结合文本情感、主题、社交特征和深度学习的股价预测方法
2020-01-04陈媛先
陈媛先

[摘 要] 文章旨在提出一种结合文本数据情感值、文本主题、社交数据,并基于深度学习算法LSTM模型(Long-Short Term Memory,长短期记忆网络)的股价预测方法。文章通过将情感测量值丰富到6种,特别是测量了情感分歧值(情感值标准差),为情感参与股价预测提供了新的特征值。同时,将社交数据(文本的阅读数、点赞数)纳入模型中,考虑到了社交影响因素。在此基础上,文章将文本的主题因素纳入股价预测中,最终形成情感、主题、社交相结合的丰富文本特征集。基于OLS回归,首先验证了情感、主题、社交等特征和股价的相关性,然后,使用LSTM算法对特征与预测值进行了模型训练,最后基于训练好的模型对样本进行了回测。从回测结果看,增加了情感和主题后,模型具有良好的预测能力,对下一天收盘价的预测误差控制在0.5元以内。
[关键词] 文本情感;文本主题;LSTM;社交特征;股价预测
中图分类号:TP391.1 文献标识码:A
使用文本信息进行股票走势预测的研究越来越常见,在使用到的文本信息中,个股新闻和财报(徐伟, 李韵喆. 2015; 张梦吉, 杜婉钰, 郑楠. 2019; 杨阳. 2015)是比较常用到的一种文本信息[1-3]。此外,社交文本也成为重要的分析信息来源,比如,微博文本(朱梦珺, 蒋洪迅, 许伟. 2016; 张栋凯, 齐佳音. 2015)[4-5]。
在使用文本信息进行股价预测的时候,主要的分析方向有甄别市场情绪、分析主题、分析文本的传播效果等。大部分的研究通过其中1种或者2种方向来对股市做分析和预测。其中,情感、情绪结合股价分析是最常见的一种文本信息挖掘和使用的思路。尽管当前已经有不少研究成果,但是,我们认为当前的研究仍然存在不足,在本文中,我们将提出一种更深度利用文本信息预测股价的方式。
我们认为,现有结合情感、主题的预测方法主要不足在于:1、情感值参与预测时候仅考虑情感方向、情感强度,没有体现情感的波动。而在同一个文本中(如一个讨论特定话题的帖子),参与者不同,情感有差异,这种差异在传统的情感使用中被抹杀了,只考虑整体的情感方向和數值,本文增加考虑同一个文本中,不同情感表达的差异性,以正向方差、负向方差的方式进行体现。2、当前情感和主题参与预测时候,不考虑社交因素,本文将文本获得的关注度或者影响面加入了考虑,以文本被阅读、被点赞的数据参加模型预测。3、LDA和情感结合使用的时候,目前技术主要是使用LDA来提升对情感分类的准确性,在本文中,我们将情感和主题都当作独立的特征值,参与到LSTM算法模型的预测中。4、当前技术在结合情感进行股价预测的时候,主要使用SVM等传统分类方法进行,本文在算法选择上主要选择LSTM算法。
在文章中,我们将针对如上提到的不足进行优化,主要创新在于,第一、丰富了情感的测量。在纳入到股价预测中的情感指标中,不仅仅考虑了情感值的正负向、情感值的大小,还考虑了情感的波动(每个讨论的情感波动,包括正向情感标准差,负向情感标准差);第二、考虑了社交特征,将文本的阅读数、点赞数加入到预测模型中,将文本的影响面考虑到,并纳入估计预测模型中;第三、对股吧本文信息进行了主题挖掘,将发现的主题以新的特征加入到预测模型中。
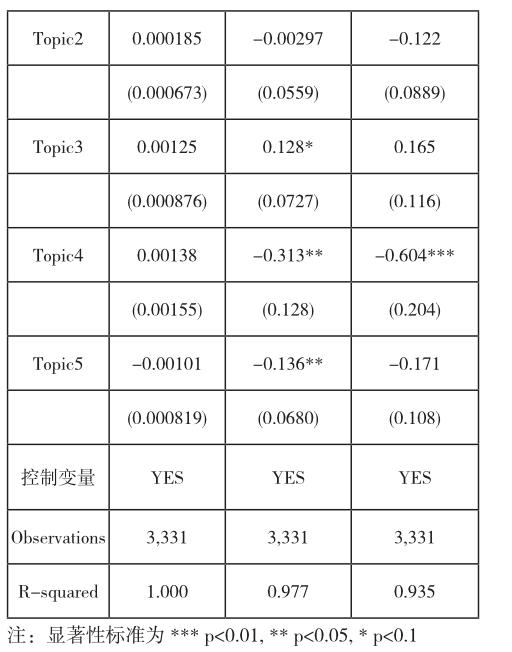
我们的重要发现包括:基于OLS回归,我们发现:情感值的多少(评论内容)和价格、交易量、交易金额不相关。相对来说,当天积极方向的情感平均值意味着10天后股价的下降。 积极方向的情感值标准差往往意味着股价在未来的上涨。而消极方向的情感值得标准差往往意味着股价在5-10天会下降。消极情感标准差值还和未来10天内的成交股数、成交金额负相关。社交帖子浏览数(Read)和未来成交股数、成交金额呈现显著正相关关系,而和未来股票价格存在显著负相关关系,意味着投资者多浏览帖子和后续的交易选择存在相关性,更大的可能性是在在决定是否买入的环节多浏览帖子会促进购买,而在出售环节,如果多参考网友意见,也会加快出售。即,投资者在买入新股和售出股票环节,都会受到网友的影响。而主题4和主题5的匹配会促进成交股数和成交金额,但是,和股价的显著下降也相关,因此,可以看到主题4和主题5的匹配主要影响股票出售策略。即,讨论如果围绕实业经营、产业周期等,意味着未来交易放量、成交活跃相关但是股价下降。主题1促进促进成交股数、交易金额和股价同步下降,即,交易萎缩、价格下降。主题3和收盘价上涨相关。主题2主要和未来10天的开盘价下跌有关。而在我们挖掘的股吧内容中,主题4和主题5主要涉及实业经营、产业更相关,而主题1、主题2和主题3主要和股票的技术走势相关。
在OLS验证了特征与未来股票交易存在相关性后,我们将特征引入到深度学习中,使用LSTM算法,对特征进行学习,训练合适的模型。我们发现,在LSTM预测股价的模型中引入情感、主题特征后,不管是在预测短期1天的股价,还是相对更长时间,比如10天的股价方面,模型的预测精准度都显著提高,这有效证明丰富的情感特征、文本主题特征对股价预测具有有效的作用。
一、文献综述
情绪结合股价进行分析和预测的方法已成为一种重要的股票分析方法。常见的分析思路如:分析投资者情绪和回报率之间的关系(Baker M , Wurgler J. 2004;Wurgler J A , Baker M P. 2006;Gregory, W, Brown,et la. 2004. Sun L , Zhang L . 2017)[6-10]。随着自然语言处理技术(NLP)的发展,国内学者在这个领域的研究也在快速推进当中,利用金融文本进行情感和股价关联分析的文章近些年也开始增多(王鸿睿, 朱青. 2010; 马驰宇2016) [11-12] 。
在文本和股价的研究中,投资者情绪的分析是一种常见的文本分析思路。一般来说,用于挖掘的文本有三类:第一类是泛文本数据,如微博论坛的社交评论文本数据。第二类是财经相关社交评论文本数据,如股吧文本数据。孟志青, 郑国杰, 赵韵雯(2018)采用东方财富股吧文本进行研究。他们结合词典,分析投资者情绪,然后基于AKMA-GARCH方法进行个股收益率预测,发现情绪对收益有短期影响,而收益率对情绪具有长期影响[13]。第三类是财报类数据,这是最正式的一种文本数据。孙伯维(2020)就通过挖掘年报文本,提炼相关特征用于进行股价预测[14]。
文本主题是通过构建文档、主题、词语三级概率分布的模式来对文本进行描述,这种方法已经广泛应用到金融分析中。徐翔, 靳菁, 吕伟欣(2018)基于LDA的方法来挖掘网络舆情,并且将分析到的网络舆情作为社会的传感器,用于预测股指走向(涨跌)。在他们的分析中,使用了支持向量机(SVM)的方法进行分类。该篇文章主要是单独使用主题分析方法来预测股市的研究[15]。涂帅(2018)在他的博士论文中将网络舆情和股票信息进行量化结合,构建了股票价格变化率的预测模型,这是利用文本信息进行股票价格预测的尝试。主题分析的思路除了在股票应用外,在其他领域的研究也开始有所研究,证明这种分析方法的广泛可行性[16]。花树雯(2019)在她的博士论文中,使用LDA主题模型的方法分析患者情感。她使用的文本信息主要来自患者留言本,在对文本信息做出情感极性分析的基础上,进行主题分析。在她的方法中,结合了LSTM的机器学习方法[17]。
在投资者情绪分析方面,情感结合文本主题的方法逐渐得到大家的认可。何永继(2016)在他的博士论文中研究了基于文本信息进行股票预测的方法。他基于微博内容,对财经类微博用户的情感进行分析,同时结合关键词和主题分析方法,构建股票的预测方法[18]。延丰,杜腾飞, 毛建华(2017)提出了基于情感词典和主题预测股价的方法。在他们的方法中,使用了情感词典来分析文本情感,包括情感的倾向、程度和相关度。在方法上,他们主要采用基于机器学习的算法,包括SVM和K-mean算法。同时,他们对文本计算了主题概率分布,最后通过结合情感+主题的方法来预测股市[19]。
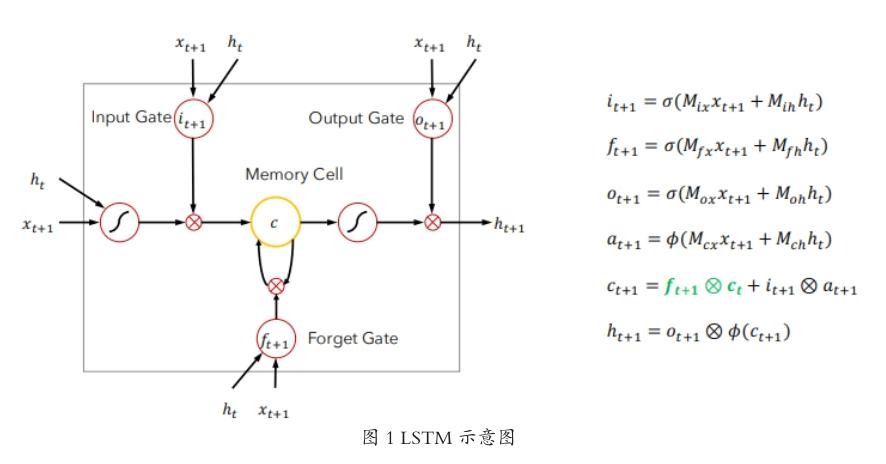
LSTM(Long Short Term Memory networks)是深度学习的一种算法,在处理时序性数据上独具优势。LSTM的优势在于在它的算法中通过sigmoid函数对信息进行了特殊的控制,即“门”的机制。在LSTM算法中,一共有三种特殊的控制“门”,分别为:遗忘门(forget gate)、输入门(input gate)和输出门(output gate)。其中,遗忘门决定在运算中抛弃哪些信息;输入门用于决定保存的信息,而输出门决定输出的隐函数。
LSTM原理如下图1:
如图1所示,LSTM算法最上层C线用于控制信息的增删,它是一个核心。模型中涉及到的参数如下:
h:神经元细胞的计算结果
X:输入向量
C:细胞状态
H:神经原细胞输出的隐向量
f:遗忘门
i:门
o:输出门
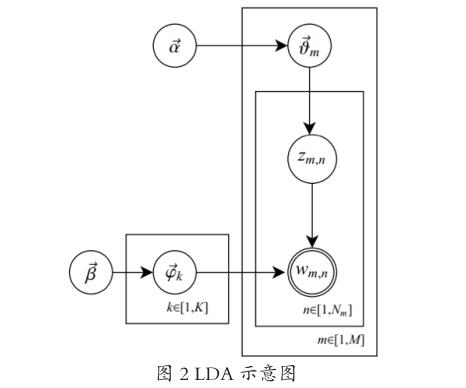
LDA(Latent Dirichlet Allocation)是机器学习领域重要的算法模型。Blei, David M.、Ng, Andrew Y.、Jordan, et al. (2012)提出LDA的文本分析方法后[6],该方法迅速成为重要的文本分析方法,结合经济的很多相关分析也开始尝试使用该方法进行使用。
LDA分类的对象是文本-词-主题,通过LDA的算法,可以对海量文本构建文本-主题-词的概率分布,示意图如图2:
如图2所示,在计算文本-主题-词概率分布的时候,有两个基本的步骤,从α到θ的过程为构建文档-主题的概率过程(Z,其中m和n分别代表文档编号和主题编号),得到p(topic|doc)。而β到Ψ为构建主题-词的过程(w),得到词汇信息,得到p(word|topic)。通过不断迭代、收敛,可以得到最优的θ和Ψ组合。计算公式如下:
二、理论构建和技术处理
尽管有文章已经尝试通过情感和主题的方法来进行股价预测,但是普遍有不足在于:
首先,在情感上沒有测量上,普遍测量的情感值只包括情感方向(正向、反向),部分研究考虑了情感的极性(比如,-7代表极强的负向情感,0代表中性,而+7代表极强的正向情感)。但是,我们认为情感的波动率体现了大众对特定事情的看法差异性,这种差异性如果没有纳入到考虑中,而只是采用一种平均的方向或者强度来替代,可能会抹杀意见分歧带来的未来变动可能。此外,分析的文本也大部分是基于微博等大众社交平台,而不是专业的股票社交平台文本。
此外,在情感值得计算上,一般按天将所有内容进行合并,然后得到得是一个综合的,并不考虑每个具体内容对应的社交影响力。我们认为,如果抛弃了社交信息建模,实际是漏掉了关键的信息,可能会导致模型误差更大,因为即使2个文本情感值一样,但是观看和点赞的人数不一样,代表这2个文本块的社会影响力是存在差异的,这种差异性如果不考虑,就会可能出现中重要特征的遗漏。
基于此,我们想构建一个完整的基于文本情感、主题、社交的股票预测模型,并且采用LSTM的方法来进行计算和预测。在构建模型前,我们需要考虑的问题有:
问题一,股吧文本很多,如何处理不同的文本,合并还是单个帖子处理?在同一个社交帖子中,不同的人针对同一个帖子的讨论主题可能具有不同的情感倾向,集合起来,一个帖子里面,整体的情感波动如何测量?哪些情感特征对股价具有预测意义?
问题二,在不同的社交文本中,即使情感值是类似的,但是文本指向的主题不同,可能对股价影响的权重是有差异的。比如,一个文本涉及的是公司财务做假,一个涉及的是公司销售客服质量,两个即使情感相似,但是因为主题差异很大,在影响股价方面可能是有差异的。因此,如何将文本涉及的主题结合到股价预测中?
问题三,文本在社交方面的实际覆盖程度,可能会导致在同样情感和主题下,文本对股价的预测能力有差异。比如,一段文本只有1个人观看,另一段文本可能有100个人观看,那么即使这两个文本的情感值和涉及到的主题一样,那么对股价的预测影响也是不一样的。如何将这种差异性考虑到股价预测模型中?
问题四,采用何种机器学习的算法进行预测?因为股票的价格具有一定的时序性质,因此,考虑时序性的算法可能会更具有优势。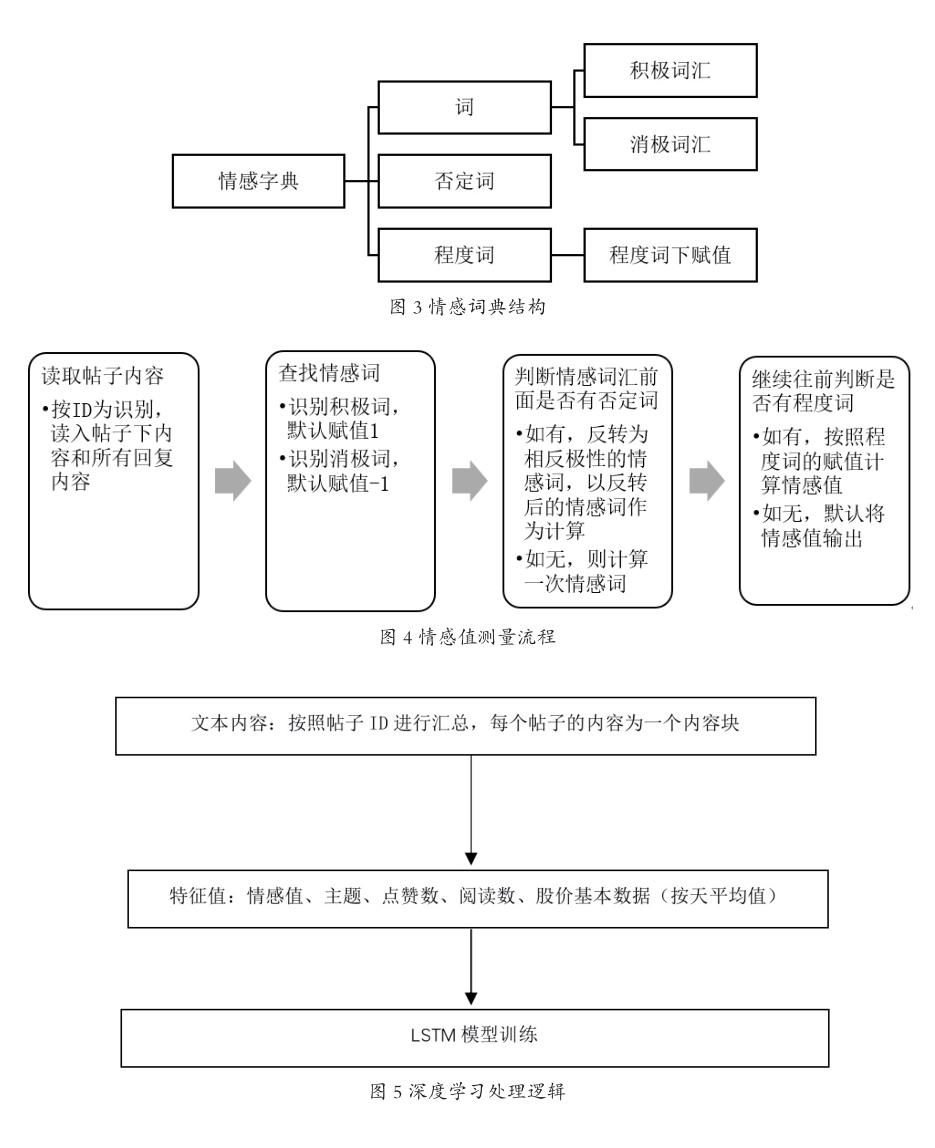
实际上,在情感处理上,我们将同一个讨论主题下的所有文本内容进行汇总,然后基于自有的情感词典进行情感测量。在我们的情感词典结构如下图4所示:
积极词汇如好、美、不错等,而消极词汇为糟糕、郁闷等。否定词如:不,非、无、勿等。程度词为极端、非常、特别、绝对等表达程度的词汇。在计算帖子情感词逻辑中,我们的处理逻辑如下图4所示:
通过如上处理,我们可以在文字中得到积极情感词和消极情感词的数字序列,将序列进行计算,得到加总值(Pos,Neg)、平均值(AvePos,AveNeg)和标准差(StdPos,StdNeg)。
在文本主题处理上,我们做了取舍,只考虑前5个主题和前10个词语。即,将所有文本中(单个帖子的汇总文字)涉及到得最重要得主题进行挖掘,得到文本的主题和每个主题下的重要词语。
在社交特征方面,我们将帖子对应的的点赞、阅读数据作为单独的字段加入预测模型的特征值序列中。
在模型算法上,我们选择LSMT(Long-Short Term Memory)作为支撑算法。LSTM(长短期记忆网络),是一种时间循环神经网络。LSTM通过输入门、遗忘门、输出门的设置,在处理和预测时间序列中间隔和延迟非常长的重要事件方面具有独特的优势。考虑到涉及不同情感和不同主题的讨论文本在真实的环境中可能延续不同的时间,LSTM是一个比较好的选择。最终完整的预测流程如下图5:
三、实证分析
(一)数据和处理过程
我们从tushare拉取了东方雨虹(股票代码为:002271)历史股价数据,数据格式为天, 数据字段包括时间(天)、开盘价(open)、收盘价(close)、最高价(high)、最低价(low)、股价变动(change)、股价涨跌幅(pct_change)、前一天收盘价(pre_ close)、成交手数(vol)、成交量(amount)。
我们的文本数据来自某股吧论坛。我们爬取了东方雨虹(股票代码为:002271)股吧的讨论帖子,一共9076多个帖子。爬取关于东方雨虹股票历年社交评论的文本数据,包括:文本内容、对应社交文本当前最新的阅读数量、被点赞数量,每类数据为1列,分别设置字段为Text、Read、UP_vote。每个文本数据赋予独立ID,ID按照时间(天)顺序,从1开始编号,为1,2,….,依次编号。
我们首先对文本数据(帖子内容)进行处理,处理过程为:分词(结巴工具)、进行主题分析(基于LDA,分析的参数设置为:主题5个,每个主题10个词语),得到前5个主题和对应词,如下:
主题1对应词汇:”大宗”“解禁”“抛出”“吸回”“诱多”“下车”“崩盘”。
主题2对应词汇:“见底”“腰斩”“老股民”“纳斯达克”“领先”“不同”“相似”“意味着“。
主题3对应词汇:“飞天”“下车”“逻辑”“仓位”“崩盘”“一半”“后市”“前天”“优秀“。
主题4对应词汇:“科技”“5g”“产业”“周期”“中长期”“进军”“世界”“资本”“安全”“现金流”“裁员“。
主题5对应词汇:“顶背离”“卧倒”“安全”“研究”“智能”“背离”“理论”“边缘”“工程”“护盘”“macd”。
可以看到,主题4和主题5讨论话题和实业经营、产业更相关,而主题1、主题2和主题3主要和股票的技术走势相关。
在此基礎上,我们创建了5个新的字段:Topic1,Topic2,Topic3,Topic4和Topic5,然后分别赋值,赋值逻辑如下:
如果当前文本(Text)涉及主题1中任何一个词语,则Topic1赋值为1,否则为0;
如果当前文本(Text)涉及主题2中任何一个词语,则Topic2赋值为1,否则为0;
如果当前文本(Text)涉及主题3中任何一个词语,则Topic3赋值为1,否则为0;
如果当前文本(Text)涉及主题4中任何一个词语,则Topic4赋值为1,否则为0;
如果当前文本(Text)涉及主题5中任何一个词语,则Topic5赋值为1,否则为0;
接着,我们将文本数据(帖子内容)进行情感分析,处理过程为:分词(结巴工具)、情感分析。在处理帖子的时候,首先将单个帖子的所有评论汇总,然后分析帖子内容的情感值。在情感值分析上,对内容进行了如下情感值处理:
首先识别分词后词向量中有的情感词,是积极词汇还是消极词汇,如果是积极词汇,则赋值1,消极词汇赋值-1。情感词汇的识别按照词典方式进行管理。然后识别是否情感词词有反转,如果在情感词前面有强化助词,如非常、太等,会对情感词进行加权,加权分四级,如非常、很、更、通常,加权分数为4,3,2,1。四级强度词依据词典进行加权。
通过以上处理,在一个帖子内容中,我们可以得到多个情感词和对应分值。我们将情感数值按帖子内容处理得到如下情感指标:正向情感值累加值、负向情感值累加值、正向情感标准差、负向情感标准差、正向情感平均值、负向情感累加值, 分别对应字段为:Pos、Neg、AvePos、AveNeg、StdPos、StdNeg。
最后我们合并股价数据、主题数据、情感数据、社交数据依据ID进行汇总,得到包含如下字段的文件。
至此,我们的数据处理部分完成。样本总量为9076,单个帖子积极情值最高为2980000,消极情感值为1850000。所有帖子的平均积极情感值为442.655,消极情感值为251.143。因此,在所有帖子中,積极的情感词比消极的情感值要高。情感波动方面,积极情感值的波动率为251.143,而消极情感值波动率为152.332,即,在积极情感方面看法差异较大。帖子的平均阅读数量为2127.626,因此股吧帖子的浏览还是比较大的。点赞平均值为1.29,大部分的帖子是没点赞。涉及到主题1的帖子占77.1%,涉及到主题2的帖子为68.1%,涉及主题3的帖子为37.4%,涉及主题4的为24.4%,涉及主题5的为38.7%。因此,大部分的帖子讨论的还是技术走势,涉及主题4和5,即实业和长远经营的帖子占比较低。开盘价平均为26.502,收盘价平均为27.061,收盘价平均为26.526。日成交量平均204000,日股价涨跌幅在-2.17%和3.28%之间,日价格最高波动为跌-7.987和涨10.025元,平均变动了18.2%。
(二)特征相关性验证-基于OLS回归
在实证部分,我们验证情感指标、主题指标和社交指标与未来股价、交易量和交易金额的相关性。我们主要在控制了前一天交易数据基础上进行分析,前一天交易数据的变量包括开盘价(open)、最高价(high)、最低价(low)、收盘价(close)、成交股数(vol)、交易金额(amount)、涨跌幅(change)和股价变动(pct_ chg)。
验证情感指标、主题指标和社交指标与未来股价(收盘价)的相关性采用简单OLS回归,回归结果见表1。
从表2可以看到,情感值的总和(logPos, logNeg)对未来1天(next1day_close)、未来5天(next5day_ close)和未来10天(next10day_close)的收盘价无显著相关性。当天的情感波动是标准差是正的,和未来1天的收盘价无显著相关关系,但是和未来5天及10天的股价是显著正相关的。当天的情感波动是标准差是负的,和未来1天的收盘价无显著相关关系,但是和未来5天及10天的股价是显著负相关的。
当天社交帖子的阅读数显著增多,和未来1天的收盘价是显著正相关关系,而和未来5天、10天的股价显著负相关。当天社交帖子的点赞数显著增多,则和未来1天的收盘价显著负相关,但是和未来5天和10天的股价无任何相关关系。
当天的社交帖子内容如果匹配到Topic1,则和未来5天股价显著负相关。当天的社交帖子内容如果匹配到Topic2,和未来1天、5天、10天收盘价无显著相关性。当天的社交帖子内容如果匹配到Topic3,和未来5天收盘价显著正相关。当天的社交帖子内容如果匹配到Topic4,和未来5天、10天收盘价显著负相关。当天的社交帖子内容如果匹配到Topic5,和未来5天收盘价显著负相关。
从表2可以看到,情感值的总和(logPos, logNeg)对未来1天(next1day_open)、未来5天(next5day_open)和未来10天(next10day_open)的开盘价影响都是不显著的。情感值平均值 logAvePos, logAveNeg总,积极的情感平均值和未来10天的开盘价是负相关的,但是消极的情感平均值和未来开盘价不相关。当天的情感波动是标准差是正的,和未来1天、未来5天及10天的开盘价是显著正相关的。当天的情感波动是标准差是负的,和10天的开盘价是显著负相关的。
当天社交帖子的阅读数显著增多,和未来1天、未来5天、10天的开盘价显著负相关。当天社交帖子的点赞数显著增多,则和未来1天、未来5天和10天的开盘价无任何相关关系。
当天的社交帖子内容如果匹配到Topic1,则和未来1天、5天开盘价显著负相关,但是和未来10天开盘价无显著相关性。当天的社交帖子内容如果匹配到Topic2,和未来10天开盘价显著负相关,但是和1天、5天的开盘价无显著相关性。当天的社交帖子内容如果匹配到Topic3,和未来1天、5天开盘价显著正相关,但是和未来10天开盘价不相关。当天的社交帖子内容如果匹配到Topic4,和未来5天、10天开盘价显著负相关,和未来1天不相关。当天的社交帖子内容如果匹配到Topic5,和未来5天开盘价显著负相关。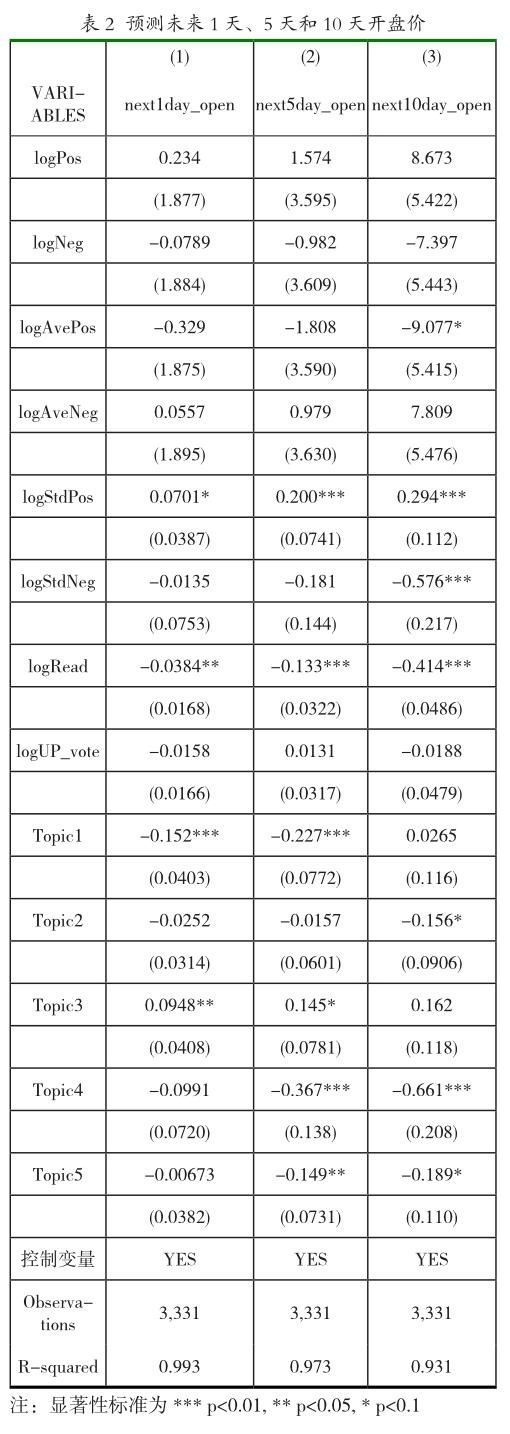
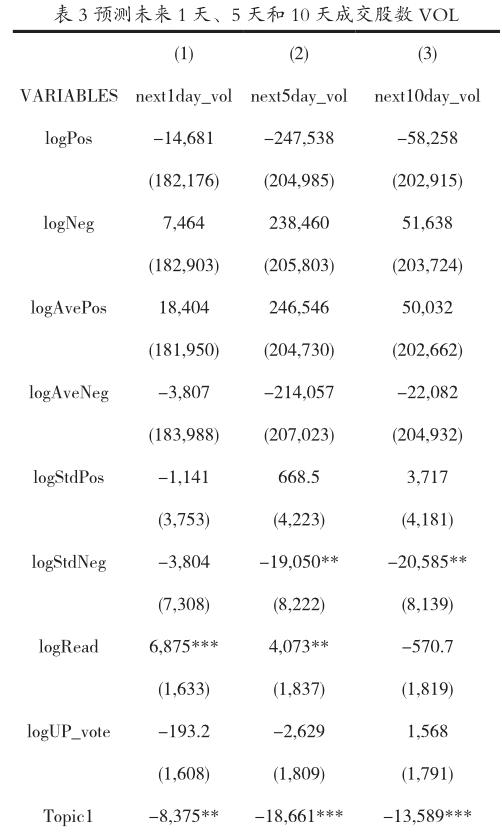
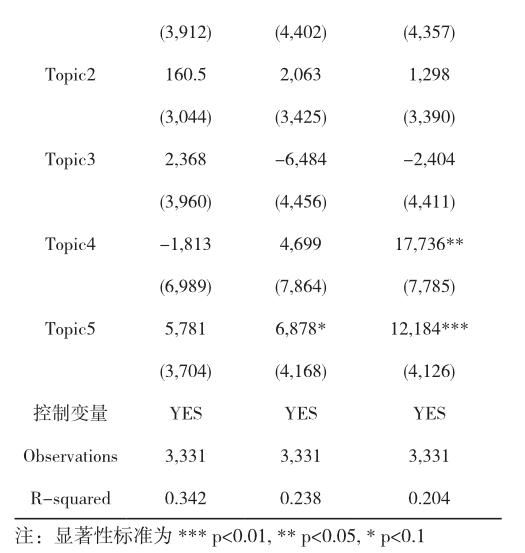
从下表3可以看到,当天的情感波动是标准差是负的,和10天的成交股数VOL是显著负相关的, 情感的其他指标和未来1天(next1day_vol)、5天(next5day_ vol)和10天(next10day_vol)的成交股数VOL均无显著相关性。
当天社交帖子的阅读数显著增多,和未来1天、未来5天的成交股数VOL显著正相关。当天社交帖子的点赞数和未来1天、未来5天、未来10天的成交股数VOL无显著相关性。
当天的社交帖子内容如果匹配到Topic1,则和未来1天、5天、10天成交股数VOL显著负相关。当天的社交帖子内容如果匹配到Topic4,和未来0天成交股数VOL显著正相关,和未来1天、5天无显著相关性。当天的社交帖子内容如果匹配到Topic5,和未来5天、10天的成交股数VOL显著正相关。当天的社交帖子内容如果匹配到Topic2和Topic3,则和未来1天、5天和10天的当天成交股数VOL无显著相关性。
从下表4可以看到,当天的情感波动是标准差是负的,和未来5天、10天的成交金额Amount是显著负相关的, 情感的其他指标和未来1天、5天和10天的成交金额Amount均无显著相关性。
当天社交帖子的阅读数显著增多,和未来1天的成交金额Amount显著正相关。和未来5天的成交金额Amount显著负相关。当天社交帖子的点赞数和未来10天的成交金额Amount显著正相关。
当天的社交帖子内容如果匹配到Topic1,则和未来5天、10天成交金额Amount显著负相关。当天的社交帖子内容如果匹配到Topic5,和未来5天、10天的成交金额Amount显著正相关。当天的社交帖子内容如果匹配到主题,则和未来1天、5天和10天的当天成交金额Amount无显著相关性。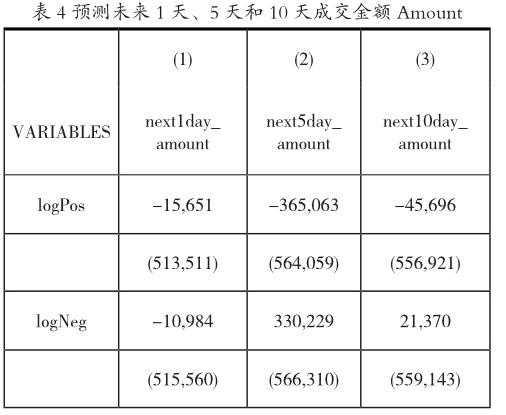
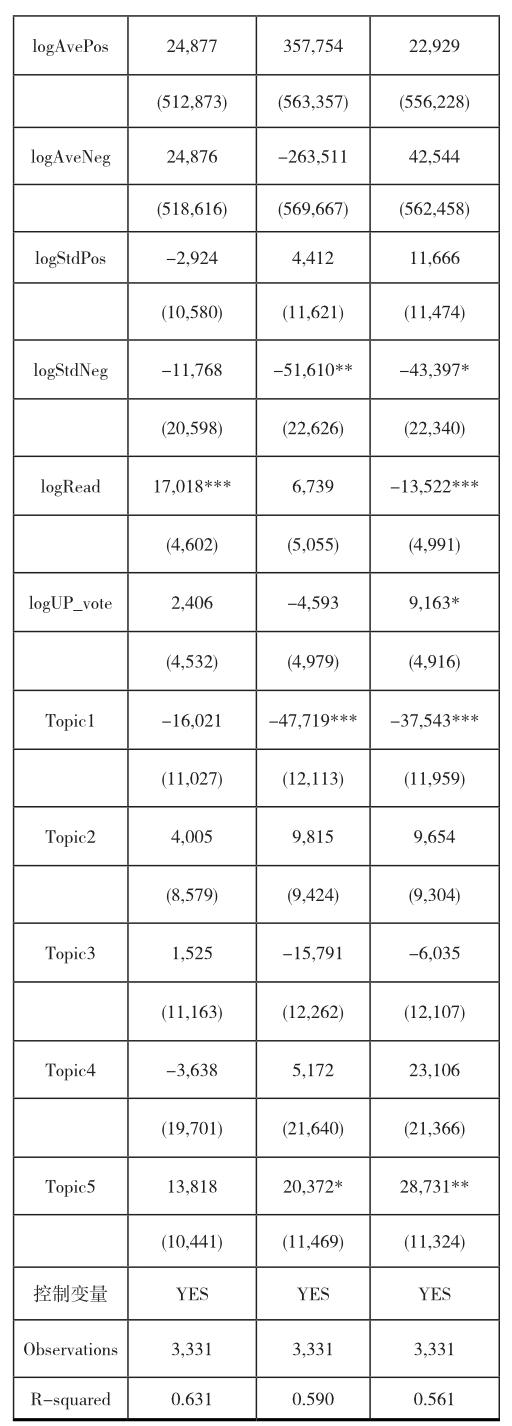
注:显著性标准为*** p<0.01, ** p<0.05, * p<0.1
从以上分析,我们可以观察到一个现象,情感值的多少(评论内容)和价格、交易量、交易金额不相关。相对来说,当天积极方向的情感平均值意味着10天后股价的下降。积极方向的情感值标准差往往意味着股价在未来的上涨。而消极方向的情感值得标准差往往意味着股价在5-10天会下降。我们认为情感标准差体现的是意见的差异,意见差异大,意味着分歧多,而积极和消极两个方向的标准差体现的是哪个方向的合理更大些,因此,和股价的趋势存在一定的相关性。消极情感标准差值还和未来10天内的成交股数、成交金额负相关。
社交帖子浏览数(Read)和未来成交股数、成交金额呈现显著正相关关系,而和未来股票价格存在显著负相关关系。意味着投资者多浏览帖子和后续的交易选择存在相关性,更大的可能性是在在决定是否买入的环节多浏览帖子会促进购买,而在出售环节,如果多参考网友意见,也会加快出售。即,投资者在买入新股和售出股票环节,都会受到网友的影响。
Topic4和topic5的匹配会促进成交股数和成交金额,但是,和股价的显著下降也相关,因此,可以看到topic4和topic5的匹配主要影响股票出售策略。即,讨论如果围绕实业经营、产业周期等,意味着未来交易放量、成交活跃相关但是股价下降。Topic1促进促进成交股数、交易金额和股价同步下降,即,交易萎缩、价格下降。Topic3和收盘价上涨相关。Topic2主要和未来10天的开盘价下跌有关。
(三)基于深度学习LSTM算法的模型训练和预测结果
我们采用Pytorch框架进行机器学习,选择的算法是LSTM。因为样本量较少(处理为天后,样本量只有367个),我们将样本划分为训练集和预测集,各自比例为0.94和0.06。作为特征进行学习的字段包括:Pos、Neg、AvePos、AveNeg、StdPos、StdNeg、Read、UP_vote、Topic1,Topic2,Topic3,Topic4, Topic5,开盘价(open),最高价(high)、最低价(low)和收盘价(close),交易量(vol)、成交额(amount)、前一天收盘价(pre_ close)、涨跌幅(change)、股价变动(pct_chg)。我们需要预测的值为下一天的收盘价(next1day_close)。我们的目标是预测未来1天收盘价,在训练好模型后调用,得到预测值,然后将预测值和真实值进行对比。在LSTM预测上,我们将数据处理为均值,即对特征指标和预测指标均按天计算均值。
Train loss是训练数据上的损失,衡量模型在训练集上的拟合能力。Valid loss是在验证集上的损失,衡量的是在未见过数据上的拟合能力,也可以说是泛化能力。模型的真正效果应该用valid loss来衡量。损失函数定义为:Loss=(真实值-预测值)2的均值
我们设置迭代20次,可以看到,随着迭代次数增多,损失下降很快,在迭代到20次的时候,训练损失和验证损失趋平(图6)。
将训练好的模型进行回测,回测价格和真实价格的对比如下图7。 图中蓝色为真实价格,红色为预测价格。可以看到,预测价格和真实价格之间差距在0.5元以内,模型具有较好的预测效果(图7)。
四、结语
本文旨在提出一种结合文本数据情感值、文本主题、社交数据和LSTM(Long-Short Term Memory,长短期记忆网络)算法的股价预测模型。本文通过将情感分类从简单的正负向丰富为情感波动,包括6种情感值,为情感参与基于深度学习的股价预测提供了新的特征值。同时,将文本的社交数据(文本的阅读数、点赞数)纳入模型中,考虑到了文本本身产生的影响面因素。更为重要的是,本文在此基础上,将文本所重要表达的主题加入的股价预测模型中。
本文通過对股吧的帖子文本进行分析,在帖子的维度将情感值、主题、社交等特征进行提取,然后和股价信息合并。一共采用了9076多条帖子内容,时间跨度从2018/8/2到2020/5/26(共367个交易日)。首先通过OLS回归,验证了情感、主题、社交等特征变量和股票交易存在相关性,然后基于深度学习模型(LSTM)对进行数据训练,最后基于训练好的模型对数据进行了回测。从回测结果看,预测值和真实值的差距在0.5元左右,模型具有较好的预测能力。
本文的不足在只在单只股票上进行了测试,尚未完成将单只股票方法推广到其他股票,因此,这种方法是否在其他股票上也会存在很好的预测能力,尚需要进一步研究。其次,本文在处理主题的时候,选择的是5个主题和10个词语的方法,这种方法是否是一种最优的方案也存在质疑,也需要进一步研究。
参考文献:
[1]徐伟,李韵喆.行业与个股新闻对股票价格影响的定量分析[J].财经界,2015(020):31-32.
[2]张梦吉,杜婉钰,郑楠.引入新闻短文本的个股走势预测模型[J].数据分析与知识发现,2019(5):11-18.
[3]杨阳.上市公司新闻情感倾向对股价的影响分析[D].北京:北京理工大学,2015.
[4]朱梦珺,蒋洪迅,许伟.基于金融微博情感与传播效果的股票价格预测[J].山东大学学报 (理学版),2016(11):13-25.
[5]张栋凯,齐佳音.基于微博的企业突发危机事件网络舆情的股价冲击效应[J].情报杂志, 2015(003):132-137.
[6]Blei, David M.、Ng, Andrew Y.、Jordan, et al. Latent Dirichlet Allocation[J]. J. Mach. Learn. Res,2012(3):
993-1022.
[7]Wurgler J A , Baker M P . Investor Sentiment and the Cross-Section of Stock Returns[J]. Economic Management Journal, 2006,61(4):1645-1680.
[8]Baker M,Wurgler J . Investor Sentiment and the Cross-Section of Stock Returns[J]. NBER Working Papers,2004.
[9]Gregory, W, Brown,et la. Investor sentiment and the near-term stock market[J]. Journal of Empirical Finance,
2004.
[10]Sun L , Zhang L . Optimal consumption and investment under irrational beliefs[J]. Journal of Industrial and Management Optimization, 2017,7(1):139-156.
[11]马驰宇.网络金融信息情感分析及其与股票市场波动关联关系研究[D].合肥:合肥工业大学,2016.
[12]王鸿睿,朱青.基于金融文本情感的股价关联挖掘模型[J].企业技术开发,2010(21):78-79.
[13]孟志青,郑国杰,赵韵雯.网络投资者情绪与股票市场价格关系研究——基于文本挖掘技术分析[J].价格理论与实践,2018(008):127-130.
[14]孙伯维.年报文本与数据分析及可视化的设计与实现[D].大连:大连理工大学,2020.
[15]徐翔,靳菁,吕伟欣.网络舆情作为社会传感器对股票指数的影响——基于LDA主题模型的挖掘分析[J].财务与金融,
2018,176(06):5-13.
[16]涂帅.基于网络舆情的股票信息分析与建模[D].兰州:兰州理工大学,2018.
[17]花樹雯.基于LSTM和LDA模型的患者情感分析研究[D].杭州:浙江理工大学,2018.
[18]何永继.基于微博情感分析的股市预测方法研究[D].南京:南京大学,2016.
[19]延丰,杜腾飞,毛建华,等.基于情感词典与LDA模型的股市文本情感分析[J].电子测量技术,2017(12):82-87.
