基于路径增强SSD的遗失物体检测模型
2020-01-05徐好好单志勇徐超
徐好好 单志勇 徐超


摘 要:在日常出行中,乘客经常会将一些重要物品遗落在出租车后座上,而司机往往因为忽视使乘客出现损失。为对车内遗失物体进行检测,提出一种改进的SSD目标检测模型。在主干网络部分引入路径增强的特征金字塔网络(FPN),称为PA-SSD。将PA-SSD应用于常见遗失物品检测实验,结果表明,该算法检测速度为12fps,在验证集上的mAP为98.6%。基于PA-SSD的检测模型能高效且准确地识别乘客遗失物体,方便通知领取,減少乘客不必要的损失。
关键词:目标检测;卷积神经网络;SSD;FPN;路径增强
DOI:10. 11907/rjdk. 201379
中图分类号:TP306 文献标识码:A 文章编号:1672-7800(2020)011-0017-04
Lost Object Detector Based on PA-SSD
XU Hao-hao1,SHAN Zhi-yong2,XU Chao1
(1. School of Information Science and Technology, Donghua University;
2. Ministry of Education, Digital Textile Research Center, Shanghai 201620, China)
Abstract:In daily travel, passengers often leave some important items in the back seat of the taxi, and drivers often fail to notice that the loss of these items, which causes passengers property lose. In order to detect the lost objects in the car,this paper proposes an improved SSD detector which uses path augumented FPN in the backbone and it is called single shot multibox detection with path augumentation(PA-SSD). PA-SSD is applied to the detection of common lost items. The experimental results show that the detection speed of this detector is 12fps, and the mAP on the verification set is 98.6. PA-SSD can efficiently and accurately identify the lost objects, and it is easy to remind the passengers.
Key Words:object detection; convolutional neural network; SSD; FPN; path augumentation
0 引言
随着深度学习的发展,基于深度学习的目标检测模型研究成为热点。Firshick[1]为解决R-CNN速度较慢问题提出Fast R-CNN,使特征提取过程可共享,加快了检测速度,但提取RoI仍然会消耗大量时间;Ren等[2]提出Faster R-CNN并引入RPN,将获取提议区域过程放入整个网络一起训练以加快检测速度;Dai等[3]提出R-FCN引入位置敏感得分图使RoI具有较明确的位置信息,减轻Head结构计算量从而提高检测速度;Redmon等[4]提出在YOLO引入网格思想,在网格中做预测;Liu等[5]在SSD中基于不同尺度特征图生成锚框进行预测;Lin等[6]提出RetinaNet引入Focal loss作为分类损失函数,避免样本不平衡的影响;佘颢等[7]引入组归一化和TReLU激活函数对SSD进行改进;沈新烽等[8]使用轻量级MobileNetV3-Large作为SSD主干网络,并利用FPN[9]提升对小物体检测效果;韩文轩等[10]采用深度可分离卷积代替卷积层加快SSD检测速度。
以上文献均没有考虑主干网络输出的较深层特征图位置信息不明确这一因素。本文借鉴PANet[11]思想,基于Mask R-CNN[12]框架进行改进,在主干网络FPN结构上添加一条自底向上的路径增强分支,用于加强深层特征图位置信息,针对PANet不便于实时性检测问题提出PA-SSD。在遗失物体图像数据集上进行训练和测试,结果显示mAP较SSD检测率有显著提升。
1 SSD简介
1.1 SSD整体框架
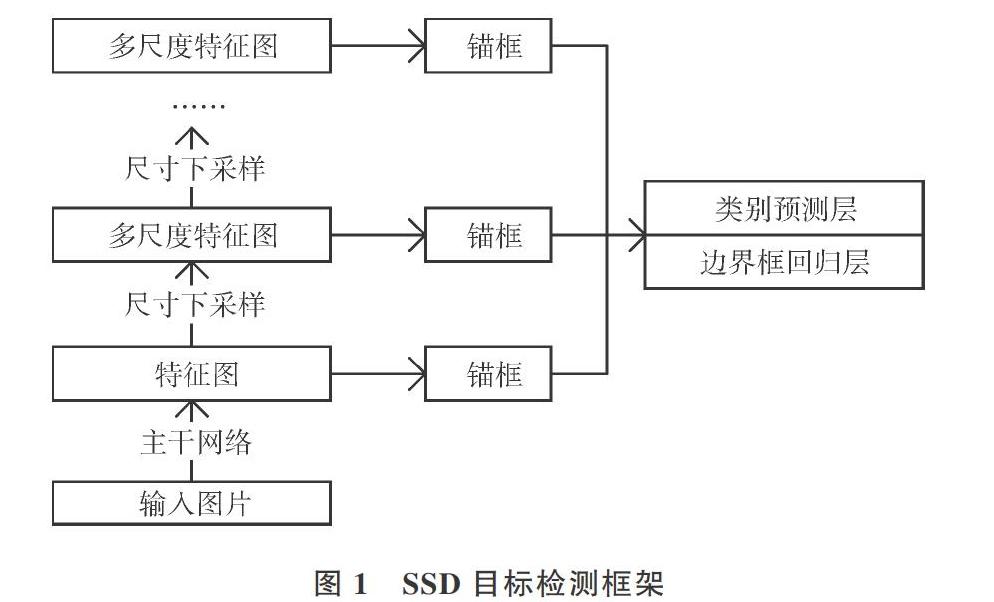
SSD整体框架由一个主干网络和若干个下采样模块连接而成,如图1所示。使用VGG16[13]作为主干网络只输出一个特征图,然后通过若干下采样模块将特征图尺寸减半生成多尺度特征图。因此,图1中越靠近顶部的特征图尺寸越小,像素感受野越大,越适合检测尺寸较大目标。针对不同尺度特征图分别基于锚框机制进行分类以及边界框偏移量回归,使检测器适应不同尺度物体。
1.2 损失函数
目标检测任务分为分类和边界框偏移量回归,最终损失函数定义为两者各自损失函数的加权和。SSD损失函数如下:
式(1)为模型最终损失函数,是回归损失和分类损失两部分的加权和。其中[N]代表锚框数量,[Lconf(x,c)]和[Lloc(x,l,g)]分别代表分类和回归损失,[x]为锚框,[c]为置信度,[l]为预测框,[g]为真实框,[α]代表权重系数。式(2)是回归损失,使用光滑L1损失,只对正类锚框计算损失,[i,j,p]分别代表锚框、真实框和类别索引,[p=0]代表背景类,[m∈{cx,cy,w,h}]代表4个边界框偏移量,[xpij={0,1}],取1时代表第[i]个锚框与第[j]个真实框交并比大于设定阈值,即关于类别[p]匹配,取0时即不匹配,不计算损失。式(3)是分类损失,为多元交叉熵损失,[cpi]代表第[i]个锚框预测为类别[p]的概率。
2 PA-SSD
使用如ResNet[14]等全卷积神经网络结构作为主干网络,输出特征图位置信息较少,通过下采样模块后生成的深层特征图包含的位置信息更少,无法准确预测目标边界框,这是SSD存在的主要问题。针对该问题,本文结合FPN以及路径增强方法对SSD进行改进,提出PA-SSD,使主干网络输出的多尺度特征图同时具有较高的位置信息和语义信息,从而提升检测精度。
2.1 FPN简介
深度卷积神经网络往往输出具有明确语义信息的特征图,但其位置信息不明确。FPN在基础网络上引入特征金字塔结构提取多尺度特征图,采用特征融合方式使得浅层特征图也具有较明确的语义信息,其结构如图2所示,包括自底向上分支、自顶向下分支以及横向连接3个部分。自底向上分支采用基础卷积神经网络结构,以ResNet为例,输出特征图分别为[C1,C2,C3,C4,C5],C1由于尺度过大不参与特征融合。横向连接利用1×1的卷积将这些特征图通道数统一到256,得到[C2,C3,C4,C5]。自顶向下分支即特征融合计算,C5即M5,上采样后与C4'作逐元素求和得到M4,同理得到M3和M2。为消除混叠效应还需要将[M2,M3,M4,M5]通过3×3卷积得到的[P2,P3,P4,P5]作为FPN输出。FPN结合锚框机制适用于检测各种尺寸目标,但FPN输出的顶层特征图位置信息并未得到加强,所以检测器对大物体位置回归不够准确。
2.2 基于路径增强FPN的主干网络
PANet为解决FPN深层特征图位置信息不明确问题引入基于路径增强的FPN作为主干网络,结构如图3所示。FPN输出[P2,P3,P4,P5],此时深层特征图位置信息仍然很弱,所以在FPN右侧添加一条自底向上的特征融合分支。P2即N2,N2通过步幅为2的3×3卷积将尺寸减半后,与P3作逐元素求和后再经过一个步幅为1的3×3卷积得到N3,同理得到N4和N5。本文为了检测更大的目标将N5通过一个最大池化层将尺寸减半得到N6。综上,基于路径增强的FPN由于进行了两次特征融合,使得特征图同时具备较明确的语义信息与位置信息,能更好地执行目标检测任务。
2.3 PA-SSD整体框架
PA-SSD目标检测流程如图4所示。为减少计算量,主干网络输出的N2不参与预测。由于FPN结构直接输出多尺度特征图,所以不需要额外的尺寸减半模块和全局平均池化层,直接基于[N3,N4,N5,N6]生成锚框并基于这些锚框进行分类与偏移量回归。
PA-SSD的Head結构包含类别预测层和边界框回归层,损失函数与SSD保持一致。设预测物体类别数为C,加上背景类,每个锚框将预测C+1个类别,则对于一个高、宽分别为h、w的特征图,每个单元生成a个锚框,一共生成ahw个锚框。分类预测层利用卷积层通道输出类别预测,将[N3,N4,N5,N6]分别进行1×1的卷积使通道数变为a(C+1),使输出和输入与特征图上每个点的空间坐标一一对应,最后使用Softmax函数作为激活函数输出类别置信度。边界框回归层设计方法同类别预测层设计类似,同样对[N3,N4,N5,N6]分别做1×1卷积。由于每个锚框需要预测4个偏移量,所以输出通道数设为4a。
3 实验结果与分析
3.1 数据集
本文使用自制数据集,包含1 000张图像,其中训练集800张,验证和测试集各100张。数据集包含6类容易遗漏的物体,分别为笔记本电脑、身份证、水杯、手机、背包和钱包。加载数据集时需将输入图片尺寸转换为1 024× 1 024×3,批量大小为4,所以一个批量输入形状为(4,3, 1 024,1 024),标签形状为(批量大小,n,5),n代表单个图像最多含有的边界框个数,本文设置n=10,而5代表物体类别及4个偏移量。
3.2 实验流程
PA-SSD损失函数与SSD保持一致,主干网络使用ResNet50基于ImageNet预训练,整个模型使用SGD优化器进行训练,基础学习率设置为1e-3,随迭代次数逐渐降低,权重衰减系数设置为5e-4,共迭代20 000次。训练流程如图5所示。
将SSD、DSSD[15]、YOLO V3[16]以及本文提出的PA-SSD在数据集上进行训练,并使用均值平均精确率(mean Average Precision, mAP)对4种检测器进行评估对比,mAP指每一类物体对应P-R曲线下的面积平均值,能够较好显示检测器质量。
3.3 实验结果
4种检测器在遗失物体数据集上对比实验如表1所示,分别记录不同检测器的主干网络结构、mAP以及识别速度。
如表1所示,PA-SSD虽然较SSD和YOLOV3牺牲了一些识别速度,但是精度得到显著提高,且精度和速度都优于DSSD,证明PA-SSD在检测遗失物体精度上优于主流一阶段目标检测框架。
为了移除检测器生成的多余边界框,在测试阶段使用非极大值抑制(non-maximum suppression,NMS)对检测器结果进行后处理,选取测试集中某张测试图片,其预测结果如图6所示,可以看到即使在光线较暗的场景下,PA-SSD也能准确识别出遗漏的物体。
4 结语
本文基于SSD提出一种PA-SSD目标检测模型,主干网络部分引入自底向上路径增强的FPN,摒弃了下采样模块和全局平均池化层获取多尺度特征图方式,直接基于主干网络输出多尺度特征图生成锚框,并进行分类和边界框回归。使用本文模型在遗失物数据集上进行训练实验,结果表明,PA-SSD较主流一阶段的检测模型具有更高的mAP。但本文自制的数据集只包含6个类别,在更多类别上的检测结果未知,泛化能力有待增强,需在后续工作中继续优化。
参考文献:
[1] GIRSHICK R. Fast R-CNN[C]. Proceedings of the IEEE conference on computer vision and pattern recognition, 2015: 1440-1448.
[2] REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[C]. Advances in Neural Information Processing Systems,2015: 91-99.
[3] DAI J, LI Y, HE K, et al. R-FCN: object detection via region-based fully convolutional networks[C]. Advances in Neural Information Processing Systems,2016: 379-387.
[4] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2016:779-788.
[5] LIU W, ANGUELOV D, ERHAN D, et al. Ssd: single shot multibox detector[C]. European Conference on Computer Vision. Springer, Cham, 2016:21-37.
[6] LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[J]. arXivpreprint:2017,1708(2),2002-2011.
[7] 佘颢,吴伶,单鲁泉. 基于SSD网络模型改进的水稻害虫识别方法[J]. 郑州大学学报(理学版): 2019,26(5):1-6.
[8] 沈新烽,姜平,周根榮. 改进SSD算法在零部件检测中的应用研究[J]. 计算机工程与应用,2011,25(4):1-10.
[9] LIN TY, DOLLAR P, GIRSHICK R,et al. Feature pyramid networks for object detection[J]. arXiv preprint, 2016,1612(1):31-44.
[10] 韩文轩,阿里甫·库尔班,黄梓桐. 基于改进SSD算法的遥感影像小目标快速检测[J]. 新疆大学学报(自然科学版),2019,18(11):1-7.
[11] LIU S,?QI L,?QIN H, et al.Path aggregation network for instance segmentation[J]. arXiv preprint, 2018,18(3):15-34.
[12] HE K, GKIOXARI G, DOLLAR P, et al. Mask r-cnn[C]. Computer Vision (ICCV), 2017 IEEE International Conference on,IEEE, 2017:2980-2988.
[13] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[J]. arXiv preprint,2014(9):1409-1556.
[14] HE K, ZHANG X, REN S, etal. Deep residual learningfor image recognition[C]. Proceedings of the IEEE conference on computer vision and pattern recognition, 2016: 770-778.
[15] FU CY, LIU W, RANGA A, et al. Dssd: deconvolutional single shot detector[J]. arXiv preprint, 2017,1701(12):59-66.
[16] REDMON J, FARHADI A. Yolov3: an incremental improvement[J]. arXiv preprint, 2018, 1804(9):27-67.
(责任编辑:杜能钢)
收稿日期:2020-04-17
基金项目:国家自然科学基金项目(61602110)
作者简介:徐好好(1994-),男,东华大学信息科学与技术学院硕士研究生,研究方向为计算机视觉;单志勇(1967-),男,博士,东华大学信息科学与技术学院副教授、硕士生导师,研究方向为电磁场与微波技术、无线通信、天线、人工智能;徐超(1994-),男,东华大学信息科学与技术学院硕士研究生,研究方向为群智能优化算法。本文通讯作者:单志勇。
