基于平行语料和翻译概率的多语种词对齐方法
2019-12-30杨飞扬赵亚慧崔荣一易志伟
杨飞扬,赵亚慧,崔荣一,易志伟
(延边大学 计算机科学与技术学院 智能信息处理研究室,吉林 延吉 133002)
0 引言
统计机器翻译的思想是从一个包含大量句子对齐的双语平行语料中学习翻译规则,实现从一种自然语言翻译为另一种自然语言[1-2],词对齐方法主要有: 基于统计方法、词典的方法、语言特征的词对齐方法等。找到单词的翻译是建立对齐关系的前提,而建立词对齐关系是任何统计机器翻译模型的基本步骤之一[3]。目前机器翻译的性能很大程度上依赖于训练语料的规模和质量,训练语料规模越大、质量越好,则有效的翻译知识越多,涵盖的语言现象也越充分。然而在完成特定领域翻译任务时,机器翻译的性能往往偏低[4],原因在于通用领域翻译系统无法针对特定领域的翻译知识、句子表达方式以及语言风格等做出调整。因此针对特定领域以及低资源语言的翻译,需要一种在没有完整数据库的情况下,能够高效地做到词的形式对应,做到有针对性的翻译。IBM条件概率模型[5]采用句子级的划分,用分数计数克服长短句带来的误差;用枚举的方法降低对应停用词的数学期望,克服语料预处理的误差,但在实验中发现,预处理的权重是影响实验结果的主要原因。在IBM的对齐模型中,弥补一对多情况的方法是对实验结果进行对称化,从两个方向进行EM算法[6](expectation maximization)的训练,但进行EM算法的训练需要大规模的语料才能使结果准确。过去的几年里,人们尝试使用跨语言主题模型来获得翻译语料[7-8],构建主题作为双语匹配的分布,其中匹配先验可能来自不同的初始证据,如机器可读字典。
上述方法的主要缺点是需要引入了外部知识[9],本文在以往的研究基础上,针对特定语料进行改进,不依赖字典及外部知识,不依赖大规模语料进行训练,假设存在翻译关系的词之间具有明显的共现关系,且在服从Zipf定律的低频词区域点互信息可以有效地被翻译概率取代,通过对候选翻译结果进行优化,以更高的效率确定特定的双语对齐单词,并通过实验验证了本方法的有效性。
1 相关工作
1.1 点互信息
点互信息(pointwise mutual information,PMI)度量两个随机变量取特定值时的相互关联程度[10-11]。在本文讨论的单词翻译问题中,汉语单词tS和对应的英文单词tT之间的关联强度可以用点互信息公式计算,如式(1)所示。
(1)
其中,P(tS,tT)是语料库中源语言单词tS及目标语言单词tT共现的概率(汉译英情况下,tS是汉语单词,tT是英语单词);P(tS)和P(tT)分别是语料库中源语言单词tS及目标语言单词tT各自出现的概率。利用联合概率的性质,式(1)可以写成:
(2)
由此可见,PMI度量了当确定源语言单词tS时,目标语言单词tT出现的概率相比该目标语言单词先验概率的变化情况。这里存在3种可能的情况:
(1) 如果源语言单词tS与目标语言单词tT统计独立,则tS的出现不会改变tT出现的概率,即:P(tT|tS)=P(tT),导致PMI(tS,tT)=0,从共现意义上这两个词之间没有关联性,不可能存在词对齐关系。
(2) 当源语言单词tS出现时目标语言单词tT出现的概率减小,小于其先验概率,则PMI(tS,tT)<0,二者之间存在相互抑制关系,但不存在对齐关系[12]。
(3) 只有当源语言单词tS出现时目标语言单词tT出现的概率增加,大于其先验概率,则PMI(tS,tT)>0,二者之间才可能存在对齐关系。因此当给定源语言单词tS时可通过考察与其点互信息大于零且超过一定阈值的若干目标语言单词作为候选翻译词。
1.2 Zipf定律
Zipf定律表明在英语单词中,只有极少数的词被经常使用,而绝大多数词很少被使用。实际上,包括汉语、朝鲜语在内的许多国家的语言都有这种特点[13]。在一个语料库中,若将词语出现的频率(即词频)记作Pr,将该词的词频排位记为r,则Zipf定律可表示为式(3):
C=Pr·r
(3)
其中,C为一个大于零的常数。式(3)表明某个词汇出现的频率和频级的乘积是常数。这条定律说明,人们一般偏好比较常用的词汇,而不是生僻的词汇。若将Pr和r的关系表示在双对数坐标系中,所绘制出的曲线几乎为一条直线,并且斜率近似为-1。为了准确求解这一斜率,Zipf定律还可以推广为:
C=Pr·ra
(4)
其中,a为待定常数,r为频级:r=1,2,…,n。对式(4)两边取对数后整理得式(5):
logPr=logC-alogr
(5)
这条定律说明,人们一般偏好比较常用的词汇而不是生僻的词汇。以英文为例,词频分布具有“长尾”特征,如图1所示。本文将利用这一特性提出合理假设,简化式(2)定义的单词间关联强度的计算方法。
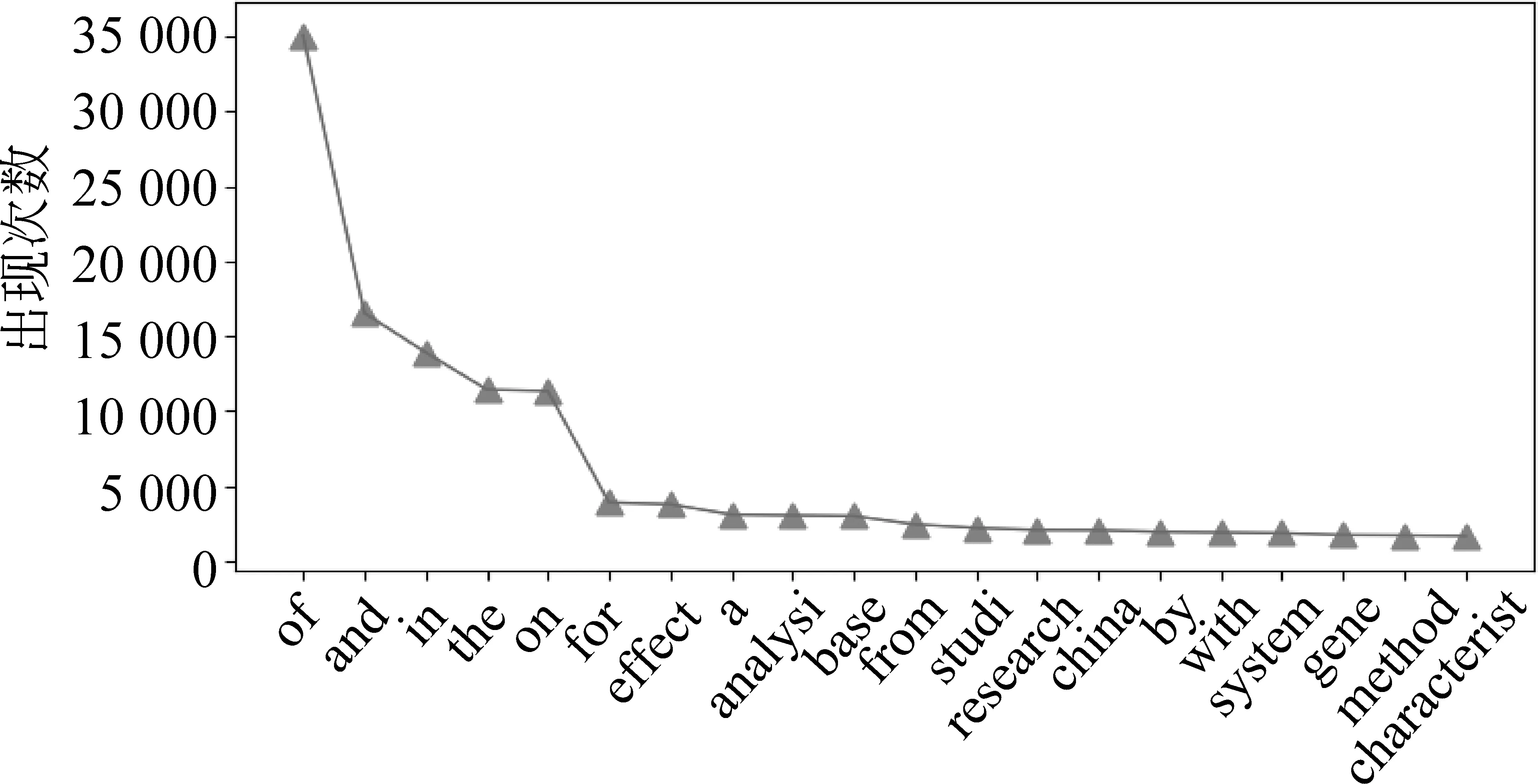
图1 文本词汇频次分布图
2 基于翻译概率的词对齐算法
2.1 点互信息度量法可简化为翻译概率
Zipf定律表示在文档语料中极少数词汇高频出现,大多数词汇出现的频率很低。如果我们考虑普通频级区域单词对齐问题,源语言与目标语言单词之间相关程度的度量可由式(3)改进为更高效的形式。从单词对齐的目的和Zipf定律刻画的普通频级区域词频特性来看本文做如下假设是合理的。
假设1平行语料中不存在高频词;
假设2所考虑的目标语言单词近似服从均匀分布。
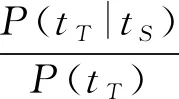
(6)
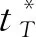
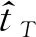
(7)

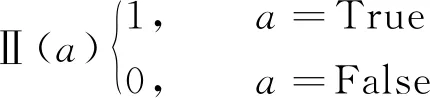
(8)
翻译概率的算法如下:

算法1 翻译概率
利用算法1,通过设定概率阈值可对给定源语言单词获得若干候选目标单词,这些单词具有与源语言单词对齐的可能性。对特定源语言单词tS可按条件概率P(tT|tS)递减方式给出候选目标语言单词tT1,tT2,…,tTm。为保证翻译关系的可信性,翻译概率须超过一定的阈值,即满足:
P(tT1|tS)≥P(tT2|tS)≥…≥P(tTm|tS)≥PTS
(9)
其中,PTS称为翻译概率阈值,是为保证词对齐可信度的翻译概率的下限值,低于PTS的翻译词可视作当前语料无法匹配到真正翻译词的情况,不纳入计算。在满足式(9)的m个目标词中选取前k个作为单词tS的翻译候选单词,其中PTS的取值根据源语言语料质量与规模实验确定。
源语言语料中出现次数过低的单词,因为概率估计缺乏数据,不能通过式(7)和算法1有效地计算其翻译概率。但可以通过算法1计算其翻译概率的源语言单词tS的概率P(tS),判断其是否也超过一定的阈值,如式(10)所示。
P(tS)≥PS
(10)
其中,PS称为有效概率阈值,是可以通过平行语料技术进行词对齐处理的源语言单词在语料中应出现的最低概率。在进行单词频级计数时由高到低排序,根据语料规模视为低频词的单词,不纳入计算,满足式(10)的源语言单词tS称为词对齐有效源语言单词。
2.2 词对齐优化处理
通过研究扩大高频词的范围发现,在利用上述条件概率方法进行跨语言词对齐处理时,通过以下措施可进一步提高对齐效果。
(1) 去除预处理过程中出现的病态分词结果;
(2) 去除当前停用词表中未登录的停用词;
(3) 对一词多义(一个源语言单词对应于相同语义的多个目标语言单词)和组合词(一个源语言单词对应于多个目标语言单词的组合)情况,进行如下处理: 利用式(9)、式(10)调整阈值,对组合词的情况进行对称化处理,使其重组成源语言对应翻译词组。
该方法弥补了语料针对性、分词细粒度和语料规模不足带来的误差,从而提升了词对齐的准确性。在分类一词多义与组合词时能够完善特定语料的单词义项。具体算法如下:

算法2 翻译概率优化算法
3 实验结果及分析
3.1 平行语料预处理
本文实验语料为延边州科技信息服务中心数据库中的30 827条中、英、朝语科技类平行语料,满足形式对应。语料预处理步骤如下:
(1) 使用jieba分词工具对句子进行分词;
(2) 对多语种互译句子进行按行对齐,用|||符号隔开;
(3) 去除中、英、朝文本中的标点符号、数字、特殊符号、多余的空格,统一英文大小写等;
(4) 对英语部分进行词干还原,还原动词原型,保留形容词和副词的词根;
(5) 去除中、英、朝文本中的高频停用词。
3.2 中—英—朝平行语料词对齐实验方案
因为语料样本有限,所以在平行语料中选择出现概率最高的100个词对齐有效源语言单词,通过算法1计算,列出与源语言单词相关度最大的5个目标语言候选词,并按翻译概率从高到低排列[满足式(9)];在此基础上用优化算法进行优化处理。翻译的准确率均达到94%以上,其中造成误差的原因有预处理分词的病态分词、特定文本的停用词无法去除、语料规模造成翻译的局限性等。表1~表4是部分实验结果展示。

表1 汉译英翻译概率(部分结果)
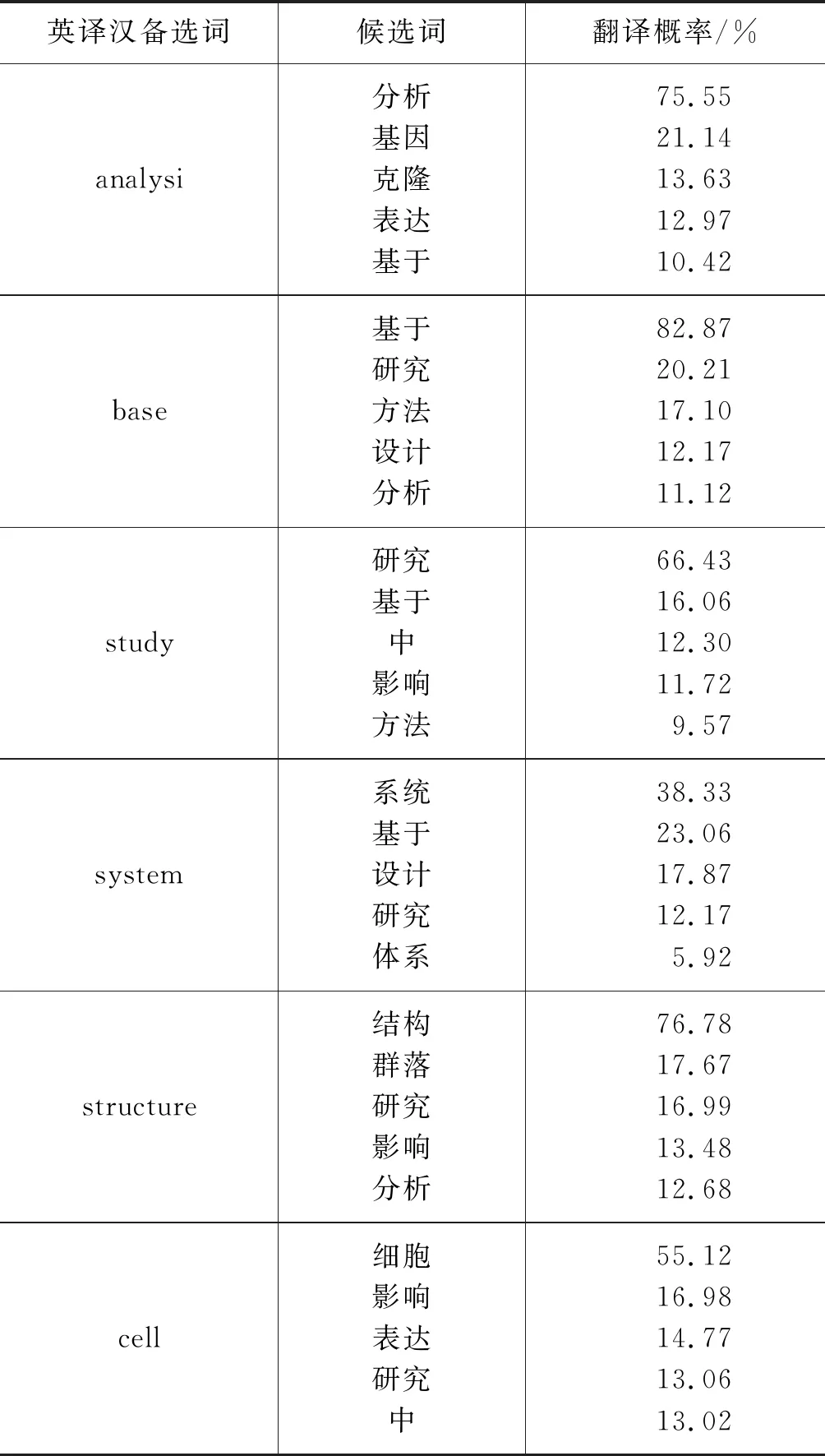
表2 英译汉翻译概率(部分结果)
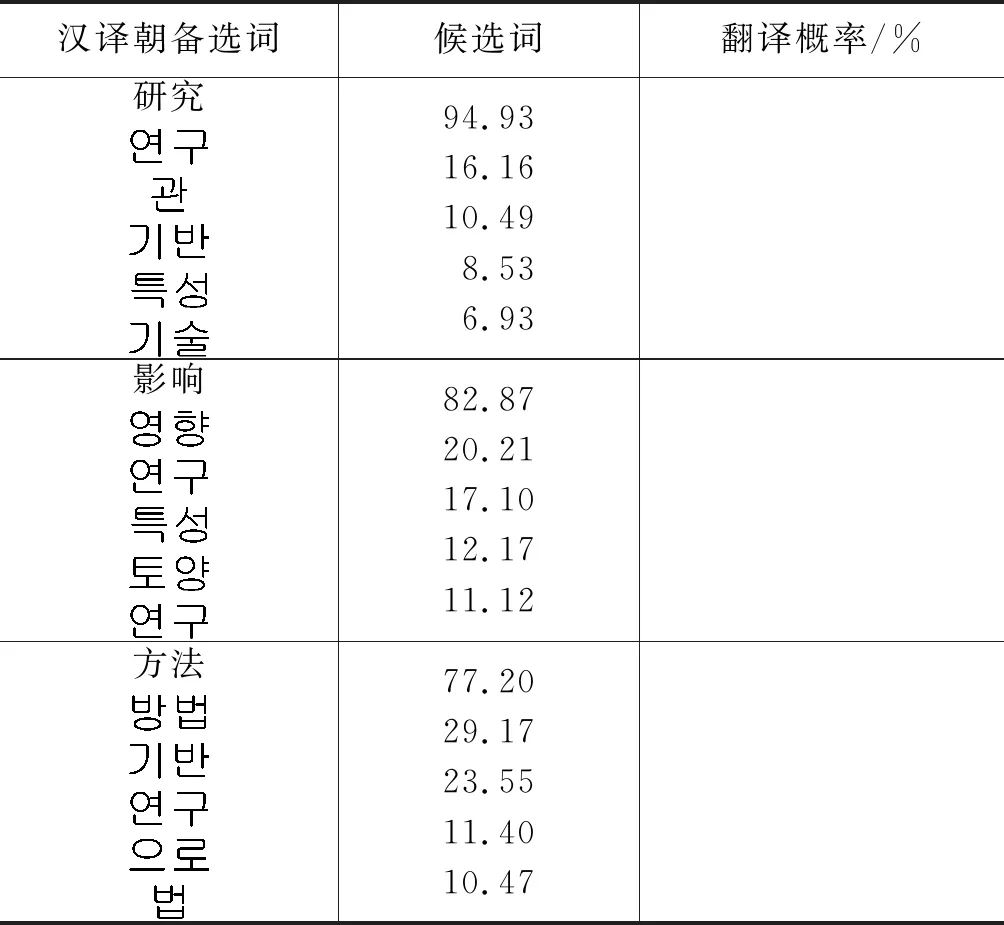
表3 汉译朝翻译概率(部分结果)

续表
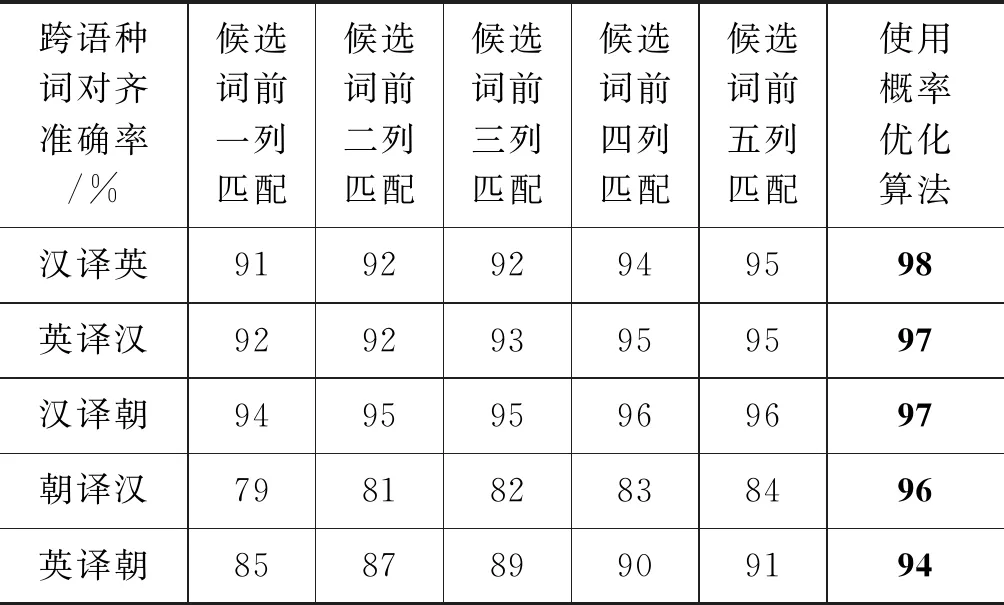
表4 双向翻译时前100高频词准确率对比
3.3 源语言单词数量与语料规模对翻译准确率的影响
(1) 保持语料规模不变,将待处理源语言单词范围扩展,观察算法的有效性。
(2) 保持待处理源语言单词范围不变,改变语料规模,观察准确率的变化程度。
实验分别控制语料不变高频词范围扩展,观察算法的有效性及可行域局限性;控制高频词范围不变,改变语料规模,观察准确率的变化程度。通过以上实验过程,分析影响准确率的权重高低、预测算法可行范围,配合翻译概率优化算法并统计,得出以下结论。
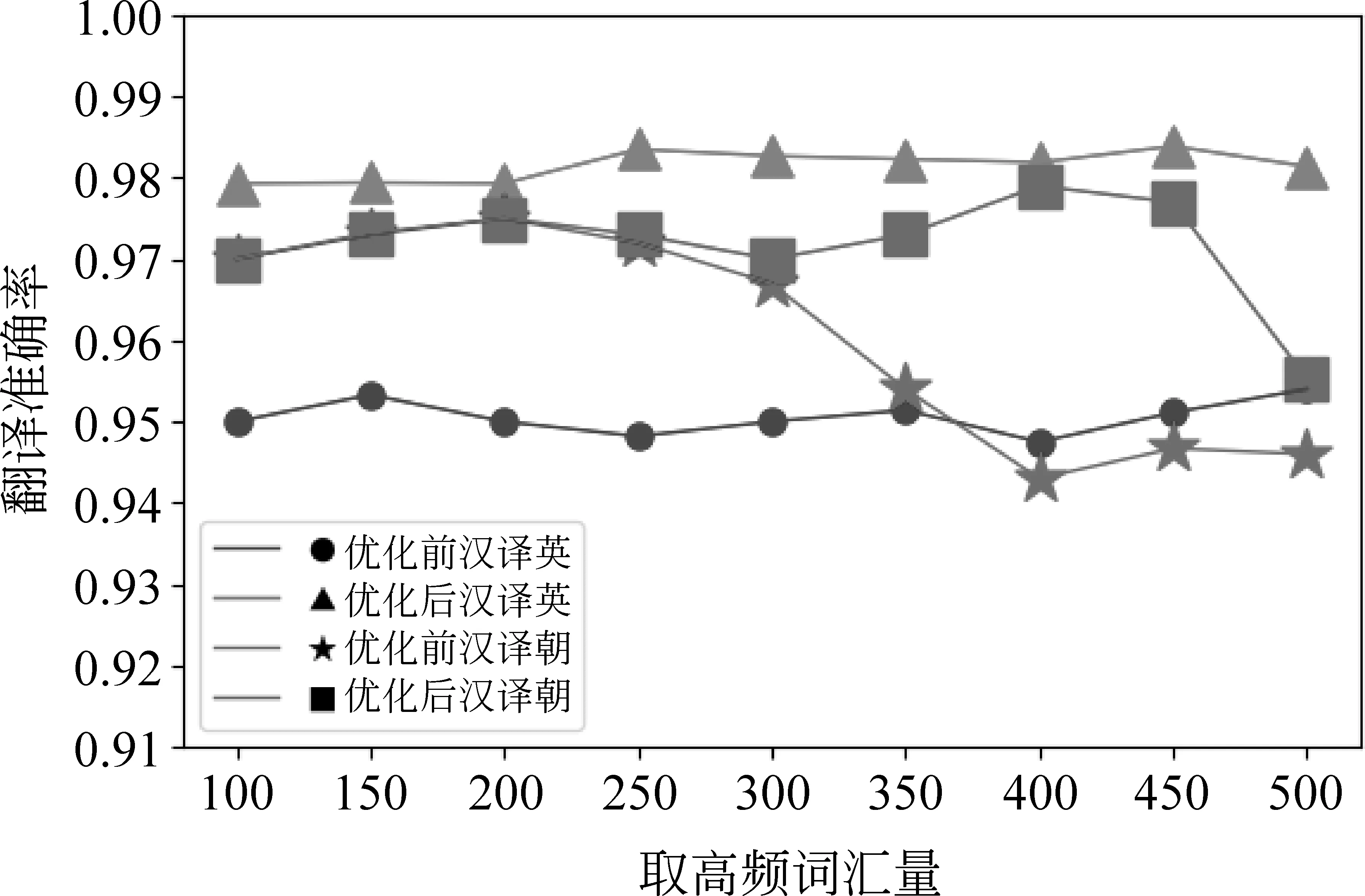
图2 汉译英、汉译朝控制语料不变的翻译准确率
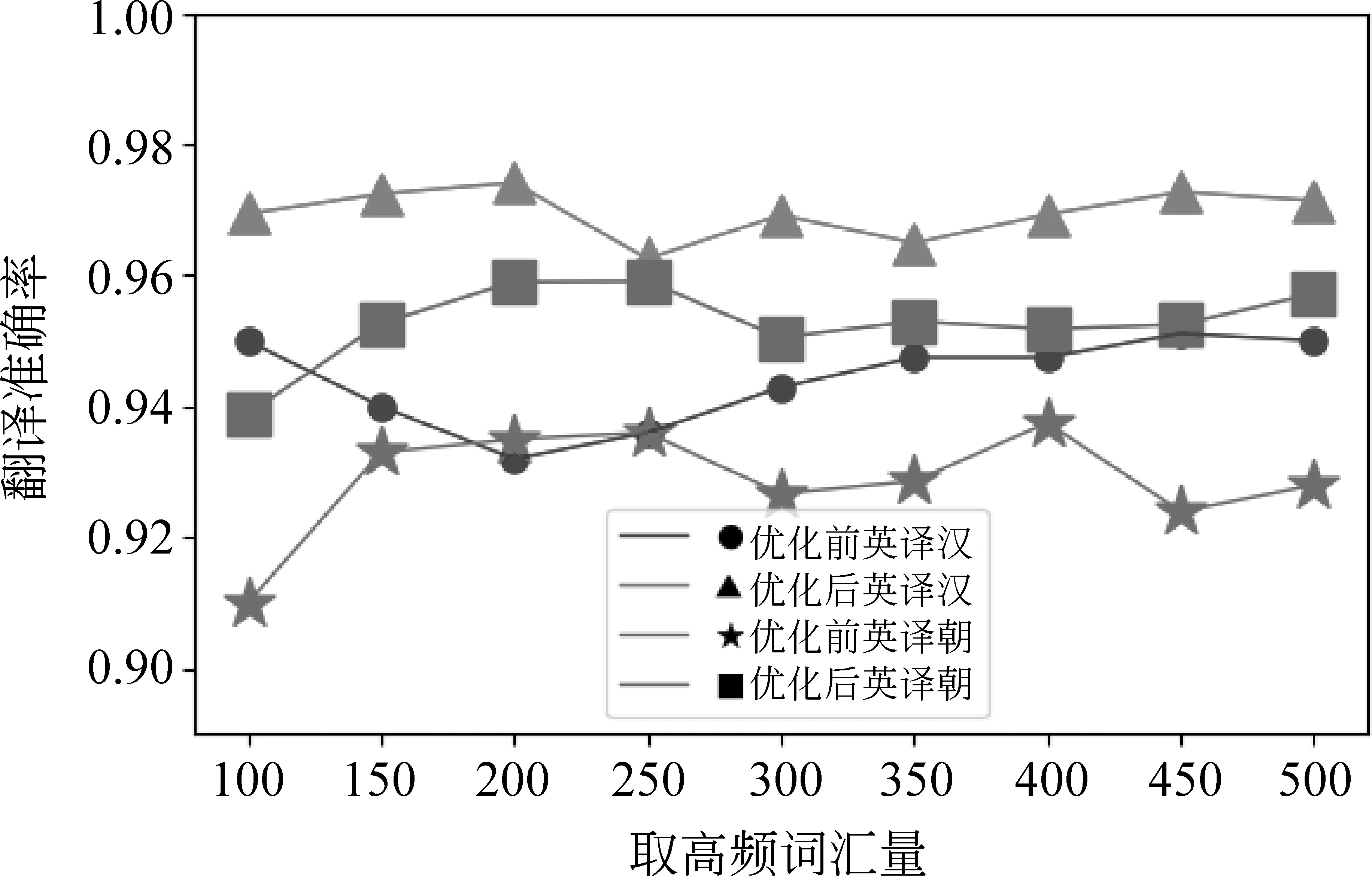
图3 英译汉、英译朝控制语料不变的翻译准确率
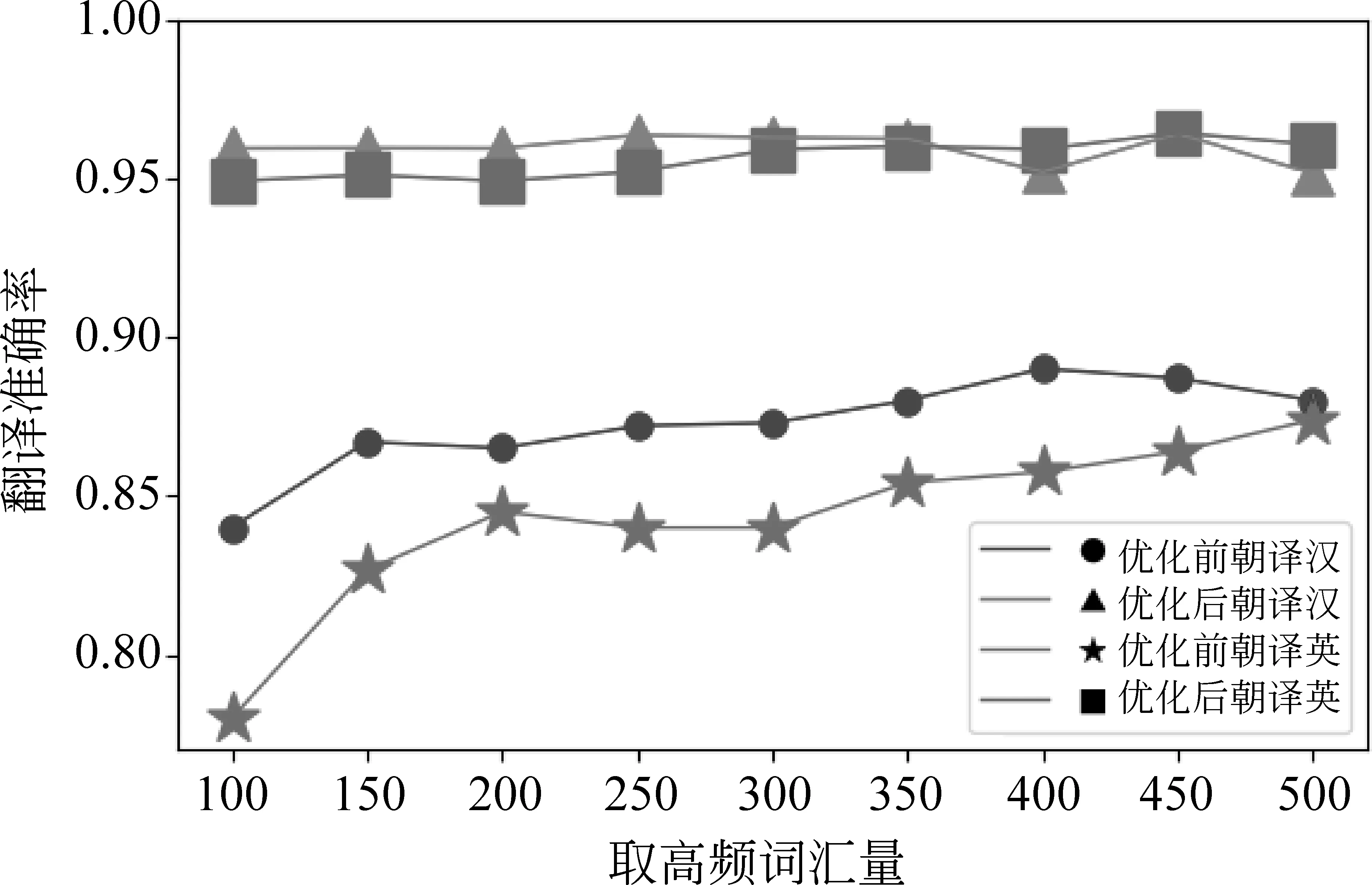
图4 朝译汉、朝译英控制语料规模不变的翻译准确率
由图2~图4可知,保持语料不变,通过改变源语言普通高频单词取值范围,在有效范围内,对汉、英、朝进行翻译时准确率在94%以上,使用翻译概率优化算法对朝鲜语进行翻译,准确率与未优化前对比提升了15%。因为朝鲜语的分词效果不如英语和汉语好,停用词表的构造不如英语和汉语成熟,所以优化后提升效果最为明显。
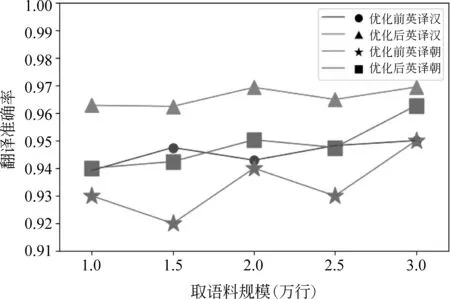
图5 英译汉、英译朝控制高频词量不变的翻译准确率

图6 汉译英、汉译朝控制高频词量不变的翻译准确率
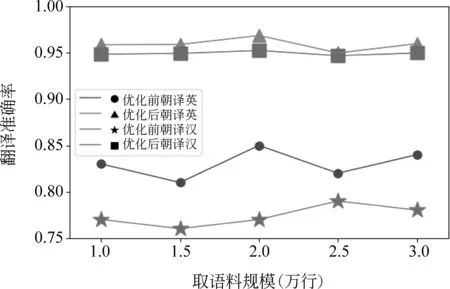
图7 朝译英、朝译汉控制高频词量不变的翻译准确率
由图5~图7可知,保持源语言普通高频单词取值范围不变,改变源语言语料规模范围,在有效范围内双语互译的准确率均处于折线形上升的趋势。实验结果也印证了语料规模越大,翻译的准确率越高这一特点,汉译英优化效果前后对比提升了3%左右。英译汉优化效果前后对比提升了2%左右。整体上汉译英、朝的准确率高于其他情况,造成此情况的原因可能是因为汉字的信息熵本身较其他语言高,也可能是原文作者是汉语的母语者,汉语翻译成其他语言的准确率最高,并且其他语言未优化时,很多正确翻译词对应在翻译概率第三列、第四列,而汉译英、朝对应在非最高翻译概率的词却很少,翻译会产生噪声,在双向翻译信源经过有损信道时,降低了准确率。
3.4 翻译概率优化算法针对一对多情况的区分
在使用翻译概率优化算法时针对一对多的情况,分为源语言对应多个目标语言正确词、源语言单词由多个目标语言词组成两种情况,示例如表5、表6所示。

表5 源语言对应多个正确词
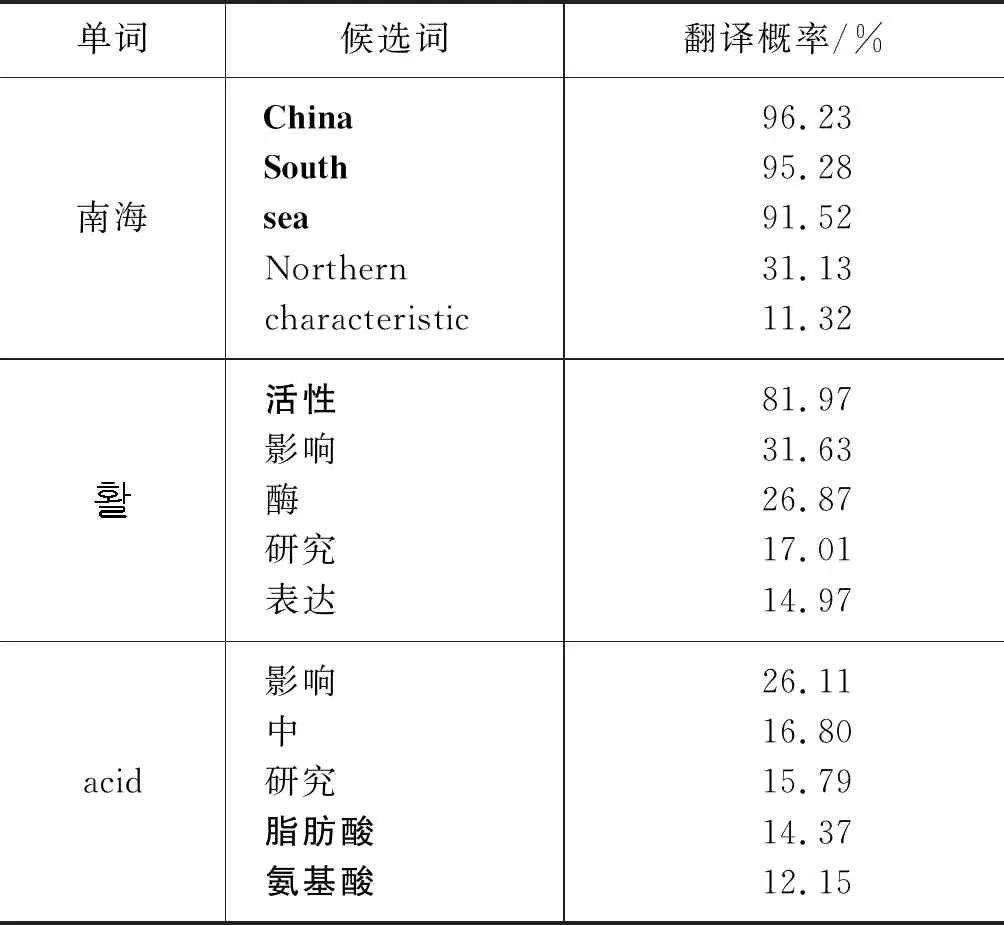
表6 一个词由多个词组成
4 结论及下一步工作
本文研究了一种基于共现关联强度的单词跨语言映射方法,以汉、英、朝语平行语料为素材,以简化的点互信息准则即翻译概率为核心算法,以实践中总结归纳的翻译概率优化算法为后处理方法,可以在一个小规模语料中做到词对齐。从实验结果可看出,三种语言互译优化后都有较高的准确率,在实验中发现了影响准确率的3个因素,按重要程度由高到低依次是:
(1) 分词预处理的细粒度划分(造成病态分词是导致误差的一个主要原因);
(2) 语料规模的大小;
(3) 选用的高频词数量。
语料规模越大,翻译的准确率会越高,对应的准确翻译词也会越多,由于语料种类的不同,语料规模的不同会导致该阈值不具有普遍性,如需计算,应对语料进行分类,不同类别的语料有不同的高频词翻译可行域,即不同的有效性阈值。
该方法对语料中部分法语、西班牙语词也能够做到词对应,下一步工作将对其他语种进行实验,以验证准确性并加以推广。
