基于机器学习的煤矿突水预测方法①
2019-12-20谢天保
童 柔,谢天保
(西安理工大学 经济与管理学院,西安 710054)
1 引言
随着我国能源行业的不断发展,煤矿突水问题越来越成为大众值得关注的问题,这不仅关系煤矿工人生命安全,也关系着国家人力财力损失.据统计,在2006-2016年期间,我国煤矿突水事故共发生440起,死亡682人[1],因此为了减少突水事故的发生以及人员的伤亡,对煤矿是否会突水进行提前的预测显得越发重要.
目前煤矿突水预测方法包括很多种,大多以神经网络为主[2-6],这种方法针对突水量定量预测误差较大,针对是否突水定性预测时,开关量阈值需要靠专家经验确定.而在构建模型前进行关键因素的选择也是很重要的一个步骤,文献[7]使用层析分析法的一致性检验与专家评分来进行特征的选取,主观性强,受限于专家的经验.文献[4]使用主成分分析进行降维,主成分降维后的特征相互独立,在一定程度上可以提高模型预测精度,但对特征重要性的分析不够明确,难以应用于现实问题中煤矿突水特征因素的选择.文献[7,8]首先通过理论分析确定了含水层(包括厚度、水压及富水性)、底板隔水层厚度、地质构造等相关因素,并通过各特征数据统计分析说明,这些特征的重要性,然后建模预测,然而煤矿突水是由煤矿生产开采过程中各种复杂的因素综合作用的结果,各特征的独立分析并不能体现各特征相互作用,相互影响的煤矿突水机理.
基于以上分析,本文在理论分析(煤矿构造条件、含水层条件、开采条件、岩性组合条件)的基础上,收集样本数据.然后采用稳定性选择的特征方法针对数据样本进行分析,以预测准确率为目标对煤矿突水影响因素进行筛选,获取与之相关的关键因素,之后采用3种典型机器学习算法,随机森林、神经网络以及支持向量机分别进行煤矿突水预测模型的构建,结合3种模型的预测结果确定最终结果,以此验证特征选取后的预测模型的准确率以及稳定性,通过实验可帮助煤矿工作人员减少数据收集的工作量以及收集成本,并且提高突水预测精度.
2 煤矿突水影响因素关键特征选取
常用的特征选择方法主要分为3种:过滤法、包装法和嵌入法[9],根据不同的情境及目的所使用方法也不同,而在本次试验中,将采取包装法中的稳定性选择方法来进行特征的选取.
2.1 稳定性选择
Meinshausen N等人在2009年提出了稳定性选择这种特征选取的方法[10],并指出其并不是一种新的算法,而是基于Lasso特征选择方法并对其进行加强和改进.具体来说,稳定性选择是一种基于二次抽样和选择算法相结合的特征选取方法,选择算法可以是支持向量机SVM或者回归等算法,而二次抽样意味着不是使用所有的数据一次性选择出最重要的特征,而是抽取数据子集以及特征子集来运行选择算法,不断重复,最终可以计算出每个特征作为重要特征出现的频率,即使用出现的次数除以子集被测试的次数,将其看做每个特征的得分并作为特征筛选的依据.最重要的特征若每次都被选到,则它的得分会高达1,而最不重要的特征最终得分将会为0.大多数实验证明,相对比于其他的特征选择方法,稳定性选择是性能最好的方法之一.
2.2 数据准备
煤矿突水机理具有多样性,是指在不同的地质及水文地质条件下,采用破坏或水压破坏表现出不同的空间组合特征,突水机理的多样性反映了地质及水文地质条件的变化,煤矿突水是否突水受制于诸多因素的综合影响[11].在本次实验中,我们通过查阅资料以及煤矿专家的帮助,共取得了包括构造条件、含水层条件、开采条件、岩性组合条件4个方面的相关影响因素,再加上突水征兆这个因素,共获得22个与煤矿突水有关的影响因素以及其所对应数据数据类型,如表1所示,并且收集与表1中22个煤矿突水相关因素以及突水结果所对应的数据1056例.

表1 煤矿突水相关因素及数据类型
2.3 基于稳定性选择的特征选取
在Python的sklearn.liner_model库中Randomized LogisticRegression(以下缩写RLR)实现了稳定性选择,因此根据1.1中的相关分析,可以使用其作为特征选择的工具.在RLR中,稳定性选择的实现主要有以下步骤:
Step 1.对初始数据进行二次抽样,随机选取k个特征以及对应m行数据,统计每个特征被选次数N;
Step 2.使用所选数据构建逻辑回归模型;
Step 3.对模型进行L1正则化,稀疏化数据使大多数不重要特征的权重变为0,最终筛选最重要特征,统计每个特征被选为最重要特征的次数n;
Step 4.继续进行Step 1,RLR算法默认共构建200个逻辑回归模型,直到模型构建完成进行下一步;
Step 5.计算每个特征被选为重要特征的频率,即进行稳定性选择之后各特征的得分,score=n/N,通过scores_属性来获取每个特征的得分,获得高分的特征就是所需选择的重要特征.
在使用RLR算法进行建模时,其正则化参数C会影响最终各个特征的score,为了获取合适的正则化参数,我们在(10-2,102)区间内取了100个C值进行建模,计算出每个模型中各特征的得分情况,以此绘制了如图1所示的正则化参数C与各个特征score之间的关系.

图1 正则化参数C与score的关系
由图1中可以看出,随着正则化参数C的减小,即相当于正则化强度的增大,各个特征的得分都将趋于0,而在C约为0.18时,所有特征的得分都为0,也就是没有特征被选为重要特征,本实验的目的是筛选出7个重要特征,因此合适的C值是使得7个特征得分不为0.
实验发现当C=1.6681时,最重要的7个特征的得分不为0,其他特征得分都为0,因此使用此C值进行RLR建模进行特征选取,将每个特征的得分从高到低进行排列后得到如下的表2,从表中很明显能看出来断层充水对煤矿是否突水影响最大,得分为1.0,说明在每次进行特征选择时,断层充水都会被选为最重要的特征,在断层充水之后,突水征兆对煤矿突水也有较大影响,其次是裂隙带充水、陷落柱、陷落柱充水、含水层水压和裂隙带.7个特征选取出来后,继续增加影响因素数量进行实验后发现,预测准确率没有发生变化,这说明可以继续增加因素的数量,但因素数量过多会导致预测时计算成本过高,收集数据时工作量变大,因此此处仅选择7个最重要特征.但此次实验结果仅针对已收集到的数据,有新的数据增加时,还需再进行实验来验证结果是否发生变化.

表2 重要突水因素及其得分
根据《矿区水文地质工程地质勘查规范》提出,与煤矿突水最相关的两个因素为断层充水以及含水层水压,文献[4]中根据PCA方法所筛选出的因素为断层、构造、含水层等,文献[12-14]通过调查分析提出影响煤矿突水重要因素主要有断层、陷落柱、水压,由此可以看出本次实验所筛选的关键因素符合煤矿突水的整体研究.
3 实验分析
经过1.3中的特征选取,我们确定了与煤矿突水相关的7个重要的影响因素,为了确定这7个因素对于预测结果的准确率是否有提高以及算法的稳定性,本次实验使用随机森林、神经网络以及支持向量机3种典型机器学习算法构建煤矿突水预测模型,使用特征选取前后的数据进行建模,对比预测准确率.
3.1 数据处理
由表1(见2.1节)可以看出煤矿突水样本数据特征有离散型、连续型2种.离散型数据的数据类型为逻辑数据(以陷落柱充水为例,若充水则为1,若无则为0),连续型数据则是使用浮点型数据类型来表示具体的数字.因此在使用神经网络以及支持向量机进行建模前需要对数据进行处理,对于离散型数据需使用独热编码,而连续型数据由于不同特征的值大小差别太大,因此需要进行标准化处理将数据缩放到相同的区间以提高准确率.
数据处理完成后,使用Python中train_test_split函数随机将数据集划分为训练数据集和测试数据集,函数的第3个参数test_size用来设定测试集数据的多少,本实验将设定test_size=0.3,即1056例数据随机选取70%为训练集数据,其余30%为测试集数据.
3.2 煤矿突水分类预测算法分析
(1)随机森林是由许多CART二叉树所组成的预测模型,其中每一棵二叉树是通过随机选取的特征以及训练数据集建立的,因此每一棵二叉树都是没有关联的并通过计算基尼指数来选择属性进行建立,对于每一组测试数据,每一个二叉树都进行预测,最终通过投票机制得出最终的分类预测结果.随机森林相当于一个特殊的集成学习算法,它是由许多个弱的分类器即CART树所组成的一个强分类器,因而预测准确率较高.
(2)神经网络是一种有监督学习方法,其结构分为输入层、隐藏层和输出层.在进行训练的过程中,主要分为2个部分:正向传播和反向传播.正向传播过程是在输入层进行特征属性的输入,并设置神经元之间的权值,通过若干隐藏层进行前向计算,获得每个神经元的输出.反向传播过程是将正向传播计算的结果与真实结果进行对比,进而反向计算调整权值和误差,反复进行调整,提高模型准确率.
(3)支持向量机(SVM)也是一种有监督的学习方法,在二分类问题中使用较多,对于线性可分问题,支持向量机运用优化算法实现最大化分类间隔;而对于非线性问题,支持向量机通过适当的核函数将输入空间映射到高维空间,实现高维空间线性可分,将非线性问题转化线性问题[15],然后在新空间中利用二次型寻优算法寻找一个最优超平面将两类样本分开,保证分类准确率.
3.3 煤矿突水预测模型的构建
(1)随机森林模型使用RandomForestClassifier来建立模型,参数n_estimator设置为100,即随机森林中共建立100个决策树进行预测;参数max_depth设置为4,即决策树深度最大为4,实验中对决策树进行可视化后发现,当决策树深度为4时,所有数据基本上已经分类完成,且准确率高,因此可将决策树深度减小来提高预测效率.
(2)神经网络将使用MLPClassifier来建立模型,参数hidden_layer_sizes设置为(50,50),即设置两层隐藏层且每层神经元个数为50,在特征选择后其设置为(15,15),这是因为输入层神经元个数不同,隐藏层相应需要改变;参数slover权重优化的求解器使用“lbfgs”,它对于小型数据集可以更快的收敛并且分类表现更好.
(3)支持向量机将使用SVC来建立模型,惩罚参数C通过循环建模发现当C小于0.4,预测准确率将会降低,因此设置为C=0.4,参数kernel通过实验得出使用‘linear’线性核函数分类更准确.
使用3种模型的fit方法分别对特征选取前后的训练数据进行训练,之后使用训练好的模型对测试数据进行预测,从而得到表3中的预测结果对比.
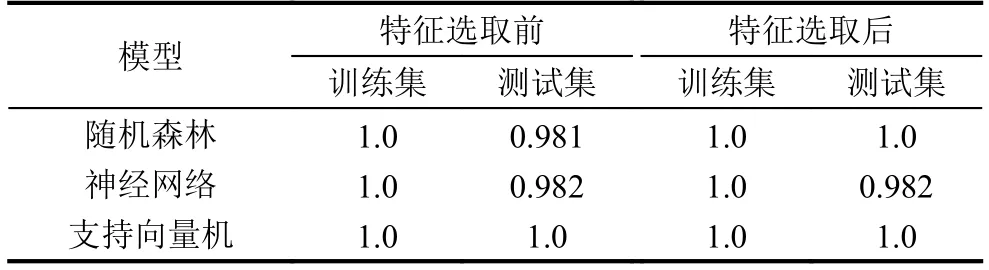
表3 特征选取前后预测准确率对比
从表3中可以看出在特征选取前后3种模型预测准确率都很高,随机森林模型在特征选取前后训练集准确率都高达100%,而测试集在特征选取后准确率提高至100%,神经网络模型和支持向量机模型在特征选取前后训练集以及测试集的准确率虽然都没有变化,但整体准确率很高,可以看出,支持向量机模型是三者中最优的,所有准确率都达到100%.随机森林在进行预测时,由于在构建模型时已进行了剪枝,从而减少了拟合且预测速度相对较快,准确率较高;使用神经网络进行分类时,由于神经网络需进行反复调整权重,因此其模型构建速率相对较慢,使用神经网络模型预测的分类结果实际上是连续性的,通过判断其是否大于0.5决定预测结果为1或0,即突水或不突水,这种阈值判断的方法使得预测结果相对较差;使用支持向量机进行模型构建时,由于需要调整的参数较多,因此在构建模型时时间较长,但一旦选择正确的核函数之后,其泛化能力会达到最佳,预测准确率高.
在此基础上,本实验继续使用交叉验证方法对特征选取的正确性进行检验,使用cross_val_score方法对3种模型都进行交叉验证,取参数cv=15,即进行15轮的交叉验证,取15次预测准确率的平均值,实验结果如表4所示.由表中可以看出,特征选取后准确率有些许提高,没有达到100%是因为15次交叉验证中14次预测准确率达到1,而仅有一次未达到1,由此可以看出利用选择后的特征建立预测模型准确率较高.

表4 特征选取前后交叉验证结果
为了进一步确定特征选取后3种预测模型的稳定性,我们绘制了3种模型的ROC曲线来评价模型性能,如图2所示.

图2 特征选取后各预测模型ROC曲线
从图中可以很明显看出,图2(a)随机森林和图2(c)支持向量机模型都很稳定,训练集以及测试集的真正类率和假正类率都达到最优,而图2(b)神经网络模型相比下来略有不足,但稳定性也算比较好.
由此可以看出在进行特征选择后,预测模型仍然非常稳定,因此可以证明在第2节中所筛选影响煤矿突水的预测模型都很稳定,由此得出实验所筛选的关键因素在进行煤矿数据收集时是可进行参考的.
4 结论
本文通过稳定性选择的特征选取方法筛选影响煤矿突水结果的关键因素,并通过随机森林等3种典型分类预测模型对选取前后预测准确率进行对比,发现准确率都很高并且随机森林以及支持向量机模型达到100%,通过ROC曲线的绘制也可看出特征选取后的关键因素是可取的.
