EEG和ECG信号的非线性耦合在睡眠分期中的应用研究
2019-12-18张克刚王卫东
张克刚,刘 戈,王卫东
(1.解放军总医院海南医院医学工程科,海南三亚 572000;2.解放军总医院第一医学中心,北京 100853)
0 引言
睡眠质量与人体的健康息息相关,而评估睡眠质量的重要标准就是睡眠分期。睡眠分期是衡量睡眠质量和诊治睡眠障碍性疾病的基本方法。美国睡眠医学学会(American Academy of Sleep Medicine,AASM)在2007年提出了AASM标准,将睡眠时相主要划分为五期[1],包括清醒期(wakefulness,W)、非快速眼动期Ⅰ期(non-rapid eye movementⅠ,N1)、非快速眼动期Ⅱ期(non-rapid eye movementⅡ,N2)、非快速眼动期Ⅲ期(non-rapid eye movementⅢ,N3)和快速眼动期(rapid eye movement,REM),现已被广泛应用。
脑电(electroencephalogram,EEG)是通过放置在头皮表面的电极记录的人体神经元电活动的宏观综合表现,可反映大脑不同状态的信息。心电(electrocardiogram,ECG)是心脏的每个心动周期中起搏点、心房、心室相继兴奋产生的生物电变化。EEG与ECG 2种生理信号均与睡眠分期密切相关:EEG在不同睡眠时相表现出不同的节律波[2];随着睡眠的加深,心率变异性(heart-ratevariability,HRV)呈现有规律的变化[3-4]。在睡眠自动分期的研究领域,单独或综合使用EEG、ECG作睡眠分期的研究有很多[5-9],但使用EEG、ECG信号间的耦合程度作为分期标准的研究并不多。在很多生物系统的研究中都发现了一些器官之间的耦合或者同步关系,而符号转移熵(symbols transfer entropy,STE)和互信息(mutual information,MI)是衡量2个系统之间的相关程度或者混乱程度的参数。人体EEG、ECG均是受自主神经系统控制的,EEG、ECG间的MI和STE反映了大脑和心脏这2个器官之间的耦合程度和方向性信息。随着人体从清醒状态到睡眠的不断加深,大脑活动自由度会不断减少,身体各器官不断耦合,信号的相关性也逐渐变强。井晓茹等[10]对W期与N1期的STE值进行对比,发现STE有差异性。张梅等[11]基于EEG、ECG、肌电(electromyography,EMG)3种生理信号,利用符号化部分互信息区分生物体清醒期和睡眠期,发现清醒期的符号化部分互信息显著高于睡眠期。因此,本文基于前人的研究,将STE和MI这2种非线性耦合分析方法推广应用于AASM分期标准下睡眠五期的研究,发现睡眠各期EEG、ECG耦合程度的变化规律,为睡眠自动化分期研究增加新的判断依据。
1 符号互信息(sign mutual information,SMI)与STE的定义
1.1 MI和转移熵(transfer entropy,TE)
对于任意一个随机变量X,有概率分布p(x),它的香农熵定义如下:

其中,H(X)代表随机变量X的香农熵。变量X的不确定性越大,其熵值越大,把这一随机变量X搞清楚所需要的信息量也就越大。
MI是信息论里一种有用的信息度量,描述两变量之间的信息交互情况。它可以看成是一个随机变量中包含的关于另一个随机变量的信息量,或者说是一个随机变量由于已知另一个随机变量而减少的不确定性。2个随机变量X和Y的MI定义如下:

其中,H(X)和H(Y)分别代表随机变量X、Y的香农熵;H(X/Y)和H(Y/X)为条件熵;H(X,Y)为联合熵,是由X、Y的联合概率分布p(x,y)得到的;I(X;Y)反映随机变量X、Y间的相关性。MI的物理含义如图1所示。

图1 MI物理含义图
因MI不能看出信息的方向和动力学信息,2000年Thomas Schreiber提出了TE[12],TE是用来反映系统各变量之间信息传递的不对称性,它具有方向性和动态性。在其定义中引入了转移概率。
有2个随机变量X、Y,若X在n+1时刻的状态与Y在n时刻的状态不独立,由xn、yn推测采样点xn+1时所需要的熵为

若X在n+1时刻的状态与Y在n时刻的状态是独立的,则由xn、yn推测采样点xn+1所需要的熵为

TE的定义即为H2与H1的熵差:

1.2 原始序列符号化和相空间重构
符号动力学分析方法[13]是将原始序列转化为由几个符号组成的序列再进一步对符号序列进行分析的方法。该方法是在符号动力学、混沌序列分析理论的基础上发展起来的。对原始时间序列作符号化的优势包括:克服噪声对分析结果的影响;保留时间序列的动力学特征;简化运算过程,大大提升运算速度,使复杂时间序列的实时分析成为可能等。本文采用的符号定义如下:

其中,xi为原始时间序列X中的元素;yi为得到的符号序列Y中的元素;μ1为原始序列X中大于等于0的取样信号的平均值,μ2为序列X中小于0的取样信号的平均值;a=0.05[14]。
将原始序列符号化后得到的一维离散时间序列扩展到m维空间的过程就是相空间重构,这是非线性动力学研究至关重要的一步。相空间重构的过程就是动力系统重建的过程。该过程中定义2个参数:相空间维数m(即字长)和延迟时间τ,为避免进一步损失符号序列的有效信息,本文中τ取1,而嵌入维数m通常取3~7[10],本文考虑算法的效率,m取3。
1.3SMI与STE
在了解了符号化、相空间重构、MI和转移熵的相关知识后,可得出SMI和STE的计算步骤(如图2所示):先对原始时间序列进行符号粗粒化和相空间重构,得到符号嵌入矢量构成符号字,然后将每一个符号字按照时间有序排序得到一个新的时间序列,再分别对新的时间序列求MI和转移熵即可得到SMI和STE。
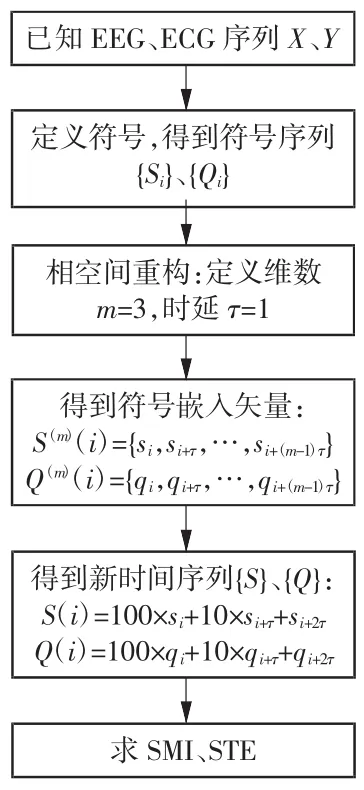
图 2 SMI、STE 计算流程图
2 SMI、STE用于睡眠分期
2.1 数据来源
本文使用PhysioNet生理信息库中CAP Sleep Database数据库和MIT-BIH Polysomnographic Database数据库中随机选取的9名受试者整夜睡眠实测数据。其中包括CAP Sleep Database数据库的3名健康志愿者睡眠数据、3名癫痫患者的睡眠数据和MIT-BIH Polysomnographic Database数据库的3名睡眠呼吸暂停综合征患者的睡眠数据。在MIT-BIH Polysomnographic Database数据库中,使用C3-O1导联EEG,采样频率250 Hz。在CAP Sleep Database数据库中,使用C4-A1导联EEG,采样频率512 Hz。受试者包括男性和女性。测试过程中未使用任何药物干扰。数据库中每30 s的睡眠分期结果已由专家人工进行了标注(以R&K睡眠分期标准标记)。定义30 s数据为一个样本。9名受试者睡眠样本分布见表1。

表1 9名受试者睡眠样本分布个
2.2 方法
由于符号粗粒化能够去除噪声的影响,故本研究不对原始数据作任何预处理,直接读取每名受试者EEG、ECG原始数据,按照图2所示流程计算SMI和STE值。使用SPSS Statistics 24软件进行统计学分析,对每名受试者睡眠五期各组间SMI、STE进行正态性检验和方差齐性检验。在满足正态分布的前提下,若方差齐则使用SNK(Students Newman Keuls)组间检验,方差不齐使用Dunnett T3组间检验;不满足正态分布的情况下,使用非参数秩和检验。显著性水平均为0.05。
2.3 结果
输入9名受试者不同睡眠时相的样本数据,得到睡眠各期STE均值,详见表2。对9名受试者睡眠各期的STE值进行统计学分析,各组数据均满足正态性检验,方差齐性检验P<0.001,表明方差不齐,使用Dunnett T3组间检验。统计学结果见表3。

表2 9名受试者睡眠五期EEG-ECG的STE均值
从表2可以得出结论,整体而言,9名受试者睡眠各期的STE规律性一致。随着睡眠的加深,STE值逐渐减小,说明EEG、ECG两时间序列的混乱程度减小,相关程度越来越好,身体各器官不断耦合,在N3期两序列相关程度达最优。到REM期STE值又有所增大,两序列间的混乱程度增大。CAPnfle12和CAPnfle13两名受试者在N1期的STE均值相较于W期稍有增大,可能与W期、N1期样本量较小以及直接使用整个30 s的EEG、ECG数据进行特征值计算(因一个人工分期的30 s信号可能不完全属于一个睡眠分期)或者个体差异有关,但不影响整体的规律性。由表3可知,9名受试者睡眠五期各组间STE大多有显著性差异,但不同受试者由于年龄、外界刺激、身体状态、疾病情况等不同,组间差异有所不同。表2、3表明了STE在不同受试者中作睡眠分期的稳定性,适合用作睡眠分期的特征参数。

表3 9名受试者睡眠各期EEG-ECG的STE组间统计学分析
同样,计算9名受试者不同睡眠时相的SMI值并进一步分析,得到的结果见表4、5。

表4 9名受试者睡眠各期EEG-ECG的SMI平均值(C4-A1)

表5 9名受试者睡眠各期EEG-ECG的SMI组间统计学分析
从表4、5可以发现,整体上,SMI与STE规律性一致。随着睡眠的加深,SMI值逐渐减小,到REM期又有所增大。但由表5可知,对于CAPn1和CAPn2而言,各睡眠时相SMI的统计学差异较好,但对于其他受试者,组间的差异性较差。综上,SMI应用于睡眠分期的效果差于STE。
3 结论与讨论
STE、SMI反映2个时间序列的相关程度或者混乱程度,其值越大,不确定性越大,表示序列的混乱程度越大;而值越小,不确定度越小,表示序列的相关程度越好。本研究发现,EEG-ECG的STE、SMI可以用于睡眠五期的分期,在文章有限数据验证的情况下,可得出结论:STE的睡眠五期分期效果优于SMI。将STE用于9名受试者睡眠各期,各期之间大多有显著统计学差异,但该特征对于某些受试者W期和N1期、N1/N2期与REM期的区分效果不佳。随着睡眠的加深,身体不断耦合,原来的活跃部分失活,EEG、ECG 2个时间序列的混乱程度减小,相关度变好,STE、SMI值减小,到REM期又增大,说明序列的不确定度又稍有增大。因此,STE和SMI可以作为研究睡眠分期的重要特征。
本文具体定义了SMI和STE 2种特征作睡眠分期的研究。但使用不同的符号定义、不同的字长,或者不做相空间重构等定义出来的SMI和STE会对睡眠分期结果影响巨大。本文将相空间重构后的字定义为序列中的一个元素对序列进行符号化研究,是因为考虑相空间重构后的字包含有相邻时间采样点的动态信息。该符号定义下的STE用于分期的效果较优,而SMI对睡眠分期有效但效果较差,具体哪种SMI的定义对睡眠分期效果最优可以作进一步研究。
