基于C3D的足球视频场景分类算法①
2019-12-20马汉杰许永恩
程 萍,冯 杰,马汉杰,许永恩,王 健
(浙江理工大学 信息学院,杭州 310018)
引言
随着网络技术的普及、多媒体信息的爆炸性增长、社会生活节奏不断加快,人们往往没有足够的时间观看整段视频节目,而是希望根据自己的需求观看特定的部分.足球作为全球最受欢迎的一项体育运动,有着广泛的收看群体.足球比赛的持续时间较长,人们感兴趣的内容却是不同的,有人喜欢看精彩镜头(射门、点球等),有人喜欢看中场配合.然而,面对海量的视频数据,依靠传统人工剪辑分类方式,不仅极大地浪费人力资源而且也不能保证工作的及时性与可靠性.
目前,足球视频的场景分类面临的主要问题包括:场景切换检测的查全率和查准率不够高,无法满足实际需求,其次,在人工制定足球语义方面,需要耗费大量的人力资源.为了解决上述问题,国内外学者进行了系统、深入的研究,并取得了一定的成果.
在解决场景切换检测准确率问题上,陆思烨等[1]提出基于双阈值灰度直方图的场景检测算法,通过比较相邻帧的灰度直方图差与高低阈值的大小,针对场景可能的渐变情形,比较非相邻帧的直方图差与高低阈值的大小来判断是否发生了场景切换.方宏俊等[2]结合数字电视图像处理芯片中硬件算法设计的低复杂度要求,介绍了一种基于动态阶数控制直方图分布的场景检测优化设计算法.孙桃等[3]对动画帧图像分块并提取其 HSV颜色特征,然后将连续帧的相似度存入一个固定长度的缓存队列中,最后基于动态 Bayesian 决策判定是否有场景切换.段淑玉等[4]提出一种应用于帧率提升系统的,根据内插帧各匹配块的均值SAD为检测依据的场景切换检测算法,解决场景切换时ME/MC算法因匹配失误产生严重块效应的问题.
语义方面,早期的场景分类研究中,文献[5,6]是基于图像特征的,即通过描述颜色、纹理和形状等底层特征来实现分类.之后,用融合多种特征的方法来描述不同内容的图像场景,Naveed等[7]利用混合特征进行训练以预测人类活动.他们使用HOG、SIFT、LBP等作为训练系统的特征集.Kang等人[8]在对视频底层特征分析的基础上,提取音视频关键字作为中级特征,基于隐马尔科夫模型来检测精彩视频片段.Ekin等[9]通过提取视频的中低级特征,提出了一种有效的足球视频摘要生成框架,能够生成慢速运动、进球和基于对象特征分类的慢速运动3类摘要.文献[10,11]结合网络直播文本对体育视频事件进行检测,实验表明检测到的事件类型更加丰富,准确率也得到较大提升.但网络直播文本的获取和文本事件与视频事件的对齐是此方法的关键和难点.于俊清等[12]利用足球比赛中观众情绪波动情况,建立情感激励曲线并对曲线尖峰进行检测,但基于尖峰检测误差较大,检测性能无法满足实际需要.
相较于传统的场景分类方法,文献[13]利用卷积神经网络(Convolutional Neural Network,CNN)进行场景分类,通过自学习的方式来“识别”图像,利用反馈网络实现实现分类.Jiang等[14]首先将视频分解为关键帧,然后将这些关键帧的CNN特征传递给RNN进行分类.Tjondronegoro等[15]对不同类型的事件进行统计分析,选择6个具有区分性的特征,根据统计结果建立一系列规则把足球视频事件分为进球、射门和犯规3类.但过程比较繁杂,人力耗费较大.Ji等[16]提出基于三维卷积神经网络的体系结构,该算法捕捉多个相邻帧中编码的运动信息,从输入帧中生成多个信息通道.最终的特征表示为结合了所有通道的信息.但该算法应用场景是机场监控视频中人的行为识别.目前,对于足球视频中的活动识别,模型仅限于处理二维数据的输入实现分类.本文提出了一种基于三维CNN(C3D)的足球视频分类模型,模型通过执行三维卷积,从空间和时间维度中提取特征,从而捕获编码在多个相邻帧中的运动信息.具体算法流程如图1所示.

图1 算法流程图
本文的算法以视频作为输入,在场景切换检测的基础上将视频分割成小片段,根据预定义的类别将片段进行标记,然后,将小片段送入C3D(三维卷积)网络中进行训练.
1 算法设计
1.1 场景切换检测
本文提出的算法建立在三维卷积的神经网络模型上,模型以视频作为输入.首先,对足球视频的场景切换进行检测,提取不同场景的视频片段以实现镜头分割,通过边界检测算法将视频中每个镜头的边界帧检测出来,然后通过这些边界帧将完整的视频分割成一系列独立的镜头.
根据足球视频场景变换的特点,整场比赛中突变镜头的情况较多,在综合考虑了效率和准确率之后,本文选取了基于像素比较的镜头分割方法:帧间差分法,如式(1)所示:
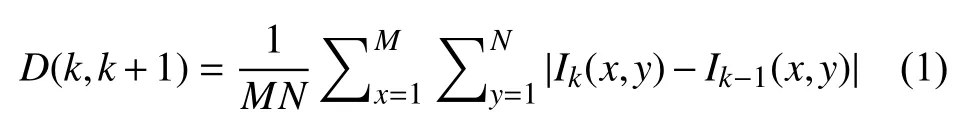
其中,Ik(x,y)和Ik+1(x,y)分别表示第k帧和第k+1帧在(x,y)处的亮度值,M和N分别表示该帧图像的高度和宽度.D(k,k+1)的值表示两帧之间的变化.当D(k,k+1)大于某一设定的阈值时则认为这两帧分别属于两个不同的镜头.
对于回放镜头,由于镜头切换频率较低,文献[12]通过实验验证了基于Logo 的回放镜头检测方法的可行性,因此,本文采取上述基于徽标检测的方法对回放场景进行检测.
1.2 语义镜头标注
文献[17]通过提取特征值并结合决策树来对镜头进行分类和语义标注.本文结合决策树算法及人工规则对分割好的镜头进行语义标注.决策树流程如图2所示.
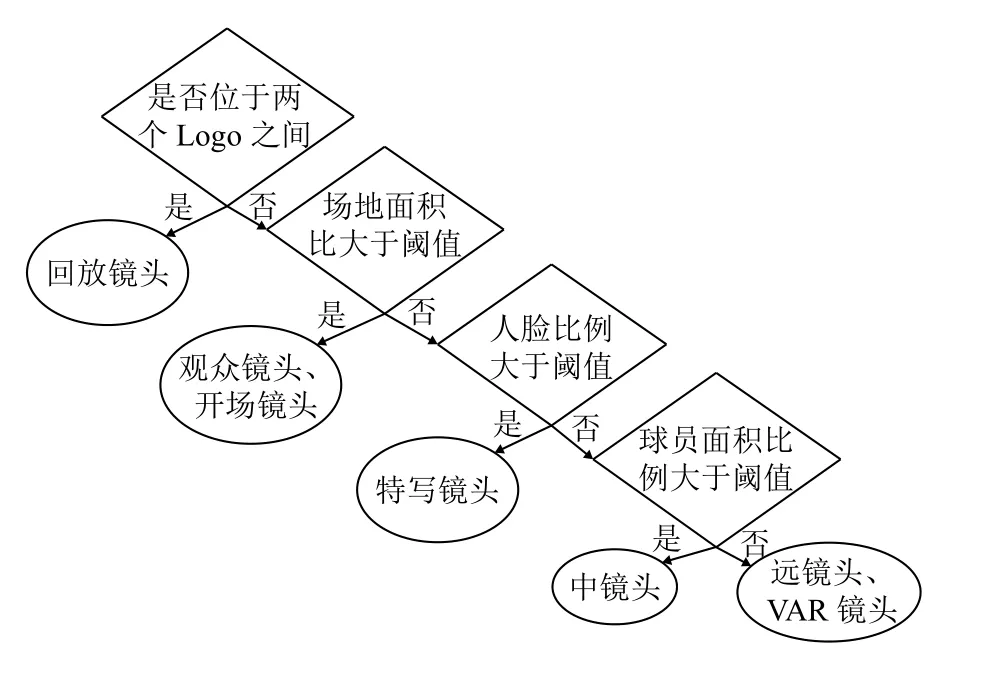
图2 决策树流程图
在决策树的第一层首先区分的是回放镜头和非回放镜头,决策树的第二层则是通过颜色直方图来判断场地面积,以此将非回放镜头分为场内镜头和场外镜头(观众镜头、开场镜头);第三层通过计算人脸比例提取场内镜头中的特写镜头;第四层通过计算场地和球员面积比例将剩下的场内镜头分为远镜头、VAR镜头和中镜头.
本文将镜头场景分为7类,分别为:远镜头、中镜头、特写镜头、回放镜头、观众镜头、开场镜头及VAR镜头.各镜头语义代表帧如图3所示.

图3 镜头代表帧
1.3 C3D模型设计
本文优化了经典的C3D网络的结构.经典的C3D网络结构是由8个3D卷积层(Convolution)、5个3D最大池化层(MaxPooling)、2个全连接层(Fully-Connect)构成.优化后的网络结构减少卷积层的个数,新的网络结构为5个卷积层,5个最大池化层,3个全连接层,2个Dropout层及1个Softmax层组成,如图4所示.
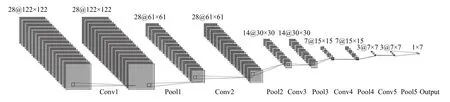
图4 C3D网络模型图
1)输入层
输入层的数据为一个个视频片段,但由于视频的长度长短不一,我们选用最近邻插值的方式,对视频片段少于采样长度的数据进行填补,以达到每次采样的长度为28帧.同时,我们还将视频序列帧的大小统一尺寸为122×122.
2)卷积层与池化层
本文采用三维卷积,在视频的空间和时间维上对相邻帧进行卷积操作以提取特征.这些特征保存了空间信息和时间信息,便于对视频中物体的运动进行检测.针对单通道,与2D卷积不同之处在于,输入图像多了一个depth维度,故输入大小为(1,depth,height,width),卷积核也多了一个k_d(depth)维度,因此卷积核在输入3D图像的空间维度(height和width维)和depth维度上均进行滑窗操作,每次滑窗与(k_d,k_h,k_w)窗口内的values进行相关操作,得到输出3D图像中的一个value.如图5所示.

图5 2D卷积
针对多通道,输入大小为(3,depth,height,width),则与2D卷积的操作一样,每次滑窗与3个channels上的(k_d,k_h,k_w)窗口内的所有values进行相关操作,得到输出3D图像中的一个value.如图6所示.
我们的视频片段每帧的大小为c×l×w×h,其中c为图像的通道数,l为视频序列的长度,即我们的采样帧数,w和h为每帧的宽和高.卷积层的核大小为d×k×k,d为卷积核的时间深度,k为核的空间大小,本文卷积层的核大小为3×3×3,所有池化层都是最大池化,内核大小为2×2×2(第一层除外),步长为1.第一层池化层的内核大小为1×2×2,其目的是不过早地合并时间信号,同时满足28帧的剪辑长度.

图6 3D卷积
3)Dropout 层
为了防止模型过拟合,我们引入了Dropout层,它将深度神经网络模型作为一个集成的模型进行训练,然后将所有值取平均,而不只是训练单个模型.网络模型将Dropout率为p,即一个神经元被保留的概率为1-p.当一个神经元被丢弃时,无论输入的是什么、相关的参数是多少,它的输出值都会被设置0.Dropout_1和 Dropout_2 层的p值初始设置为0.5.
4)Flatten层
Fatten层的作用是将数据“拍平”,即将多维的数据一维化,作为从卷积层到全连接层的过渡.Flatten层的处理不会影响批处理batch_size的大小,因此,本文的数据在经过Flatten层处理后,数据大小为256×9=2304.
5)损失函数
损失函数是衡量我们的网络结构在我们的数据集上训练的好坏的一项指标.当训练集的预测大部分为错误时,则对应输出较大的损失函数值.当模型的输出结果较好,则损失函数的输出也将较低.如果我们想要改变算法的某些部分来提高我们模型的性能,损失函数的输出将作为我们的参考标准.本文在架构中使用了交叉熵损失函数,如式(2)所示:
通过概率分布q来表达概率分布p的困难程度,p代表正确答案,q代表的是预测值,交叉熵越小,两个概率的分布越接近.
在此基础上,利用Softmax函数求出每个类的概率.Softmax函数如式(3)所示:
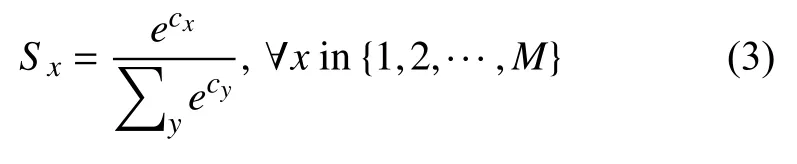
其中,S是每个可能结果M的分类概率得分.假设我们有一个具有M种可能结果的分类问题,当我们输入一幅图像进行分类时,我们根据每个结果得到分类分数S1,S2,…,SM.在得到预测后,将某一特定框架的分类分数除以所有指数分数之和后,得到基于最小损失的实际类,该类的概率最大.
2 实验分析
2.1 实验环境
实验环境为Ubuntu16.0,运行内存为16 GB,GPU型号为 NIVIDIA 1080 Ti,内存为12 GB.本文用MXNet框架搭建模型.
2.2 数据集
针对足球比赛视频,目前还未形成一个公开的数据集,为了训练本文的分类算法,必须自行收集数据,并根据需要对镜头的场景进行标记.因此,本文也为足球数据集的生成做出了贡献.在本文的分类中包含7种类型,包括开场镜头、观众镜头、远镜头、中场镜头、回放镜头、特写镜头、以及VAR镜头.每个类别的场景镜头约600个,每个镜头的平均持续时间为7秒,视频的帧率为25 秒/帧.本文的数据集包括5场世界杯比赛,每场比赛为90分钟.我们将数据的训练集与测试集按4:1的比例分配.
2.3 训练过程
由于本文的数据集有限,在采用3D CNN提取特征时,容易导致模型过度拟合,因此,我们引入了Dropout层,并设置不同的Dropout参数进行训练.训练准确率与测试准确率如表1所示.
本文发现,模型在Dropout值为0.7时,效果最好,因此,我们用这个Dropout值对网络进行训练.
在训练过程中,网络在迭代周期为1000时,损失函数的值最小,此后,损失函数开始收敛,如图7所示.
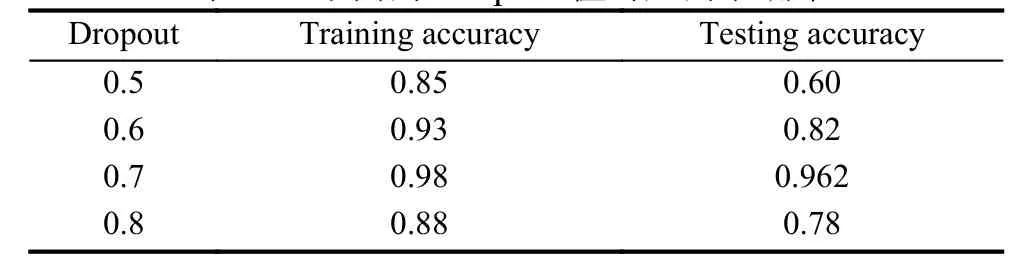
表1 不同的Dropout值对应的准确率

图7 迭代周期与准确率
与此同时,模型的优化函数采用自适应估计(Adam)梯度优化函数,其他参数配置如表2所示.

表2 超参数配置
2.4 实验结果
本文算法将足球视频场景分为7类,分类结果如表3所示,表格最右列表示未分类(漏检)镜头数,对角线的位置表示正确分类的镜头数.由表3可以看出,本文算法针对特写镜头的场景分类准确率最高96%,与文献[18]对比,场景类别更加丰富.同时,在特写镜头分类时,准确率高于文献[18]的基于HMM的事件检测分类算法.与文献[19]提出的基于贝叶斯网络的足球事件检测算法相比,虽然远镜头分类准确率低于其算法,但特写镜头的准确率高于其算法.与Jiang[14]所提出的2D CNN网络比较,特征提取更为有效,分类的准确率较高.与Chen[15]相比,数据集更丰富,比较的类别也更多.与基于LSTM的2D CNN相比,3D CNN同时捕获了二维CNN的时空特征,取得了较好的效果.本文数据对比如表4所示.
3 结束语
2 D CNN在空间特征的学习效果较好,但无法对视频的时间特征进行处理.本文提出的基于C3D的足球视频场景分类算法,分别对时间特征和空间特征进行了有效的提取,实现了比传统技术更好的精度,本文在特写镜头分类时,准确率提高了2%.本文算法在场景切换检测的基础上,根据预定义的类别将各个场景片段进行标记,利用3D CNN学习时空特征,然后将其进行分类.下一步工作计划是进行实时的足球视频场景分类,与此同时,扩展场景类别以识别足球视频中更复杂的场景.
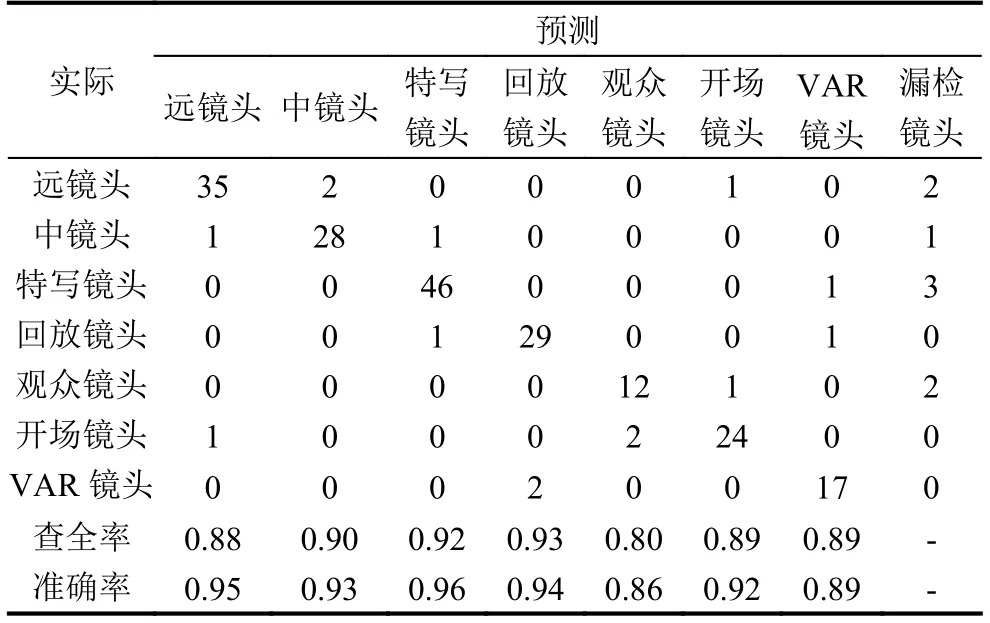
表3 查全率与准确率实验结果

表4 特写镜头分类结果对比
