CedarAdvisor:负载自适应的自动化索引推荐工具
2020-01-11阳文灿胡卉芪段惠超胡耀艺钱卫宁
阳文灿 胡卉芪 段惠超 胡耀艺 钱卫宁


摘要:索引在提高查询性能方面可以起到至关重要的作用,数据库管理员的一项重要工作是为数据库选择合适的索引.但随着数据库工作负载的不断复杂、数据量的持续增加、库中关系表的逐渐增多,人为地分析工作负载成本、选择合适的索引并估算数据库空间变化情况变得越发困难.本文设计了一款面向负载的自动化索引推荐工具——CedarAdvisor.它从日志中自动化收集负载,统计查询频率,在为单条查询生成候选索引的基础上,评估索引收益与代价,通过动态规划算法生成整个负载的索引推荐.最后我们在分布式数据库上验证了工具的有效性.
关键词:数据库;工作负载;索引推荐
中图分类号:TP392
文献标志码:A
文章编号:1000-5641(2020)06-0052-11
0引言
随着互联网应用的不断发展与成熟,在云计算、大数据、人工智能等新技术的带动下,数据的绝对量在以惊人的速度不断膨胀.根据DELL公司一项预测显示,2020年全球生产的数据量达到40ZB.在大数据领域,数据筛选是对海量数据进行发掘与分析的基础,而数据筛选面对的场景具有数据量庞大、数据多节点存储、查询业务繁多等特点.如何高效地对海量数据进行查询、分析、处理和更新,为政府、企业、组织提供决策支持,一直是学术界和工业界共同关注的一个研究方向.
如今,当在数据库中面对海量数据进行查询操作时,索引在提高查询性能方面可以起到至关重要的作用.在查询执行过程中,通过查询索引表的方式替代全表扫描,可以大幅缩短查询时间.然而,索引在缩短数据项搜索时间的同时,也增加了额外开销,主要体现在:(1)索引需要额外的存储空间;
(2)使得更新操作复杂化,因为在对基表进行更新操作时,需要对相应的索引表进行同步更新.
因此,在日常业务中,为了确保系统在面对工作负载时保持良好的性能,如何为工作负载选择一组合适的索引是数据库管理员面临的一个重要问题,即索引选择问题(Index Selection Problem,ISP).但随着数据量的大幅增加、工作负载的复杂性和动态性的不断增加,数据库管理人员面临着更为困难的挑战.如何减轻数据库管理员的工作难度、降低维护数据库系统的人力成本,成为当前数据库研究领域的一个热点问题.
本文以数据负载索引选择问题为出发点,总结了部分商用数据库的自动化索引推荐工具,提出了一种基于规则与基于代价相结合的负载自适应索引推荐模型,并实现了一款索引推荐工具——CedarAdvisor,最后在分布式数据库上验证了工具的有效性.
本文的主要贡献如下:
(1)实现了一个基于规则与基于代价相结合的负载自适应索引推荐模型.
(2)实现了一个索引收益一代价评估模型.
(3)从候选索引空间中罗列所有索引组合配置复杂度非常大,本文采用动态规划算法在有限时间内得到最优或者接近最优的索引组合配置.
1背景和相关工作
人们从20世纪70年代就开始进行索引选择问题的研究.尽管研究时间很长,但有两个基本原因使得该问题尚未完全解决,首先,索引选择问题本质上是一个排列组合问题,对一个大型企业的生产环境数据库而言,有大量的表和列,难以在有限时间内枚举所有的索引组合情况.其次,难以通过用简单的搜索算法为负载找到一个最优的索引组合配置.数据库管理人员很难在时间有限、空间有限的情况下,为负载建立合适的索引.越来越多的数据库提供商力图通过自动化工具减轻数据库管理人员的工作负担,帮助企业降低数据库总运营成本.各大供应商对此进行了相应的研究并将研究成果应用在了自身推出的产品中.
(1)AutoAdmin microsoft公司的AutoAdmin项目主要研究数据库系统的自管理与自调优技术,并将研究成果应用到了SQL Server产品中,推出了针对SQL Server7.0的Index Tuning Wizard和针对SQL Sever 2005的Database Tuning Advisor.Database Tuning Advisor的执行策略是,将整个负载作为输入,逐条分析负载中的查询.首先为单条查询语句选出最优或者接近最优的索引,主要是通过分析负载语句中能够减少执行成本的结构,作为此条查询的候选索引空间,通过代价模型分析每个索引的收益,在不超过索引数量限制的基础上,通过贪心算法从候选空间中选出可以减少此条查询执行时间的索引,直至查询时间无法再减小.之后将所有单条查询的推荐索引作为整个负载的候选索引空间.接着对集合中的索引进行适当的合并,主要是将作用查询相同的索引合并为一个新的索引.最后,再次利用贪心算法从负载候选索引空间中选出整个负载的最优索引集合.
(2)DB2 Designer Advisor
IBM公司的DB2 Designer Advisor是IBM为DB2数据库研发的自调优工具,可针对工作负载提供索引、物化视图、数据分区等方面的建议.DB2 Advisor的索引选择基于的思想是,假设将所有可能的索引都注入数据库中作为虚拟索引(Virtual Index),通過DB2的查询优化器生成最佳的访问计划,如果计划中用到了一个或多个虚拟索引,那么这些索引就是单条查询的候选索引.但枚举所有可能的索引会使得候选集合过于庞大,因此DB2 Advisor通过使用DB2的查询优化器中的“Smart column Enumeration for Index Scans”(SAEFIS)算法限制候选索引数量.SAEFIS算法主要通过分析语句中的谓词条件、GROUP-BY、ORDER-BY条件,以生成可能在虚拟索引中用到的列集.DB2 Advisor通过“Brute Force and Ignorance”(BFI)算法枚举所有可能的索引,并在DB2中虚拟地建立索引,即索引并不真正建立,但查询优化器可以搜索到.调用查询优化器为单条SQL生成最佳查询计划.在查询计划中找出虚拟索引作为负载整体候选索引.理论上可通过查询优化器的“Mass Query Optimization”(MQO)技术为负载推荐最优索引组合,即调用一次查询优化器同时为多条SQL推荐索引,但由于MQO技术在商用数据库中并不支持,因此DB2 Advisor采用0-1背包算法解决负载索引推荐.
2 CedarAdvisor整体架构
CedarAdvisor索引推荐工具是基于小米SQL优化和改写工具开发的,面向整个负载的索引推荐工具.它从日志中自动化收集负载,统计查询的频率,在为单条查询生成候选索引的基础上,评估索引收益与代价.通过动态规划算法生成整个负载的索引推荐,并在分布式数据库Cedar上进行了测试.图1展现了该工具的主要执行流程.
CedarAdvisor索引推荐工具主要分为如下几个部分.
(1)负载收集:主要功能是从数据库的日志中提取执行的查询SQL作为工作负载文件,并统计每条查询的使用频率.
(2)语法解析:采用语法解析库将查询解析为语法树结构.
(3)候选索引:通过分析语法树中谓词条件、分组条件、排序条件选出候选列,通过数据库统计信息获取列信息、表信息,在估算选择率的基础上为单条查询推荐出最佳索引.全部查询的最佳索引构成了整个负载的候选索引空间.
(4)数据库基本信息获取:通过访问数据库,获取表和列的元信息、统计信息,为代价模型提供支撑数据.
(5)索引评估:估算每个索引带来的收益和成本.
(6)负载索引:通过动态规划算法,在有限的时间内选出相对最优的索引配置,完成负载索引推荐.
3具体实现
3.1负载收集
数据库日志会记录已经执行的查询.例如,分布式数据库Cedar将执行过的查询记录在T-node(查询节点)的日志中.负载收集的任务是从日志中读取执行过的查询SQL,加入负载文件中,并统计每条查询的使用频率.
3.2候选索引生成
实践中,大型企业的一个数据库里通常含有几百张表,采用枚举的方法生成的候选索引空间将会非常庞大,因此必须采用一些方法限制候选索引的数量.根据Tapio Lahdenmaki等人提出的观点,在一个查询中,在谓词条件、连接条件、ORDER-BY条件、GROUP-BY条件中涉及的列上建索引对提升查询效率的帮助是最大的,因此可以通过分析查询中的特定条件列,将候选索引的数量尽可能减少.
索引的选择本身是一个在收益和代价之间做权衡的过程.索引的收益来自查询性能的提升,索引代价来自额外的占用空间和对事务更新性能的影响.选择较少的索引列可以减少索引的占用空间和索引维护代价,而选择较多的索引列可以减小回表查询的概率,获得最大的查询性能提升.我们将尽可能减少索引列的选择方式称为“最小化索引”,将尽可能多地增加索引列的选择方式称为“最大化索引”.本文采用的是最小化索引模式.
具体步骤如下:
(1)遍历AST中WHERE条件中的等值条件列,加入等值列数组,称之为EQValues数组;
(2)遍历AST中WHERE条件中的范围条件列,加入范围列数组,称之为RangeValues数组;
(3)根据采集的数据库元信息和统计信息,补全EQValues和RangeValues中所有列的基本信息;
(4)将EQValues与RangeValues中的列,分别依据选择率升序排列;
(5)定义一个HashMap,Key为表名,Value为列数组PKColumns,存放的列作为该索引表主键列.将EQValues与RangeValues中的列依据表名加入不同表的PKColumns中.在此需要注意的是,若PKColumns中存在原表第一主键列,则该表扫描路径将不走索引而直接扫描原表的主键索引,因此该表不推荐索引,删除此对Key-Value.
其具体流程如算法1所述.
3.3列基本信息
生成候选索引的时候,需要知道列的基本信息,从语法树中获取到候选列时,列所属的表名可能存在3種情况:①表名为真实表名;②表名为别名;③不存在表名.针对前两类情况,都可以直接在语法树中找出真实表名.针对最后一类情况,直接从该SQL涉及的表中查找相同列名,若能找到则补充表名信息,若无法找到说明该列属于子查询结果集,在此层查询的候选索引中去除该列,留给子查询处理.
生成候选索引还需要估算列的选择率(SelectionRate).选择率的估算参考了PostgreSQL数据库的计算方法:
3.4索引收益-代价评估
为单条查询生成最佳索引之后,需要计算每个索引的收益与成本.在此阶段,收益是每个索引能为单条查询执行所减少的时间,而成本是每个索引所占用的空间大小.由于不可能将索引真正建立后再去统计查询的执行时间,需要一个代价模型去估算索引能带来的时间减少.
(1)索引收益
在查询执行过程中,有一个访问路径决策阶段.访问路径是获取基本表数据的可能途径,可分为直接从原表获取或通过索引表获取.若索引表包含的列无法包含上层算子的所有列,则需要通过索引中包含的原表主键访问原表,这一过程称为回表.本文讨论的索引表不带有冗余列,因此在计算索引收益之前,需要判断使用该索引是否需要回表,若需要,则回表标志位置为True.
前文已经介绍了选择率的计算方法,再结合基本表的行数信息,可以估算出扫描出来的结果集的大小,进而使用这些数据来计算访问路径代价.访问路径代价主要包含:将磁盘读取到内存中的磁盘10代价、执行过滤计算的CPU代价、索引回表代价,以及GROUP-BY和ORDER-BY条件的排序操作所产生的排序代价.
在代价估算过程中,无法获取绝对真实的代价,但由于只需要做到不同访问路径之间的代价比较,因此以某个代价作为代价单位1,其他的代价都为相对于这个基准代价的一个比值.
1)全表扫描代价
基本表的全表扫描代价为FullTableScanCost,主要包含CPU代价CpuRunCost和磁盘IO代价IOCost:
(2)索引代价
索引代價主要是估算索引所占用的空间大小,通过统计信息获取原表行数Tuples(R),即索引表行数Tuples(Index).对于varchar类型,本文采用保守计算方式,即字符串占满所申请长度,通过索引表每一列数据类型估算每行数据大小TupleSize,最终索引表大小估算公式为
Size(Index)=Tuples(Index)×TupleSize.
3.5负载索引推荐
接下来将介绍为工作负载推荐索引的算法.通过经典0-1背包算法去解决负载的索引选择问题.每个索引都有收益与代价两个属性,存在放入与不放入背包两种状态.索引的收益是指对利用它的查询的估计执行时间的改进,并乘上每个查询在工作负载中发生的频率,索引的代价是指估算的索引表的大小,同时通过设定每张表的最大索引数量约束索引对事务更新造成的延时.
背包具有固定的最大尺寸,放人背包中的索引大小不能超过背包大小的限制.与此同时,由于当原表发生更新操作时,索引表需要进行同步更新,为了避免一张表索引数量过多对其更新事务造成延时,数据库通常会对一张表的最大索引表数量进行限制.例如,在Cedar中,一张表的最大索引数量默认为10.算法的目标是使得放人背包中的索引收益最大化.其具体流程如算法2所述.
4实验评估
在分布式数据库Cedar上,验证CedarAdvisor所推荐索引的有效性.
4.1实验环境
将Cedar部署在单集群环境中,集群中有1台T-node(更新节点)、1台Q-node(查询节点)和1台S-node(基线节点).每台机器的主要配置:Intel(R)Xeon(R)CPU E5-26200@2.00 GHz型号2核心CPU,128GB内存和1TB机械硬盘.
4.2实验方法与结果
采用TPC-DS基准作为数据来源和负载来源,生成1GB的TPC-DS数据并导入库中,从TPC-DS中选出部分可以满足Cedar索引使用规则并且涉及大表查询的查询,与此同时,对SQL进行一些改写,以便更好地体现出索引的作用.在每条SQL中,为每个表都添加上选择率较低的范围过滤条件,改写后的SQL名称以原SQL名加上“-1”命名;在每条SQL中为每个表都添加等值过滤条件,改写后的SQL名称以原SQL名加上“-2”命名.选出18条查询SQL构成本次实验的负载,负载中有重复的SQL,如表1所示,频率为每条查询SQL的执行次数,整个负载共执行30次查询.
表2给出了CedarAdvisor针对此负载经去重与整合后推荐的所有候选索引.并非所有的候选索引都会进入最终被推荐的索引集合.需要结合索引空间限制、每个索引的收益与代价,选出整个负载的最优索引.
首先测试针对单条查询所推荐索引的有效性.使用CedarAdvisor分别给每条查询推荐索引,经数据预热后比较每条查询的使用索引与不使用索引执行的时间长短.测试结果如图2所示.
图2给出了负载中各条查询使用推荐索引的执行时间.可以看出,当非主键列上的过滤条件使用索引时,一定程度上加快了查询速度.当过滤条件为范围条件时,可将全表扫描转化为对索引表的范围扫描,TPCDS原SQL的执行速度得到了部分提升,“-1”系列SQL的执行速度得到了明显提升.当过滤条件为等值条件时,可将全表扫描转化为索引表的点查询,较大提升了“-2”系列SQL的执行速度.证明了单条SQL索引推荐策略的有效性.
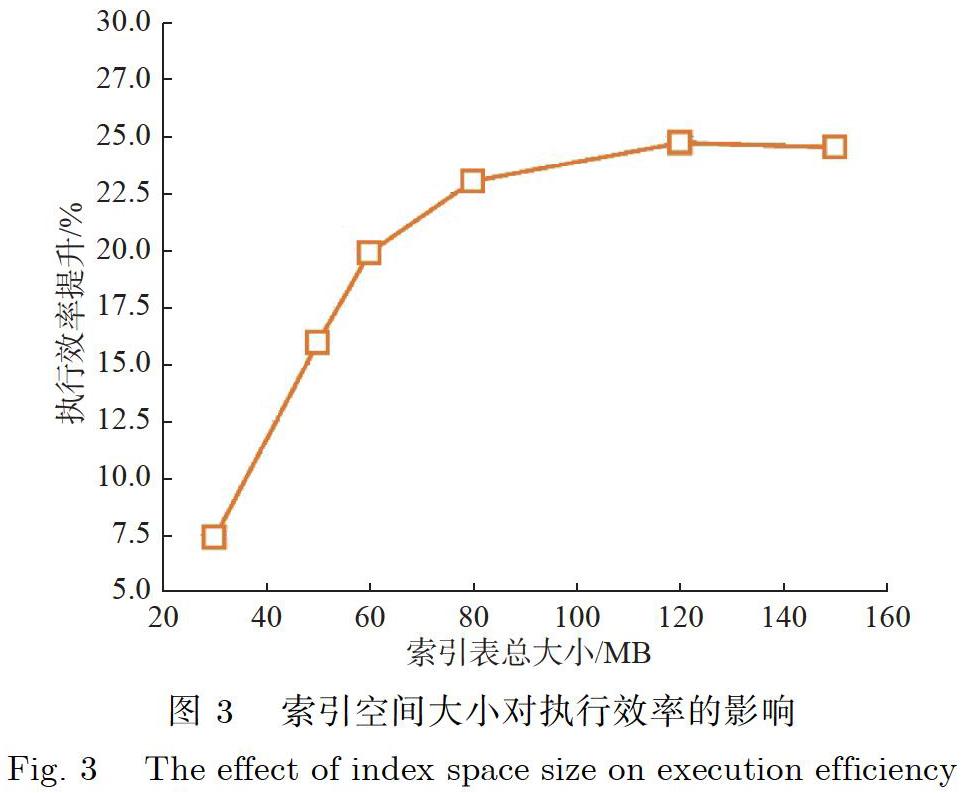
接下的实验是为了验证在不同索引空间限制条件下,CedarAdvisor针对整个负载推荐的索引集合对负载执行时间的影响,实验结果如图3所示.
在该实验中,当最大索引空间小于80MB时,增大索引空间可以容纳更多的索引表,显著提升了查询执行效率,缩短了负载的限制时间.但索引空间已经大于80MB后,增加索引数量已经无法再有效地增加负载执行效率.3.5节中已经介绍,负载的索引集合,是在单条SQL推荐索引的基础上,再通过背包算法放入最优索引集合.因此当最大索引空间小于某个值前,通过增加索引可以有效提升查询负载的执行效率.但当索引空间大于某个值后,单纯通过增加索引已无法有效提升查询负载的执行效率,只会增加空间消耗与索引维护成本.该实验证明了通过0-1背包算法选择最优索引集合的有效性.
5总结
本文以数据库索引选择问题为出发点,首先介绍了两款商用数据库的索引推荐工具的大致原理,进而提出了面向负载的、以有限候选空间为基础且用动态规划算法为负载选择索引的模型,在此模型的基础上实现了CedarAdvisor索引推荐工具,并在分布式数据库Cedar上验证了该工具的有效性.SQL的结构是非常丰富的,本文论述的索引推荐模型只讨论了部分常见SQL结构,对于SQL中的一些复杂结构,如何为其选择索引并评估收益值得进一步研究与讨论.
