基于多特征的微博突发事件检测算法
2019-12-23王雪颖杨文忠张志豪李东昊秦旭
王雪颖 杨文忠 张志豪 李东昊 秦旭


摘 要:为了降低社交媒体中突发事件带来的危害,提出一种基于多特征的微博突发事件检测算法。该算法融合了文本情感过滤和用户影响力计算方法。首先,通过噪声过滤和情感过滤得到饱含负面情感的微博文本;然后,采用提出的用户影响力计算方法并结合突发词提取算法来提取突发词特征;最后,引入凝聚式层次聚类算法对突发词集进行聚类,从中提取突发事件。通过实验检测,准确率为66.84%,验证了该方法能有效地对突发事件进行检测。
关键词:突发事件; 用户影响力; 情感过滤; 突发词; 聚类
中图分类号:TP391.1
文献标志码:A
Microblog bursty events detection algorithm based on multifeature
WANG Xueying1, YANG Wenzhong1*, ZHANG Zhihao1, LI Donghao1, QIN Xu2
1.College of Information Science and Engineering,Xinjiang University, Urumqi Xinjiang 830046,China;
2.College of Software,Xinjiang University, Urumqi Xinjiang 830046,China
Abstract:
In order to reduce the harm caused by bursty events in social media, a multifeature based microblog bursty events detection algorithm was proposed. The algorithm combines text emotion filtering and user influence calculation methods. Firstly, the microblog text with negative emotion was obtained through noise filtering and emotion filtering. Then the proposed user influence calculation method was combined with the burst word extraction algorithm to extract the characteristics of burst words. Finally, a cohesive hierarchical clustering algorithm was introduced to cluster bursty word sets, and extract bursty events from them. In the experimental test, the accuracy is 66.84%, which proves that the proposed method can effectively detect bursty events.
Key words:
bursty topic; users influence; sentiment filter; burst word; clustering
0 引言
隨着近年来社交媒体的普及,人们交流和获取信息的便利性有了大幅度的提升,人们已经步入了一个全新的媒体时代。以微博为代表的社交媒体平台更是凭借其发布、分享、传播信息的便捷性,成为了大多数网民首选社交平台,据中国互联网络信息中心(China Internet Network Information Center, CNNIC)2018年第42次《中国互联网络发展状况统计报告》显示,至2018年6月30日,我国网民规模达8.02亿,而微博用户规模达到3.37亿,网民使用率42.1%,较去年年底增长率为6.8%[1]。
微博作为一个迅速兴起并基于用户实时获取、共享信息的平台,其日活跃用户数已达到了1.65亿。与传统新闻媒体相比,作为一种新型社会媒体,微博特有的短文本性、弱关系性和即时性等特点在信息传播中发挥了重要作用[2],网民们能第一时间在平台上获得自己感兴趣的信息。因此, 微博的舆情传播速度要远远快于传统媒体,逐渐成为了主要的舆论场所,如果某件受广大民众关注的事件对公共安全造成了危害,则会变成突发事件。为了及时在微博的海量信息中发现舆情并及时地对微博的言论进行管控和疏导,微博突发事件检测对社会稳定有着重要意义。
1 相关工作
有关微博舆论检测的研究,近年来受到了国内外广大专家学者的广泛关注。他们在微博事件检测的效率提升上都做了很多工作,其主要研究大致分为两类:
一是以微博文本为中心,Cui等[3]为了有效解决短文本中数据稀疏的问题,以LDA(Latent Dirichlet Allocation)为基础建模,提取文本中潜藏的主题信息。Lee等[4]将LDA与时间序列等特征进行结合,提高了单一的LDA检测模型的效率,但是LDA模型中涉及话题数量选择的问题,需要人工的干预,数值不同,对结果也会造成不同的影响。
二是基于突发特征为中心。在这类文本聚类的文章中, 首先对微博突发内容的特征进行提取,再对提取后的突发特征进行聚类,最后通过聚类结果提取突发事件:张鲁民等[5]通过对微博构建情感符号模型,判断出网民情感在大多数情况下能主导事件的扩散程度,突发事件的发生导致信息量的暴涨,网民的情绪也随之波动,因此对微博原文、评论内容进行情感分析,能够明显提高突发事件检测的精确度,但仅考虑情绪的变化特征并不够全面;郭跇秀等[6]通过分析用户行为特征,认为影响力大的用户能够更多地主导事件的扩散程度,通过结合突发词特征的抽取提出了一种基于用户影响力的计算方法来对突发事件进行检测,然而一些流量明星的博文也具有较高的影响力,因此并不能有效地排除;仲兆满等[7]认为突发事件具有地域突发特征,提出了一种基于网络地域的突发事件检测方法,然而这个方法会遗漏一些不具有地域突发特征的博文,如“范冰冰偷逃税”事件;Du等[8]引入了PageRank的算法来计算用户影响力权重,并结合了突发词特征来发现突发事件,该方法增加了用户对话题的影响力,但忽略了用户的一些信息,容易受到僵尸用户的影响。
基于以上分析,本文考虑了将通过用户特征的多个方面来计算得到每个用户的影响力权重,并结合情感过滤的方法来抽取突发词,然后引用凝聚式层次聚类算法对突发词进行聚类得到多个类簇,其中每一个类簇代表一个突发事件,并从中选取突发特征最高的博文来描述该事件。本文提出了一种基于用户影响力和情感过滤的方法模型来实现对突发事件的检测。最后通过实验检测对比,验证了该方法的有效性。
2 微博预处理
由于微博中有大量的无用信息,如用户的广告、日常生活等信息,这些信息会对突发事件的检测造成干扰。根据文献[9]爬取的话题微博数据显示,手机产品的微博中,垃圾微博占比高达70%。因此在突发事件检测前,需要对微博数据进行合理的预处理,去除噪声微博,保留有用数据,提高后续工作的效率和正确率。
2.1 微博噪声过滤
NLPIR(Natural Language Processing and Information Retrieval)分词系统,是由张华平博士多年科研工作累计的成果,其主要功能包括中文分词、英文单词分割、组合注释、命名实体识别、新词识别、关键词提取, 支持各种编码、各种操作系统、多种的开发语言和平台。本文采用NLPIR分词对去噪后的数据进行分词、过滤停用词等,后续采用一定过滤规则进一步过滤掉无用微博文本。
1)参考文献[10]过滤规则,在新闻领域中,有新闻六要素之说,即何时(When)、何地(Where)、何人(Who)、何事(What)、何故(Why)和如何(How),简称为5W1H。由于一般微博篇幅字数都比较小,分析认为如果微博要描述一个完整的突发事件,需要至少包含3个要素,即何人、何地、何事。
2)过滤粉丝数在某一阈值以下的用户。本文将不会对粉丝数接近于0的用户进行信息采集,他们其中一部分可能是平台生产出的僵尸用户,负责发大量的广告或成为水军,另一部分可能为只获取微博信息的不活跃用户,这些用户所发布的信息无法造成大面积扩散,因此删除这类用户所发布的微博信息,可以有效降低噪声干扰。
3)去除文本中URL连接、表情符号、英文等。
2.2 情感过滤
突发事件,在一定程度上指的是突然发生的,并且会对社会公共安全造成一定的危害的事件,文献[11]认为网民的情感是主导突发事件发生的催化剂,饱含负面情绪词较多的事件,成为突发事件的概率更大。情感倾向性分析主要有基于语义的情感词典方法和基于机器学习的方法[12],机器学习过滤需要耗费大量人力和时间,因此本文使用BosonNLP情感词典来得到每篇文档的情感值,每篇文档的情感值计算方法如式(1)所示:
Se(n)=∑wi∈positivepositive_word(wi)+∑wj∈negativenegative_word(wj)(1)
其中: Se(n)表示第n个文档的情感值;positive为情感词库中的正面词;negative表示情感詞库中的负面词;positive_word(wi)表示该文档中包含正面的情感词数;negative_word(wj)表示该文档中包含负面的情感词数。
3 突发词提取
文献[8]中对突发词给出了定义:突发词是指在某个时间窗内,若某一个实词被大量使用,且在之前的时间窗内很少被使用,则该实词被视为一个突发词。时间窗指每个独立的时间段。本文统一以1d为单位。文献[13]提出的老化理论,认为每个词都具有一个生命周期,即出生、发展、消退、死亡。
根据以上定义,本文将微博数据文本以天为单位划分成一个个单独的时间窗(可根据需求改变时间窗的大小)并提出了词的突发度计算方法,主要从词频、词频增长率、词权重、用户影响力来得到词的突发度。
1)词频增长率的计算。
因为明星效应,每天都会有粉丝为明星刷大量微博来制造话题,只从一个词在单位时间窗内出现的频率来定义一个词的突发度是不够全面的,因此本文计算一个词在单位时间窗内的增长率计算公式如式(2)所示:
Fi,k=SFi,k-SFi,k-11+SFi,k-1 (2)
其中:Fi, k表示词i在窗口k中的词频增长率;SFi,k表示词i在窗口k中出现的频率。当突发事件发生时,网民会创作或转发大量关于此事件的博文,因此某突发词的出现的频率也会增高,计算词的增长率能较好地体现一个词的突发度。
2)词权重的计算。
发生突发事件时,相关事件的微博数量会呈现爆发式增长,这也代表着微博中会大量出现描述同一事件的突发词,因此本文需要一种词语权重计算方式来描述这一现象。TFIDF(Term FrequencyInverse Document Frequency)作为用于信息检索与数据挖掘的常用加权技术,可以用来评估一个词在一篇文档或一个语料库中的重要程度。传统TFIDF算法主要运用在某个词在一篇文档中出现较多而在其他文档中出现较少的环境中,对于微博热点突发词的广泛分布情况,传统TFIDF算法表现较差。综上所述,本文采用文献[14]中的TFPDF词权重算法,该算法克服了原有算法对突发事件检测带来的缺陷,公式如式(3)、(4)所示:
Wj=∑c=Dc=1Fjcexp(njc/Nc)(3)
Fjc=Fjc∑Kk=1F2kc(4)
其中:Wj表示词语j的权重;Fjc表示词j在微博文档集c中出现的频率;njc表示在微博文档集c中出现词j的微博数;Nc表示文档集c中文档总数;k表示文档集中所有词数;D表示文档集c的总数。
3)用户影响力。
通常情况下,微博发送者的影响力会对其微博的扩散带来可观的影响,本文引入用户影响力概念来更加精准地定位突发事件,影响力的计算包含多个维度:粉丝量、更新速度、评论数、转发数等。综上所述,本文定义了用户U=(Rep,Com,Fan,Type,Update)。其中:Update为该用户一个月内微博更新数量,最小取1;Rep、Com为一个月内微博的转发数量及评论数量总和;Fan为该用户的粉丝数量;Type为用户的类型权重,官方微博取1、大V微博取0.7、普通用户取0.5。因此,考虑以上多个因素,提出了一种用户影响力计算方法,如式(5)所示:
Du=(Repu+Comu)×Fanu×TypeuUpdateu(5)
正如前文所述,在一个舆论平台上,如果一个用户受到的关注量越大,相应的,该用户的影响力也会越大,那么他所发表的言论中,包含突发词的博文是突发事件的可能性也越高。为了能更好地得到一个突发事件,本文将用户影响力与突发词特征进行结合,提出一个突发词的突发度计算方式,如式(6)所示:
wordj,t=1N∑t-1k=t-N(Wj,t×Fj,t×∑pn∈pj,tlb(Dpn)-Wj,k×Fj,k×∑pb∈pj,klb(Dpb)) (6)
其中:wordj,t代表词j在时间窗t内的突发度;Wj,t是词j在t时间窗内的权重;Dpn是包含词语 j的一条微博 pn 的发布者的影响力;pj,t是在时间窗t内包含词语 j 的所有微博;N是时间窗的总数。
4 突发事件检测
4.1 突发词相似度
突发词相似度计算方法建立基于上下文的词语共现分析的词语相似度计算方法。因此,为了计算两个突发词之间的共现性词语相似度,需要从语料中获取词语的上下文统计信息。词语共现相似度,即在一个规模庞大的语料库中,有两个词经常共同地出现在同一文档数据中,那么认为这两个词是相互关联的,而且随着这两个词共同出现的频率越高,就说明它们之间的关系越紧密。如“重庆公交坠江事件”中,“公交”“坠江”这两个词的语义没有相似度,但是根据本文的共现相似度分析,这两个词共同出现在多个博文数据的概率增加了,因此认为这两个词之间的关联关系也比较大。该方法的计算公式如式(7)所示:
Sim(wi,wj)=|{pn|pn∈Pk,wi∈pn,wj∈pn}| |Pk|(7)
其中:k为时间窗,本文以天为单位;wi、wj为两个突发词;Pk是时间窗k内的所有微博集;pn是时间窗k内包含突发词wi、wj的微博。
4.2 突发词聚类
使用一个正确的聚类算法是事件检测的关键步骤,本文采用凝聚式层次聚类。凝聚式层次聚类是一种自底向上的层次聚类方式,其会将样本集中的所有数据点都当作为一个聚类,计算每两个聚类之间的距离并将距离最近的两个聚类进行合并,重复上述步骤,当聚类结果中数据的合并到达一定的程度,就停止该聚类步骤,步骤终止的条件并不是固定的,可以适当性地调整聚合的阈值从而防止过度合并或确定最佳的聚类效果。
算法步骤如下所示:
输入 样本集合D,聚类数目或者某个条件(此为突发词集)。
输出 聚类结果(突发词聚类集)。
步骤1 将样本集中的所有的样本点(突发词)都当作一个独立的类簇。
步骤2 计算两两类簇之间的距离,找到距离最小min_distance的两个类簇c1和c2。
步骤3 合并类簇c1和c2为一个类簇。
步骤4 若min_distance小于阈值,返回步骤2;否则输出结果并结束。
该算法的缺点是计算量大、时间复杂度高。聚类结果中不同的类簇包含的突发词数也是不一样的,由于前文提到描述一个事件至少包含三个要素,即何人、何地、何事。因此本文过滤掉少于3个词的类簇,剩下的每个类簇则代表了一个事件。
5 实验结果与分析
本文利用新浪微博的API接口采集了2018年10月28日至11月4日约10万条微博数据,其中每条微博包含的信息有用户ID、用户信息、转发量、评论数、粉丝数、发布时间和博文内容。本文首先对采集到的数据进行预处理并以天为单位对数据进行划分,再根据突发词提取算法进行突发词识别得到突发词集,最后对突发词集聚类并根据聚类结果选取权重较高的几个突发词进行显示并提取相關且热度最高的一条微博来代表抽取的突发事件。
5.1 评价指标
本文采用准确率(Precision)、召回率(Recall)与 F值(Fmeasure)作为微博突发事件检测方法的性能评测指标,具体计算方法如式(8)~(10)所示:
Precision=B.correctB.output(8)
Recall=B.correctB.number(9)
Fmeasure=2*Precision*RecallPrecision+Recall(10)
其中:B.correct为系统中识别正确的突发事件个数,B.number为系统中事件总数,B.output为识别到的突发事件个数。
5.2 突发词抽取
在对微博文本进行预处理后,需要对文本中的突发词进行提取,前文根据提出的词的突发度计算公式得到了词的突发度,因此,最终选取突发度排名前100的突发词组成该时间段内的突发词集。
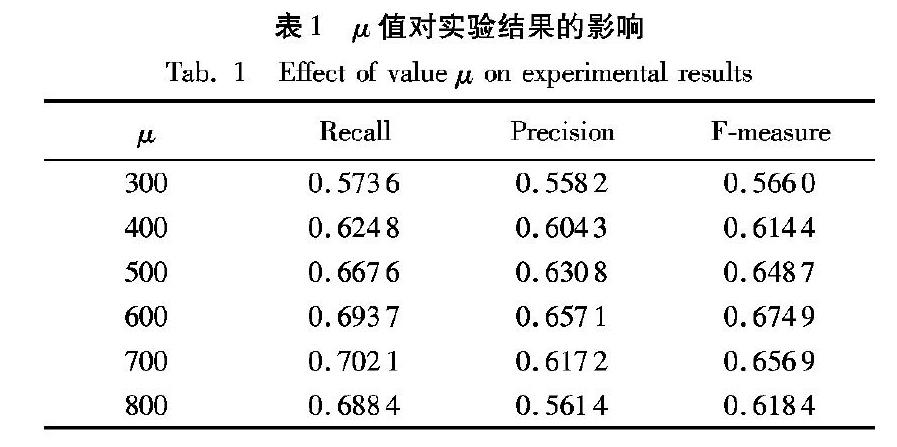
在突发词聚类中,簇间阈值μ分别取300~800不同的值进行检测,实验结果如表1所示。
可见,当μ取值为600时,此检测结果F值到达峰值,因此本文取μ=600对当前的数据进行突发事件检测,根据抽取到的事件簇,本文选取每个突发簇中热度最高的一篇博文来描述所代表的事件,微博的热度主要通过其转发和评论来决定,因此可以通过一篇微博的转发数和评论数来大致衡量一篇微博的热度:
微博热度=α×转发数+β×评论数
根据文献[15]考虑到微博转发的影响力大于评论的影响力,因此α、 β分别取0.6和0.4。
最后,本文根据每个事件簇的最高微博热度来对检测的事件进行排序,并选择用热度最高的博文来代表描述对应事件,如表2所示。
编号时间突发词对应事件
12018年10月28日重庆、公交车、碰撞、坠江、交通、相撞10月28日上午,重庆万州区长江二桥上发生一起交通事故,一辆大巴车与一辆轿车相撞后,冲破护栏掉入长江。目前尚不清楚大巴车上乘客数量,伤亡情况不明。
22018年10月28日高铁、女童、猥亵、父女【疑似#高铁上父亲猥亵女儿#:撩起她的衣服不停抚摸、亲吻】有网友称,G1402次高铁上,一名男子对一女童做出猥亵动作,并推测应该是父女关系……
32018年10月29日李咏、哈文、主持人、去世、癌症主持人李咏因癌症在美国去世,妻子哈文发文:在美国,经过17个月的抗癌治疗,2018年10月25日凌晨5点20分,永失我爱。
42018年10月30日金庸、武侠、去世、香港港媒报道,金庸先生于2018年10月30日下午在香港养和医院逝世,享年94岁……
52018年11月3日兰海、高速、收费站、兰州、交通、死亡央视消息,兰海高速兰州南收费站发生一起严重交通事故,一辆大货车失控,从收费站冲下连撞31车。目前已经造成11人死亡,31人受伤(11重伤)……
62018年11月1日高铁、霸座、黑名单、火车、信用【高铁霸座姐被列入黑名单 将限制乘坐所有火车席别】11月1日,国家公共信用信息中心公布10月份新增219人被限乘火车,其中高铁“霸座姐”出现在“黑名单”。
5.3 对比实验
实验一 与其他实验不同的是,本文是在基于突发词聚类的基础上,结合了用户影响力和情感过滤两方面的特征,为了验证算法的可行性,将从以下4个方面进行验证:
1)N_S。该模型仅考虑对突发词的聚类来提取突发事件。
2)S_S。该模型在对突发词聚类的同时,仅考虑了通过情感词集来进行情感过滤的特征。
3)U_S。该模型在对突发词聚类的同时,仅考虑了用户的影响力特征。
4)B_S。该系统为本文提出的模型,根据突发词的特征再结合用户影响力和情感过滤来提取突发词集,从而获取最终结果。
其实验对比结果如表3所示。
表3描述了各个模型的效果,整体上来看,N_S效果最差,B_S效果最好,但召回率要低于U_S,这是因为在进行情感过滤时模型只保留了负面倾向的数据来进行聚类。但是考量一个突发事件检测模型,不仅是覆盖范围要广,其准确率也要高,从Fmeasure中可以看出,B_S的效果是最好的。
实验二 为了进一步阐述本文方法的有效性,与各种方法对比效果,本文将文献[15]中根据突发词的词频、增长率、权重的排名来综合提取突发词集的方法和文献[16]中提出的TimeUserLDA的事件检测方法作为本文的baseline1和baseline2来与本文方法进行对比实验。表4详细列出检测出了根据各种方法检测到的突发事件前3个事件,表5描述了各个方法的检测效果对比。
从表4可以看出,baseline1和baseline2的检测结果中都含有非突发事件的热点事件,这些事件在当时虽然也会有较高的影响力,但并不能看作是一个突发事件。而从表5中可以看出,相比较baseline方法,本文方法在召回率、精确率和F值都有所提高,分析其原因主要有以下两点:
1)文献[15]在微博噪声过滤中只过滤了一部分无意义的博文,而本文方法是在此基础上,添加了文本情感过滤和用户影响力,使噪声对突发事件识别的影响降低。
2)而文献[16]中通过LDA模型对数据进行建模,再加入时间序列和用户信息来对数据进行突发事件的检测来提高检测效率; 而本文方法是通过突发特征来识别突发事件,具有一定的针对性,并根据用户信息和情感过滤进一步提高了检测效率。因此从检测效果上来看,本文方法具有一定的可行性。
6 结语
由于微博文本内容的简短性和实时性,本文对微博文本特征、传播特性作了分析,提出了基于用户影响力和情感分析的突发事件检测模型。从实验结果中可知,所提模型能够对突发事件有較好的检测能力;后续研究的发展和改进之处是继续提高突发词集检测的效率,及更加准确地对突发事件进行描述。
参考文献 (References)
[1] 中国互联网信息中心. 第42次中国互联网络发展状况统计报告[R].北京:中国互联网信息中心,2018. (China Internet Network Information Center. The 42th statistical report of China Internet development[R]. Beijing: China Internet Network Information Center, 2018.)
[2] 李洋,陈毅恒,刘挺. 微博信息传播预测研究综述[J]. 软件学报, 2016, 27(2):247-263. (LI Y, CHEN Y H, LIU T. Survey on predicting information propagation in microblogs[J]. Journal of Software, 2016, 27(2):247-263.)
[3] CUI L, ZHANG X, ZHOU X, et al. Topical event detection on Twitter[C]// Proceedings of the 2016 Australasian Database Conference, LNCS 9877. Berlin: Springer, 2016:257-268.
[4] LEE S, LEE S, KIM K. Bursty event detection from text streams for disaster management[C]// Proceedings of the 21st International Conference Companion on World Wide Web. New York: ACM,2012: 679-682.
[5] 张鲁民,贾焰,周斌,等. 一种基于情感符号的在线突发事件检测方法[J]. 计算机学报, 2013, 36(8):1659-1667. (ZHANG L M, JIA Y, ZHOU B, et al. Online bursty events detection based on emoticons[J]. Chinese Journal of Computers, 2013, 36(8): 1659-1667.)
[6] 郭跇秀,吕学强,李卓基. 基于突发词聚类的微博突发事件检测方法[J].计算机应用,2014,34(2):486-490. (GUO Y X, LYU X, LI Z J. Bursty topics detection approach on Chinese microblog based on burst words clustering [J]. Journal of Computer Applications, 2014, 34(2): 486-490.)
[7] 仲兆满,管燕,李存华,等. 微博网络地域Topk突发事件检测[J]. 计算机学报, 2018, 41(7):1504-1516. (ZHONG Z M, GUAN Y, LI C H, et al. Localized Topkbursty event detection in microblog[J]. Chinese Journal of Computers, 2018, 41(7):1504-1516.)
[8] DU Y, HE Y, TIAN Y, et al. Microblog bursty topic detection based on user relationship[C]// Proceedings of the 6th IEEE Joint International Information Technology and Artificial Intelligence Conference. Piscataway: IEEE, 2011:260-263.
[9] 姚子瑜,屠守中,黃民烈,等. 一种半监督的中文垃圾微博过滤方法[J].中文信息学报, 2016, 30(5): 176-186. (YAO Z Y, TU S Z, HUANG M L, et al. A semisupervised method for filtering Chinese spam tweets [J]. Journal of Chinese Information Processing, 2016, 30(5):176-186.)
[10] 王勇,肖诗斌,郭跇秀,等. 中文微博突发事件检测研究[J]. 现代图书情报技术, 2013(2): 57-62. (WANG Y,XIAO S B,GUO Y X,et al. Research on Chinese microblog bursty topics detection[J]. New Technology of Library and Information Service, 2013(2): 57-62.)
[11] 费绍栋,杨玉珍,刘培玉,等. 融合情感过滤的突发事件检测方法[J]. 计算机应用, 2015, 35(5):1320-1323. (FEI S D, YANG Y Z, LIU P Y, et al. Method of bursty events detection based on sentiment filter[J]. Journal of Computer Applications, 2015, 35(5): 1320-1323.)
[12] 马力,宫玉龙. 文本情感分析研究综述[J]. 电子科技, 2014, 27(11):180-184. (MA L, GONG Y L. Research on text sentiment analysis[J]. Electronic Science and Technology, 2014, 27(11):180-184.)
[13] CHEN C C, CHEN Y T, SUN Y, et al. Life cycle modeling of news events using aging theory[C]// Proceedings of the 2003 European Conference on Machine Learning, LNCS 2837. Berlin: Springer, 2003:47-593.
[14] BUN K K, ISHIZUKA M. Topic extraction from news archive using TF*PDF algorithm[C]// Proceedings of the 2002 International Conference on Web Information Systems Engineering. Piscataway: IEEE, 2002:73-82.
[15] 陈国兰. 基于爆发词识别的微博突发事件监测方法研究[J]. 情报杂志, 2014(9):123-128. (CHEN G L. Microblog Emergencies detection approach based on burst words distinguishing[J]. Journal of Intelligence, 2014(9): 123-128.)
[16] DIAO Q, JIANG J, ZHU F. Finding bursty topics from microblogs[C]// Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2012: 536-544.
This work is partially supported by the National Natural Science Foundation of China (U1603115, U1435215), the Xinjiang Uygur Autonomous Region University Research Project Innovation Team (XJEDU2017T002), the Natural Science Foundation of Xinjiang Autonomous Region (2017D01C042).
WANG Xueying, born in 1995, M. S. candidate. Her research interests include natural language processing.
YANG Wenzhong, born in 1971, Ph. D., associate professor. His research interests include public opinion analysis, information security, machine learning.
ZHANG Zhihao, born in 1995, M. S. candidate. His research interests include early warning of emergencies, information security.
LI Donghao, born in 1994, M. S. candidate. His research interests include natural language processing.
QIN Xu, born in 1994, M. S. candidate. Her research interests include natural language processing, public opinion analysis.
