联合特征相似性度量和交并比的检测框优选研究
2019-12-16孙世强左海维赵露婷
孙世强 左海维 赵露婷

摘要:非极大值抑制(Non-Maximum Suppression,NMS)算法作为Faster R-CNN(region-based convolutional neural net-work,R-CNN)的后置处理算法,从物理空间判定检测框的重叠比例,忽略内在特征联系,造成漏检和误检问题。因此提出联合特征相似性度量和交并比的检测框优选方法(Optimized box Based on lou and Feature similarity,OBIF)。该方法首先计算两个检测框的交并比(Intersection over Union,lou),判断检测框之间的重叠比例;然后计算闵式距离,表示重叠的检测框之间的特征相近性,进行深层次判断;最后联合闵氏距离和交并比实现检测框优选。当运行效率一致和时间复杂度相同时,将Faster R-CNN+OBIF应用到PASCAL VOC 2007数据集和结直肠腺癌数据集,比较传统NMS算法,平均识别准确率分别提高了1.4%和1.1%,方法检测精度得到显著的提升。
关键词:目标检测;非极大值抑制算法;FasterR-CNN;交并比;特征相似性度量
中图分类号:TP391.41 文献标识码:A
文章编号:1009-3044(2019)29-0190-04
根据2018年的世界癌症报告,癌症已成为主要的公共健康问题和首要死亡原因。早期癌症可以临床治愈,治愈率达80%,而对于中晚期癌症,通过正规治疗,可以延长生命期,但治愈率较低,不足20%。与中晚期癌症患者相比,早期病人的长期生存率和生活质量都有显著提高,治疗费用也大幅下降,所以早期诊断和治疗意义重大。
在临床上,病理学检查往往被视为癌症诊断的金标准。其中,病理图像是对患者病变部位的组织进行切片,在显微镜下进行放大成像得到的图像。能够直接反映出组织内部所发生的病变,是医生进行癌症诊断的重要依据,甚至是最终依据。由于病理学人才的缺失、病患人数的增加、对癌症准确诊断率和诊断时间的更高要求,目前将深度学习技术嘲融入计算机辅助系统,承担病理图像前期预分析工作,将病理图像中存在问题的细胞核进行框选,最终由医生进展针对性诊断,可以较大程度缩短早期病理诊断时间,减少和舒缓病理医生的工作量和精力,提高癌症诊断效率。
本文实验采用Faster R-CNN(region-based eonvolutionalneural network,R-CNN)框架应用至结直肠腺癌数据集,癌症病理图像特征图经RPN网络嗍(Region Proposal Network,RPN)后会生成大量的检测框。NMS (Non-Maximum Suppression,NMs)算法对检测框集合进行合理筛选,合并同类别检测框,以达到问题细胞核分类和检测框回归的目的。由于NMS算法仅将交并比(Intersection over Union,IoU)作为评价指标,容易造成目标的漏检和误检。此外,NMS算法忽略各检测框特征图的内在特征联系,不具有特征敏感性。所以本文提出联合特征相似性度量和交并比的检测框筛选方法(optimized box Based on louand Feature similarity,OBIF),通过设置合理OBIF指标阈值,完成病理图像中问题细胞核的检测工作,辅助医生完成癌症诊断。
1相关知识
1.1Faster R-CNN
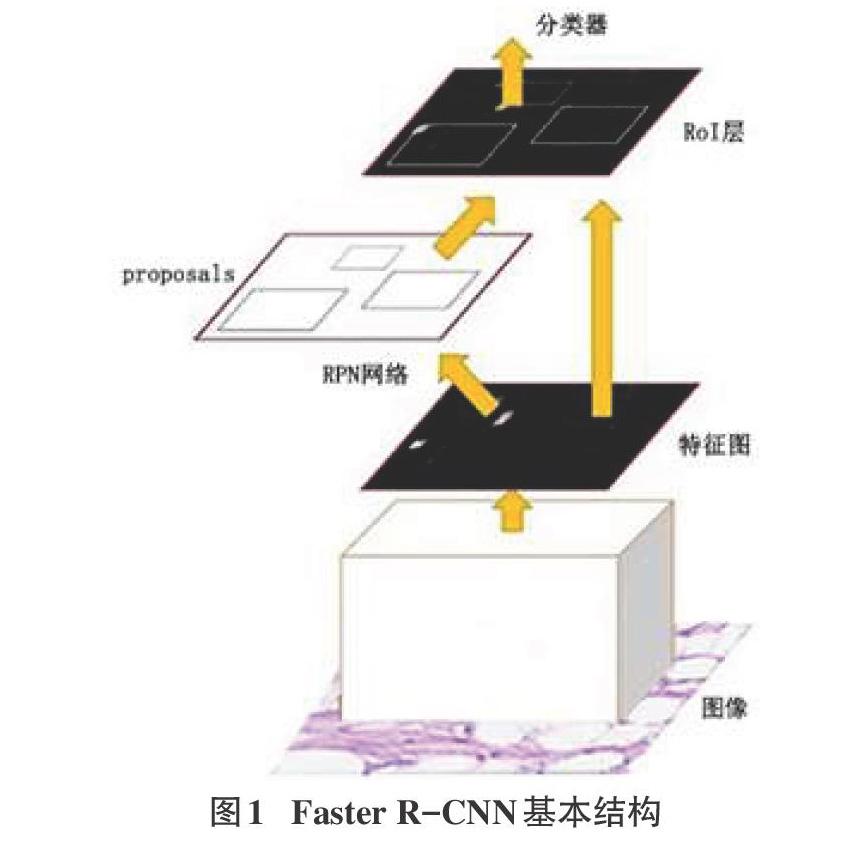
Faster R-CNN是目标检测领域经典算法,它将feature既-traction、proposal提取、bounding box regression、classification整合在一个网络中。如图1所示,FasterR-CNN分为4个主要内容:
(1)Faster R-CNN采用一组基础的conv+relu+pooling层提取图像的特征图。该特征图被共享给RPN和全连接层。
(2)RPN网络用于生成region proposals。RPN实际分为两条操作线,一条通过softmax分类anchor属于foreground或者background,另一条计算对于anchor的框回归偏移量,修正an-chor获得精确的proposals。
(3)Roi Pooling层收集输入的feature maps和proposals,综合后提取proposalfeaturemaps,送入全连接层判定目标类别。
(4)利用proposalfeaturemaps计算proposal的类别,同时再次框回归获得检测框最终的精确位置。
其中,特征图经过RPN网络后产生约20K个anchor,但如此数量的检测框不可能全部送入Fast R-CNN。一方面这20K个anchor中存在大量重叠的检测框,另一方面会产生巨大的计算开销,造成检测速度下降。因此在RPN网络生成检测框后要采用一定的机制来进行优化筛选,在Faster R-CNN中,目前采用的是非极大值抑制的方式,具体如下:
(1)检测框集合P,检测框置信度集合c和保留检测框集合K;
(21將集合c从大到小排列,将置信度最大所对应的检测框移至集合K中,并在集合P中将该检测框删除;
(3)计算集合P剩余检测框与该检测框的IoU值,删除大于设定阈值T的检测框;
(4)重复(2)和(3)的操作步骤,直至集合P为空。
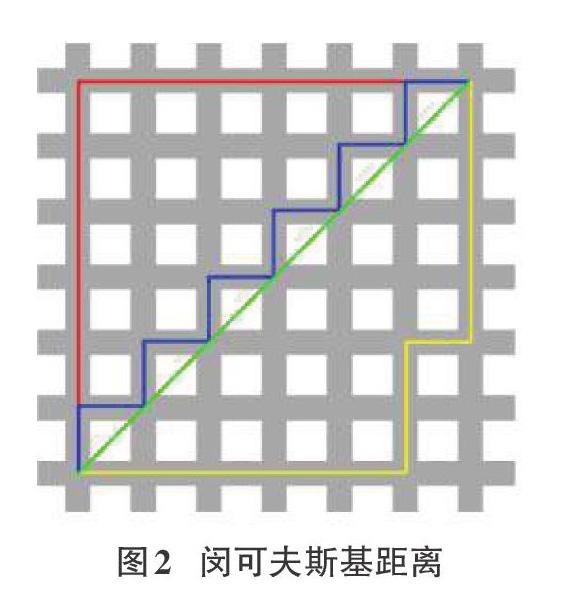
1.2闵可夫斯基距离
在智能分类算法中,为区分样本之间的差异性,通常需要做样本特征的相似性分析,并以“距离”作为评价指标。根据数据特性的不同,可以采用不同的相似性度量方法,本文选用的是闵可夫斯基距离。
闵式距离是衡量数值点之间距离的一种非常常见的方法,两个n维向量
