MDP及PROLOG在自动驾驶中的应用
2019-12-27班兵杨志刚杨航
班兵,杨志刚,杨航
MDP及PROLOG在自动驾驶中的应用
班兵,杨志刚,杨航
(陕西重型汽车有限公司,陕西 西安 710200)
近些年来,自动驾驶迎来了新一轮研究热潮,相关领域技术发展迅速。其中行为决策系统在自动驾驶系统框架中占据重要地位。文章借鉴驾驶员行车过程中视觉行为的注意力分配机制,通过感兴趣区域推理和马尔科夫决策的有机协作生成驾驶动作。最后通过仿真,实现了简单场景下的决策指令生成。
行为决策;感兴趣区域;马尔科夫决策过程
前言
自动驾驶汽车是一种通过电脑系统实现无人驾驶的智能汽车,它的行驶模式更加节能高效,可以为国家节省数千亿的交通拥堵成本、交通事故成本以及运输过程中的人力成本。无人驾驶系统整体框架一般由感知、决策、控制三部分组成。其中决策模块在无人驾驶系统中有着非常重要的作用,不仅保障行车安全,也为路径规划提供指导和限制信息。目前,无人驾驶系统设计常用的三类决策算法为基于有限状态机FSM[1]或决策树[2]的规则决策算法、马尔科夫决策和强化学习算法、端对端深度神经网络决策算法[3]。
规则决策算法可以将交通规则知识和驾驶经验知识编辑成规则条例,从而实现行车过程中驾驶动作的匹配选择,其逻辑推理性较强,但却不能很好地处理驾驶环境中的不确定因素。马尔科夫决策将不确定环境下的驾驶行为决策问题转化成可量化的回报值计算,从而选取最优动作,但其逻辑推理性较弱,且因状态空间过大而导致其实时性变差,难以满足在线行为决策系统的需求。因此本文在场景理解的基础上,基于交通规则和驾驶经验,利用基于规则的推理机制得到感兴趣区域,从而使得驾驶动作遵守交通规则的同时减少马尔科夫决策过程中概率推理计算的运算量,即保证决策结果合理性的同时提升了系统的实时性。
1 基于规则的感兴趣区域生成
人类驾驶员行车过程中对周围环境的注意力分配具有目标驱动性,一般情况下,受目标地点和全局路径规划的影响,驾驶员的视觉注意力会选择性地集中在局部目标区域附近,从而仅提取和理解小范围区域内的环境动态信息,而在一定程度上忽略其它区域的信息。在结构化特征明显的城市道路工况下,此种目标驱动性根据不同的驾驶任务可以细化到具体的道路实体上。如驾驶员在交叉路口进行左转弯行驶时,驾驶员会将注意力集中在当前路段、交叉路口和左转弯目标路段,依据感兴趣区域内的实时交通动态信息决定下一步的驾驶动作。
驾驶行为决策系统中驾驶动作的生成是建立在对驾驶场景充分理解的基础上的,而驾驶场景本体模型是场景描述的依据,因此在考虑驾驶场景信息层次性和关联性的基础上,建立无人驾驶车辆的本体概念模型。
本体模型包括实体类别定义及属性描述。在给定驾驶场景相关实体类别的定义之后,实体的状态信息及与其它实体的联系通过数据属性和关系属性来描述。根据上述驾驶场景本体模型,可实现对自动驾驶车辆周围环境中静态实体、动态实体的状态信息和相互间关系的充分描述,从而为进一步的逻辑推理做好准备。
感兴趣区域生成规则中,车辆在路上状态下(非路口区域)行驶,当前车道为最右侧车道时的规则可描述为:
eoi(V,L):-egoVehicle(V),currentRoadState(V,”onRoad”),isOnLane(V,X),isRightMost(X,ture),findLeftLane(V,Y),append([X],[Y],L).
车辆V当前道路状态为在路上,车辆V在车道X上,车道X是最右侧车道,车道X的左侧车道为车道Y,因此车辆V的感兴趣区域为当前车道和左侧车道。
Prolog是一种基于谓词演算的高效率声明式程序设计语言,是面向非数值计算的描述性语言,在符号处理和推理方面具有极大的优势,Prolog推理的基础是由一系列事实和事先编辑好的规则构成的数据库。对于提出的问题,推理机基于数据库自动进行逆向演绎推理,并得出结果。
驾驶行为决策系统具体实现时,主体框架由C++编程实现,推理系统由Prolog动态链接库进行调用,从而实现双方信息交互[4]。在求解当前行驶状态下的感兴趣区域时,首先将描述当前场景的事实及事先离线编辑好的规则通过输入函数输入到数据库,然后通过推理机得到问题求解答案。
2 马尔科夫决策过程驾驶动作生成
2.1 马尔科夫决策过程简介
马尔科夫决策过程(MDP)是描述智能体(Agent)与环境之间相互作用的一种模型,可以看作是一个受控的马尔科夫过程,用来处理动态环境下不确定的序列式决策问题[5]。
其基本决策过程如下:首先,遍历动作集合中的所有动作,每一个动作在当前状态下通过转移函数计算得到下一刻状态,由每一个动作及其对应的下一个状态通过回报函数的计算得到一个立即回报值,计算动作值函数。然后将下一个状态当做当前状态,重复迭代上述步骤,更新动作值函数,直到到达一定的迭代次数或到达局部目标点,最后通过最优动作值函数推算出最优动作,并输出给局部路径规划。
2.2 MDP模型求解核心函数
(1)状态空间
状态空间包括自动驾驶车辆感兴趣区域内动态实体的所有可能描述信息,本文将状态空间定义为无人车及周围其它车辆的空间存在状态:

其中N为它车个数。对于自动驾驶车辆自身,主要关注其在感兴趣区域中的位置坐标(xego,yego)、速度vego和航向角θego,而对于周围车辆,除了关注其位置、速度和航向角之外,还要关注其驾驶意图bi:
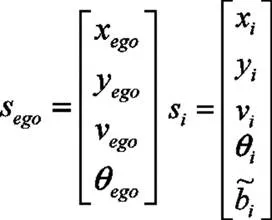
驾驶行为决策过程中,迭代过程的结束需要一个终止状态sterm来判断,本文选取下述两种情况作为结束标志:无人车与静、动态障碍物发生碰撞或无人车到达目标位置。当到达终止状态时,马尔科夫过程不再进行迭代,当前感兴趣区域内的决策过程结束,等待感兴趣区域的更新。
(2)动作空间
动作空间主要用于定义无人车所有可能选择的驾驶动作,包括横向和纵向驾驶动作指令。为方便车辆底盘控制系统理解上层驾驶指令,动作空间需对抽象动作指令进行参数化表示,保证车辆状态按照决策输出进行调整响应。
表1 驾驶动作参数化表示对应关系

(3)转移函数
状态转移函数用StateTransition表示,是对输入的状态Si和动作a进行计算,得到Δt后的下一时刻自动驾驶车辆所在的状态Si+1。
对于无人驾驶车辆,认为无人驾驶车辆的自身状态信息是准确的,进而其转移模型由下面车辆运动学模型唯一确定:
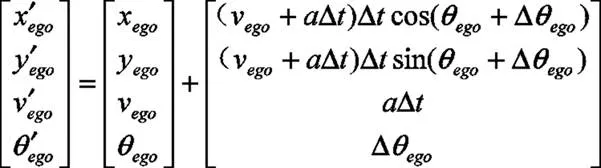
对于ROI内其它车辆,根据驾驶意图预测得到的预测轨迹进行计算。
(4)回报函数
回报函数用getReward表示,是对自主驾驶任务完成程度的定量评估,通常根据安全性、舒适度、任务完成度和任务完成效率多个目标属性进行定义,从而得到此状态和动作的评价,即:

其中,安全性是无人车关注的第一要素,必须保证无人车不和周围车辆发生碰撞事故。若驾驶动作a执行后发生碰撞则得到负的回报值,用来惩罚动作a,否则回报值为正,认为执行动作a后的状态安全。
驾驶行为决策结果还需保证行车过程中的稳定性,避免车辆控制动作频繁的切换,以保证乘坐时的舒适性,当有横向动作或纵向加减速时得到负的回报值。
任务完成度评价是为了使无人驾驶车辆行驶趋向目标点,使其能够完成驾驶任务。执行动作后,若抵达当前感兴趣区域内的局部目标点时,给予正的回报值,以引导车辆向目标位置行驶。任务完成效率评价是为了使无人驾驶车辆能够以更高效的速度到达任务目标点,也就是速度越大,相应的奖赏回报值也是越大的。但同时需要遵守交通规则,也就是行驶速度需在当前ROI内公路规定的最高限速vmax以内,当条件允许,无人驾驶车辆会以vmax的速度行驶。
(5)动作值函数
动作值函数是一个递归函数,用Qstar表示,首先检测当前状态是否到达终止状态send,若到达则结束递归,然后判断当前迭代次数是否到达T,若到达则结束递归,否则对所有可能的动作a进行循环计算。
在输入状态Si和动作a下,通过转移函数StateTransition计算出自动驾驶车辆下一刻会转移到状态Si+1,判断状态Si+1是否超出ROIbound范围,若超出范围进行剪枝的操作,即直接返回,不进行值函数的计算,也不计入可执行动作的数目,不超出则通过getReward函数计算状态Si+1的即时回报值Reward。
接着通过下式计算所有动作A的动作值函数Q(s,a),其中Q(s',a')通过Qstar函数进行递归迭代计算。
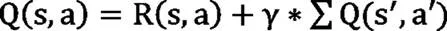
其中,γ为折扣因子,并且0<γ<1,折扣因子保证了总收益的收敛性;R为回报函数。
(6)MDP函数
MDP决策算法函数根据输入的状态S、感兴趣区域ROI信息进行迭代计算,生成最优动作。首先对输入的ROI信息进行处理变为ROIbound限制,包括ROI位置坐标(x,y)的边界、ROI所在车道的限速vmax,航向角θ的范围限制(取决于自动驾驶车辆的转向性能)。
然后检测当前状态是否到达终止状态sterm,若到达,则终止循环,等待感兴趣区域更新,否则对所有可能的动作a进行动作值函数计算。
最后通过下式可以求得最优状态值函数V*,也就获得最优动作a*并作为决策动作返回。

2.3 MDP核心算法实现流程
在自动驾驶系统输入行驶任务后,根据逻辑推理机、感知系统、它车驾驶意图预测模块实时传回的数据信息,初始化感兴趣区域和当前状态。感兴趣区域信息包括ROI区域坐标、ROI区域内车道数量、ROI区域内的车速限制和ROI内的局部目标点sobj,当前状态包括自动驾驶车辆和ROI内它车的位置(x,y)、速度v和航向角θ。然后开始并每隔Δt调用一次MDP决策生成函数进行最优驾驶动作的生成,并输出到局部路径规划,直到到达终止状态sterm。
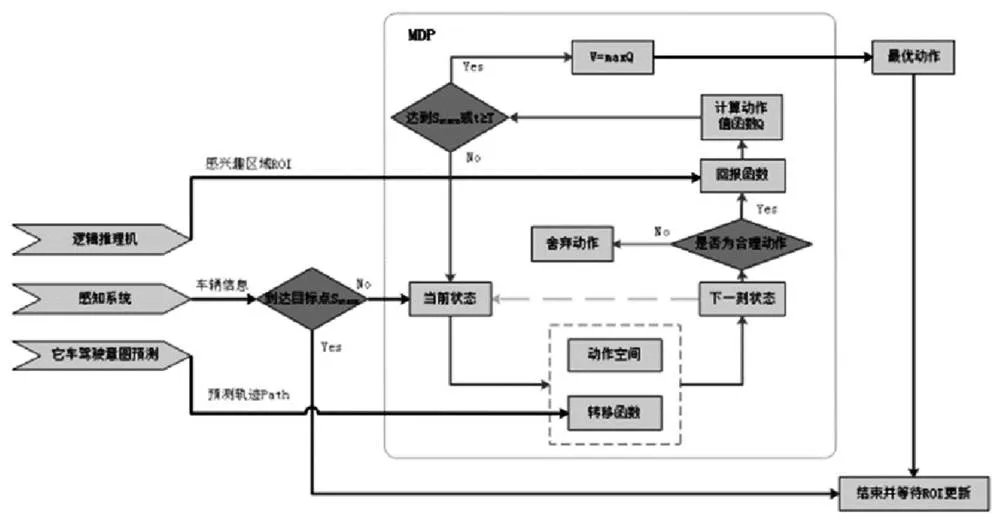
图1 MDP核心算法实现流程
在每一次MDP决策之前,需要根据属性ROIat对在ROI内可能的动作进行筛选,以减少不必要的迭代计算时间。即当ROIat为在路口,横向动作只可能是转向动作:左转、直行、右转;当为在路上,横向动作只可能是换道动作:左换道、车道保持、右换道。
在每一次MDP决策之后,执行生成的驾驶动作a*之后,根据逻辑推理机和感知系统实时的信息反馈,更新ROI信息和状态S,作为下一次动作生成的输入参数。
3 仿真结果
仿真场景设置为:当前路段为同向3车道,本车处于最右侧车道。本车前方存在一缓慢行驶的它车。根据离线设置的规则库进行逻辑推理,生成当前的感兴趣区域及其属性信息。然后通过马尔科夫决策过程生成驾驶动作指令,由图4、图5可知,横向动作为左换道后车道保持,纵向动作依次为为加速、匀速、停车,实现了简单场景的决策。
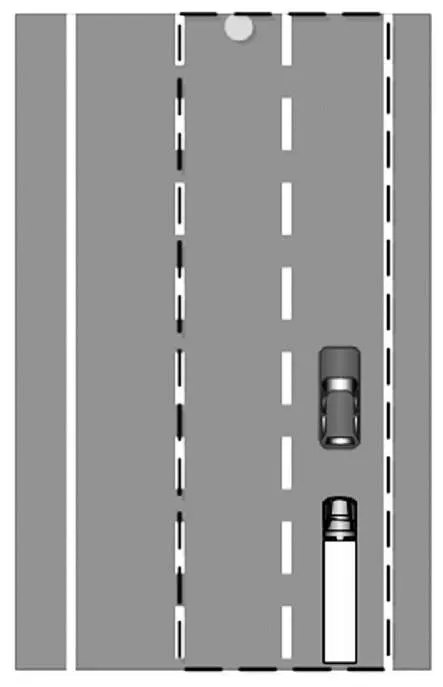
图2 仿真场景
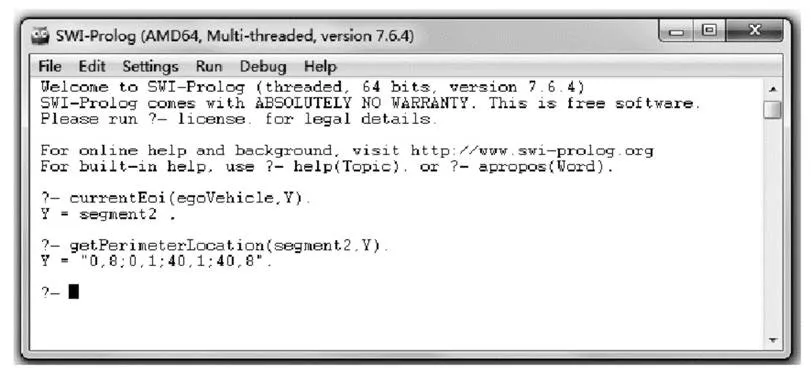
图3 感兴趣区域生成
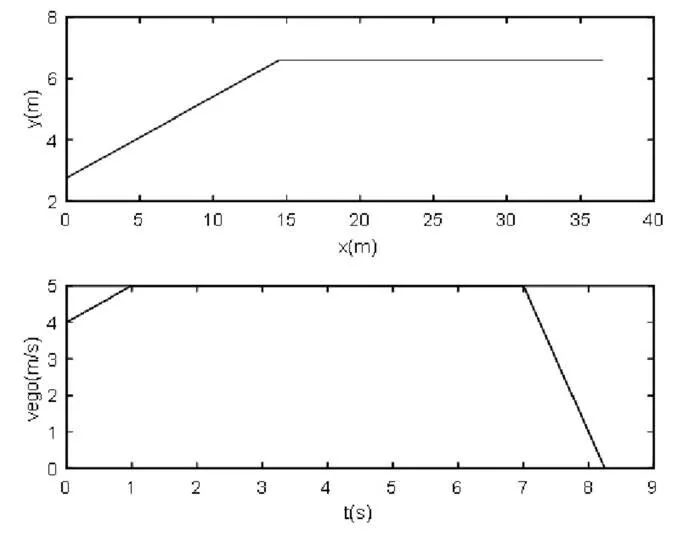
图4 决策路径及速度
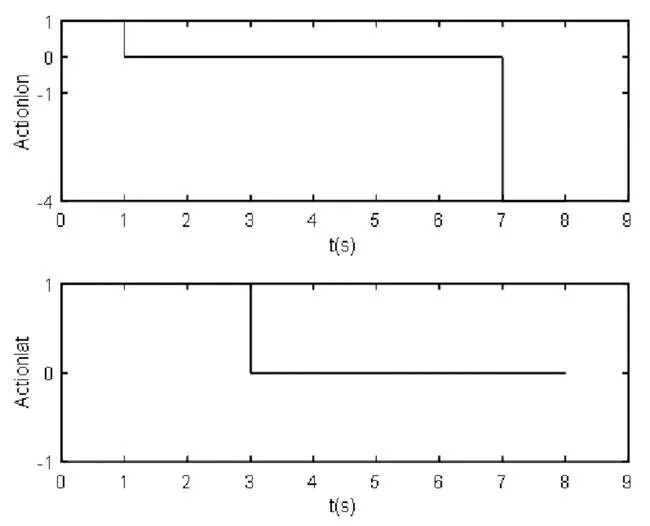
图5 横、纵向决策指令
4 总结与展望
(1)通过感兴趣区域推理和马尔科夫决策的有机协作可实现简单交通场景下驾驶动作的生成。
(2)在复杂交通场景决策中,本文决策算法的实时性仍有改进提升的空间,构建高效快速的MDP计算模型或结合自动驾驶的任务特点对决策算法进行改进将是非常有价值的研究课题。
[1] 熊光明,李勇,王诗源. 基于有限状态机的智能车辆交叉口行为预测与控制[J].北京理工大学学报,2015,35(1):34-38.
[2] 杜明博.基于人类驾驶行为的无人驾驶车辆行为决策与运动规划方法研究[D].合肥:中国科学技术大学, 2016.
[3] 熊璐,康宇宸等.无人驾驶车辆行为决策系统研究[J].汽车技术, 2018.
[4] 武桂鑫,许烁.C ++ 与Prolog 双向数据交换实现混合控制架构下机器人任务规划[J].计算机应用,2015.
[5] Sebastian Brechtel, Probabilistic MDP-Behavior Planning for Cars[J]. 2011 14th International IEEE Conference on Intelligent Transporta -tion Systems Washington, DC, USA. October 5-7, 2011.
Application of MDP and PROLOG in autopilot
Ban Bing, Yang Zhigang, Yang Hang
( Shaanxi heavy truck Co., Ltd., Shaanxi Xi'an 710200 )
In recent years, a new wave of research upsurge on autonomous driving has emerged, and technology of related fields have developed rapidly. The behavior decision-making system plays an important role in the framework of autonomous driving system. In this paper, the attention distribution mechanism of drivers' visual behavior during driving is used for reference, and driving actions are generated through the organic cooperation of region of interest reasoning and markov decision making. Finally, the decision-making instruction generation under simple scenes is realized through simulation.
Behavior decision-making; Region of interest; Markov decision making
U469.7
B
1671-7988(2019)24-37-04
U469.7
B
1671-7988(2019)24-37-04
10.16638/j.cnki.1671-7988.2019.24.012
班兵(1986.03-)男,中级工程师,就职于陕西重型汽车有限公司,从事整车性能及控制策略开发工作。
