一种解决命名实体识别数据集类别标记失衡的方法
2020-01-10许丽丹刘嘉勇
许丽丹, 刘嘉勇, 何 祥
(1.四川大学网络空间安全学院, 成都 610065; 2.四川大学电子信息学院, 成都 610065)
1 引 言
命名实体识别是自然语言处理领域中一项重要任务,经过几十年的研究发展已取得了显著成果[1-5].但是目前已有的研究较少关注命名实体识别数据集数据类别标记不平衡这类数据分布问题[6].数据类别标记不平衡[7]是指一个类别的数据量与属于另一类别的数据量差距较大,且小样本量类呈现出的信息更具价值.数据类别标记不平衡会影响统计学习模型的效果,导致模型更关注多数类别数据,忽略少数类别数据[7-16].在分类问题中解决数据类别标记不平衡的方法主要有以下三类: (1) 采样方法,包括欠采样和过采样方法[7];(2) 改进统计学习算法,包括one-class学习方法[8],修改算法的代价[9]以及集成学习[10];(3) 特征选择,通过收集最佳特征子集[11]以实现最佳性能.
针对序列数据,Tomanek等人通过主动学习,在数据标记阶段尽可能平衡地标记数据[12].Douzas等人使用条件对抗生成模型为少数类别数据生成更多数据以缓解数据失衡[13],但这种方法模型复杂、计算代价大.Gliozzo假设频繁出现的单词一般不提供文本具体信息,也不会是实体.可以过滤掉这些词以减小非实体类单词与实体类单词比值[14].Maragoudakis等人使用Tomek连接法在训练阶段减少训练集中不必要的负面样本[15].Akkasi等人[6]提出了平衡欠采样方法,该方法保留句子逻辑短语结构以及句子间相关性,并在四个生物医学数据集上分别实验比较随机欠采样、SWF[14]和平衡欠采样三种欠采样方法的效果并证明了调节数据集中实体类单词和实体类单词比例可以改善模型效果.然而这种方法直接剔除数据集中非实体单词或语句,可能破坏文本的短语结构,丢失有价值的数据.
针对已有方法可能造成的信息丢失问题,本文通过改造遗传算法[17]用于序列文本合成,提出了一种基于遗传算法的数据类别标记平衡方法,本文简称CBM-GA(class balance method based on genetic algorithm).该方法保留所有原始语料,利用遗传算法基因重组、繁衍行为特点,充分挖掘类别平衡文本特征,尽可能维持语句中实体短语结构的同时,合成新文本以扩充原始数据集.实验表明,本文提出的方法有效缓解数据集类别标记不平衡问题,提高命名实体识别任务性能.
2.1 类别平衡方法框架
本文提出的数据类别平衡方法CBM-GA框架如图1所示,首先对原始数据集进行筛选,获得合适的父代样本集,通过适应度函数评估样本并按照其适应度函数值排序获得有序父代样本集.从有序父代样本集中随机选择样本形成父代样本对,经过交叉和变异操作生成新样本,再次使用适应度函数评估新样本,抽取适应度函数值高的新样本集合更新下一轮文本合成操作所需的父代样本集,如此循环N次.最后将第N轮生成新样本数据集和原始数据集合并产生扩充数据集,用于命名实体识别.

图1 CBM-GA框架图Fig.1 Method framework
2.2 类别平衡方法原理
2.2.1 数据筛选 现有用于命名实体识别研究的公开数据集中实体单词个数远小于非实体单词个数,且包含大量无实体单词、类别严重失衡的语句[6].直接使用这样的数据集进行文本合成会增加后续操作代价,降低文本合成效果.因此需要进行文本筛选,初步获取类别分布相对平衡的文本集合作为父代样本集.
如何评估文本类别标记平衡的程度是首先需要解决的问题,Akkasi等人[6]用非实体单词个数和实体单词个数比值来评估文本类别标记平衡性,如式(1)所示.
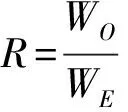
(1)
式(1)中,WO表示语句中非实体单词个数;分母WE表示语句实体单词个数.本文将R值作为文本平衡性的衡量指标,R值越大文本类别越不平衡.
统计分析常用数据集CoNLL2003[18]、JNLPBA[19]中语句的非实体单词个数与实体单词个数比值R和语句单词总数的关系,我们可以得出以下结论:文本单词个数越多,R值越大,文本类别越不平衡,两者近似反比例关系,如图2所示.
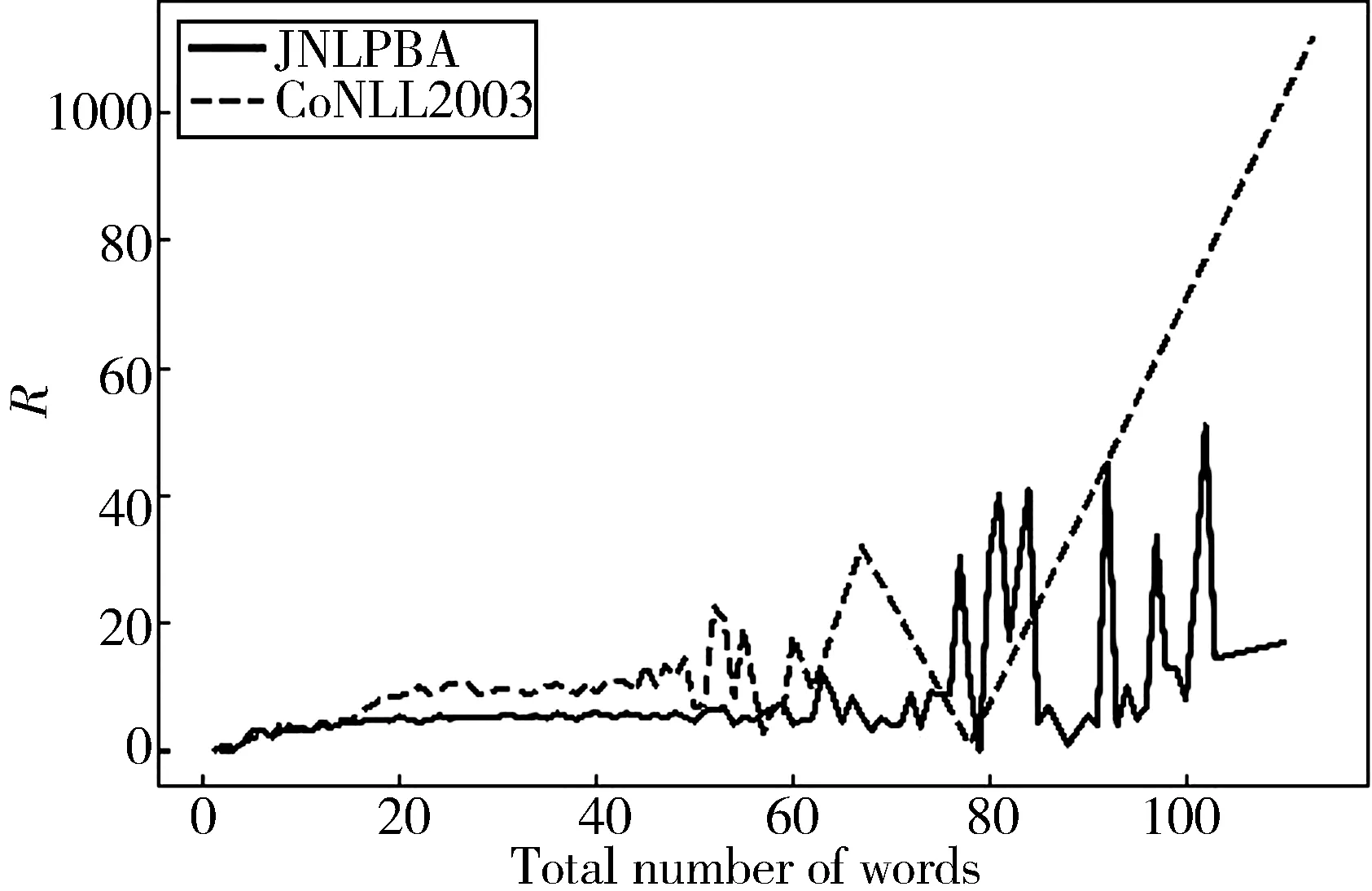
图2 两个常用数据集文本R值与文本单词个数关系图
Fig.2 Relationship between the textRvalue of two common datasets and the number of text words
图2中横轴表示语句的单词总数,纵轴表示语句中非实体单词个数与实体单词个数的比值.实线、虚线分别表示JNLPBA、CoNLL2003数据集的文本R值与文本长度的关系,二者整体呈上升趋势.当文本单词个数超过60,文本的R值波动幅度变大;当文本单词个数超过100,JNLPBA数据集的R值均处于剧烈波动状态,CoNLL2003数据集R值快速增长,表明此时文本类别较不平衡,使用这样的数据进行后续操作将不利于合成类别均衡的新文本.
因此,为了减少后续文本合成操作的计算代价,提高合成效率,数据筛选过程中需要剔除类别严重失衡的数据.结合上述分析,数据筛选具体流程如下.
(1) 计算每个语句中实体单词个数,剔除不含实体单词的语句;
(2) 剔除单词个数超过100的语句.
2.2.2 适应度评估 适应度函数,在遗传算法中用以评估给定解决方案与所需问题最佳解决方案的接近程度[17].CBM-GA方法使用适应度函数作为评估指标以评估样本的平衡性,并将类别标记平衡条件引入适应度函数中,使得算法寻优过程中尝试构造类别分布平衡的新样本.定义适应度函数f如式(2)所示.
f=sigmoid(Rs-R)+λ×sigmoid(R-Rr)
(2)
式(2)中,R为式(1)定义的语句非实体单词和实体单词的比值;Rs是合成文本R值上限值;Rr是合成文本R值下限值;λ是Rr权重系数.式(2)借助sigmoid函数控制合成样本的R值在[Rr,Rs]范围内.
由图2分析可知文本单词个数不应过长,因此向适应度函数中添加单词个数小于100的限制,如式(3)所示.
(3)
式(3)中,L表示语句单词个数限制函数;l表示当前样本单词个数.relu函数限制合成文本的长度.适应度函数引入单词个数限制,如式(4)所示.
f=sigmoid(Rs-R)+λ×sigmoid(R-Rr)+
(4)
式(4)中,μ是L的权重系数,用以控制类别平衡条件和单词个数限制的重要性差异.
2.2.3 文本合成 CBM-GA方法文本合成过程主要是通过一系列选择、交叉和变异操作合成数据标记平衡的数据.其中,选择操作从有序父代样本集合中抽取父代样本构建父代样本对集合;交叉操作将父代样本对进行组合以生成新样本;变异操作调整新样本的单词顺序,向样本中添加更多随机性.
CBM-GA方法将文本视为染色体,将单词及其实体标记类型视为染色体上的基因.如图3所示.每个框内上行表示单词,下行表示对应实体类型标记[17],二者共同构成一个完整的基因.基因构成染色体,又称之为样本.将数据集中每个文本视为样本,数据集视为样本群体.
为了便于后续分析,定义样本染色体x=(x1,x2,…,xn),其中,xi是包含单词及其对应实体类型标记的基因,n是染色体长度.
1) 选择操作
在选择步骤中,遍历有序父代样本集并按照比例选择方法[20]随机选择两个父代样本构成父代样本对,从而构成父代样本对集合.
图3 染色体示意图
Fig.3 Chromosome schematic diagram
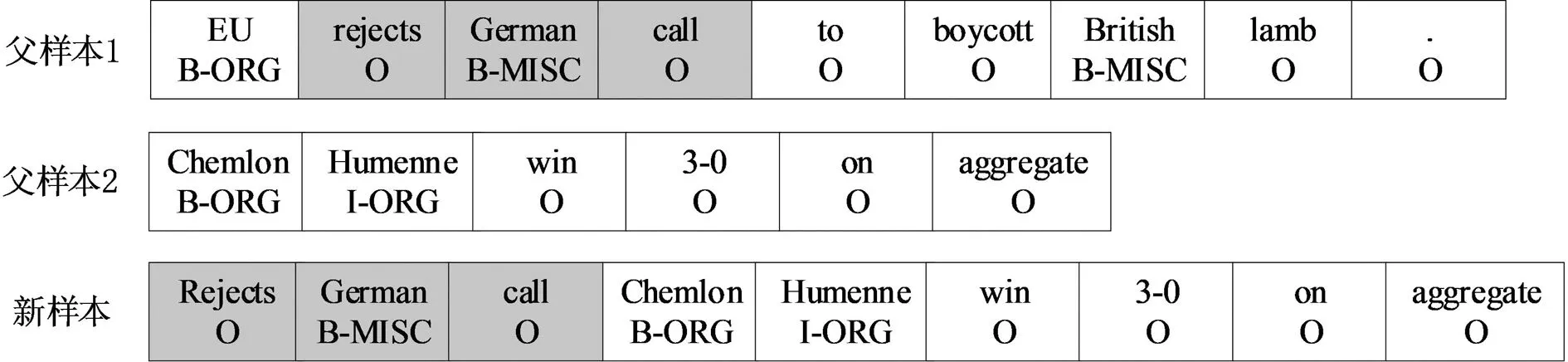
图4 交叉过程示意图Fig.4 Crossover schematic diagram
2) 交叉操作
在交叉阶段,对父代样本对集合中每个父代样本对采用随机交叉策略进行单词序列相互交换,以产生新样本,如图4所示.
为避免实体短语被切分而导致命名实体模糊、歧义等问题,CBM-GA方法修改基因组合规则,限制单词交换位置仅为开始,结尾以及O标记[18]的非实体单词位置以确保实体单词结构完整交换.因此首先根据父样本1的实体标记类型,构建交换位置集合l.并随机从l中抽取交叉发生的开始、结束位置以得到单词序列如图中黑色框单词序列,将其与父样本2合并生成新样本x′.
x′=x1[lstart:lend]+x2
(6)
式(6)中,x1表示父样本1;x2表示父样本2;lstart、lend分别表示从交换位置集合l随机抽取的开始、结束位置;x′表示新样本.
3) 变异操作
本文采用随机交换单词位置的方式实现变异.具体操作为:设定一个变异概率α,对交叉得到的新样本x′,随机产生一个[0,1]区间上的随机数r,如果r<α,则随机交换新样本x′两个单词的位置.最终生成样本如式(7)所示.
(7)
式(7)表明当r<α时,随机选定两个单词位置i、k,交换x′中两个位置的单词从而实现变异操作,反之则不进行变异.
综上分析,CBM-GA方法完整表述如算法1.
算法1 CBM-GA方法
输入原始训练样本集合S;参数Rs、Rr、λ、μ、循环次数N、变异概率α、合成样本集合大小La
输出扩展的新样本集合A
Begin
初始化迭代次数n:n=0
(1) 遍历原始训练样本S,过滤不含实体单词及文本单词个数超过100的语句,获得父代样本集D;
(2) 遍历父代样本集D,根据式(4)计算每个语句的适应值并排序,得到有序父代样本集D1;
(3) 使用比例选择法随机从D1中抽取两个父代样本组成的父代样本对集合;
(4) 遍历父代样本对集合:
(a) 针对父代样本对(p1,p2),分别从p1、p2样本的开始、结尾及非实体单词的位置集合中随机选择位置变量以截取单词序列;
(b) 将单词序列合并成新样本T;
(c) 以概率α交换T中任意两个位置的单词,并将T加入新样本集合G;
(5) 遍历G,根据式(4)计算每个新语句的适应值.抽取适应值最高的La个样本的集合替换D1、G,迭代次数n加1;
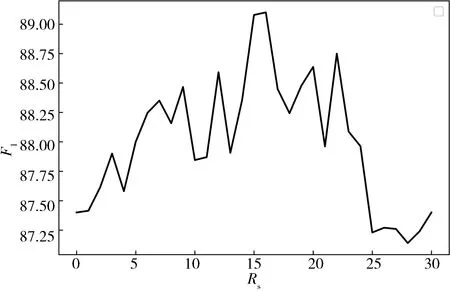
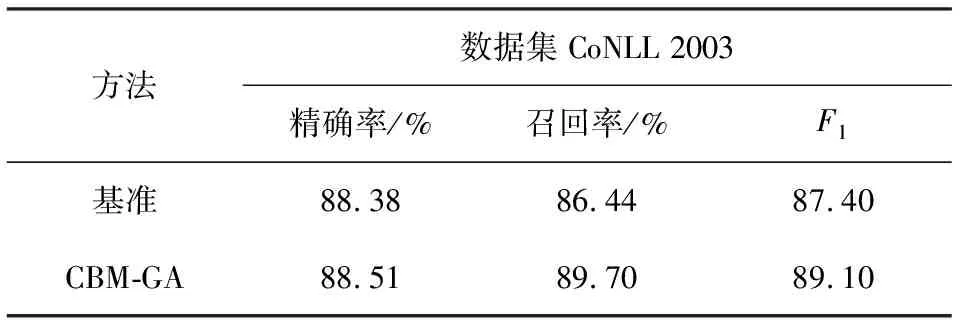
(6) 如果n End 为了验证CBM-GA方法的有效性,排除单一数据集影响,实验采用命名实体识别研究中常用数据集CoNLL2003[18]和JNLPBA[19]进行实验.数据集基本统计信息如表1所示. 表1 数据集统计信息表 如表1所示, CoNLL 2003已分配好训练集、验证集和测试集;JNLPBA仅划分了训练集和测试集.本文从JNLPBA中随机抽取1/3数据作为验证集. 本文实验平台为ubuntu16.04系统服务器,GPU为GeForce GTX 1070,显存8 G.实验模型使用tensorflow框架构建. Akkasi等人提出平衡欠采样方法以缓解数据集的类别失衡问题,从而改善命名实体识别的效果,其借助命名实体识别评价指标作为最终的方法有效性衡量指标[6].本文沿用该评价指标来论证CBM-GA方法的有效性.命名实体识别一般采用精准率(prec)、召回率(recall)和F1值作为模型性能评估指标[1-5].本文使用的模型评价指标定义如下. (8) (9) (10) 根据2.2节定义,CBM-GA方法实现过程涉及参数:合成样本R值上限Rs,合成样本R值下限Rr,Rr值权重λ,L的权重系数μ,合成样本集合大小La,变异概率α以及循环次数N. 根据Whitley等人的经验[17],本文实验将α设为0.01.为给其它参数设置合理的取值,实验基于Bi-LSTM-CRF模型[2]使用贝叶斯优化[16]寻优方法来设置参数.具体操作如下. 1) 分别以1为步长,设置Rs,Rr的取值范围为[0,30];以500为步长,设置La的取值范围为[500,2000];以0.1为步长,设置λ取值范围为[0,1];以1为步长,设置循环次数N取值范围为[1,10],构建参数集合; 2) 基于Bi-LSTM-CRF模型使用贝叶斯优化寻优方法以F1值为指标,对参数集合进行寻优.选取验证集实验结果中F1值最大的参数作为后续实验参数. 图5 参数Rs选择实验结果Fig.5 Results of Rs selection 以CoNLL 2003数据集的Rs参数选取为例,以1为步长,设置Rs取值区间为[0,30],绘制不同Rs对应F1值分布图,如图5所示. 根据图5可知,当Rs为15时,合成的数据集进行命名实体识别F1值最高,因此选定Rs=15.由此思路选择其他参数,最终参数取值如表2所示. 表2 数据集参数表 实验使用Bi-LSTM-CRF模型作为基准模型.为了验证CBM-GA方法的有效性和优异性,分别设计了2组对比实验.且为了避免偶然因素影响,实验结果均为5次重复实验结果.具体如下. 为了验证CBM-GA方法的有效性,设计基准模型和CBM-GA方法对比实验. 1) 基准实验:使用基准模型分别对CoNLL2003、JNLPBA建模; 2) CBM-GA方法实验:使用基准模型分别对CBM-GA方法作用后的两数据集建模; 针对CoNLL 2003数据集的实验结果如表3所示,CBM-GA方法相比基准模型在保持精确率几乎不变的情况下,召回率提升3.26%,F1值提高1.70%;针对JNLPBA数据集的实验结果如表4所示,CBM-GA方法虽然造成精确率的小幅下降,但其召回率提高了2.44%,最终F1值增加了1.03%. 为了验证CBM-GA方法表现优于已有平衡欠采样、随机过采样方法,设计以下对比实验. 1) 随机过采样方法实验:使用随机过采样方法扩充原始CoNLL 2003、JNLPBA,获取与CBM-GA方法相同规模的扩充数据集,并使用基准模型其建模; 2) 平衡欠采样方法实验.使用平衡欠采样方法处理原始两数据集获得新样本集合,并随机采样新样本集合扩充原始数据集以获取与CBM-GA方法相同规模的扩充数据集,使用基准模型其建模; 优异性验证实验结果如表5和表6所示,针对CoNLL 2003数据集,CBM-GA方法召回率比平衡欠采样高2.98%,比随机过采样方法高3.29%,F1值均超出1.76%以上;针对JNLPBA,CBM-GA方法召回率比平衡欠采样高1.78%,比随机过采样方法高2.25%,F1值均超出0.97%以上. 综上实验分析验证了CBM-GA方法可以有效提高模型召回率,改善命名实体识别效果,相比已有方法表现更优异. 表3 CoNLL 2003数据集上有效性验证结果 表4 JNLPBA数据集上有效性验证结果 表5 CoNLL 2003数据集上优异性验证结果 表6 JNLPBA数据集上优异性验证结果 进一步分析实验结果,以CoNLL 2003数据集为例,绘制基准、CBM-GA实验接收者操作特征曲线(receiver operating characteristic curve,ROC)[21]如图6所示. 图6 ROC曲线Fig.6 ROC of baseline and CBM-GA 分别计算两条ROC曲线对应AUC[22]值如表7所示. 表7 AUC值 图6和表7更一步证明CBM-GA模型通过缓解实体类和非实体类单词个数的不平衡问题,有效地改善了命名实体识别的效果. 从时间代价分析,CBM-GA算法增广CoNLL 2003数据集需2.42 min,增广JNLPBA数据集训练需2.4 min,相比Bi-LSTM-CRF模型训练每epoch需32 s,50个epoch需要26.7 min,CBM-GA算法的运行成本是可以接受的.数据类别标记失衡是普遍存在于开源数据集的问题,但目前关于命名实体识别任务上的数据标记失衡研究较少.本文针对这一现状创新性地改造遗传算法,提出了保持文本实体短语结构的CBM-GA方法.实验结果表明,CBM-GA方法在文本数据预处理阶段有效缓解数据集类别标记失衡问题,改善模型召回率并进一步提高命名实体识别性能.该方法可以应用在其它序列标注任务上如分词、机器翻译等中.
3.2 实验评价指标
3.3 实验参数设置与寻优

3.4 实验测试结果



3.5 结果分析


