基于XGBoost与协方差特征的频谱感知算法
2020-01-05束学渊曹晓航
束学渊 曹晓航

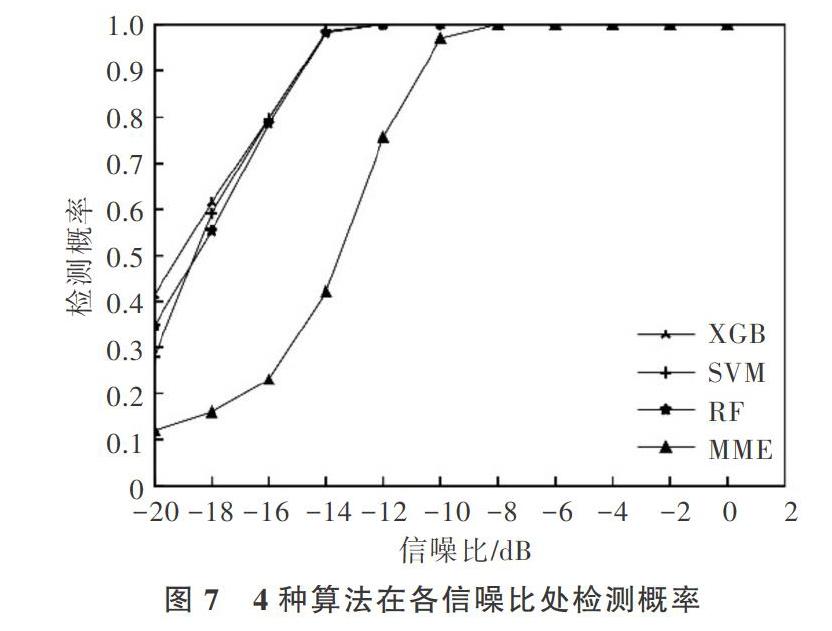
摘 要:近年来随着盲检测算法的提出,越来越多基于采样协方差矩阵的盲检测算法开始应用于频谱感知。针对基于信号协方差矩阵的频谱感知算法门限无法准确获得,以及特征信息单一等问题,提出基于XGBoost与协方差特征的频谱感知算法。首先提取接收信号采样协方差矩阵统计量作为XGBoost的训练特征向量,并生成训练样本和测试样本,然后对XGBoost进行训练得到频谱感知分类器,最后利用分类器进行频谱感知。仿真结果表明,该算法比支持向量机算法、随机森林算法及传统最大最小特征算法的检测概率更高,在信噪比为 -14dB时,该算法检测概率达到0.98,且训练时间与测试时间少于对比算法,具有良好的性能。
关键词:认知无线电;协作频谱感知;XGBoost;机器学习;协方差矩阵
DOI:10. 11907/rjdk. 201300 开放科学(资源服务)标识码(OSID):
中图分类号:TP312 文献标识码:A 文章编号:1672-7800(2020)011-0084-06
Spectrum Sensing Algorithm Based on XGBoost and Covariance Features
SHU Xue-yuan,CAO Xiao-hang
(College of Communication Engineering,Hangzhou Dianzi University,Hangzhou 310018,China)
Abstract:In recent years, with the proposel of the blind detection algorithms, more and more blind algorithms based on sampling covariance matrix are applied to spectrum sensing. Aiming at the problem that the threshold value of spectrum sensing algorithm based on signal covariance matrix is difficult to get accurately and the feature information is single, we propose a spectrum sensing algorithm based on XGBoost and covariance feature. Firstly, the statistics of the covariance matrix of the received signal is extracted as the training feature vector of XGBoost, and then the training and test samples are generated, and the training is carried out to obtain the spectrum sensing classifier. Finally the classifier is used to carry out spectrum sensing. Simulation results show that the proposed algorithm has a higher detection probability than the support vector machine algorithm, random forest algorithm and traditional maximum and minimum feature algorithm. When the signal-to-noise ratio is -14dB, the detection probability of this algorithm reaches 0.98, and the training time test is less than the comparison algorithm with good performance.
Key Words:cognitive radio; cooperative spectrum sensing; XGBoost; machine learning; covariance matrix
0 引言
隨着无线通信网络的不断推出,频谱资源变得日益短缺,而目前已使用的频段资源利用率并不太高。为解决这一问题,认知无线电(Cognitive Radio,CR)应运而生,频谱感知是其中的关键技术之一。
传统能量检测(Energy Detection,ED)算法较为简单,感知时间短,但噪声峰值对算法影响较大,不适合在低信噪比环境下使用[1];匹配滤波检测方法精度较高,但是必须知道主用户信号的先验知识[2];循环平稳特征检测算法精度高,能很好地抑制噪声,但其复杂度高、感知时间长[3]。在进行实际频谱感知时,先验信息都是无法获取的,并且单用户频谱感知方法受低信噪比、隐藏终端和信号衰落等因素影响严重。针对这些问题,基于接收信号协方差矩阵的盲检测算法[4]相继被提出,多用户协作感知在一定程度上克服了上述问题,适用于独立同分布的相关信号检测。基于协方差的盲检测算法包括:最大最小特征值检测法[5](Maximum-minimum Eigenvalue,MME)、最大最小特征值之差法[6](The Difference between the Maximum Eigenvalue and Minimum Eigenvalue,DMM)、特征值之差与几何平均特征法[7](Difference between the Maximum-Minimum and Geometric Mean Eigenvalue,DMMG)、能量最小特征值法[8](Energy with Minimax Eigenvalue,EME)、协方差绝对值法[9](Covariance Absolute Value,CAV)。基于协方差的算法能在一定程度上消除噪声不确定性的影响,但其判决门限是渐进的,不精确的門限设定会影响算法检测性能。
为解决传统协作频谱感知的门限问题,近年来学者提出利用机器学习进行频谱感知的算法。该类型算法首先构造特征,再训练机器学习算法,利用训练得到的模型进行信号分类,不需要理论推导检测门限,并且对不同噪声环境适应度高。文献[10]使用BP神经网络作为感知分类器,但该算法容易陷入局部最优解;文献[11]提取信号循环谱特征参数,使用随机森林(Random Forest,RF)进行感知判决,但由于该方法为单点感知,无法避免多径和衰落等影响;文献[12]使用支持向量机进行频谱检测;文献[13]利用循环自相关特征和Adboost算法进行频谱感知。
XGBoost(eXtreme Gradient Boosting)算法是陈天奇等[14]于2015年提出的一种集成学习算法,在部分领域已进行了应用研究。本文使用信号协方差矩阵的多个特征统计量组成样本特征向量,训练XGBoost算法作为感知分类器进行频谱感知。该方法克服了渐进门限的局限性,并且提取多个信号协方差矩阵特征,在减少信息冗余的同时,能够尽可能多地利用有效特征。
1 系统模型与理论基础
在经典的认知网络(Cognitive Radio Network,CRN)中,假设认知网络由M个次级用户(Secondary User,SU)和一个主用户(Primary User,PU)组成,yi(n)是第i个次级用户的接收信号,s(n)为主用户发送信号,hi(n)是第i个次级用户与主用户之间的信道系数,噪声为vi(n),且噪声服从均值为0、方差为σ2的高斯分布。第i个次级用户进行频谱感知的二元假设可表示为:
yi(n)=vi(n)H0s(n)hi(n)+vi(n)H1 (1)
式中,H0表示无主用户存在,H1表示有主用户存在。M个次级用户收集信号,感知信号矩阵如式(2)所示。
Y=y1(1)y1(2)?y1(N)y2(1)y2(2)?y2(N)????yM(1)yM(2)?yM(N)M×N (2)
其中,N为信号采样点数。认知用户接收信号的统计协方差矩阵为:
Ry=EYYH (3)
由于信号采样点数是有限的,无法精确计算统计协方差矩阵Ry,因此使用样本协方差矩阵Ry(N)作为Ry的估计。
Ry(N)=1Nn=1NYYH (4)
2 基于协方差统计特征的XGBoost频谱感知
2.1 协作频谱感知常见算法
(1)MME算法。MME算法以接收信号采样协方差矩阵Ry(N)最大特征值与最小特征值的比值作为统计量,表达式如下:
TMME=λmaxλmin (5)
其中,λmax为协方差矩阵最大特征值,λmin为协方差矩阵最小特征值。根据Wishart随机矩阵Ry(N)的特征值极限分布以及M-P律可推出MME感知算法判决门限为:
γMME=(N+M)2(N-M)21+(N+M)-23(NM)16F1-1(1-Pfa) (6)
其中,F1-1为Tracy-Widom第一分布的累积分布逆函数。
(2)DMM算法。DMM算法基于接收信号协方差矩阵最大特征值和最小特征值在主用户信号存在与否时的差异性进行检测,其检测统计量为:
TDMM=λmax-λmin (7)
DMM检测算法判决门限为:
γDMM=σ2NvF1-1(1-pf)+μ-λmin=σ2NvF1-1(1-pf)+μ-(N-M)2 (8)
(3)EME算法。EME算法检验统计量为接收信号平均功率与信号协方差矩阵最小特征值的比值:
TEME=T(N)λmin (9)
其中:
T(N)=1MNi=1Mn=1Nyi(n)2 (10)
其判决门限为:
γEME=(2NMQ-1(Pfa)+1)N(N-M)2 (11)
其中,Q-1为Q函数的逆函数,Q函数为:
Q(x)=x+∞12πexp(-12t2)dt (12)
(4)CAV算法。接收信号是否存在主用户信号会导致协方差矩阵的差异,CAV算法利用这一差异进行判决检测,设:
T1=1Mi=1Mj=1Mrij (13)
T2=1Mi=1Mrii (14)
其中,rij为Ry(N)第i行第j列的元素,T1为Ry(N)所有元素绝对值的平均值,T2为Ry(N)所有对角线元素绝对值的平均值,则CAV算法检测统计量为:
TCAV=T1T2 (15)
相应判决门限为:
γCAV=1+(M-1)2Nπ1+Q-1(Pfa)2N (16)
(5)Cholesky分解算法。由于协方差矩阵的非负定性,则由Cholesky分解可知,Ry唯一表示为:
Ry=QTQ (17)
其中,Q是主对角元素大于零的上三角矩阵。当s(n)不存在时,Ry=σ2nI,由Cholesky分解得Q=σnI,即Q的非对角线元素均为零;当s(n)存在时,Ry=Rs+σ2nI,由Cholesky分解得Q的非对角线元素不为零,则Cholesky算法检测统计量为:
TCCF=1≤i≤j≤Mqij21≤i≤Mqij2 (18)
2.2 XGBoost算法
XGBoost算法是一种集成学习方法,是GBDT(Gradient Boosting Decision Tree)算法的改进算法。GBDT算法思想为通过不断降低残差,使上一次迭代模型残差在当前梯度方向上下降。模型要达到较好的评估指标一般需要一定数量的CART树,当数据量较大时,会导致GBDT模型计算量巨大,而XGBoost算法在特征粒度上进行并行处理。XGBoost算法在训练之前,预先对数据进行排序,以block结构保存,并在之后的迭代优化中重复使用这一结构。在进行节点分裂时,需要计算每个特征各切分点的增益,最终选取增益最大特征的切分点进行分裂,其对各个特征切分点的增益计算进行并行处理,从而大大减小了计算量。在迭代优化过程中,GBDT算法的损失函数只进行了一阶泰勒展开,而XGBoost算法对其损失函数进行二阶泰勒展开,对损失函数进行更精确的估计。并且该算法在计算损失时加入正则惩罚项,在迭代优化时进行预剪枝,有效地控制了模型复杂度。
XGBoost是串行树结构,第k棵树结构的生成取决于前k-1棵树的结构。XGBoost算法希望建立K个回归树,使树群预测值尽可能逼近真实值,而且有尽量强的泛化能力,因此是一个泛函最优化问题。
2.2.1 XGBoost算法损失函数
XGBoost算法数学模型表示为:
yi=k=1Kfkxi, fk∈F (19)
其中,K为树的棵数,fkxi是第k棵树对输入xi特征的输出得分值,fk为相应映射函数,F为相应函数空间。
损失函数表示为:
L=i=1nl(yi,yi)+k=1KΩfk (20)
其中,l(yi,yi)为训练模型对样本xi的训练误差,Ωfk表示第k棵树的正则惩罚项。
循环地在模型中加入一棵回归树,其损失函数都会发生改变。在加入第t棵树时,前t-1棵树已训练完成,此时前t-1棵树的正则惩罚项和训练误差均为已知常数项。则XGBoost的目标损失函数可表示为:
L=i=1nl(yi,yit-1+ftxi)+Ωft+C (21)
对于目标損失函数中的正则惩罚项部分,从单一的树结构方面加以考虑,对于其中每一棵回归树,其模型可表示为:
ftx=wqx,w∈RT,q:Rd→1,2,?T (22)
其中,T为该树的叶节点个数,w为该叶节点得分值,q(x)是模型映射关系,用来将样本映射到1~T的某个节点内。q(x)代表CART树结构,wq(x)即为单个树模型对样本x的预测值。则每一棵树的L2复杂度惩罚为:
Ωft=γT+12λj=1Tw2j (23)
此时,XGBoost目标损失函数可改写为:
L=i=1nl(yi,yti)+k=1tΩfk=i=1nl(yi,yt-1i+ftxi)+Ωft+C=i=1nl(yi,yt-1i+ftxi)+γT+12λj=1Tw2j+C (24)
2.2.2 树节点最优值求解
用泰勒二阶展开式近似表示损失函数,将ftxi看作Δx。则原目标损失函数可表示为:
Lt≈lyi,yt-1i+?yt-1lyi,yt-1ftxi+12?2yt-1lyi,yt-1ftxi2+γT+12λj=1Tw2j+C (25)
设gi=?yt-1lyi,yt-1,hi=?2yt-1lyi,yt-1,同时对于第t棵树,lyi,yt-1i为常数。去除所有常数项,进一步将目标损失函数改写为:
Lt≈i=1ngiftxi+12hiftxi2+γT+12λj=1Tw2j (26)
已知ftx=wqx,w∈RT,q:Rd→1,2,?T,将损失函数转换成在第t棵树叶节点的表达形式,第t棵回归树的叶节点角度表示为:
Lt≈i=1ngiwqxi+12hiw2qxi+γT+12λj=1Tw2j=j=1T(i∈Ijgi)wj+(12i∈Ijhi+λ)wj2+γT (27)
其中,T表示第t棵树的叶节点数量,Ij={i|q(xi)=j}表示第j个叶节点上的样本集合,wj表示第j个叶节点打分值。令Gj=i∈Ijgi,Hj=i∈Ijhi,则:
Lt≈j=1TGjwj+12(Hj+λ)w2j+γT (28)
对wj求偏导,并令其导数为零,则有:
Gj+(Hj+λ)wj=0 (29)
求解得:w?j=-GjHj+λ。
则目标损失函数最优值为:
L?=-12j=1TG2jHj+λ+γT (30)
w?j为叶节点打分值。
2.2.3 最优树结构求解
一个叶节点分裂为两个子节点的评估标准为:
Gain=12G2LHL+λ+G2RHR+λ-(GL+GR)2GL+GR+λ-γ (31)
式(30)是单节点的L?值减去切分生成两个叶节点的L?值,Gain若为正数,且值越大,表明该切分方法效果越好。γ是一个临界值,其值越大,表示对切分后L?下降的幅度要求越严格,相当于在建树的同时进行了预剪枝,以控制模型复杂度。
对所有特征切分点进行扫描,通过计算确定是否分裂该节点,以及使用哪一个切分点。如果分裂,对分裂出的两个节点递归地调用该分裂过程,找到最优树结构后,继续迭代生成下一棵树,直到模型达到最优或一定阈值后停止。
XGBoost依据该标准使用贪心算法一层一层枚举不同树结构,求出一个最优树结构加入迭代模型中。在迭代过程中,每棵树最佳叶节点值w?j由式(32)求出,此时完成整个建树过程。
2.3 算法流程
在传统基于接收信号协方差矩阵的频谱感知中,构造出如TMME、TDMM、TEME、TCAV、TCCF等检验统计量,然后依据对应门限进行二分类判决。由于这些检测统计量在一定程度上可确定接收信号中是否存在主用户信号,因此将上述统计量作为每个训练样本的特征向量,即样本特征向量为:
r=TMME,TDMM,TEME,TCAV,TCCF (32)
设总样本数为Q,则训练集表示为:
S=(r1,y1),(r2,y2),?(rQ,yQ) (33)
本文频谱感知方法处理过程如图1所示。
算法流程如下:
步骤1:根据系统模型,分别在H1和H0情况下生成信号协方差矩阵,提取特征统计量组成正负样本。对于每一固定信噪比取等量样本,对每一固定信噪比数据的每个特征列进行标准化,消除不同信噪比之间的量纲影响。
步骤2:将样本切分为训练样本data_train和测试样本data_test。
步骤3:根据XGBoost算法生成步骤,利用训练数据data_train对XGBoost算法进行训练优化,通过分步网格搜索确定超参数。
步骤4:利用测试数据样本data_test,通过各项指标对算法模型进行评估。
3 实验仿真
实验仿真基于软件MATLAB R2014a、Python3.6,硬件CPU為Inter(R) Core(TM) i5-3230M,运行内存为8GB。由MATLAB生成训练数据和测试数据,利用Python的sklearn模块进行模型训练并测试效果。实验参数设置如下:主用户信号采用BPSK信号,载波频率为7kHz,噪声信号为加性高斯白噪声,均值为0,方差为1。初始采样点数为800,初始协作用户M为5。对信噪比从-20dB到0dB、间隔为2dB的每一信噪比均生成相同数量的训练样本,且正负样本数量相同。对每一量级信噪比的样本特征列进行标准化。
3.1 训练数据量对模型性能的影响
将数据分为3组进行实验对比,第1组训练数据量为11 000,每个信噪比数据为1 000;第2组训练数据量为 22 000,每个信噪比数据为2 000;第3组训练数据量为 33 000,每个信噪比数据为3 000;测试数据量均为11 000,每个信噪比数据为1 000。分别用以上3组训练数据训练XGBoost算法得出3个模型model_1、model_2、model_3,使用AUC值作为模型评估指标,用分布网格搜索确定模型超参数,各模型在测试数据上AUC值对比如图2所示,训练与测试时间对比如表1所示,测试时间为总样本测试时间。
由图2可知,3个模型在信噪比大于等于-10dB时,AUC值均为1;在信噪比为-12dB时,model_1、model_2、model_3分别为0.999 85、0.999 73、0.999 68,各模型无明显差异;在信噪比为-14dB时,分别为0.991 77、0.993 65、0.994 00,其中model_2和model_3较model_1提升幅度基本一致;在信噪比为-16dB、-18dB、-20dB时,各模型有明显差异,其中model_2相比model_1分别提高了0.009 97、0.028 39、 0.006 66,model_3相比model_1分别提高了0.016 78、0.013 40、0.003 58。从-14dB至-20dB共4处信噪比来看,model_2相比model_1平均提高了0.011 72,model_3相比model_1平均提高了0.009 00。由此可见,model_2较model_1训练数据量增加了一倍,在低信噪比处检测概率有一定提升,而model_3较model_1训练数据量增加了两倍,其在低信噪比处的检测概率并没有高于model_2,反而有所下降,说明进一步增加训练数据量并没有更好地表征数据真实分布,反而可能导致模型复杂度增加,降低模型泛化能力。3个模型对22 000个训练样本的训练时间和11 000个测试样本的测试时间比较也符合上述推断,如表1所示,后两组模型训练时间并未与训练样本量呈线性增加,在测试数据相同的情况下,model_3的测试时间更长,说明模型计算复杂度增加,因此后续试验采用model_2的方案。
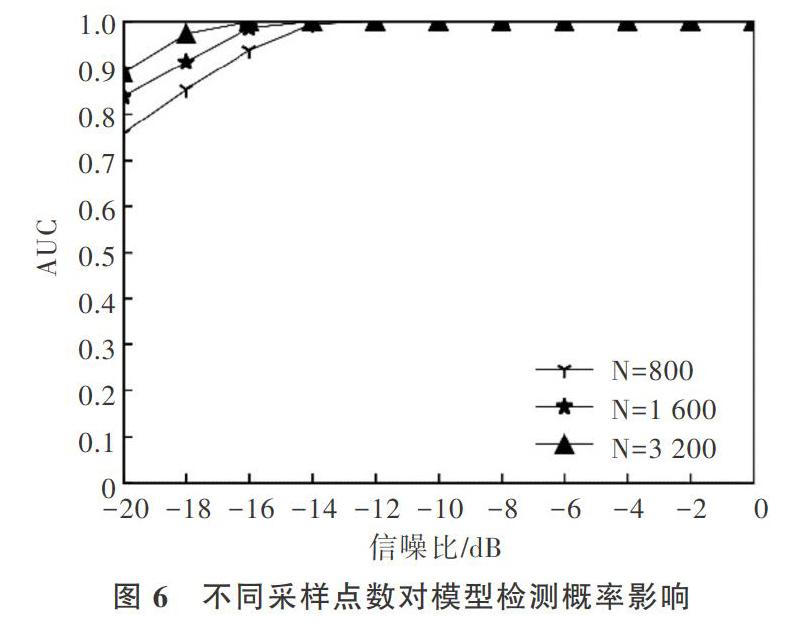
3.2 协作用户数与采样点数对模型性能影响
图3反映的是当信号采样点数为800时,不同认知用户数M对XGBoost模型性能的影响。由图3可知,协作用户越多,模型在测试数据上的AUC值越高,在低信噪比处差异越明显。图4是在虚警率为0.1时,不同协作用户M对模型检测概率的影响,其差异性变化趋势与图3相符。
[7] 杨雪梅,徐家品,何希. 基于特征值对数分布的频谱感知算法[J]. 电子技术应用, 2018, 44(1): 79-83.
[8] JAIN S A,DESHMUKH M M. Performance analysis of energy and eigen value based detection for spectrum sensing in cognitive radio network[C]. Pune:International Conference on Pervasive Computing(ICPC),2015.
[9] CHHAGAN C, RAJOO P. A reliable spectrum sensing scheme using sample covariance matrix for cognitive radio[C]. 2016 IEEE International Conference on Advances in Electronics, Communication and Computer Technology(ICAECCT), 2016: 17-20.
[10] 陈易,张杭,胡航. 基于BP神经网络的协作频谱感知技术[J]. 计算机科学,2015, 42(2): 43-45,64.
[11] 王鑫,汪晋宽,刘志刚,等. 基于随机森林的认知网络频谱感知算法[J]. 仪器仪表学报, 2013, 34(11): 2471-2477.
[12] 聂勇,叶翔,翟旭平. 基于支持向量机和噪声估计的宽带频谱感知方法[J]. 电子测量技术,2017, 40(12):88-92.
[13] 崔立波,陈立岩,刘强,等. 基于CAE与AdaBoost的频谱感知[J]. 计算机工程与设计, 2015, 36(5): 1161-1164.
[14] CHEN T Q, GUESTRIN C. XGBoost: a scalable tree boosting system[C]. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,2016:785-794.
[15] 王桂兰,赵洪山,米增强. XGBoost算法在風机主轴承故障预测中的应用[J]. 电力自动化设备, 2019, 39(1): 73-77,83.
[16] 张玄黎,修春娣,王延昭,等. 基于CSI-XGBoost的高精度WiFi室内定位算法[J]. 北京航空航天大学学报,2018,44(12):2536-2544.
[17] 崔艳鹏, 史科杏, 胡建伟. 基于XGBoost算法的Webshell检测方法研究[J]. 计算机科学, 2018, 45(S1): 375-379.
(责任编辑:黄 健)
