基于文档分层表示的恶意网页快速检测方法①
2019-12-20林金芳
袁 梁,林金芳
1(无锡城市职业技术学院 师范学院,无锡 214153)
2(国防科技大学 系统工程学院,长沙 410073)
当前,利用恶意网页的攻击非常普遍.360安全报告指出,2018年上半年,360互联网安全中心共截获各类新增恶意网页1622.6万个,同比2017年上半年(201.5万个)上升了7倍[1].如何有效识别这些恶意网页面临多种挑战:首先检测方法必须在用户无感的情况下运行;其次检测方法必须能够识别恶意网页以躲避检测为目的的各种代码混淆技术;最后检测方法必须能够在海量的Web网页访问中,快速找出嵌入在正常网页中的恶意代码片段[2].
为了应对这些挑战,本文提出了一种基于深度学习的恶意网页快速检测方法,使用简单的12个字符正则表达式标记化Web内容,然后在多个分层空间尺度上检测这些内容.分层空间尺度是指不是简单地将整个HTML文件上的令牌(token)集合作为输入,而是计算令牌集合在多个本地特定子区域上的表示:将HTML文件分成1/2、1/4、1/8和1/16,然后在这些层级上运用两个全连接层(fully connected layer)来提取这个HTML文件的表示.该方法基于简单的令牌流输入来学习Web内容的高质量表示,可以从任意长度的网页中快速找到微小恶意代码片段.
1 相关工作
恶意网页检测研究工作的一个重点是仅使用URL字符串来检测恶意Web内容.文献[3]基于黑名单的方法,首先对恶意URL进行标注,然后利用字符串匹配等技术实现恶意URL的识别;文献[4]以URL词汇特征和主机特征为基础建立统一的分类模型,进而根据已有标注集合识别恶意URL,他们专注于人工标注来最大化检测精度;文献[5]使用URL作为检测依据,但也包含其他信息,例如Web链接中的URL引用,将手工提取特征作为SVM和K-最邻近分类器的输入.但是这些方法只关注URL相关信息,因此无法利用Web内容中的恶意语义.虽然基于URL的系统具有轻量级的优势,并且可以在没有完整Web内容的环境中进行部署,但本文的工作重点是HTML文件,因为它们能检测出更深层次的威胁.
文献[6-8]尝试从HTML和JavaScript中提取特征并将其提供给机器学习或启发式检测系统来检测恶意Web内容.文献[6]提出一种基于机器学习分类器的网页恶意代码检测方法,通过分析JavaScript脚本本身特征,来检测网页恶意JavaScript脚本;文献[7]提出一个Web网页抓取器,用于JavaScript反混淆和分析,再将全部抽取的JavaScript代码用自定义的基本词表示,然后利用3种机器学习算法通过异常检测模型检测恶意网页;文献[8]提出一种手动定义的启发式方法,使用静态特征提取来检测恶意HTML文档.这些方法与本文的研究类似,不同之处在于,本文使用无解析器标记化方法来计算HTML文件的表示,而不是显式地解析HTML,JavaScript或CSS,甚至模拟JavaScript的执行.Web内容的无解析器表示允许对恶意文档和良性文档的语法和语义做出最少量的假设,从而使深度学习模型在学习Web内容的内部表示方面具有最大的灵活性.
在Web内容检测之外,国内外学者在基于深度学习的文本分类领域做出了广泛的研究.例如,文献[9]提出的单层卷积神经网络(CNN),使用无监督(Word2Vec)序列和词嵌入(word embedding)序列,在句子分类任务中,可以提供良好的性能;文献[10]对使用单层CNN进行文本分类所需要的超参数进行调整,进一步优化模型性能;文献[11]的模型则表明在文本分类问题上,直接从字符输入中学习表示的CNN方法更具竞争力.本文的工作涉及了这些方法,但不同之处,本文模型是运行在HTML、JavaScript和CSS多种格式混搭的HTML网页上,这些格式中可能包含任意源代码、攻击负载和自然语言.由于HTML文件内容的不确定性使得定义离散词汇变得相对困难,因此本文不使用词嵌入作为模型输入,相反使用简单的、格式无关的标记化方法对Web文档分层表示.
2 模型设计
2.1 设计原则
本文模型是基于恶意网页检测的下述特殊性提出的:
(1)恶意内容片段通常很小,但HTML文档的长度差异非常大,这意味着恶意内容在HTML文档中的长度比例是可变的.因此需要模型在多个空间尺度上检查文档,以识别给定文档是否是恶意的.
(2)HTML文档的显式解析实际上是HTML、JavaScript、CSS和数据的执行,这是不可取的,因为这可能需要高计算开销,并且在检测器内打开攻击面,存在被攻击者利用的可能.
(3)JavaScript的仿真执行、静态分析或符号执行也不可取,因为同样存在增加计算开销和在检测器内打开攻击面的可能.
基于上述问题,模型设计遵循了下述原则:
(1)模型不对HTML文档执行详细解析、静态分析、符号执行或内容模拟,而是对文档组成格式做最小假设,进行简单的词袋样式标记,本文称为令牌袋(Bag of Token,BoT).
(2)模型在代表不同区域和聚合层级的多个尺度空间上捕获局部性表示,而不是简单地将整个文档以单层的令牌袋表示.
2.2 设计方法
模型涉及一个特征提取器,负责从HTML文档中解析出一系列令牌(token);一个神经网络模型,包括两个逻辑组件.
(1)检查员:在分层空间尺度上应用共享权重(shared-weight),并将文档的信息聚合成1024长度的向量.
(2)主网络:对检查员的输出做出最终的分类决策.
(3)特征提取器:首先,使用正则表达式([^x00-x7F]+|w+)+)对目标文档进行标记,它将文档沿非字母数字字边界进行分割.然后将得到的令牌流划分为16个相等长度的连续块,其中长度定义为令牌数,如果文档的令牌数量不能被16整除,则最后一个块中的令牌要少.标记化和分块功能系统实现的Python代码函数TokenizeChunk如下.

接下来,使用函数TokenizeLengthHash,它利用一个修改过的hashing trick,使用1024个bin,为每个块创建令牌袋.


整个流程的结果是,先将HTML文档标记,再将得到的令牌集合分成16个相等长度的块,然后将每个块散列到1024个bin中,得到一个16×1024 tensor,表示从HTML文档中提取的令牌袋序列,其中序列中的每个元素表示输入文档的连续1/16上的聚合.
(4)检查员组件:检查员负责将提取的特征表示输入到神经网络中.如图1所示,第一步,创建一个层级表示令牌序列,在这个层级中,先将最初的16个令牌袋折叠成8个令牌袋,再将8个令牌袋折叠成4个,4折叠成2,2折叠成1.这样就在多个空间尺度上获得了多个令牌袋,用于捕获令牌的出现.整个折叠过程的平均窗口长度为2,步长为2,直到递归得到一个令牌袋.采用平均而不是求和的方法,对于给定文档保证了每个表示级别的范数相同.

图1 检查员组件逻辑
一旦检查员创建了这种分层表示,它就会继续访问聚合树中的每个节点并计算输出向量.检查员是一个前馈神经网络,有两个完全连接的层,每个层有1024个ReLU单元.本文使用layer normalization[12]来防止梯度弥散,使用dropout[13]规范化检查员,dropout=0.2.
在检查器访问每个节点后,为了计算1024维向量输出,模型从1024个神经元中获取最大激活,其结果是用最后一个层中的每个神经元的最大输出表示文档的最终向量.简单地说,这将增强输出向量捕获模式,因为这些模式最好地匹配了用于预测恶意内容的已知模板特征,无论它们出现在文档中的什么位置,或者整个文档有多长.
(5)主网络组件:一旦检查员计算了目标文档的1024维输出向量,向量就被输入到模型的主网络中.如图2所示,主网络也是一个前馈神经网络,有两个完全连接的层,在每个完全连接的层之前是layer normalization和dropout,与检查员的一样,dropout=0.2.

图2 主网络组件逻辑
模型的最后一层由26个Sigmoid单元组成,对应于对文档做出的26个检测决策.其中一个Sigmoid用于确定目标文档是恶意的还是良性的,其余25个Sigmoid检测各种信息标签,用于确定文档的恶意软件家族归属,例如确定文档是网络钓鱼网页还是漏洞利用工具包.为了训练模型,本文在每个Sigmoid输出上使用binary-cross-entropy损失函数,然后平均得到的梯度以计算参数更新.模型强调评估良好与不良Sigmoid输出的准确性,但也考虑了模型输出的性能.
3 实验
本文的目标是创建一个可以运行在端点、防火墙和Web代理上的快速Web内容检测模型.模型的准确性和速度是主要考核指标.
本文以两种方式测试了上述模型的准确性.首先它与其他词袋模型进行了比较,这些基线模型代表了标准的文档分类方法,其次以各种方式修改了模型,以测试模型设计的合理性.
本文没有直接给出实验用例测试模型的速度.分层尺度空间模型涉及网页内容的解析,但同涉及Web内容解析或仿真执行的其他方法比较,40万个网页的检测耗时仅为这类WAF产品的30%,速度优势明显.
3.1 实验数据
实验数据集来源于360公司的NGSOC和TIP平台.360公司全球化布控的探针每天接收数万个新的HTML文件,使用60个Web威胁扫描程序扫描它们.实验数据集是平台2018年前9个月推送的数据,如图3所示.
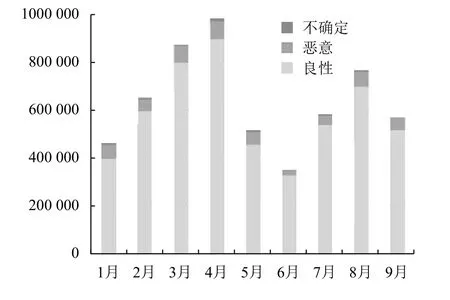
图3 实验数据集
HTML文件基于SHA256进行唯一标识.训练/测试集的拆分依据文件的首次推送时间来计算.这可以确保:一是训练和测试集是不同的(因为稍后提交的相同HTML文件将解释为重新推送该文件,会选择忽略);二是训练和测试实验更加接近实际部署场景.
标记策略是将良性HTML文件定义为全部扫描器判断为正常的文件,即0威胁,将恶意文件定义为3个或更多扫描器判定为威胁的文件.因此实验丢弃了1到2个扫描器判定为威胁的文件,因为这一小部分检测意味着安全行业仍然无法确定它们是恶意的还是良性的.从图2中可以看出,这些不确定的文件占整个文件集很小的一部分.
这种标记方法存在风险,即模型简单地记住了360产品的知识,而不是学习真正新颖的检测功能,以检测360可能错过的未知威胁.因此在实验中,本文使用了历史模拟法(historical simulation),定义如下:
(1)在360首次推送的某个时间点t之前Web内容文件上训练模型.
(2)在时间点t后两个月内首次出现的Web内容文件上测试模型.
此方法弥补了模型检测未知威胁能力不足的问题,这是因为测试的文件在训练中从没有出现过,但是360有时间通过检测规则和黑名单更新来检测新的威胁.换句话说,只要模型能够正确预测未来Web内容的标签,360就有时间将黑名单或检测规则更新,从而间接证明本文模型具备检测0-day威胁的能力.
另外,本文还手工检查了标记为良性的,但模型却显示具有很高恶意概率的样本,最终发现大多数误报是垃圾内容,后面会详细讨论.
3.2 实验设置
为了评估分层尺度空间模型的性能,本文进行了4个实验.其中对比实验将本文模型与其他基线模型进行了比较,对比实验中涉及的神经网络模型,模型训练采取Adam优化算法、batch_size=64,以及基于验证集的早停法.2个对比实验设置如下:
FF-BoT:一种前馈架构,使用本文模型提取的令牌作为输入,但是将其散列为16 284长度向量.因为它与本文模型中使用的16×1024表示具有相同的维度,因此近似于逐个比较.FF-BoT提供了一个简单的深度学习词袋基线与本文模型进行比较.
XGBoost-BoT:使用与FF-BoT相同的特征输入的梯度提升决策树(XG-Boost)模型.
另外本文还对分层尺度空间模型进行了修改,以确定模型内部流程的合理性.2个修改实验如下:
HIM-Flat1:模型的变体1,删除了平均池化步骤,这样检查员只能看到树的叶节点.换句话说,在输入冠军模型的31个聚合表示中,该模型只能看到16个连续的块,而没有更大的聚合窗口.此实验用于对比在分层空间尺度上检测HTML文档的性能增益.
HIM-Flat2:模型的变体2,一个简单的前馈神经网络,它使用与分层尺度空间模型相同的特征表示.但是,它不是在每一步都应用共享权重检查,而是简单地将16×1024连续的令牌向量光栅化为单个16 284长度的向量,并将其输入到前馈神经网络中.该实验评估了模型相对于只在第一层密集使用共享权重检查的性能增益.
4 实验结果
图4(a)和图4(b)给出了实验结果的ROC曲线,y轴表示TPR真阳率,x轴表示FPR假阳率.图4(a)将FF-BoT和XGBoost-BoT与本文模型进行了比较,图4(b)将修改模型与完整模型进行了比较.

图4 实验ROC曲线对比图
图4(a)的ROC曲线显示本文模型要优于其他基线模型.以0.1%的FPR比较这些模型的相对性能,本文模型、FF-BoT和XGBoost-BoT分别达到96.4%、94.5%和94.1%的检测率.根据FPR,本文模型实现了3.6%的假阳率,而FF-BoT和XGBoost-BoT大约是5.5%和5.9%.总体来说,分层尺度空间模型的整体ROC曲线明显优于FF-BoT和XGBoost-BoT.
另外FF-BoT参数(约2000万)远远超过本文模型(约400万),相对于本文模型表现不佳.这表明本文模型捕获了更有效的恶意HTML文档特征表示,这要归功于检查员在分层表示中检查的每个空间上下文中使用相同的参数.
图4(b)的ROC曲线显示在0.1%的FPR前提下,HIM-Flat1和HIM-Flat2变体的检测率均达到93.5%.变体模型的ROC曲线明显差于本文模型.与HIMFlat1的对比实验表明在多个空间尺度上检查内容对于获得良好的准确性至关重要.类似地,与HIM-Flat2的对比表明,检查员在检查每个空间上下文和尺度时使用相同的参数对于产生高检测精度的重要性,因为HIM-Flat2对每个空间上下文使用单独的权重,从而得到更差的结果.
为了更好地理解分层尺度空间模型学到了什么,本文采用了恶意软件家族标签来细分恶意样本.基于0.1%的全局误报率阈值,分层尺度空间模型的总体检测率为96.4%,并根据预设的恶意软件家族对检出文件进行了归类.表1中的显示表明,本文模型在代码注入XSS,浏览器漏洞利用和iFrame劫持方面取得了理想的检测效果,但在钓鱼网站上的检测率不高.由于一个恶意文件可能同时属于多个家族,故表中的百分比总和要大于100%.
另外,本文还检查了模型与360公司标签不一致的情况,证明模型实际上已经检测到360错过的未知恶意Web内容.为进行这项分析,本文检查360公司标记为良性验证集中排名前20的评分测试示例,发现20个中的11个实际上是恶意的或有潜在威胁的,9个是误报.恶意文件中的3个是来自网页内容拦截器的警报页面,本身不是恶意但表示恶意警告;3个是恶意伪装JQuery库,1个是释放svchost.exe木马文件到磁盘的Javascript,1个是页面点击劫持,1个是包含下载者执行代码的页面,2个是垃圾广告邮件.该分析验证了模型能够超越标签噪声并识别未知的恶意内容.
5 结论
本文的工作与大多数基于深度学习的文档分类(如情感分类)不同,本文设法捕获试图逃避检测的恶意行为,而情感分类句子作者并不隐藏他们表达的情绪.此外,本文避免使用原始字符序列作为模型的输入,因为HTML文档的长度使得涉及原始字符串的卷积神经网络在端点和防火墙上难以处理.本文模型采用纯粹基于令牌的静态检测方法,避免了复杂解析或仿真系统的需求,能有效处理Web页面的检测问题,而不管Web页面的大小如何变化,以0.1%的误报率实现96.4%检测性能,甚至可以识别以前未被安全产商捕获的恶意Web内容.模型良好的速度和准确性使得其适合部署到端点、防火墙和Web代理中.
