据的基本信息见表2.
在训练和比较高频轨迹数据集时(采样点时间间隔小于30s),随机选择10000条作为测试数据集,其余则划分为训练集.由于长度较长的轨迹较少,所以在训练低频轨迹数据时,二次采样会进行重复采样.最后,得到15000条完整轨迹,训练数据集大小为10000条,测试数据集大小为5000条.
4.2实验环境
实验在Ubuntu14.04环境下进行,采用Python3.6语言编写,利用Pytorch1.0深度学习框架;CPU为Intel Xeon(R)1.90GHz×6,GPU為NVIDA Corporation GM107GL[Quadro K2200],32GB内存.
4.3实验结果
实验首先采用正交初始化进行模型的权重初始值设定,初始偏移值设为0.每训练1条轨迹序列则进行1次梯度更新,直到训练完所有的训练数据.高频轨迹的训练时间约为4h,低频轨迹的训练时间约为1h.然后将本文的基于GRU模型的路网匹配算法分别与文献[14]中提出的OHMM算法、文献[15]提出的INC-RB算法在准确率和效率这两个方面进行比较.
图5给出了准确率的实验结果,横轴为不同的采样频率,纵轴为具体的准确率值.准确率的计算方式为算法预测准确的路段与总路段之比,从图5中可以看出,在高频采样段,基于GRU模型的路段预测算法的准确率会稍低于INC-RB算法和OHMM算法,但是也接近94%;随着采样频率的降低,INC-RB算法和OHMM算法的准确率会逐渐衰减,而基于GRU的算法的准确率仍然能够保持在一个较高的水平.
图6给出了基于GRU的路网匹配算法与INC-RB和OHMM在效率方面的比较,横轴为不同的采样频率,纵轴为算法的处理速度,单位为每毫秒处理的采样点个数,在图中可以看到基于GRU的路网匹配算法不管在低频轨迹数据集还是高频轨迹数据集中,效率上都远超上述两种算法.从高频数据转为低频数据的过程中,由于GPS采样点之间的距离较远,所以INC-RB和OHMM的计算量较大;而由于在低频轨迹数据中,每条路径中的采样点个数相对较少,所以基于GRU模型的路网匹配算法需要在测试时不断进行初始化,导致统计时的效率变低.
5结论
本文提出了一种利用GRU模型对路段直接进行定位的在线路网匹配算法,和目前最新的在线路网匹配算法相比,基于GRU模型的路网匹配算法不需要对路网建立索引,匹配时不需要遍历索引产生多条候选路段,也不需要搜索多条推测路径,从而大大加快了路网匹配过程.在以后的研究工作中,为了应对更大的道路网环境,可以将图进行分割,减小GRU的选择范围;同时由于本文算法还未考虑额外的一些信息,如移动对象的速度和方向,故将来可以从GPS轨迹中提取这些额外的信息进行训练,从而更进一步提高算法的精确性.
