基于文本挖掘的教学设计能力需求研究
2019-12-30郭杰誉
郭杰誉


摘 要:教育改革、在线教育、STEM教育的不断发展,对教育工作者的教学设计能力提出了新的要求,如何识别这些要求,成为教学设计领域不可忽视的问题。该研究从市场真实数据入手,采用文本挖掘技术分析教学设计能力需求,包括:根据现有研究提出教学设计能力分析框架;使用爬虫技术获取北上广深一线城市与“教学设计”相关的岗位数据,进行分组、分词等文本预处理,并使用分类器验证分类合理;依据教学设计分析能力框架和分词结果构建教学设计能力指标体系与词袋模型;建立能力分析雷达图,呈现每类岗位能力需求的具体情况;并根据研究结果提出提供灵活的课程体系以满足教学设计能力需求的模块组合、丰富前沿领域的教学实践以培养实战能力等建议。
关键词:文本挖掘;教学设计;能力指标;词袋模型
中图分类号:G420 文献标志码:A 文章编号:1673-8454(2019)23-0067-07
一、引言
杜华分析1982-2012年间与“教学设计”相关的国内外文献,指出国内教学设计在应用上仅限于学校范畴。[1]然而,教学设计的实际需求并不仅限于学校范畴,不论是一直存在的企业培训领域,还是已兴起的在线教育、STEM教育领域,都体现出对教学设计的强烈需求,本研究使用的数千条与“教学设计”相关的岗位信息就是最有力的证据。本文以这些岗位信息为研究对象,综合应用教学设计能力和文本挖掘技术两大领域的理论知识,挖掘当下校外范畴的教学设计能力需求,对相关领域的学术研究及人才培养具有一定的指导意义。
二、理论依据与研究框架
1.教学设计能力
教学设计是连接教与学的理论与教学实践的桥梁学科,试图运用系统方法寻找解决教学问题的最佳方案;[2]教学设计是一个系统过程,即把教与学的原理转化到教学材料、教学计划、教学过程等计划方案中的过程。[3]上述两个定义反映出教学设计的功能和宏观研究对象,即连接教与学的理论和教学实践的桥梁功能,涉及教与学理论、系统方法、计划与过程等研究对象。为合理运用各种理论、经验,有效实现教學设计的功能,自然对相关从业者的教学设计能力提出了要求。
能力是完成一项目标或者任务所体现出来的综合素质,从职业能力开发视角看,能力是知识、技能和态度与具体的职位或工作情境的结合。[4]因此,本研究认为教学设计能力是相关从业者能够依据相关理论或经验,分析教学问题、组织教学资源、设计教学方案并进行实施与改进,最终解决教学问题所具备的知识、技能和态度的总和。
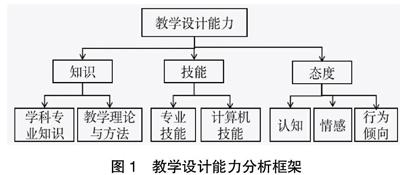
具体来说,知识方面,不仅包括学科专业知识,也包括教学理论、方法等内容;技能方面,按照教学设计的流程可以分为分析能力、设计能力和评价能力,但从操作层面看,会涉及办公软件的使用、图形处理、编程等具体技能;[5]态度方面,刘美凤等将教学设计能力的态度方面分为重要性认识、应用意识、评价与反思意识以及终身学习意识四个维度,而态度包含认知、情感和行为倾向三种成分,上述四个维度仅阐述了态度的认知成分和行为倾向成分,因此需要添加情感成分(如喜欢、热爱等)。[5]综上,本研究依据的教学设计能力分析框架如图1所示,后续将结合所使用的文本信息,依据知识、技能和态度三个维度及其子维度,提出具体的词汇分类指标。
2.文本挖掘技术
文本挖掘也称文本数据挖掘,其主要目的是采用数据挖掘技术,从非结构化或半结构化的语言文本中提取出潜在有价值的、新颖的、可被理解的、重要的模式和知识。[6]文本挖掘的一般过程如2图所示。本研究在文本分类验证研究、根据词袋模型建立能力分析雷达图的过程中均不同程度地运用到图2所示的研究步骤,不同之处主要体现在特定处理模式环节。
3.研究框架
本研究的框架如图3所示。从网页获取的1450条职位信息作为文档集,首先依据职位名称分成三类,分别是教师/讲师类、研发设计类以及职能类。为了验证分类是否合理,分别使用kNN、朴素贝叶斯、TF-IDF·朴素贝叶斯三种分类器进行检验,最终发现使用了朴素贝叶斯原理的分类器错误率稳定,纯朴素贝叶斯分类器的错误率最低,说明上述分类的每类文本呈现一定特征,分类可取。
接着,依据上述教学设计能力分析框架(见图1),并结合具体高频词汇,提出知识储备、设计分析能力、教学能力、沟通能力、管理能力、办公软件能力、计算机语言能力、图形处理与设计、情感态度与个人素质等9个指标,每个指标由若干词汇构成的词袋模型表示。最后依据“能力指标-词袋模型”挖掘三类职位在9个指标上的分布情况,并进行解读。
三、研究内容
研究内容具体包括文本预处理、分类器验证、建立能力指标及词袋模型、建立能力分析雷达图等部分。
1.文本预处理
文本预处理包括数据准备、文本清洗、分词、特征选择等过程。本研究使用的朴素贝叶斯分类器、TF-IDF·朴素贝叶斯分类器、kNN分类器,以及能力指标-词袋模型和能力分析雷达图的建立均基于相同的文本获取与预处理过程,现阐述如下。
(1)文本获取与异常值处理
本研究在智联招聘平台上,以“教学设计”为关键词,搜索得到北京、上海、广州、深圳四个城市的岗位信息,借助Python爬虫代码将岗位信息获取下来,每条数据包括岗位名称、岗位职责/职位描述,以及该岗位的URL链接等信息。
异常值包括缺失值和重复值。由于部分网页的结构略有不同,直接获取的数据中有30条左右的岗位职责/职位描述信息缺失,考虑到空缺信息量不大,且均是重要信息,就根据URL链接定位到具体的网页,重新获取相关信息。重复的数据有两类,一类是内容一样,但URL链接不一样,研究发现是同一家公司或机构连续发布了几条相同的招聘信息;另一类是内容和URL均一样,这可能是由于网页更新引起的,这两种情况均去掉重复的,保留一条,最终获得1450条数据,其中岗位职责/职位描述等文本信息是本文的重点研究对象。
(2)文本清洗
(3)自定义词典与分词
本研究使用jieba分词模块,该分词算法结合了基于规则和基于统计的分词方法,同时还可以添加自定义词典,适用性强。[7]研究特定领域的信息时,将该领域的专业词汇识别出来至关重要,为了达到较好的分词效果,需要建立自定义词典,如将“教学设计”、“教育心理学”、“课程开发”、“教师资格证”等体现领域特色的词汇加入自定义词典,分词结果就会呈现出这些词汇,避免词汇意义过度稀释。
(4)停用词表与特征选择
停用词表包含众多语气助词、虚词、特殊符号,以及众多无意义的词汇,如“的”、“用于”、“至于”等,使用停用词表可以在分词的基础上去掉这些无意义的词汇。同时,多次观察分词结果,可将更多与研究主题无关的词汇添加到停用词表中,如“薪资”、“周末”、“地点”等,以利于特征词汇呈现,减小特征向量的长度。
最终分词后得到8188个不同词汇,这些词汇构成词汇列表V=[v1,v2,…,v8188],同时用一个长度为1450的列表CL存储各文档的类型标签,若三类职位分别标注为A、B、C,则CL[ci] (ci∈(A,B,C),i=1,2,…,1450)。
2.使用分类算法检验分类可行性
为了更有针对性地分析能力需求,根据职位名称将与教学设计相关的岗位信息分成了“教师/讲师类”、“研发设计类”以及“职能类”三种,为了验证这种类型是否合理,使用监督型分类器进行验证,即通过学习训练集中的数据,建立一定模型,再用该模型对测试集中的数据进行分类,如果错误率较低且稳定,就说明各类型的文档呈现一定特征,分类可取,各类型的具体特征有挖掘的价值。笔者试验了多种分类器,最终发现使用了贝叶斯原理的分类器满足要求。
对于第i个文档di,根据词汇列表V统计该文档中出现相应词汇的出现次数,存入一个新的列表Wi,作为该文档的特征向量,即Wi=[wi,k] (k=1,2,…,8188),称Wi为文档di的基于词汇频数的特征向量。1450个文档构成一个1450×8188的矩阵,用M0表示,即M0=[Wi]=[[wi,k]] (i=1,2,…,1450;k=1,2,…,8188)。分类器将矩阵M0的数据按一定比例随机分成训练集和测试集,并结合类标签列表CL[ci]建立相应模型。
(1)kNN分类器
k-近邻算法(kNN)采用测量不同特征值之间的距离方法进行分类,即计算出待分类数据与每个训练数据的距离,从中选出k个最小的距离所对应的样本数据,统计这k个样本数据中出现次数最多的分类,就作为待分类数据的分类,本研究有三个类别,所以k取4。[8]
数据之间的距离可以采用两个向量的余弦相似度表示,对于文档di和dj,其词向量是Wi=[wi,k] (k=1,2,…,8188),Wj=[wj,k] (k=1,2,…,8188),其余弦相似度公式如式(1)所示:
Sim(di,dj)==(1)
其中Wi·Wj表示两个向量的点乘,|Wi|·|Wj|表示向量的模的乘积。余弦相似度越高,即Sim(di,dj)的值越接近1,表示两个向量更有可能属于同一类。
欧式距离公式如式(2)所示:
dis(di,dj)=|Wi-Wj|=(2)
其中Wi-Wj是向量对应项相减的结果,也是一个向量。本研究在矩阵M0的基础上分别使用上述两种距离公式进行了kNN分类验证,理论上两种kNN分类器的效果等价。
(2)朴素贝叶斯分类器
朴素贝叶斯分类器是基于条件概率的分类方法,该算法假设各特征之间相互独立。根据贝叶斯准则,可以交换条件概率的条件和结论,从而达到用先验概率和条件概率计算后验概率的目的。对于待分类文档W,其属于类型ci的后验概率如式(3)所示:
P(ci│W)=(3)
其中P(ci)是类型为ci的先验概率,P(W│ci)是类型ci发生的条件下,文档W发生的条件概率,根据这个公式计算出文档W属于各个类型的后验概率,取后验概率最大的类型为判断结果。在实际应用中,用训练集中的数据训练出每个条件概率P(W│ci)和先验概率P(ci),据此再对训练集中的数据进行分类。
(3)TF-IDF·朴素贝叶斯分类器
为了寻找更理想的分类器,笔者将TF-IDF理论与朴素贝叶斯理论结合起来构建了新的分类器,与上述纯朴素贝叶斯算法的不同之处在于,每个文档的特征向量采用TF-IDF表示,而不是词汇频数。其中,TF(Term Frequency,特征项词频)是词语在文档中的词频,即词汇在某一文档中出现的频数与该文档总词汇数的比值,TF的作用主要是抵消文本长度不一(过长或过短)带来的影响,使词汇在同等条件下进行对比。IDF(Inverse Document Frequency,逆文档频率)表示为文档总数目与该词汇出现的文档数目的比值取对数。[9]IDF的主要思想是,如果一个词汇在一个文本中出现频率很高,而在其他文本中出现频率很低,该词汇就具有较高的类别区分能力,应给予更高权重。[10]
对于文档di的第k个词汇vk,其特征值wdi,k用TF-IDF计算的公式如式(4)所示:
wdi,k=tfdi,k·log
=·log
(4)
其中wdi,k是特征项的权重,tfdi,k=是词汇vk在文本di中出现的频率,即文档di中该词汇的频数wi,k与该文档所有词汇数的比值,N=1450是总文档数,nk是包含词汇vk的文档数。由wdi,k(k=1,2,…,8188)构成新的特征向量Wdi=[Wdi,k ](k=1,2,…,8188),进而形成新的特征矩阵M1=[Wdi]=[[wdi,k]](i=1,2,…,1450;j=1,2,…,8188),在M1的基础上继续使用朴素贝叶斯分类算法即可。
3.建立能力指标体系及词袋模型
(1)建立教学设计能力指标体系
从教学设计能力的知识、态度和情感三个一级维度,以及七个二级维度(见图1)出发考察词汇列表V=[v1,v2,…,v8188]中的词汇,提炼出9个能力指标——知识储备、设计分析能力、教学能力、沟通能力、办公类软件能力、计算机语言能力、图形处理与设计、管理能力、情感态度与个人素质。9个指标的分布如图4所示。
对比图1的能力分析框架,能力指标体系对维度1(知识)和维度3(态度)分别设置了一个指标,而维度2(技能)根据其子维度衍生出了5个指标。如此设置主要有以下三点考虑:①知识维度包含学科专业知识和教学理论方法两个子维度,理想情况下每个子维度就可对应一个指标,但实际上属于“教学理论方法”的词汇偏少,因此没有必要单独设置指标,可以直接从一级维度引申出指标1“知识储备”;②分词损失了语境信息,汉语词汇本身又可能具备多种词性,这使对词汇的从属判断有很强的主观性,如态度维度下的“认知”和“行为倾向”类词汇就很难选择,相对而言,反映态度的词汇很容易甄别出来,且数量可观,因此就用指标9“情感态度与个人素质”来反映态度维度;③对于职位信息来说,职业技能是重点考察对象,因此这方面的词汇确实更加丰富,类型也比较明显,因此依次根据“专业技能”衍生出指标2“分析设计能力”、指标3“教学能力”、指标4“沟通能力”和指标5“管理能力”,根据“计算机技能”衍生出指标6“办公软件能力”、指标7“计算机语言能力”以及指标8“图形处理与设计”。
(2)建立能力指标的词袋模型
词袋模型不考虑文本的词序、语言、句法等信息,而将文本简单地看成词汇的集合,且每个词汇相互独立,这一模型在文本挖掘领域广泛使用。[11]词汇列表中有众多低频词汇是没有必要考察的,因此本研究将词汇按照词汇总频数排序后,从排名10%以内的高频词汇,即前818个词汇中选取适合的词汇构建能力指标的词袋模型,词袋模型展示如表1所示(因篇幅所限,有的指标只呈现部分词汇)。为了可视化职位能力在不同指标上的分布情况,需要建立能力指标向量,能力指标向量就是基于表1所述词袋模型,对各类文档的词汇进行统计和一定计算的结果。
4.三种指标向量与雷达图设计
(1)计算各类文档的三种能力指标向量
用雷达图呈现每类职位在各能力指标上的分布情况,需要计算每类职位在各能力指标上的特征值,9个能力指标对应9个特征值,9个特征值就构成该类职位的指标向量。基于上述能力指标的词袋模型,本研究提出了三种指标向量的计算方法,以ci类文档为例:
①基于词频数的指标向量R0
ci=[r0,1
ci,r0,2
ci,…,r0,9
ci]
基于词频数,即各指标的特征值是相应词袋中的词汇在该类文档中出现的总次数。比如对于指标1,其特征值r0,1
ci是其相应词袋模型中“专业知识”、“师范类”等词汇在ci类文档出现的总次数,同理得到r0,2
ci,…,r0,9
ci。
②基于詞汇权重的指标向量R1
ci=[r1,1
ci,r1,2
ci,…,r1,9
ci]
对基于词频数的指标向量R0
ci进行归一化就得到了基于词汇权重的指标向量R1
ci,即R1
ci=。对每个特征项而言,r1,1
ci=,r1,2
ci=,…,r1,9
ci=,其中Sum(R0
ci)是对R0
ci各项求和,因此r1,1
ci,r1,2
ci,…,r1,9
ci均是小于1的浮点数。
③基于平均水平的指标向量R2
ci=[r2,1
ci,r2,2
ci,…,r2,9
ci]
在所有的职位信息中,教师/讲师类文档有681个,占总文档数的46.97%;研发设计类有380个文档,占26.20%;职能类有389个文档,占26.83%。由于各类文档数量不一致,统计各指标下的词汇数量肯定有差异,为了消除文本数量引起的差异,可以将该类文档的各指标下的词汇数量(R0
ci)与该类文档数(nci)的比值作为新的指标向量,即R2
ci=R0
ci/nci。该比值的含义是该类文档每个指标的平均水平。
(2)两种能力分析雷达图的设计
如上所述,基于词汇权重的指标向量R1
ci,与基于平均水平的指标向量R2
ci都是在基于词频数的指标向量R0
ci的基础上建立的。能力分析雷达图只能使用R1
ci或R2
ci进行构建,而不能直接使用R0
ci进行构建,因为R0
ci没有消除各类文档数目不同带来的影响;基于R1
ci(权重)构建雷达图,反映的是同类文档9个能力指标之间的差异;基于R2
ci(平均值)构建的雷达图,可反映各能力指标下,不同类文档之间的差异。换句话说,前者反映的是同类文档的内部差异,即该类文档对各能力指标的需求差异;而后者反映的是文档之间的外部差异,即各类文档对特定能力指标的需求差异。
四、研究结果与解读
1.分类器验证结果展示与解读
分类器通过学习训练集中的数据建立相应模型,然后根据模型对测试集中的数据进行分类,理想情况下训练集的数据越大,训练的模型越准确。本研究将总数据分别按照0.01、0.02、0.03、0.04、0.05、0.06、0.07、0.08、0.09、0.1、0.2、0.3、0.4、0.5的比例随机抽取出数据组成测试集,剩下的数据组成训练集,进行测试并输出错误率。每种情况测试10次取平均值作为该情况下的错误率,各分类器的错误率如图5所示。
从图5可以看出基于欧式距离与基于余弦相似度的kNN算法效果几乎等价,这在意料之中,两者错误率均围绕在75%上下,比使用了贝叶斯原理的算法高得多,笔者认为产生这种情况的原因在于,特征项数目众多(8188),并非所有特征项都具有很好的区分度,将每个特征项的差异“累加”起来的算法,误差会比较大。若还要使用kNN算法对文本进行分类,可以考虑采取一些聚类措施,降低特征向量的维度。本研究使用分类器的目的不是改进分类算法,而是找到合适的分类模型证明对职位进行的三种分类是合理的,因此不再深入阐述算法。
再观察使用贝叶斯原理的两种分类算法,纯朴素贝叶斯分类器错误率围绕在20%左右,TF-IDF·朴素贝叶斯分类器错误率维持在30%左右,使用的TF-IDF原理的分类器比纯朴素贝叶斯分类器的错误率稍高,根据TF-IDF的原理,笔者认为原因在于:①本研究使用的每条数据的长度基本相同,所以使用TF的意义不大;②尽管按照职位名称分成了三类,但其工作极可能是围绕相同的对象展开不同方面的工作,所以职位信息中呈现出来的词汇有一定的相似度,因此IDF(逆文档频率)的作用发挥有限,所以错误率反而比纯朴素贝叶斯分类器的稍高。但整体来说,这两个分类器错误率比较低且稳定,说明分类可取,每类职位具有一定特征,具有深度挖掘的价值。
从实际的角度出发,教学设计工作围绕“教学”这个核心工作展开,也离不开技术支持以及应运而生的管理工作;从理论的角度出发,IBSTPI国际教学设计标准最新版(2013年)将教学设计领域细化为教学设计专家、分析师或评估员、教学管理者以及教育技术专家四类人员参与,将该标准与本研究进行对比,可以发现教师/讲师类可以对应教学设计专家,研发设计类对应教育技术专家,职能类对应教学管理者,而分析师或评论员的能力在三种职位中均有不同程度的体现;[12]再结合分类器的验证结果,可见将与教学设计相关的职位划分为教师/讲师类、研发设计类以及职能类是合理的,这启示我们可以从这三个角度出发,理解教学设计能力所包含的能力属性。
2.能力分析雷达图与能力指标解读
(1)基于R1
ci的能力分析雷达图
对每类职位,用R1
ci(基于权重的指标向量)构建的指标矩阵结果如表2所示:
用表2生成的能力分析雷达图如图6所示。
从图6可以看出,在9个能力指标中,教师/讲师类岗位对“情感态度和个人素质”和“教学能力”的需求很突出,其次是“管理能力”、“分析设计能力”与“沟通能力”,对计算机能力的要求不高;研发设计类对“分析设计”能力的需求最突出,其次是“计算机语言能力”和“管理能力”;职能类岗位对“管理能力”的需求最为突出,其次是“分析设计能力”以及“教学能力”。
整体来看,三类岗位的“知识储备”与计算机类的能力并没有十分突出,而实际上这三种指标是非常重要的能力,笔者认为出现这种情况的原因是:①岗位招聘类的信息重点在于实用的技能上,“知识储备”的词汇不容易反映出来,所以整体上数量偏小,但这并不能说明知识储备不重要,毕竟“实用的技能”是建立在“知识储备”的基础上,因此该词袋模型有改进的空间,可以考虑建立“知识储备”与实用技能间的关联性,进而提高“知识储备”類词汇的表现力;②计算机类能力的词袋规模相对较小,比如“办公软件能力”的词袋只有“ppt、办公软件、office、word、excel”这5个词汇,实际上每个词汇出现的次数还是比较多的,但累加起来还是比不过词袋中词汇本身就多的能力指标,如指标5“管理能力”和指标9“情感态度与个人素质”,但这个影响在基于R2
ci的能力分析雷达图中已经得到改善,详见下述分析。
(2)基于R2
ci的能力分析雷达图
对每类职位,用R2
ci(基于平均水平的指标向量)构建的指标矩阵结果如表3所示。
用表3生成的能力分析雷达图如图7所示。
从图7可以看出,在9个能力指标中,教师/讲师类排第一名的有“知识储备”、“教学能力”、“沟通能力”、“情感态度与个人素质”,这符合对教师的一般认知;研发设计类排第一名的有“设计分析能力”、“办公软件能力”、“计算机语言能力”以及“图形处理与设计能力”,其中“计算机语言能力”主要指的是编程能力,“图形处理与设计”属于界面设计领域,这反映出与教育软件、教育应用程序(APP)、教育动画与课件等教学产品息息相关;职能类岗位的“管理能力”位列第一,可以认为教育产品的开发、教学工作的展开离不开优秀的管理能力,IBSTPI新标准把管理能力单独设为一个领域,这意味着管理能力在教学设计的发展中日趋重要。[12]总之,该雷达图的呈现结果是很理想的,正好反映出了各类职位能力需求的特点。
IBSTPI教学设计能力新标准有五个能力领域——“专业基础领域”、“计划与分析领域”、“设计与开发领域”、“评价与实施领域”以及“管理领域”,并在每个领域中将能力标准又分为教学设计时必须掌握的基本能力、高水平或专家型的高级能力,以及作为设计或教学项目所需掌握的管理能力,这三级能力有不同程度的交叉、渗透,这与上述研究结果有异曲同工之妙。[12]本研究提出的9个指标虽不及IBSTPI教学设计能力新标准(包含5大领域、22项标准及105个子条目)的内容丰富,但却是实际应用中有了迫切需求的具体能力,不仅不同程度地反映了各能力领域的要求,比起庞大的新标准体系,也具有灵活性、实用性和指导性。[12]整体而言,这9个能力指标反映出当前教学设计实践领域的复杂性,一个人要全面掌握这些能力似乎比较勉强,但可据此准确定位自己的发展方向,对相关能力进行专项培养。
五、总结与展望
本研究首先依据相关研究提出教学设计能力分析框架,再对数千条岗位信息进行分类,并在用贝叶斯分类器证明分类合理的情况下,建立能力指标体系和词袋模型,深度挖掘各类岗位的能力需求,最终以雷达图的形式进行可视化呈现与解读,为教学设计能力的研究提供一定新思路,也对相关专业的人才培养有一定的启发:①提供灵活的课程体系,以满足教学设计能力需求的模块组合。具体而言,既包括教学设计、教育心理学等培养教学能力的基础专业课程,也包括将相关的信息技术运用到教学或教学管理的应用型课程,以及与教育管理相关的课程。这些课程又可以划分为必修课程和选修课程,学生在学习基础课程、培养基本的教学素质的基础上,可以根据自己的兴趣和特长选择研发技术类或管理类的课程,进一步培养专业素质,提高竞争力。②丰富前沿领域的教学实践,培养实战能力。可与中小学或企业合作,建立创客、STEM、人工智能等前沿领域教学项目,让学生参与教案/学案设计、授课、教学产品研发、项目管理与运营等工作,有针对性地培养各方面的能力。
另外,本研究也有继续改进的空间:①分词技术损失了语法、语境等信息,使很多词汇变得没有意义,后续研究可以关注如何减弱这种损失;②关于能力指标与词袋模型,可以挖掘不同能力指标之间的关联程度,如上述“知识储备”与实用技能之间的关联性,进而构建更加合理的能力指标-词袋模型。
参考文献:
[1]杜华.国际教学设计研究三十年[J].开放教育研究,2013(5):79-86.
[2]Kemp Jerrold E.The instructional design process.New York,Haper and Row,1985.
[3]Patricia L.Smith,Tillman J.Ragan.Instructional Design.3rd Edition, Hoboken,John Wiley & Sons,2004.
[4]吴晓义,杜晓颖.能力概念的多维透视[J].吉林工程技术师范学院学报,2006(4):1-5.
[5]刘美凤,康翠,董丽丽.教学设计研究:学科的视角[M].北京:北京师范大学出版社,2018:13,12.
[6]Mashechkin I. V. ,Petrovskiy M. I. ,Popov D. S. ,et al.Applying text mining methods for data loss prevention[J].Programming and Computer Software,2015, 41(1):23-30.
[7]李梦杰,刘建国,郭强,李仁德,汤晓雷.基于文本挖掘的互联网教育课程主题发现与聚类研究[J].上海理工大学学报,2018(3):259-266.
[8]Harrington P.著,李锐等译.机器学习实战[M].北京:人民邮电出版社,2013.6:15.
[9]葉雪梅,毛雪岷,夏锦春,王波.文本分类TF-IDF算法的改进研究[J].计算机工程与应用,2019(2):104-109,161.
[10]陈朔鹰,金镇晟.基于改进的TF-IDF算法的微博话题检测[J].科技导报,2016(2):282-286.
[11]袁桂霞,周先春.基于多媒体信息检索的有监督词袋模型[J].计算机工程与设计,2018(9):2873-2878.
[12]方向,盛群力.IBSTPI国际教学设计能力新标准述要——教学设计师专业化发展的一种图景[J].远程教育杂志,2015(3):82-87.
(编辑:王天鹏)
