基于个人轨迹的出行模式识别
2020-01-05陈建军黄啟抒陈子晗万义良
陈建军 黄啟抒 陈子晗 万义良


摘 要 本文在大量GPS轨迹数据基础之上,分别运用C4.5决策树、支持向量机和随机森林三种机器学习算法识别了交通出行方式(包括步行、自行车、公交车、小汽车和地铁),实现基于轨迹数据的出行模式识别。首先,对轨迹数据预处理,利用时空聚类算法从离散的GPS点数据中获取停驻信息,进而提取出行段数据。其次,利用时间和坐标数据计算出行段的特征参数,包括距离、时长、平均速度、速度的95分位数、速度方差、平均加速度和最大加速度。最后,通过机器学习识别出行方式,并对三种不同算法的识别精度进行了评估。结果表明:基于速度的特征參数的区分效果显著,总时长和总距离有助于非机动车与机动车的区分以及步行与自行车的区分;C4.5决策树算法的精度为73%,支持向量机算法的精度为78%,随机森林算法的分类效果最优,准确率达到了80%以上。
关键词 GPS数据;轨迹数据;出行模式识别;机器学习
中图分类号:TP311 文献标识码:A
Travel Mode Recognition Based on Personal Trajectory Data
Chen Jianjun1, Huang Qishu2,3, Chen Zihan2,3, Wan Yiliang2,3
(1. Hunan Vocational College of Engineering, Changsha Hunan 410151; 2. College of Resources and Environmental Sciences, Hunan Normal University, Changsha Hunan 410081; 3. Key Laboratory of Geospatial Big Data Mining and Application, Hunan, Changsha Hunan 410081)
Abstract: In order to identify travel modes (walk, bike, bus, car and subway) and extract travel information from trajectory data, three machine learning algorithms including C4.5 decision tree, support vector machine and random forest are adopted to analysis massive trajectory data. Firstly, the trajectory data are preprocessed and the space-time cluster method is applied to detect the travelers residence information based on the discrete GPS point data. Based on the information the travel segments are extracted. Secondly, based on temporal information and coordinate data, the characteristic parameters of the travel segment are calculated, including distance, time interval, average speed, 95th quantile of speed, speed variance, average acceleration and maximum acceleration. At last, travel modes are detected by three machine learning algorithms and the accuracies of the recognition results are evaluated. The result shows that it is significant of the recognition based on the feature of speed, and the total time and distance can help to distinguish between non-motorized and motor vehicles and between walking and bicycles. Besides, the precision of the C4.5 decision tree algorithm is 73%, and the precision of the support vector machine algorithm is 78%. The result of random forest algorithm has the highest precision which was up to 80%.
Keywords: GPS data; trajectory data; travel mode recognition; machine learning
近年来,居民出行调查正逐渐向数据化、人工智能化转变。基于GPS轨迹数据的交通出行方式识别开始展现优势,定位技术的提高与移动通信的普及,使获取出行者数据变得海量、方便、快捷、准确、及时性高和可信度高。从居民智能手机等移动GPS采集设备获取海量轨迹数据,从中提取出行信息,就可据此对出行目的、出行方式偏好、出行分布进行分析[1]。
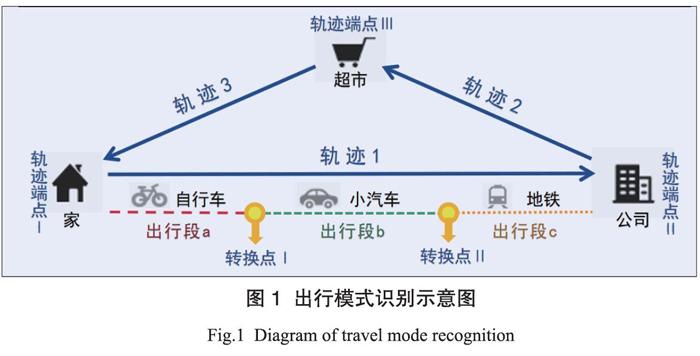
如图1所示,基于GPS数据的出行模式识别主要利用GPS轨迹点的时间特征与空间聚集程度识别轨迹端点,从而提取出行段,并计算其特征参数,然后算法实现对出行段采用的出行方式进行识别。基于GPS的出行模式识别关键在于出行轨迹特征的选取及出行模式识别算法两个方面。在出行轨迹特征方面,主要包括以下几方面的特征:(1)距离特征,包括出行距离、相邻点间距等;(2)时间特征,如时长等;(3)速度特征,包括平均速度、分位点速度、加速度、加加速度、低速点比例等;(4)方位特征,如方位角、方位变化角等[2,3]。在算法方面,目前主要采用的出行模式识别算法可分为基于规则的识別方法与基于机器学习的算法。基于规则的识别算法通常采用速度、加速度、减速度等特征构建出行模式识别规则,然后通过规则对出行方式进行分类[4]。该方法可以区分大部分步行出行和小汽车出行,却难以区分公交车和小汽车等特征较为相似的出行方式。机器学习算法可以通过综合轨迹的各种时空特征,构建轨迹聚类模型,从而达到出行模式识别的目的。Muhammad等利用随机森林算法分析手机获取的轨迹数据对出行模式进行分类[5]。李喆利用基于粒子群的支持向量机模型进行交通出行方式识别研究,得出该模型识别正确率为95.1%[6]。
本文利用GPS数据以及数据点采集的时间信息,构建多种轨迹数据时空特征,利用C4.5决策树、支持向量机与随机森林三种机器学习算法进行时空聚类分析,探讨不同轨迹模式识别算法对GPS轨迹数据特征的敏感性及其识别效果。
1 研究技术路线
本文的技术路线如图2所示,具体包括:(1)对数据进行数据筛选、数据匹配、基本特征计算等预处理;(2)依据GPS点数据的时空信息,进行数据缺失段识别和时空聚类分析,从而得到轨迹端点,将数据划分为连续的轨迹;(3)基于短暂停留点和步行段将轨迹进一步划分为出行段,并计算和分析出行段特征参数;(4)基于机器学习的出行方式识别,将选取的特征参数输入到C4.5决策树、支持向量机和随机森林三种模型中,识别出行方式,进行精度评价并对比试验结果。
2 数据与预处理
2.1 研究数据
本文采用的数据集来自微软亚洲研究院的Geolife项目[7]。该数据集是由182名用户在六年间(2007年4月-2012年8月)采集的GPS轨迹数据集,其中大部分数据是在北京市采集的,仅有极少数在其他地区分布。这些轨迹是由不同的GPS记录器和GPS电话记录的,并具有多种采样率,如1-5秒或5-10米。
数据集是由轨迹数据(plt文件)和出行方式标记数据(txt文件)两部分构成的。其中每个人的轨迹数据的示例数据如表1所示,是由按时间先后顺序排列的GPS坐标点组成的,每个点都包含纬度LAT、经度LON、海拔ASL、获取日期DATE和TIME等信息。
GPS轨迹数据中有一部分带有对应时间段的出行方式标记数据。如表2所示,出行方式标记数据由某时间段的起止时间和该时间段内采用的出行方式标记构成的。经过本文统计,该数据集包含24,802,510个有效数据点,其中共有5,268,992个数据点带有出行方式标记,最终提取出15,209条带标记的出行段。
2.2 数据预处理
(1) GPS轨迹点数据筛选
由于数据集中包含的数据量巨大,在开始提取信息之前必须要先从中获取符合研究需求的数据集。此外,由于出行方式标记数据是由人为记录的,很难避免出错。采集GPS数据时周围复杂的环境因素也容易对数据质量产生影响。因此必须对数据进行过滤筛选处理,从而提高数据质量,减小实验误差。本文的数据筛选处理主要包括:①数据格式转换:将多个plt文件存储的GPS轨迹数据导入MySQL数据库。②剔除无效数据:实现出行方式的识别的过程必须获取轨迹点数据的经纬度坐标、时间信息和出行方式标记。③剔除冗余数据:轨迹数据点是按时间先后顺序排列,若轨迹中在相同时间点记录了两条数据,则这两点间的时间间隔为零,会导致后续特征参数计算等操作出现问题。④按条件筛选:本文选取的出行方式为步行、自行车、公交车、小汽车、地铁这五种,不在条件范围内的标记数据应被剔除。
(2) GPS轨迹点基本特征计算
根据点数据的经纬度坐标和采集时间,可以计算出距离、时间间隔、速度、加速度的绝对值这四种轨迹点的基本特征。
本文中两相邻GPS点间的距离采用Haversine公式计算,此公式可计算地球表面上任意两点间的最短距离且不考虑高程数据[8]。a、b为轨迹上相邻两点,具体的距离计算公式如下:
式中,db表示a点与b点的距离;R表示地球半径;φa表示a点纬度;φb表示b点纬度;Δλ表示a点与b点的经度差。
速度计算公式如下:
式中,vb表示b点速度;db表示a点与b点的距离;Δt表示a点与b点的时间差。
加速度的绝对值计算公式如下:
式中,ab表示b点加速度的绝对值;Δv表示a点与b点的速度差;Δt表示a点与b点的时间差。
(3) 出行方式标记数据匹配
由于标记数据和轨迹数据是分开存储的,在完成数据筛选之后,需要将出行方式标记数据匹配到对应时间的轨迹点上。经过基本特征参数计算与数据匹配等预处理后的示例数据如表3所示,Time(s)表示时间间隔,Distance(m)表示两点间距离,V(m/s)表示速度,A(m/s2)表示加速度的绝对值,Mode表示在该点采用的出行方式。
3 出行段划分
3.1 轨迹端点识别
从离散的GPS点数据提取出连续的轨迹数据的原理是识别出轨迹中的停留点,从中判断出轨迹端点,并以此作为划分轨迹的标志。如图5.1所示,首先应依据时间间隔判断数据的连续性,将轨迹数据划分为缺失片段和连续片段;其次依据距离阈值从连续段中提取停留点集合。在现实生活的出行活动中,停留行为可以分为长期停留点和暂时停留点两种。例如从家到超市后停留一小时进行购物,则超市这个长期停留点即可视为这段轨迹的终止端点;驾驶汽车等待交通信号灯时停止两分钟则视为暂时停留点,不能作为划分依据。利用时空聚类分析即可在连续段中获取长期停留点。
如图3为本文轨迹端点识别的流程图。先依据相邻点的时间间隔区分缺失片段与连续片段,本文设定的时间间隔阈值Tp为150s。对于轨迹缺失片段的处理,获取缺失片段的首尾点,缺失片段的首点为轨迹终止端点,尾点为轨迹起始点。
本文对于轨迹连续片段的处理利用了DBSCAN密度聚类的算法原理[9]。首先以相邻点的距离为依据,将符合距离阈值条件Dp的点组成集合A(i)。其次根据时间间隔来筛选符合聚类条件的集合,最长时间间隔T表示轨迹中第一个数据点与最后一个数据点之间的时间间隔,最短时间间隔Tmin表示轨迹中相邻数据点间最短的时间间隔。当集合最长时间间隔T和最小时间间隔Tmin符合T/2 > Tmin时A(i)为参加聚类的集合B(i)。
计算相邻集合之间的距离Δd和时间间隔Δt。集合间的时间间隔Δt表示集合B(i)中末尾的点与B(i+1)中第一个点的时间间隔。集合间的距离Δd表示两集合中心点间的距离:
式中,Xi表示B(i)集合中心点的经度,Yi表示B(i)集合中心点的纬度,xj表示B(i)集合第j点的经度,yj表示B(i)集合第j点的纬度,n表示B(i)集合中数据点总数。
将Δd和Δt均在阈值范围内的集合合并,最终获得的长期停留点,即可作为轨迹端点去划分轨迹的连续片段。
3.2 出行方式转换点识别
在一条连续完整的轨迹中,出行者可能采用多种出行方式,例如从家到超市先乘地铁后换成步行。因此需要识别出行方式转换点,将轨迹划分成只有一种交通方式的出行段。出行方式转换时会出现短暂的停留,因此将速度为零的点作为出行段的划分依据。图5为010号人员在2008年3-5月一部分出行轨迹的出行方式识别结果。
3.3 出行段特征参数提取
计算每个出行段的特征参数,为出行方式识别提供依据。通过对相关文献的调研,特征参数可总结为如表4所示的几类:
本文计算的特征参数为出行段总距离、总时长、平均速度、速度的95分位数、速度方差、平均加速度的绝对值、最大加速度。出行段划分和特征参数计算完成后的数据示例如表5所示。
特征参数的核密度曲线如图6所示。显然非机动出行方式与机动出行方式的区分较为容易。依据平均速度Ave_v可以区分步行与自行车、汽车与公交车。速度的95分位数、总距离Sum_d和最大加速度Max_a能更好地区分五种出行方式,特别是公交车与小汽车、地铁的区分。平均加速度Ave_a的区分效果不太理想。总时长Sum_t可以区分地铁和其他机动出行方式。
4 试验及精度分析
本文此次共从GPS轨迹数据集中提取出带标记出行段15,210條,其中包含步行6898条、自行车2173、公交车2880、小汽车2344、地铁915条。按照各个出行方式所占的比例,分别随机选取70%的出行段作为训练集,输入分类器中,剩余30%的出行段作为测试集,对识别效果做出评价。
4.1 评价指标
为比较评价不同机器学习算法的识别效果,本文选择以下指标评价分类的结果。
(1)精确率(P)表示的是所有被识别为该类的样本中,判断正确的样本所占的比例:
其中,TP表示正类预测为正类的样本个数,FP表示负类预测为正类的样本个数。
(2)召回率(R)表示的是所有该类的实际样本中,被正确识别的样本所占的比例:
其中,FN表示正类预测为负类的样本个数。
(3)F-Score表示的是精确值P和召回率R的调和平均数:
4.2 结果分析
表6~8依次展示了C4.5决策树、支持向量机和随机森林算法的识别结果与评价指标。
从机器学习算法比较的角度来看,从识别结果可以分析出三总算法精度均超过70%,其中随机森林算法的识别效果最优,最高可达80%。
从出行方式的角度看,非机动出行(步行和自行车)与机动出行(汽车、公交和地铁)的区分非常容易,原因是二者的出行速度与出行距离都有极大的差别;步行与自行车的识别效果普遍比较好,机动出行之间的区分较为困难,尤其是汽车与公交车的区分,因为在三种算法中这两类的精度都是最低的,原因可能是公交车和小汽车出行的速度和各方面特征都比较相似,难以区分。此外三种算法的地铁分类召回率都偏低,本文分析有原因可能是由于地铁出行段样本偏少,且地铁因建筑遮挡对GPS数据会产生影响而造成的出行段不完整,使特征参数失去该分类应有特点。
从特征参数的角度来看,各出行方式在基于速度的特征参数中区分效果最好,尤其是平均速度特征中各类区分明显。利用速度的95分位数能很好地区分出公交车类别。总时长和距离对非机动车与机动车的区分有帮助。平均加速度绝对值的各类区分效果不够显著。
5 结论
本文利用GPS点的坐标与时间数据进行时空聚类分析,识别停留点;将离散点数据,划分成有逻辑关系的出行段数据;提取出行段的距离、时长、平均速度、速度的95分位数、速度方差、平均加速度和最大加速度这七种特征参数。其中,基于速度的特征参数的区分效果显著,平均速度为最优的特征参数,总时长和总距离有助于非机动车与机动车的区分以及步行与自行车的区分。运用C4.5决策树、支持向量机和随机森林三种机器学习算法识别出行段的出行方式,比较识别效果得出随机森林的识别效果最优,准确率最高可达80%。
参考文献/References
[1] MONTINI L, RIESER-SCH?SSLER N, HORNI A, 等. Trip purpose identification from GPS tracks[J]. Transportation Research Record, 2014, 2405(1): 16–23.
[2] 肖光年. 基于GPS轨迹数据的居民活动-出行特征识别方法[D]. 上海交通大学, 2016.
[3] 郭茂祖, 王鹏跃, 赵玲玲. 基于深度学习的出行模式识别方法[J]. 哈尔滨工业大学学报, 2019, 51(11): 1–7.
[4] STOPHER P, FITZGERALD C, ZHANG J. Search for a global positioning system device to measure person travel[J]. Transportation Research Part C: Emerging Technologies, Elsevier Limited, 2008, 16(3): 350–369.
[5] SHAFIQUE M A, HATO E. Travel Mode Detection with Varying Smartphone Data Collection Frequencies[J]. Sensors, Multidisciplinary Digital Publishing Institute, 2016, 16(5): 716.
[6] 李喆, 孙健, 倪训友. 基于智能手机大數据的交通出行方式识别研究[J]. 计算机应用研究, 2016, 33(12): 3527-3529+3558.
[7] ZHENG V W, ZHENG Y, XIE X, 等. Towards mobile intelligence: Learning from GPS history data for collaborative recommendation[J]. Artificial Intelligence, 2012, 184–185: 17–37.
[8] 樊东卫, 何勃亮, 李长华, 等. 球面距离计算方法及精度比较[J]. 天文研究与技术, 2019, 16(01): 69–76.
[9] 万豫, 黄妙华, 王思楚. 基于改进DBSCAN算法的驾驶风格识别方法研究[J]. 合肥工业大学学报(自然科学版), 2020, 43(10): 1313–1320.
*科研项目:自然资源管理知识更新及能力提升工程课程设计及研究(2020-26)、三调数据成果深度应用及拓展研究、自然资源调查监测的省市县一体化高效协同机制研究 。
*第一作者简介:陈建军,男,1975年生,测绘工程专业,主要从事测绘地理信息数据获取、处理及应用工作。
Email: chenjj205@163.com。
收稿日期:2020-09-12; 改回日期:2020-11-13。
