基于深度学习哈希算法的快速图像检索研究∗
2019-12-27李泗兰
李泗兰 郭 雅
(广东创新科技职业学院信息工程学院 东莞 523960)
1 引言
为了降低图像检索的空间复杂度与时间复杂度,研究者们在过去十几年提出了很多高效的检索技术,最成功的方法包括基于树结构的图像检索方法[1]、基于哈希的图像检索方法[2],其中,经典的哈希方法是局部敏感哈希方法(Locality Sensitive Hashing,LSH)[3]和基于向量量化的图像检索方法[4]。相比基于树结构的图像检索方法和基于向量量化的图像检索方法,哈希技术将图像的高维特征保持相似性的映射为紧致的二进制哈希码。由于二进制哈希码在汉明距离计算上的高效性和存储空间上的优势[5],哈希码在大规模相似图像检索中非常高效。
近几年研究者们对基于CNN的深度哈希算法提出了多种模型[6~8],虽然检索的效率在不断提高,但是图像语义和哈希码之间的差异依然存在,而且深度哈希在多标签图像检索中的应用还不够成熟,仍需要大量的研究。本文中在多篇文献的基础上提出了利用成多标签作为监督信息进行学习的哈希方法。该哈希算法是针对多标签图像研究结合深度学习与哈希码生成的图像哈希表示方法以及学习算法,形成针对多标签图像的深度监督哈希。该方法的基本思想包括:
1)将图像的标签设定成标签个数的一组编码,根据任意成对图像之间的标签向量的汉明距离得到成对标签,得到标签矩阵,简化了图像的多个标签,更方便作为监督信息;
2)设计合适的损失函数,本文中的损失函数包含了哈希码与图像语义之间的差异、图像特征量化为哈希码时的量化误差以及所有图像哈希码与平衡值的差值;
3)本文的框架是在特征提取模块后增加了含有sigmoid函数的隐藏层,以使得网络输出的特征值更接近于0或1。
2 深度学习
在图像检索领域中存在很多基于成对标签的监督哈希算法,如 KSH[9]、LSH[10]及 FastH[11]方法,这些方法都是基于手工设计特征的方法,没有取得很好的效果。而后提出基于CNN的深度哈希算法,通过对相似度矩阵(矩阵中的每个元素指示对应的两个样本是否相似)进行分解,得到样本的二值编码,利用CNN和交叉熵损失对得到的二值编码进行多标签预测,相比之前的方法性能有显著提升。之后又相继出现深度神经网络(Deep Neural Network Hashing,DNNH)[12]、DPSH[13]等提出端到端方法,使得学习到的图像可以反作用于二值编码的更新,更好地发挥出深度学习的能力。这个部分会讲述本文的模型架构,这个模型是特征学习和哈希码学习集合在一个端到端的框架里面。
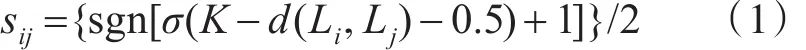
其中,d(Li,Lj)表示的是两个向量的汉明距离(两个向量对应位不同的数量),σ(g)=1/(1+exp(-z))表示的是sigmoid函数,z表示任意实值,sigmoid函数的范围为{0,1},其输出可以表示两张图片相似的概率,然后利用sign函数将概率转换为0或1,sij若为 1,则第 i,j张图片相似,若为 0,则不相似,所有图片的标签矩阵为S={sij}。
图1显示的是针对本文方法所构建的端到端深度学习框架,该框架由两部分组成,这两部分分别是用于获取图像特征的卷积神经网络模块和用于框架学习的损失函数模块。
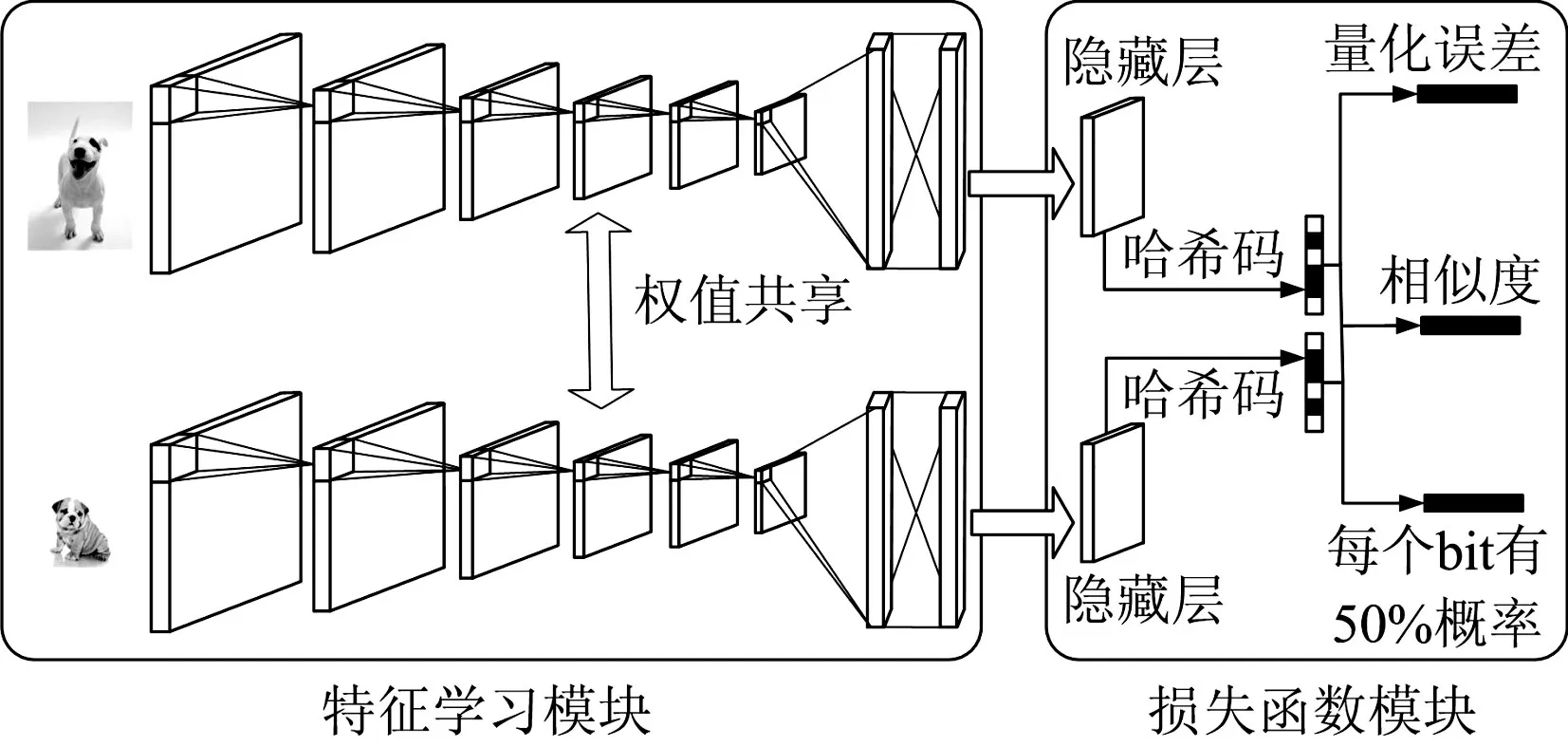
图1 深度学习框架
3 特征学习模块
在卷积神经网络领域存在很多通用的框架,如AlexNet[14]和 VGG[15],这些架构集成了深度学习和哈希函数的创建,使用更加方便。本文基于AlexNet对特征学习模块进行介绍。
这个模块由上下两个卷积神经网络组成,这个两个卷积神经网络有相同的结构并且权值共享。每个网络如AlexNet描述一致,前五层(F1-5)是卷积层,后接两层(F6-7)全连接层。卷积层是用卷积核与前一层的局部输出进行卷积,全连接层将学到的“分布式特征表示”映射到样本标记空间,在整个卷积神经网络中起到分类器的作用。整个模块的前两层及后三层都连接最大池化,取前一层局部输出的最大值作为输出,对图片的高维特征进行降维并保留其重要特征。每个卷积层和全连接层都包含有 ReLu(Rectified Linear Units)激活函数[16],使得训练的速度更快。
令θ表示第七层之前网络的所有权重,将两个图像xi,xj分别输入上下两个卷积层,第七层输出D维的特征向量个向量会同时输入隐藏层,进行成对标签的哈希函数的预测。
4 基于哈希码的损失函数模块
如图1所示,损失函数是由两部分组成:成对损失函数和平衡哈希码损失函数。设计合适的损失函数,然后利用随机梯度下降算法(stochastic gradient descent,SGD)[17]进行网络权重优化。成对损失函数是利用输出两个图像的哈希码的汉明距离判断两个图像的标签是1或者0。第二类损失是针对生成有效哈希码所设定的损失函数,通过优化隐藏层和0.5之间的差值之和,让隐藏层的激活函数的输出更接近于0或1,生成更为有效的哈希码。
4.1 成对损失函数
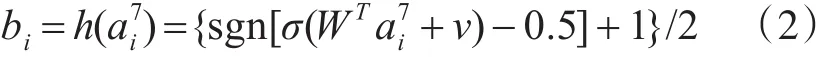
其中,WT表示的是第七层全连接层到隐藏层之间的权重,v表示偏差。所有图片的哈希码转换成二进制矩阵,本文根据LFH定义成对标签矩阵S的可能性为
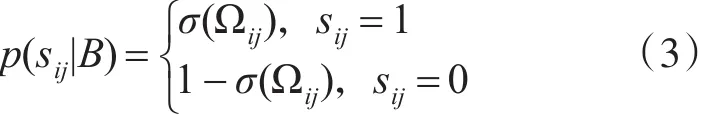
针对成对标签矩阵S,成对损失函数采用交叉熵损失函数[18]进行优化:
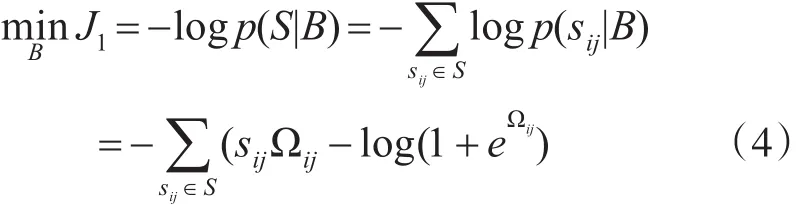
从以上公式可以发现当两张图的相似度越高,哈希码汉明距离越小,根据最大似然估计,可以得到此时s=1的概率也就越大,J1也就越小。但是因为离散优化是NP难问题,所以根据LFH方法将
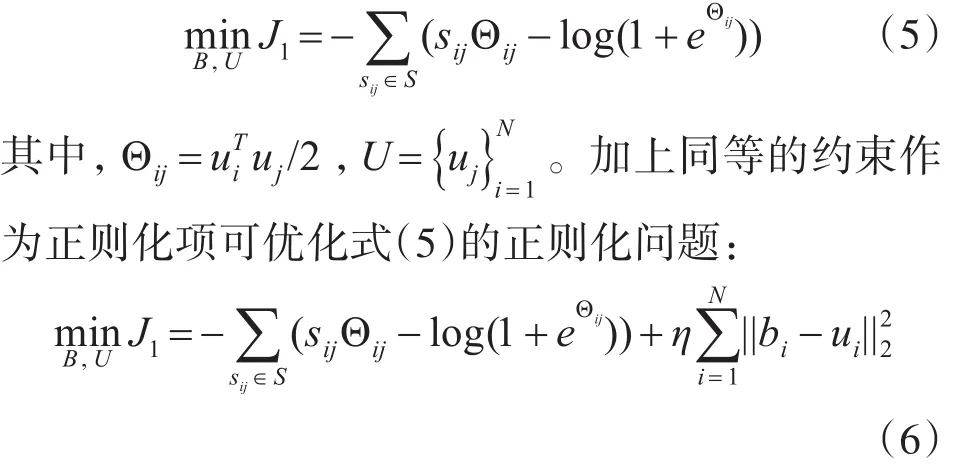
4.2 平衡哈希码损失函数
除去根据语义相似度优化图像哈希码的相似度,还需要针对生成的哈希码进行优化。哈希码的优化包括两部分:特征值转换为哈希码存在的量化误差和针对哈希码平衡的优化。第一部分从特征值到哈希码的量化误差是让特征值在输入sign函数之前尽可能地接近于0或1;第二部分是保持哈希码的平衡性。
哈希码是图像特征通过隐藏层之后得到的以0或1组成的二进制编码,但图像特征的特征值取值范围很大,所以优化相应的损失函数让图像特征通过隐藏层的激活函数后输出值aiH能够更加接近于0或1,减少量化误差。针对第一部分,损失函数设定为与0.5之间的平方差之和,即
如何保证哈希码的平衡性,最好的情况是训练样本的所有哈希码字节50%为0,50%为1,但是因为本文采用SGD进行优化,SGD是将所有训练数据随机分为多个batch,让每个batch保持哈希码的平衡很难实现。所以针对这种情况设计损失函数限制每个batch哈希码的不平衡。给定一张图片Ii,其是在{0,1}上的离散概率分布。我们希望随机生成0和1的概率是相等的,所以设定第二部分的损失函数为mean(·)表示的是计算向量中所有元素的平均值。这种方法有助于针对一个学习对象生成相同数量的0和1,同时也让两个有相同0和1数量的哈希码之间最小汉明距离变成了2,使得哈希码更加分离。
最后将两个限制条件结合起来,通过优化(7)让aiH的每个bit有50%的概率成为0或者1:
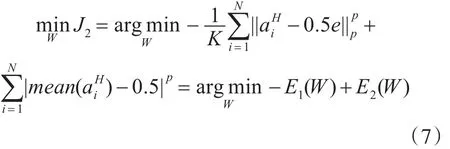
其中,p∈{0,1}上式将所有损失加起来作为损失函数,当只针对一个训练样本,可以通过(7)对每个损失项都进行优化。本文中的网络通过最小化损失函数学习到与图像语义相似的有效的二进制哈希码表达。
4.3 学习过程
将所有损失项结合起来:
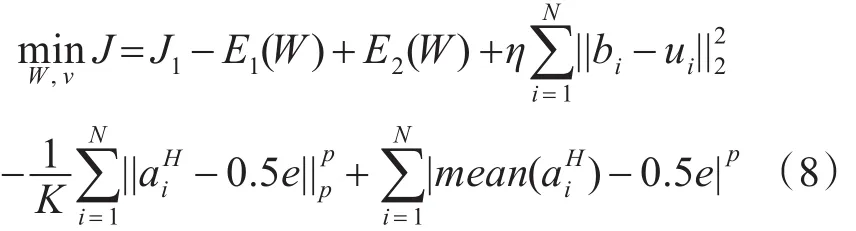
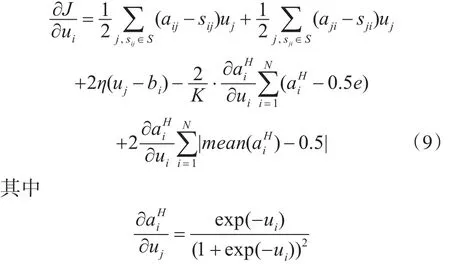
然后,我们可以利用ui更新参数W ,v和θ:
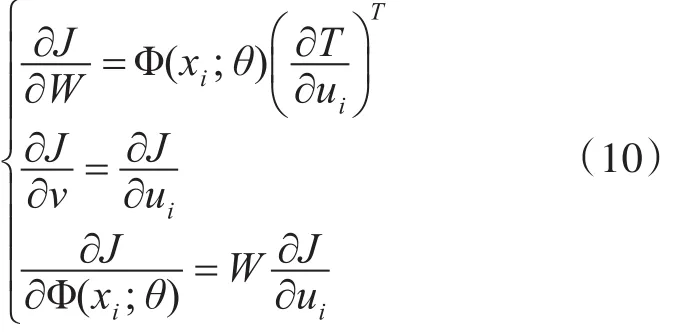
5 实验分析
5.1 实验数据和实验设备
CIFAR-10数据集总共包含60000幅彩色图片,分为10个种类,每一类包含6000张图片,每张图片大小为32×32。整个数据集分为50000幅训练图片和10000幅测试图片。NUS-WIDE数据集包含269684幅图像,81种标签,是一个每张图片带有多个标签的数据集。
在实验中本文的方法会与其他几种目前效果较好的方法进行对比,这些方法分为四类。
1)手工提取特征(512维的GIST描述符)的哈希方法(包括监督哈希和无监督哈希):SH、ITQ、SPLH、KSH、FastH、LFH、SDH;
2)利用成对标签的深度哈希方法:CNNH、DPSH;
3)利用三标签的深度哈希方法:DSRH、DRSCH、DSCH所有的实验都采用了 Matlab的MatConvNet工具箱,并且是在GT840M上运行整个框架。
5.2 评价标准
本文采用两个评价标准去评判以上采用的所有方法的性能。这些评价标准表示的是哈希算法的不同性能:
1)平均准确率(mean average precision,mAP):将查询图片与数据库所有图片的之间的汉明距离进行排序,然后计算mAP。mAP是用来衡量本文提出方法的准确性。
2)平均训练速度(mean training speed,mts):表示模型每秒能训练多少张图片。这个评价标准能够体现出哈希算法生成哈希的有效性。
5.3 实验结果
第一个实验中CIFAR-10选择1000幅图片作为测试图片,每种标签有100幅图片。无监督哈希的训练数据集就是除却测试图片剩下的所有图片,监督哈希的训练数据集是在除却测试图片剩下的所有图片中随机选择5000幅图片,每类标签包含200幅图片,NUS-WIDE则是随机选择21种标签,每种标签包含100张图片。然后在剩下的图片中每一个类别中随机选择500张图片。NUS-WIDE数据集的mAP是利用返回的相似的前5000张图片计算的。mAP的结果如表1所示。
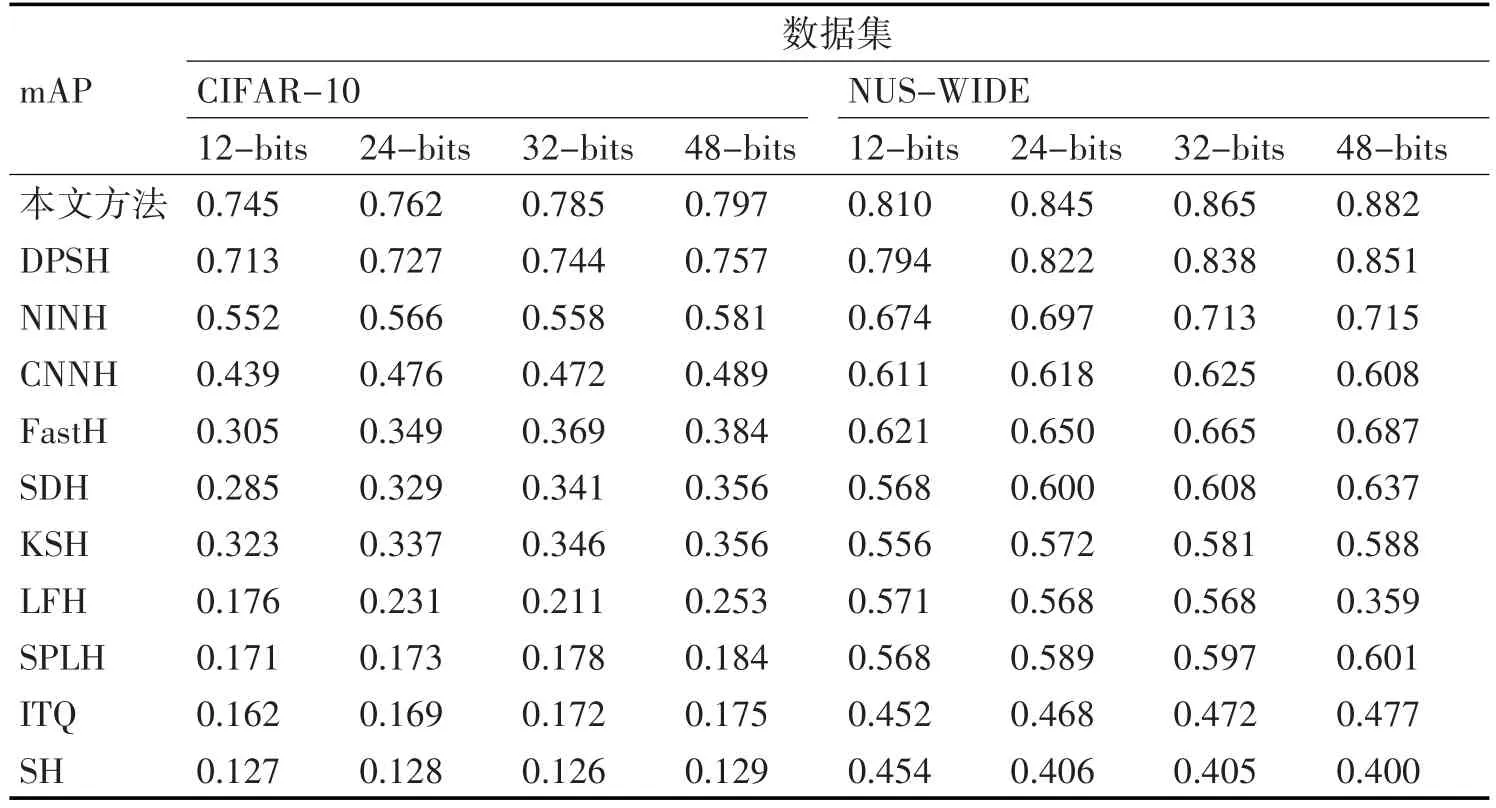
表1 本文方法与对比方法mAP

表2 本文方法与DPSH在CIFAR-10上的训练速度
表1表示了本文方法与对比方法在CI⁃FAR-10和NUS-WIDE上的mAP,相比手工提取特征的哈希方法,无论是监督哈希还是非监督哈希,都无法达到利用CNN提取图像特征更为有效。在利用CNN提取特征的方法中,DPSH方法同时进行特征学习和哈希码学习,其性能又比CNNH这种无法同时进行特征学习和哈希码学习的方法性能要好。通过分析表1和表2可以发现本文方法相比DPSH不仅在mAP上有所提高,而且训练速度也有所提升,首先可以发现通过修改后的框架和损失函数不仅生成更为有效的哈希码,提升生成哈希码的速度,还能加强判别相似或不相似哈希码的能力,提高了检索的准确率。
表3是第二个实验得出的结果,是对基于成对标签的哈希函数与基于排序标签的哈希函数的比较,测试数据和训练数据与第一个实验不一样,CI⁃FAR-10中随机选择10000幅图片作为测试数据,每一类有1000幅图片,其余的图片作为训练数据。NUS-WIDE是随机选择2100幅图片作为测试数据,总共21类,每一个有100幅图片,其余的作为训练数据,NUS-WIDE数据集的mAP是利用返回的相似的前50000幅图片计算的。作本文方法与DPSH是基于成对标签的哈希函数,DRSCH、DSCH和DSRH是基于排序标签的哈希函数,从表3可以看出基于成对标签的哈希函数比基于排序标签的哈希函数的准确度更高。
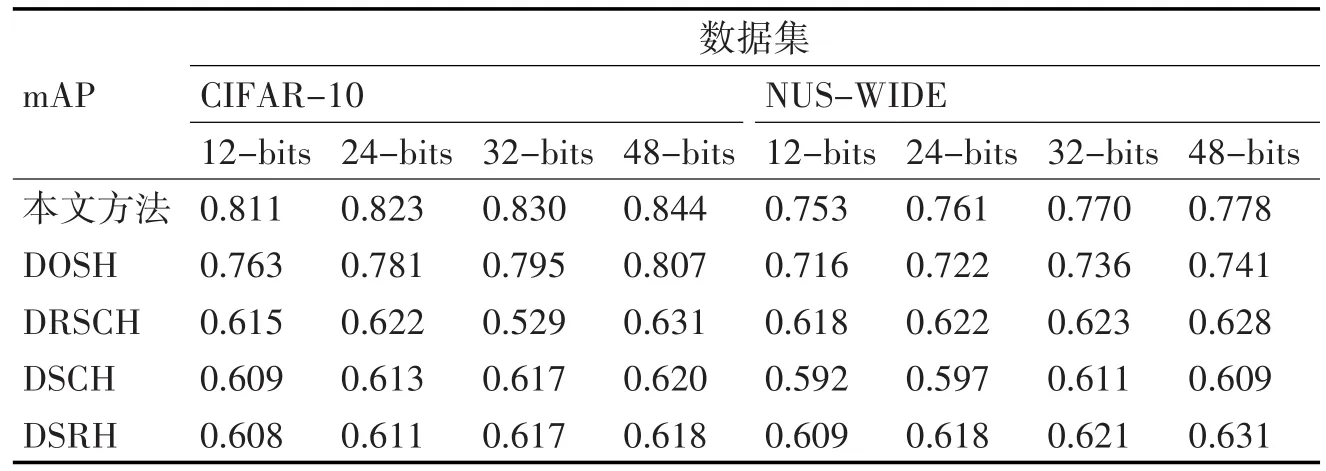
表3 成对标签哈希算法与排序标签哈希算法
6 结语
本文提出了一个针对端到端的哈希学习的图像检索方法,本文方法将目标损失函数与针对哈希码本身设定的损失函数结合在一起组成新的损失函数,本文的方法不仅能够同时进行特征学习和哈希码学习,并且能够生成更好的哈希码。在具体数据集上的实验可以看出本文的方法相比其他方法既提高了图像检索的准确度,还提高了训练模型的速度。
