一种基于改进K-means 算法的空间群划分方法
2020-01-08王玮琦唐锦波
汤 奋,游 雄,李 钦,王玮琦,唐锦波
(1.信息工程大学,郑州 450000;2.解放军75838 部队,广州 510000)
0 引言
高技术战争条件下,战争周期缩短,战争节奏加快,面对海量实时的战场数据,指挥员能否快速对战场态势作出合理估计,明确敌方意图,对战争胜负至关重要。兵力分群是将兵力按照一定的层次结构进行划分,以提高指挥员的态势认知效率。兵力分群结果的优劣,对后续的意图识别和威胁估计等准确性和可靠性有重要影响[1]。兵力分群按低级到高级分为5 个层次[2-4],分别是兵力对象、空间群、功能区、相互作用群和敌方/我方/中立方群。由此可见,空间群划分是兵力分群的重要环节。
张绪亮、龙真真、刘洁莉、王晓璇、胡艮胜、孙亮[1,5-9]等人,以实际兵力或者虚拟兵力的对象,开展了空间群划分的研究。通过分析发现,空间群划分的关键之处在于两点:一是构造作战单元间的“距离”函数,涉及兵力作战单元的属性信息选取及其权重的确定;二是合理确定分群数目和聚类中心,其本质是一个算法选择和参数优化问题。目前多数研究都集中在这两个方面,并积累了一定的成果,其中张绪亮通过顾及敌方兵力作战单元的机动速率、机动方向和空间距离以及可能的进攻目标,对K-means 算法的距离函数进行了改进,并能实现分群数目的自适应选取,但不足之处是初始聚类中心的选取依然是随机的。对K-means算法而言,不同的初始聚类中心可能会产生不同的聚类结果,从而使得分群结果不稳定,与实际情况不符。因此,需对现有用于空间群划分的K-means 算法进行改进,以提高空间群划分结果的稳定性。
1 空间群划分的概念

2 面向空间群划分的K-means 算法改进方案
K-means 算法是一种基本的聚类分析算法,算法简单,收敛速度快[2],其具体流程此处不再详述。为了取得最佳聚类结果,该算法需取不同的K 值和不同的初始值聚类中心进行多次尝试,且最终的聚类结果还可能不同。为此,当利用该算法进行空间群划分时,需对其进行改进。首先利用文献[5]所提出的改进距离度量函数来计算“距离”,然后引入了一种快速搜寻高密度点的方法,该方法在确定空间群最佳划分数目的同时,还能确定初始聚类中心,使空间群划分结果不随初始聚类中心的变化而波动,提高了分群结果的稳定性。
2.1 距离度量函数
传统K-means 算法是基于欧式距离进行聚类的,考虑空间群划分的特殊性,通常还需考虑目标的机动方向与速率、可能目的地和空间距离进行综合考虑,为此,此处使用了文献[5]中的距离度量函数(距离函数并非本文创新点)。设表示敌方作战单元ai与我方目标bj在某一时间段内的夹角;δij表示ai与bj之间的距离参数;令φij=cos(),则定义进攻关系函数Pij=φij*δij。假设当前作战地域内,敌方进攻作战单元数为n,我方防御作战单元数为m,那么就可构建一个由Pij组成的n×m 的进攻关系隶属度矩阵P[5]:

2.2 确定初始聚类中心和聚类数目
此处引入了一种快速搜寻高密度点,以确定聚类中心和聚类数目的方法[10],下面对该方法进行描述。该方法巧妙利用了聚类中心必须同时具备的两个特点:一是本身的密度大,即它的密度大于周围一定范围内的数据点的密度;二是与其他密度更大的数据点之间的“距离”更大。下面将利用上述两个特点来识别聚类中心的方法进行数学描述。
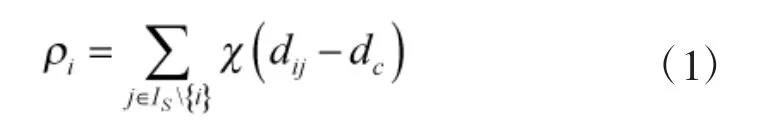
其中函数
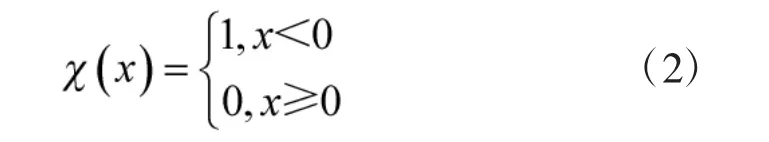
参数dc>0 为截断距离,需事先指定。由式(1)[10]可知,ρi表示S 中与xi之间的距离小于dc的数据点(除去xi本身)的个数。
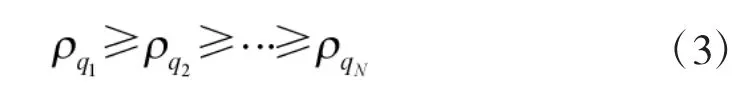
则可定义


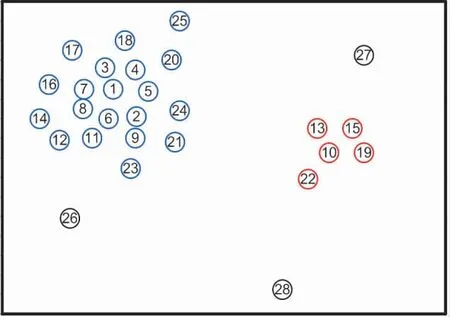
图1 二维数据点

图2 二维数据点的ρ-δ 图

2.3 面向空间群划分的改进K-means 算法
本算法假设待分群的敌方兵力作战单元基本属性:部队级别、军种类型和隶属编制军都相同,主要依据兵力作战单元的空间属性和速度进行空间群划分。通过上述两小节,面向空间群划分的改进K-means 算法流程如下:



3 实验与分析
某平原地形上,我方传感器探知敌方15 个连规模的作战单元,正向我方两个营(作战单元1 和作战单元2)所负责的防御阵地移动,准备对我发起进攻,但主攻方向不明。通过传感器进一步探测得到敌方15 个连在某一时刻的坐标和速度,如下页表1 所示,其中X、Y、U、V 分别表示敌方各连的横坐标、纵坐标、速度的水平分量、速度的垂直分量,其矢量形式如图3 所示。
我方兵力作战单元1、兵力作战单元2 的坐标分别为(0.3,12.8)、(0.8,5.8)。利用结合2.3 节中的改进算法,可计算出敌方各个作战单元映射到空间S 中的新坐标(Pi1,Pi2),以及局部密度ρi和距离δi,如表2 所示。
利用表2,绘制“ρ-δ”决策图,如图4 所示。根据2.2节确定聚类数目和聚类中心的方法,图4 中作战单元2 和作战单元15 符合初始聚类中心的特征,可取这两个为聚类中心,进而也确定了聚类数目K取值为2。在此基础上,利用各点映射到S 空间中的新坐标值,就可通过K-means 算法计算出相应的聚类结果。进过多次重复实验,15 个敌方兵力作战单元所属的类别均保持一致,如表2 第6 列所示,最终聚类结果如图5 所示。
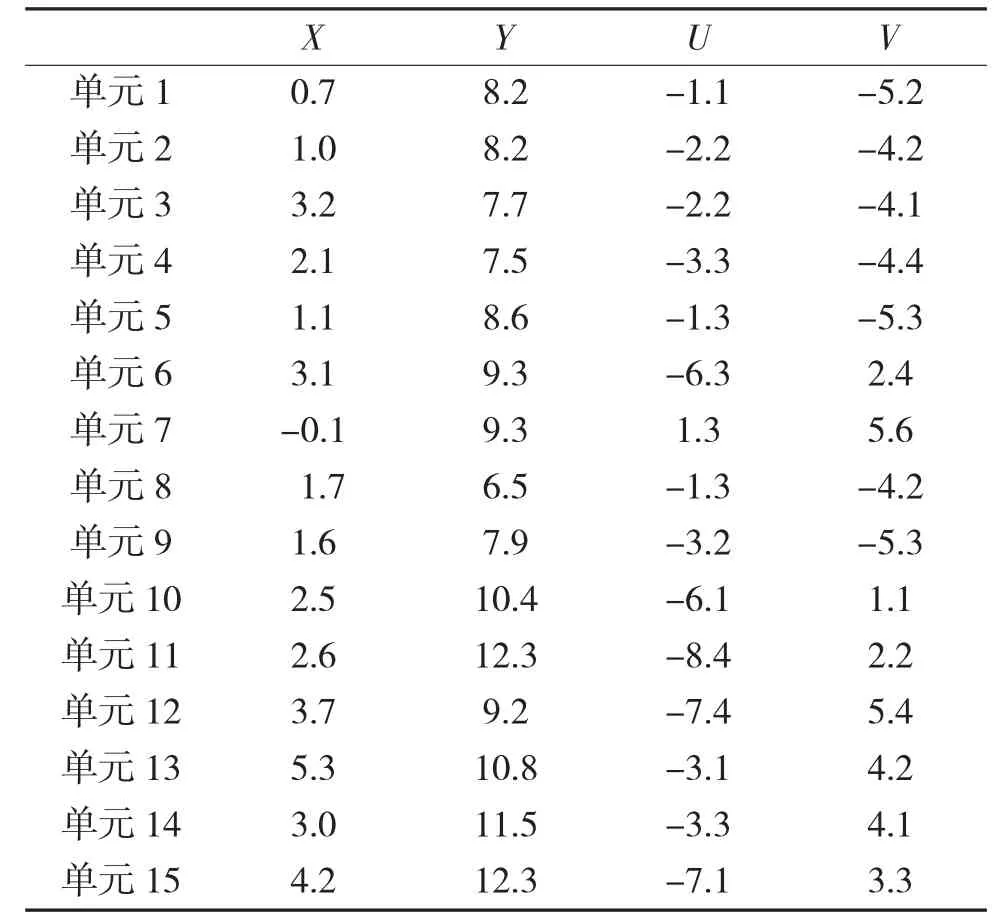
表1 敌方单元坐标数据(km)及速度(km/h)
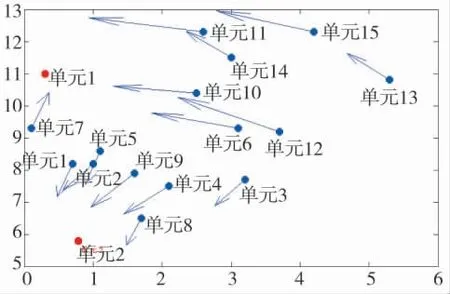
图3 各点坐标及其速度的矢量表达形式
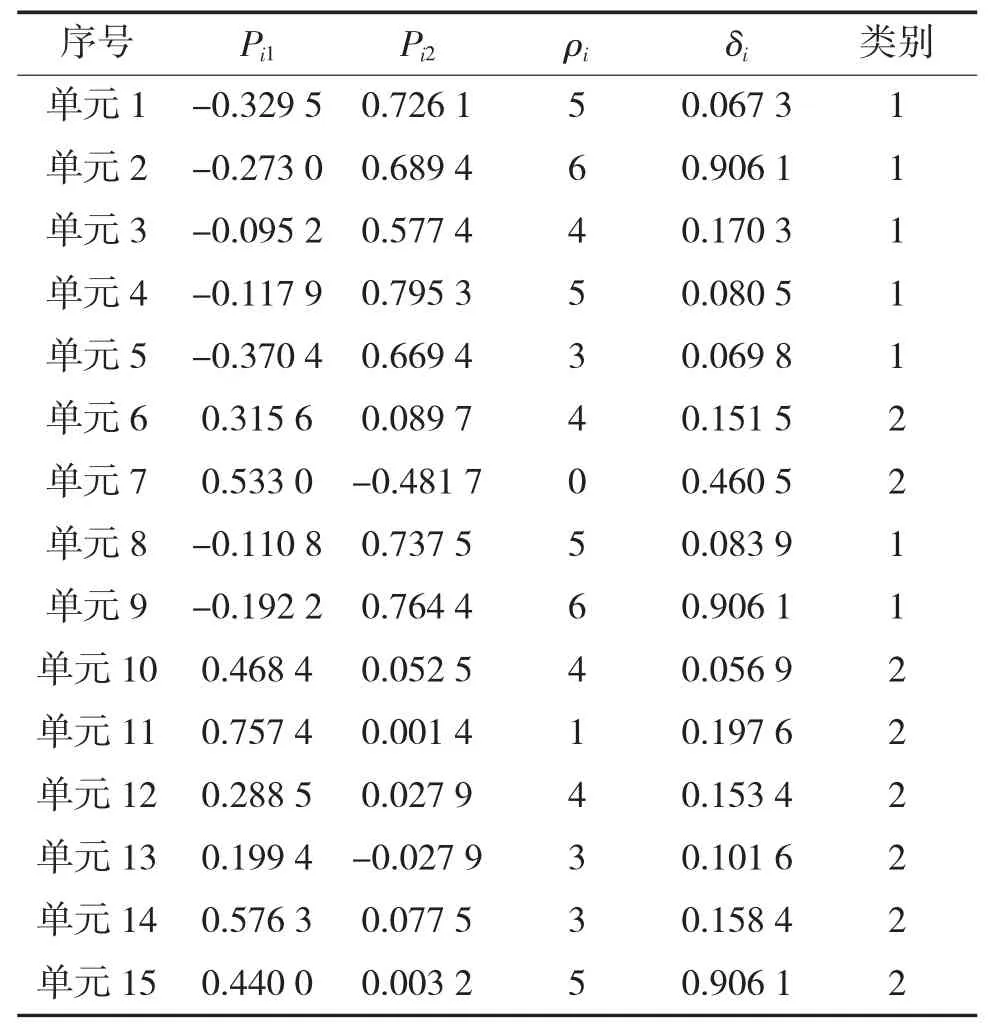
表2 映射到S 空间的坐标值和ρ-δ 值及分群结果

图4 “ρ-δ”决策图
分群的结果是,图5 中进攻我方单元1 的敌方作战单元分为了一个群,图中用蓝色对其进行了表示;进攻我方单元2 的敌方作战单元分为了另一个群,图中用绿色对其进行了表示。由图5 可知,仿真实验的分群结果与实际情况相符,正确体现了作战单元属性(机动方向与速率、空间距离、进攻目标)对分群结果的影响,表明该方法能够较好地实现战场敌军兵力的空间群划分。
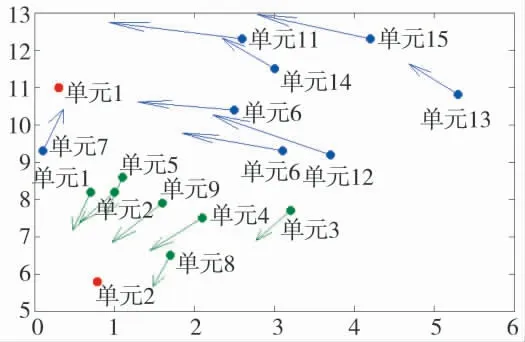
图5 最终聚类结果
4 结论
本文以提高空间群划分结果的稳定性为目标,对现有用于空间群划分的K-means 算法进行了改进。针对当前算法无法确定初始聚类中心的问题,引入了文献[10]中的一种新的方法,并利用已有的距离改进函数,对所引入的方法进行了适用性改造,实现了分群数目K 和初始聚类中心的确定,在此基础上利用K-means 算法对空间群划分进行了仿真实验,仿真结果符合实际情况,并实现了提高空间群划分结果的稳定性的目标。
需要指出的是,对海上和空中的兵力作战单元进行空间群划分时,地理和地形环境因素对其影响不大,而陆地上的空间群划分则受到战场地理、地形环境要素的影响和制约,因此,下一步的工作还需将地理、地形环境要素对兵力分群的影响考虑进去,从而得出更为可信的空间群划分结果。
