基于Hadoop与nongoDB整合技术的大数据处理分析
2019-12-16史小英杨浩
史小英 杨浩

摘要:在数据类型不断增加,规模逐渐扩大的趋势下,NO SQL技术与MapReduce并行处理理念开始备受关注。而作为N0SQL数据库典型代表,MongoDB可索引并查询大量数据,但是其所提供的MapReduce无法满足太过繁杂的数据分析与并行计算。而Hadoop具备强大的MapReduce计算能力,但实时服务延时较长。对此,可基于扩展性、数据本地化等相关要素分析,整合Hadoop与MongoDB,针对不同应用场景,寻求最优整合方式,以提高大数据处理效率与质量。
关键词:Hadoop;MongoDB;整合;大数据处理
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2019)29-0001-02
1Hadoop与MongoDB概述
1.1Hadoop
Hadoop包含大量元素,最底部为HDFS,作用是存储所有节点文件,其上层为MapReduce引擎,以及数据仓库Hive、数据库Hbase。Hadoop在大数据处理中实现广泛应用的关键在于,其数据提取、变形、加载等极具优势。Hadoop分布式框架推动大数据处理引擎尽量接近存储,比较适合批处理操作,所以,批处理结果可直接存储。Had oop的Map Reduce功能可碎片化单项任务,并实时传输到各节点,然后以单数据集形式向数据仓库加载。
1.2MongoDB
MongoDB是针对Web应用程序与互联网基础设施所设计的数据库管理系统,是典型的No SQL数据库。MongoDB以BSON为数据模型结构,其可促使MongoDB在生产环境下提高读写能力,吞吐量明显较强。而且,MongoDB还具备分片能力,可分片数据集,以此将数据存储压力分摊到多台服务器上。MongoDB还可检测主节点的存活状态,在失活的时候,可自动将从节点转变为主节点,以转移故障。由于BSON数据模型主要面向对象,因此可表征十分丰富,层次化分明的数据结构。
2Hadoop与MongoDB整合框架
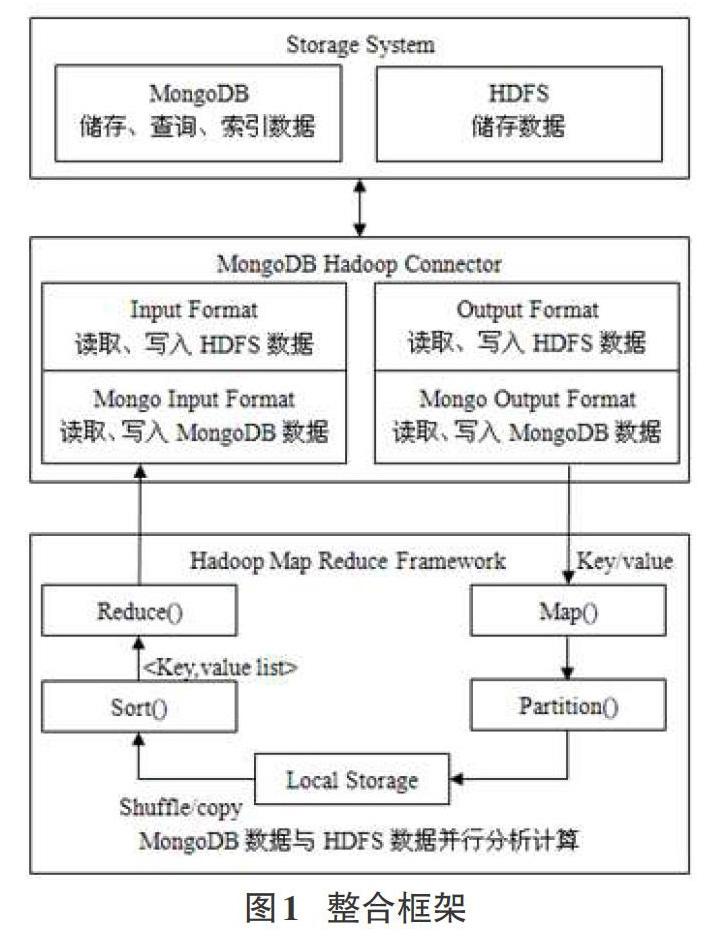
Hadoop善于分析计算海量数据,MongoDB擅长分布式存储与查询数据。有机整合可发挥双重优势,同时满足数据分析、计算、查询、存储等多项要求。整合框架具体如图1所示。
就Hadoop与MongoDB整合而言,使用了中间件,即Mon-goDB Hadoop Connector,作用是利用MongoDB替换HDFS,作为Map Reduce数据源,在分布式集群中,集合划分为固定形状的块基于MongoDB储存,而Hadoop Mappers以路由节点为载体并行读取块,解析数据,然后利用Reducer合并,传输结果于Mon-goDB。在数据处理中,HDFS并未发挥作用,为保证Hadoop与MongoDB整合的有效性、灵活性,以及数据处理的实效性。就MongoDB Hadoop Connector进行了优化扩展,即在Connector中添加Input Format与Output Format类,以HDFS与MongoDB为Map Reduce可选择输入源或者输出目标。
Hadoop与MongoDB整合方案以配置方式不同划分为四类,即:一是基于HDFS读取数据,并编入计算结果;二是基于HDFS读取数据,在MongoDB中编写计算结果;三是基于Mon_goDB读取数据,在HDFS编写计算結果;四是基于MongoDB读取数据,并编入计算结果。针对三种不同应用场合对各方案性能进行评估与测试,即:一是Read=Write,读写大致相同;Read>>Write,读明显大于写;Read<
3集群部署策略
Hadoop与MongoDB整合框架计算与查询海量大数据时,集群部署环节十分关键。
3.1MongoDB分片
为方便操作,在副本集只设计了两台机器,即主服务器与从服务器。通过科学合理设置参数,其中主服务器的任务是写,从服务器的作用是读,以此分摊主服务器写的压力。
3.2数据本地化
在Hadoop与MongoDB整合集群中,数据本地化主要基于Hadoop Task Trackers、Data Nodes与MongoDB分片服务器相互交叉重叠加以实现。但是,需要同时实现数据本地化与Mon-goDB分片读写相分离,需要把Hadoop Task Trackers和DataNodes分配于MongoDB分片从节点。如此一来,Map Reduce便可从MongoDB分片从节点中进行数据读取,在经过处理之后,将数据再次编写于MongoDB主服务器。
4实验分析
4.1数据
选用某数据进行实验。在Hadoop与MongoDB整合框架中,针对数据进行极具代表性的三种应用进行场景模拟。其一,Filter,以模拟Read>>Write场景;其二,Recorder,以模拟Read=Write场景;其三,Merge,以模拟Read<
4.2配置
实验选用总节点数是19,包含Name Node、路由器、服务器;Hadoop Data Node、Task Track、MongoDB分片进行交叉部署的主节点数为8,从节点数为8。
4.3结果分析
4.3.1数据加载与导出性能
相比MongoDB,HDFS数据加载与导出性能更好,这主要是由于HDFS不需读取数据,解析并序列化,然后基于数据库格式于磁盘进行存储,数据加载与导出操作只是简单地复制或者移动文件。HDFS数据导人与导出性能和数据大小之间为正相关关系,MongoDB数据导入与导出性能则是在数据集逐渐加大的趋势下,速率快速下降,尤其是导入速率。
4.3.2不同方案下的不同应用性能
在输入远远超出输出时,数据处理情况具体如表1所示。其中方案三与方案一对比分析,就数据输人源不同,但是方案一速率更高,所以,基于MongoDB读取数据的成本耗费比较大。而四个方案对比分析,可知彼此间性能差异较小,主要是由于输出数据很小,写入数据的位置难以很大程度上对性能造成影响。
在输入与输出相等时,数据处理情况具体如表2所示。不同的数据集中,方案一速率最高,时间最短,相同输入时,输出结果的编写位置直接影响着性能,所以,相同数据集在进行相同处理,但是选择不同整合方案时,方案三的性能与方案一最相近间。
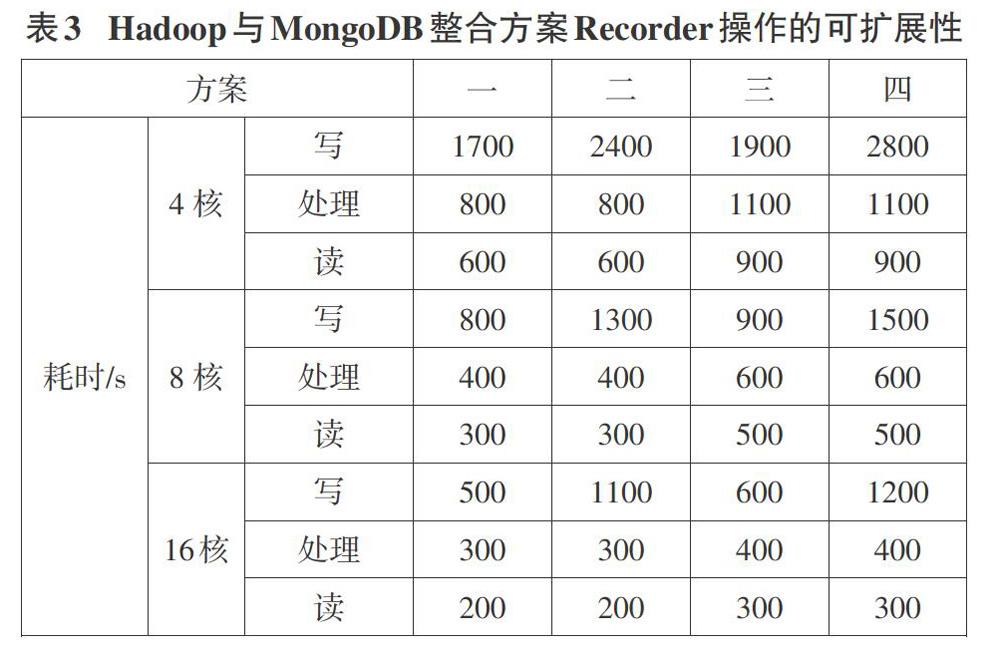
4.3.3不同方案配置的可扩展性
不同方案配置的可扩展性具体如表3所示。其中,集群规模通过4核向8核扩展时,四个方案整体性能都有显著提升,而且从表可看出,各方案的读、写、处理时间都有十分明显地缩减。
Hadoop与MongoDB整合集群扩展到8核的时候,内存与CPU利用率都会降低,可缓解二者制约性,从而使得性能快速优化提升,所以可知内存与CPU占用率太大,会导致性能严重损失,而Hadoop与MongoDB整合可横向扩展添加节点,从而有效弥补。基于内存与CPU充分状态,方案四以集群规模不断扩大的方式,可快速缩减读取时间,这主要是由于集群规模扩大,Map增多,可同时并行读取数据。但是写发生于Reduce阶段,尽管扩大集群規模,也可促使Reduce并发数增多,然而把数据分发于MongoDB分片服务器需要耗费过多成本,所以写的性能并未出现显著提升。
5结论
综述,通过实验,基于Hadoop与MongoDB整合处理大数据,得出结论:选择方案一,处理MongoDB数据,需先导出并传输于HDFS,在Hadoop处理之后,把结果导回MongoDB,以此反复导人导出,成本消耗过大,所以此方案数据处理性能最差;选择方案二,针对非MongoDB数据或已储存于HDFS数据,需密集型读,需查询处理结果时,此配置可提供最优化性能;选择方案三,针对已储存于MongoDB的数据,需密集型写,结果集应基于Map Reduce进行后续处理,此方案可提供最优化性能;选择方案四,针对已储存于MongoDB的数据,统计并聚合计算,需查询结果集时,此方案可提供最优性能。
