基于深度学习的超声图像左心耳自动分割方法
2019-12-23韩路易黄韫栀窦浩然白文娟刘奇
韩路易 黄韫栀 窦浩然 白文娟 刘奇


摘 要:從超声图像中分割出左心耳(LAA)是得出临床诊断指标的重要步骤,而准确自动分割的首要步骤和难点就是实现目标的自动定位。针对这一问题,提出了一种结合基于深度学习框架的自动定位和基于模型的分割算法的方法来实现超声图像中LAA的自动分割。首先,训练YOLO模型作为LAA自动定位的网络架构;其次,通过验证集确定最优的权重文件,并预测出LAA的最小包围盒;最后,在正确定位的基础上,将YOLO预测的最小包围盒放大1.5倍作为初始轮廓,利用CV模型完成LAA的自动分割。分割结果用5项指标加以评价:正确性、敏感性、特异性、阴性、阳性。实验结果表明,所提方法能够实现不同分辨率条件和不同显示模式下LAA的自动定位,小样本数据在1-000 次迭代时已经达到最优的定位效果,正确定位率达到72.25%,并且在正确定位的基础上,CV模型的分割准确率能够达到98.09%。因此,深度学习技术在实现LAA超声图像的自动分割上具备较大的潜力,能够为基于轮廓的分割算法提供良好的初始轮廓。
关键词:自动分割;深度学习;CV模型;左心耳;超声图像
中图分类号:TP391.1
文献标志码:A
Automatic method for left atrial appendage segmentation from
ultrasound images based on deep learning
HAN Luyi1, HUANG Yunzhi1,2, DOU Haoran3, BAI Wenjuan4, LIU Qi1*
1. College of Electrical Engineering, Sichuan University, Chengdu Sichuan 610065, China;
2. College of Materials Science and Engineering, Sichuan University, Chengdu Sichuan 610065, China;
3. School of Biomedical Engineering, Shenzhen University, Shenzhen Guangdong 518060, China;
4. Department of Cardiology, West China Hospital of Sichuan University, Chengdu Sichuan 610000, China
Abstract:
Segmenting Left Atrial Appendage (LAA) from ultrasound image is an essential step for obtaining the clinical indicators, and the prerequisite and difficulty for automatic and accurate segmentation is locating the target accurately. Therefore, a method combining with automatic location based on deep learning and segmenting algorithm based on model was proposed to accomplish the automatic segmentation of LAA from ultrasound images. Firstly, You Only Look Once (YOLO) model was trained as the network structure for the automatic location of LAA. Secondly, the optimal weight files were determined by the validation set and the bounding box of LAA was predicted. Finally, based on the correct location, the bounding box was magnified 1.5 times as the initial contour, and CV (ChanVese) model was utilized to realize the automatic segmentation of LAA. The performance of automatic segmentation was evaluated by 5 metrics, including accuracy, sensitivity, specificity, positive, and negative. The experimental results show that the proposed method can achieve a good automatic segmentation in different resolutions and visual modes, small samples data achieve the optimal location performance at 1-000 iterations with a correct position rate of 72.25%, and CV model can reach the accuracy of 98.09% based on the correct location. Therefore, deep learning is a rather promising technique in the automatic segmentation of LAA from ultrasound images, and it can provide a good initial contour for the segmentation algorithm based on contour.
Key words:
automatic segmentation; deep learning; CV (ChanVese) model; Left Atrial Appendage (LAA); ultrasound image
0 引言
房颤患者心房附壁血栓脱落可以导致体循环血栓栓塞,其中脑卒中是最常见和最严重的血栓栓塞事件[1]。最近研究显示左心耳(Left Atrial Appendage, LAA)封堵术可以有效预防房颤患者血栓栓塞[2-5],封堵术成功的关键在于左心耳形状的准确选择。对左心耳图像准确的自动分割是自动计算封堵装置的形状参数以及判断房颤的指标的重要前提,具有重要的临床意义。在分析大量医学数据时,由医生进行人工分割LAA边界繁杂耗时且主观性强, 因此,需要设计重复性强、鲁棒性高的自动分割算法,以实现后续的自动计算并同时减轻医护人员的工作负担。为此,LAA超声图像自动分割模型,需克服两大难点:1)克服图像中其他目标的干扰,实现快速准确地自动定位;2)克服超声图像中的固有斑噪和LAA内部的梳状肌和肌小梁所造成的影响,实现准确的轮廓演化。
1 相关工作
目前,活动轮廓模型(Active Contour Model, ACM)已经广泛应用于图像自动分割的方案中,ACM的基本思想是通过演化目标轮廓曲线来求解其能量泛函的最小值。常见的基本形变模型有:1)主动外观模型(Active Appearance Model, AAM);2)主动形状模型(Active Shape Model,ASM);3)模板模型(Atlas Model,AM)。由Chan等[6]提出的CV(ChanVese)模型是最受欢迎的模型之一,CV模型在边界较弱的图像上有更好的表现,但不能很好地适用于图像强度不均匀的情况。Li等[7-8]提出由局部二值拟合(Local Binary Fitting,LBF)和局部扩展拟合(RegionScalable Fitting,RSF)为能量驱动的方法。RSF在模型中引入了图像局部区域的强度信息,从而实现对强度不均匀的图像的有效分割。该类方法能够克服基于图像像素分类的分割算法的缺陷:1)鲁棒性不高;2)需要大量的人工参与以提高准确性。方法的计算量大,且如果初始轮廓选择不当,非凸的能量函数会导致模型陷入局部最小值,甚至分割失败。对于LAA图像,大部分研究采用一些基本几何形状作为初始轮廓,如果无法准确定位会极大地延长收敛时间,甚至收敛出错误的轮廓。因此,本文从提高分割精度和鲁棒性角度出发,要实现自动分割,其首要步骤就是从超声图像中快速、自动定位出LAA。
基于特征工程的机器学习方法需要人工参与,设计有效良好的特征提取方案,以将原始数据转换成可区分的特征向量。但是人工参与的工程技能和专业知识在量化过程中会有一定主观差异,对于分类结果会有一定的影响。基于卷积神经网络(Convolutional Neural Network,CNN)[9]的深度学习方法可以利用原始图像数据作为输入,通过组合每一层简单的非线性模块,就可以将输入转换成高层的表达输出,且整个表达学习的过程几乎不需要人工参与。在目标检测任务上,深度学习方法主要分为两类:1)基于选择性搜索的区域卷積神经网络(Regionbased Convolutional Neural Network,RCNN)[10-13];2)实现端到端检测的YOLO(You Only Look Once)[14-16]。基于RCNN的方法利用聚类方式,对图像进行分割分组,得到多个候选框的层次组。RCNN计算的候选框数量多且有大量重叠,冗余计算量非常大,为提高运行速度,Fast RCNN[11]方案中候选框只经过一个CNN,Faster RCNN[12]则直接利用CNN来计算候选框。然而,基于RCNN的方案,复杂的流程通常导致计算速度慢且很难实现优化。而YOLO把物体框的选择与识别进行了结合,一步输出,识别速度非常快,达到每秒45~150帧。
目前针对LAA轮廓提取的研究和文献非常少,现有的LAA定量分析软件是以左室的形态结构作为模型的。为减小所选封堵装置的误差,提高自动分割的运算效率和准确性,本文提出了一种基于深度学习网络和参数活动轮廓模型的全自动LAA提取方法,整个流程如图1所示。
首先,利用深度学习网络YOLO训练LAA超声图像得到网络的权值参数,完成LAA的准确自动定位;进而,在只含有LAA单一目标的有限范围内,利用改进的CV模型[17-18]完成LAA的自动分割。
2 左心耳自动分割方法
2.1 基于YOLO模型的自动定位
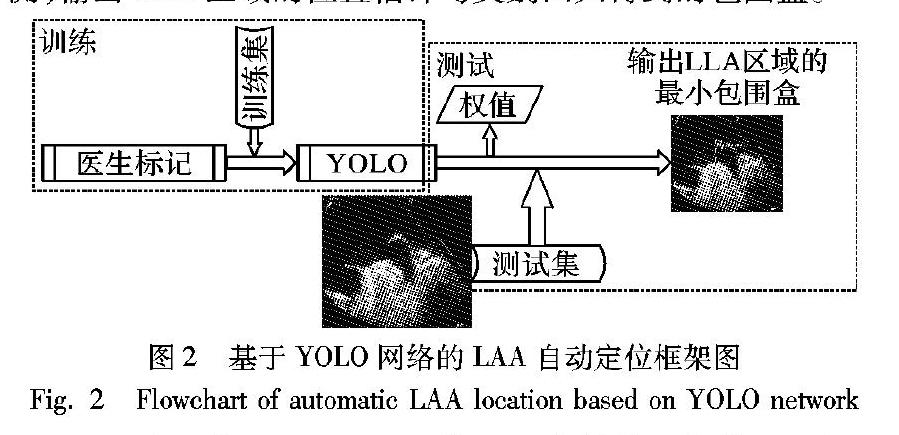
通常,完成一个心动周期所需要的时间为0.8s, 由于人眼的视觉暂留效应,当帧率高于每秒24帧时,就认为是连贯的,因此为满足实时定位并识别超声图像中的LAA,采用YOLO的网络架构,即使不采用批处理,利用GPU加速模式,对于物体识别和定位的速度也可以达到每秒45~150帧[11],能够满足对LAA的处理速度。基于YOLO网络的LAA自动定位架构如图2所示,自动定位架构主要分为训练和测试两大模块:训练时使用由医生标记的训练集对YOLO模型的权值参数进行更新;测试时固定权值参数,对测试集图像进行预测,输出LAA区域的位置估计与类别回归得到的包围盒。
图2中所使用的YOLO网络的具体结构及参数设置如图3所示,整个卷积神经网络包含了24个卷积层,并连接了2个全连接层。卷积层通过局部连接对图像局部特征进行提取;池化层降低图像尺度同时增加了卷积层的感受野范围;全连接层则整合了全局信息,能够更好地预测LAA区域。YOLO网络的具体参数设置如下:
1)网络输入缩放成统一大小,且输入图像矩阵分割成s×s 的单元格,通常将s设为7。
2)每个单元格负责输出b个矩形框,其中共包含两部分信息:①数组(x, y, w, h)表示其位置信息,x、 y表示中心相对于单元格左上角的位置偏移,记单元格左上角为(0, 0),右下角为(1, 1),w、 h表示矩形框的宽与高,都是相对于整个图片的相对值,全幅图片大小为(1, 1)。②概率P(object)表示该框是物体的概率。
3)每个单元格再负责输出c个类别的概率,用概率P(class|object)表示,最终输出时物体的概率乘以类别概率,才是整体识别到是一个物体的概率,即:
P(class)=P(class|object)×P(object)
如果一个物体的中心落入一个单元格,则该单元格上的b个矩形框的位置信息都为该物体的位置信息,c个概率中对应该物体类别值为1,其他为0。由于训练的数据集分为左心耳和非左心耳两类,所以将b、c均设为2。
4)最终输出层共包含有s×s×(b×5+c)个单元。网络每一层之间的连接,类比神经元的稀疏激活性,输入信号的稀疏特性使得学习网络并不需要很强的线性可分机制,因此在网络训练时,整个网络除了最后一层为线性激活,其他层都采用如式(1)的泄露型线性矫正激活方式[19]:
Φ(x)=x,x>00.1x,其他 (1)
YOLO每一个单元格能够预测多个包围盒,在训练时,每一个物体只需要一个包围盒,因此,根据当前最高的交并比(Intersection over Union,IoU),指定一个预测的包围盒对应待检测物体。但是,输入图片的大部分单元格中并没有落入物体中心,为增强整个网络的稳定性,引入参数λcoord和λnoobj,对类别概率和最小包围盒的误差进行分析。训练过程中,为使包围盒的预测偏差受目标大小的影响较小,最终优化的损失函数如式(2)所示:
J=λcoord∑s×si=0∑2j=0[Tobji,j(xi-i)2+(yi-i)2]+
λcoord∑s×si=0∑2j=0[Tobji,j(wi-i)2+(hi-i)2]+
∑s×si=0∑2j=0Tobji,j(ci-i)2+λnoobj∑s×si=0∑2j=0Tnoobji,j(ci-i)2+
∑s×si=0Tobji∑c∈classes(pi(c)-i(c))2(2)
其中:Tobji表示是否出现在单元格i中,Tobji,j表示使用第i个单元格中第j个类别的预测器,数组(xi,yi,wi,hi)和(i,i,i,i)分别表示目标在第i个单元格中的筛选框坐标及其估计。针对同一个物体可能识别出来多个选框的情况,YOLO采用非极大值抑制(NonMaximum Suppression,NMS)去掉重复框。根据每一个框对应的置信率,消除多余框的具体步骤如下:
1)按置信率排序由高到低排序;
2)取最大置信率的框为物体框;
3)剩余多个框中,去掉与最大置信率框的重叠率大于特定阈值的框;
4)重复步骤3),直到没有剩余框;
5)确定最终被标记为物体的框。
2.2 基于CV模型的自动分割
由于YOLO学习网络能够输出只包含单一目标——LAA的最紧包围盒,非左心耳区域所占比例较小,因此利用CV模型实现左心耳腔和其余组织的分离。作为几何形变模型,CV模型并没有用到图像的梯度信息,而是利用了目标和背景的灰度差异,因此,CV模型的一个优势是能够分割出边界梯度变化不明显的结构,并且能够实现多目标分割,能够满足本实验中不同显示模态和不同扫描条件下LAA的自动分割。CV模型的能量方程定义如式(3)所示:
E=μ·Length(L)+υ·Area(inside(L))+λ1∫inside(L)I(x,y)-l12dxdy+λ2∫outside(L)I(x,y)-l22dxdy(3)
其中:L表示演化轮廓,I表示图像灰度,μ和υ为相应项的非负系数,λ1和λ2为相应项的正系数,l1和l2分别表示演化轮廓内部和外部所有像素的平均灰度。前两项为演化轮廓的内部能量,用以正则化轮廓的几何特性;后两项为演化轮廓的外部能量,用以将轮廓收敛到正确的位置。
3 实验结果和分析
3.1 实验数据和实验平台
1)实验数据。所有的LAA超声图片都是由四川大学华西医院超声心内科提供,医生利用Phillip iE33超声诊断仪并配合经食道的探头X72t采获。数据来自不同的患者,一共512例,每一例中有1张LAA图像由医生同时标注包围框和LAA轮廓。其中测试数据集包含192例,训练数据集320例,并从训练集中随机选择192例作为验证集。
2)实验平台。硬件环境:Intel Xeon E52630 CPU 2.40GHz,8GB内存,NIVIDIA GeForce GTX 1080Ti显卡。软件环境:权值参数训练在UBUNTU 14.0.4系统,Python 2.7环境下进行;自动定位和自动分割实验在Windows 10系统,Matlab 2015a环境下进行。
3.2 实验设置
在数据采集阶段,共由3名医生完成对超声图像LAA区域的标记,标记结果为LAA在诊断图像中的最紧包围盒。在训练数据阶段,从采集数据中随机抽取512张,其中320张用于训练YOLO网络的权值,剩余192张作为该训练网络的测试。为保证整个网络架构的迭代收敛,网络参数设置如下:
1)统一图像输入尺寸为418×418;
2)由于本次的數据集有限,为了更好地引导网络朝向极值所在的方向学习,因此采用全数据集的形式输入;
3)为保证学习速度和学习的准确率,最终能够找到极值,YOLO网络的训练使用了自适应动量估计(Adaptive moment estimation,Adam)优化方法,学习率设置为0.001,批处理个数设置为8。对于式(2)所示的损失函数,λcoord设置为5,λnoobj设置为0.5。
训练阶段结束后,导出网络的权重文件,并随机抽取采集样本数据输入到训练网络测试整个学习网络性能。自动定位的输出结果为包围LAA的最小包围盒,其中,定位结果只显示置性度高于0.5的包围盒。
3.3 定位结果
得益于多层卷积网络,和传统的基于灰度信息和机器学习分类的方法相比,基于深度学习的自动定位从图像整体角度出发,从微观到宏观地分析图像中的像素、边、物体,因此能够克服传统超声图像固有的低分辨率缺陷。图4展示了学习网络在不同扫描条件下的定位结果,其中:图4(a)为LAA处于舒张末期,虽然目标明确,但扫描结果分辨率较低情况下自动定位的结果;图4(b)为目标占整幅图像比例较小,但扫描结果分辨率较高情况下的结果;图4(c)为目标清晰,但为双帧显示模式下的定位结果;图4(d)为分辨率中等水平、LAA处于收缩末期时边界不明显情况下的定位结果。因此,利用YOLO网络,可以完成LAA在不同显示模式、不同扫描条件下的自动定位。
3.4 定位误差
为确定学习网络的最优迭代次数,提取出训练阶段中在不同迭代次数下得到的权重文件进行测试,并将自动定位的结果归为以下4类:1)遗漏、2)错误、3)部分重合、4)完全重合。其中:遗漏是指LAA区域并未出现包围盒;错误是指包围盒出现在非左心耳区域;部分重合是指包围盒未包含完全左心耳,但至少包含了90%的左心耳区域;完全重合是指包围盒和医生标记的完全重合。遗漏和错误归为是偏差(NEGATIVE)定位,而部分重合和重合认为是正确(POSTIVE)的定位。本次实验利用192例验证集样本,对1-000 ~ 7-000次迭代得到的权值进行验证,表1和图5显示了以上4类的统计结果。
若仅从完全重合率来看,在5-000次迭代时重叠的样本数是最多的,但相应的错误率也较高,因此,从整体正确定位率可以看出,由于样本数量有限,在1-000次迭代时,自动定位的效果最好。并且从图5中可以看出,不同迭代次数下,统计结果差异变化较小,因此,1-000次迭代后,整个网络都处于一个稳定收敛的状态。值得指出的是,本次实验中正确自动定位的概率不是很高,主要归结为以下3方面原因:1)医学数据的训练样本数有限;2)左心耳形状的个体差异性;3)左心耳具有多样化的病理形态,而训练样本中只包括了一部分病理形态。
3.5 分割精度
针对192例测试样本中完成正确定位的数据,利用CV模型的自动分割结果如图6所示。其中,图6(a)为在目标定位结果与实际位置完全重合的情况下得到的分割结果,图6(b)则为在目标定位结果与实际位置部分重合的情况下得到的分割结果。为保证部分重合能够包含所有的区域,在自动分割之前,将包围盒自动扩增1.5倍。可以看出,正确定位后的数据均能够得到较好的分割结果。
将医生勾勒的轮廓作为“金标准”,采用5个指标:准确性(Accuracy)、敏感性(Sensitivity)、特异性(Specificity)、阳性预测值(Positive)、阴性预测值(Negative)[15]为指标,评价基于YOLO网络自动定位的左心耳自动分割方案:
Accuracy=(TP+TN)/(TP+TN+FP+FN)
Sensitivity=TP/(TP+FN)
Specificity=TN/(TN+FP)
Positive=TP/(TP+TN)
Negtive=FP/(FP+FN)
从概率上讲,TP(True Positive)表示正样例分类成正样例;TN(True Negative)表示负样例分类成负样例;FP(False Positive)表示负样例分类成正样例;FN(False Negative)表示正样例分类成负样例。
针对1-000次迭代权重下,192例测试样本中正确定位的数据(共计138例),表2在各项指标下对比了CV、LBF和RSF三种模型的分割效果。可以看出,在YOLO网络提供自动定位的初始轮廓的情况下,三种模型的分割准确率都非常高,且各项指标均表现优秀。表3中所示为三种模型的CPU耗时比较,CV模型耗时最少。因此,在三种模型精确度相近的情况下,CV模型更适用于左心耳分割任务。但是,当左心耳接近收缩末期时,整个分割结果会受到其内部的梳状肌和肌小梁影响,因而仍会导致漏检。在未来的工作中,将会为进一步提高全自动分割的准确性,结合其他技术和信息,对左心耳超声图像进行分析。
4 结语
尽管超声设备目前的应用广泛,但是超声图像的分割一直受限于图像本身的质量,虽然近年来已有相关的硬件改善,但是影响成像质量仍受病人状态、医生经验等多种因素制约。相较于目前大量的关于超声图像自动分割的研究,几乎都是基于图像本身的灰度、梯度、相位信息,或是解剖结构的先验信息构建出基于边界或是区域的能量模型,通过求解得到使能量最小的值来完成分割工作,但是模型受限于目标区域的局部特征,并且需要经过较多的预处理步骤才能在特定条件的图像上取得较为满意的效果。
为尽量克服图像质量和个体差异带来的自动分割的困难,并提高从超声图像中全自动分割出左心耳的准确性,基于YOLO模型自动定位的自动分割方法主要的创新如下:
1)依托于深度学习的理念,应用CNN结构,根据YOLO搭建出的学习网络,实现了左心耳超声图像中目标的自动定位。基于YOLO模型的自动定位架构能够较好地克服超声成像固有的低分辨率、斑点噪声的干扰,成功定位出心動周期内各种状态下的左心耳,同时,能够完成不同分辨率条件和不同显示模式结果下的自动定位。
2)在定位准确的基础上,左心耳已经被锁定包含单一目标的矩形框内,利用CV模型能够较为准确分割出目标。
由于医学样本量通常受限于患者意愿,因此测试数据量相对较小,在以后的工作中会进一步收集样本,扩大训练和测试样本数量,进一步使得自动定位和分割的结果具有更强的鲁棒性。
參考文献 (References)
[1] ALSAADY N M, OBEL O A, CAMM A J. Left atrial appendage: structure, function, and role in thromboembolism[J]. Heart, 1999, 82(5):547-554.
[2] KONG B, LIU Y, HUANG H, et al. Left atrial appendage closure for thromboembolism prevention in patients with atrial fibrillation: advances and perspectives[J]. Journal of Thoracic Disease. 2015, 7(2): 199-203.
[3] LEAL S, MORENO R, de SOUSA ALMEIDA M, et al. Evidencebased percutaneous closure of the left atrial appendage in patients with atrial fibrillation[J]. Current Cardiology Reviews. 2012, 8(1):37-42.
[4] WHITLOCK R P, HEALEY J S, CONNOLLY S J. Left atrial appendage occlusion does not eliminate the need for warfarin [J]. Circulation, 2009, 120(19):1927-1932.
[5] ABDELMONEIM S S, MULVAGH S L. Techniques to improve left atrial appendage imaging[J]. Journal of Atrial Fibrillation, 2014, 7(1): No.1059.
[6] CHAN T F, VESE L A. Active contours without edges[J]. IEEE Transactions on Image Processing, 2001, 10(2): 266-277.
[7] LI C, KAO C Y, GORE J C, et al. Implicit active contours driven by local binary fitting energy[C]// Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2007: 1-7.
[8] LI C, KAO C Y, GORE J C, et al. Minimization of regionscalable fitting energy for image segmentation[J]. IEEE Transactions on Image Processing, 2008, 17(10): 1940-1949.
[9] LeCUN Y, BENGIO Y, HINTON G. Deep learning[J]. Nature, 2015, 521(7553): 436-444.
[10] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2014:580-587.
[11] GIRSHICK R. Fast RCNN[EB/OL]. [2019-04-20]. https://arxiv.org/pdf/1504.08083.pdf.
[12] REN S, HE K, GIRSHICK R, et al. Faster RCNN: towards realtime object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149.
[13] GOULD S, GAO T, KOLLER D. Regionbased segmentation and object detection[C]// Advances in Neural Information Processing Systems 22. Cambridge, MA: MIT Press, 2009:655-663.
[14] REDMON J,DIVVALA S,GIRSHICK R, et al. You only look once: unified, realtime object detection[EB/OL]. [2019-04-20]. https://arxiv.org/pdf/1506.02640.pdf.
[15] REDMON J, FARHADI A. YOLO9000: better, faster, stronger[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017:6517-6525.
[16] REDMON J, FARHADI A. YOLOv3: an incremental improvement[EB/OL]. [2018-05-25]. https://arxiv.org/pdf/1804.02767.pdf.
[17] MAKA M, DANK O, GARASA S, et al. Segmentation and shape tracking of whole fluorescent cells based on the ChanVese model[J]. IEEE Transactions on Medical Imaging, 2013, 32(6): 995-1006.
[18] WANG X, ZHENG C, LI C. Automated CT liver segmentation using improved ChanVese model with global shape constrained energy[C]// Proceedings of the 2011 Annual International Conference of the IEEE Engineering in Medicine and Biology Society. Piscataway: IEEE, 2011: 3415-3418.
[19] MAAS A L, HANNUN A Y, NG A Y, et al. Rectifier nonlinearities improve neural network acoustic models[EB/OL]. [2018-05-28].http://robotics.stanford.edu/~amaas/papers/relu_hybrid_icml2013_final.pdf
This work is partially supported by the Project of Chengdu Science and Technology Bureau (2015-HM01-00525-SF).
HAN Luyi, born in 1995, M. S. candidate. His research interests include medical image processing.
HUANG Yunzhi, born in 1989, Ph. D. candidate. Her research interests include medical signal processing, medical image processing.
DOU Haoran, born in 1995, M. S. candidate. His research interests include medical image analysis.
BAI Wenjuan, born in 1982, Ph. D. candidate, associate senior doctor. Her research interests include dynamic evaluation of heart valve disease.
LIU Qi, born in 1966, Ph. D., professor. His research interests include machine vision, medical image processing, medical information.
