基于PCA-KELM和AT的互感器故障诊断
2019-12-14曹文彬赵艳峰蒋婷婷王先培
王 昕,曹文彬,曹 敏,赵 旭,赵艳峰,李 翔,蒋婷婷,田 猛,王先培
(1.南方电网电能计量重点实验室,云南 昆明 650217;2.云南电网有限责任公司电力科学研究院,云南 昆明 650217;3.武汉大学电子信息学院,湖北 武汉 430072)
0 引 言
互感器是电能计量系统中的重要设备之一。现阶段已投入使用的互感器,可靠性不高,一旦出现故障,将导致计量不准确,直接影响到营业性电价计费的公平合理,损害电力部门和电力用户的经济利益。研究电能计量系统互感器的故障诊断技术对提高电能计量的准确度具有重要的现实意义。
近年来,相关学者将支持向量机(support vector machine,SVM)引入到电能计量系统诊断中。文献[1-2]采用分层决策的方法,利用多类SVM分类器建立了故障诊断模型,得到较好的故障诊断效果。尽管如此,SVM仍然有其局限性,对于一对多的方法,训练样本的不均衡将对精度产生影响,存在误分、拒分区域。且该模型需要反复分组原始数据、选取训练及测试样本等数据,容易出现混淆和差错。由于近年来模式识别技术的发展,提出了一种名为极限学习机(extreme learning machine,ELM)的新型神经网络算法[3-5]随着各种改进的ELM算法以及故障诊断中的引导方法的出现,研究人员可以应对不完全和不均匀分布故障样本,ELM也开始用于电能计量系统互感器的故障诊断[6]。
针对这些问题,本研究提出了一种基于主元分析法核极限学习机 (principal components analysiskernel extreme learning machine,PCA-KELM) 结合反正切变换(arctangent transform,AT)归一化来解释计量系统电子式互感器故障诊断。较之传统的2分类SVM,构造学习过程简单,分类器的鲁棒性强,精度高。同时,与ELM相比,KELM方法[7-11]在网络的训练学习过程中,无需设定网络隐含层节点,仅需选择适当的核参数与正则化系数,通过矩阵运算,获得网络的输出权值。
1 算法基本原理
1.1 反正切变换
在故障诊断过程中,互感器的各种电压电流等数据通常呈现高度倾斜的分布。这种分布可能是数值不精确的来源,并增加机器学习的复杂性。介绍一种简单归一化的方法来重新调节电压电流等数据的相关比例。
对于输入为x,归一化输出为y的y3=arctan(x)×2/π系统,归一化能够避免初始数据中数值范围大的属性值掩盖数据范围小的属性值。常用的归一化公式有:
1)对数函数转换:

2)反正切函数转换:
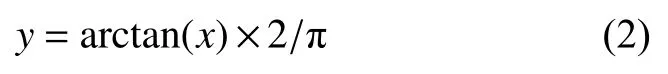
图1比较了log10变换和AT对假定数据从10-10变化到1010的运算性能。横轴为x,纵轴y1=10x,y2=log10x,y3=arctan(x-5)×2/π,如前所述,AT具有压缩大信号和扩展小信号以将任何实数变换为[-1,1]如图所示,它具有良好的非线性。
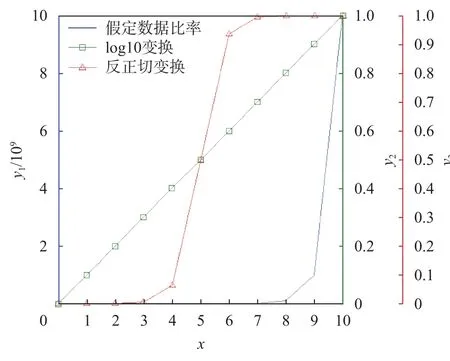
图1 AT和log10变换与假定数据比率的性能比较
1.2 主成分分析法
PCA即主成分分析法。主成分分析是考察多个变量间相关性一种多元统计方法,研究如何通过少数几个主成分来揭示多个变量间的内部结构,即从原始变量中导出少数几个主成分,使它们尽可能多地保留原始变量的信息,且彼此间互不相关。通常数学上的处理就是将原来p个指标作线性组合,作为新的综合指标,主成分分析步骤如下。
设X是带有n个样本和p个变量的数据表,即X=(xij)n×p=(x1,x2,···,xp)。
其中xj=(x1j,x2j,···,xnj)T对应第j个变量。
1)对数据进行标准化处理,即:
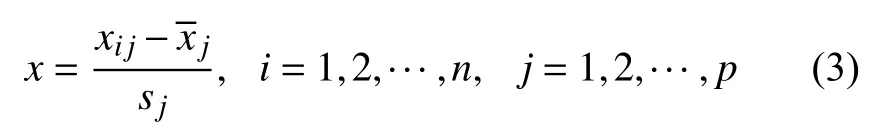
3)求V的p个特征值 λ1≥ λ2≥ ···≥ λp及对应的特征向量U=(u1,u2,···,up)。
4)计算前m个主成分的累计贡献率:

5)求前m个主成分:

其中U=(u1,u2,···,um);Y=(y1,y2,···,ym)。
1.3 KELM算法
新加坡南洋科技大学的Huang教授在2006年提出了极限学习机算法(ELM),这种算法是一种单隐层前馈网络神经网络算法。ELM模型的基本原理如下:
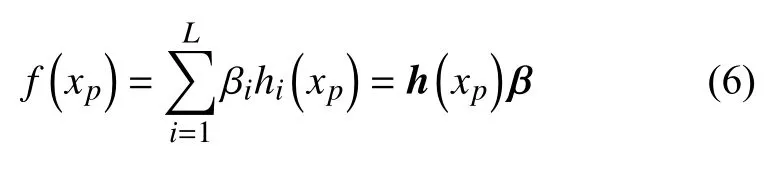
其中 β =[β1,···,βL]T为连接隐层与输出层的权值向量 。h(xp)=[h1(xp),h2(xp),···,hL(xp)]是 将xp从n维输入空间映射到L维隐层特征空间的向量。ELM网络训练目标可以表示为:
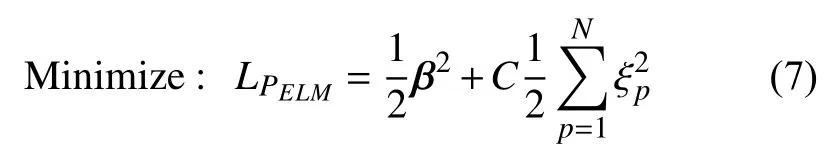
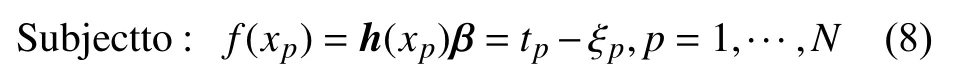
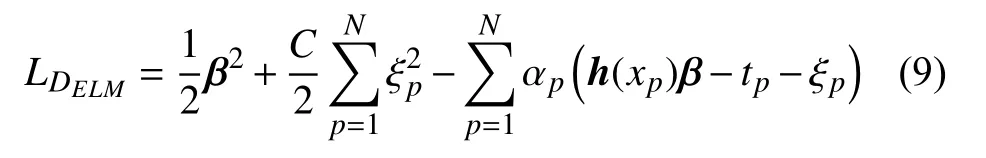
其中,αp为拉格朗日乘子。根据KKT最优化条件求解式(8)可得:
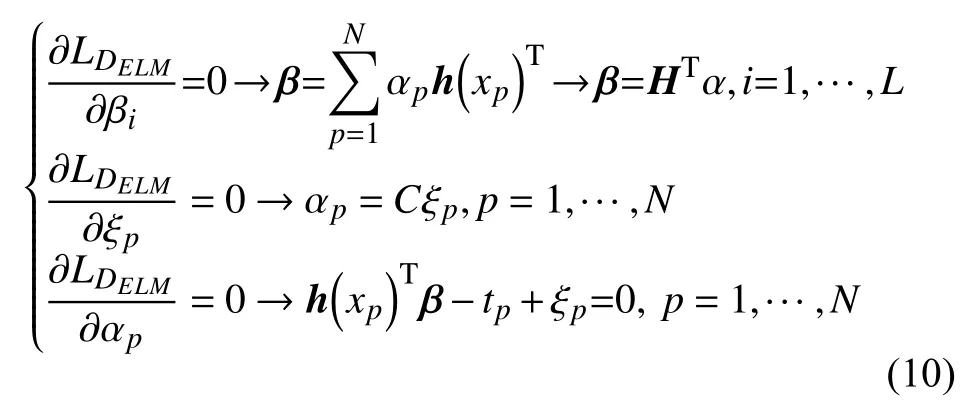
其中,H=[hT(x1),···,hT(xN)]T为隐层输出矩阵,α=[α1,···,αN]T为拉格朗日乘子向量。
求解式(11)可得:

其中,T=[t1,···,tN]T为输入样本集的目标值向量。
为了进一步提高ELM的泛化能力和稳定性,Huang等人通过比较ELM和SVM的原理,将核函数引入到ELM中,并提出了KELM算法。
使用Mercer's条件来定义核矩阵:
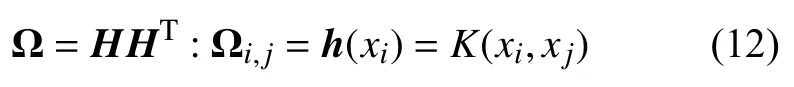
其中,Ω为一个N×N的对称矩阵,K(xi,xj)为核函数。
将式(12)代入式(8)可得KELM模型的输出为:
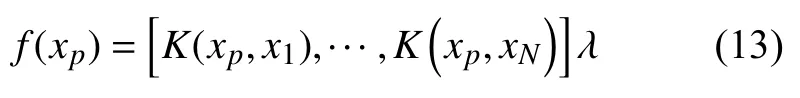
其中,λ为KELM网络的输出权值:

核函数K(xi,xj)通常设定为RBF核:
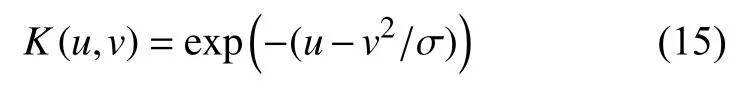
其中,σ为核参数。
在KELM中,ELM中的随机矩阵H被内核矩阵 Ω替换,并且输入样本使用核函数映射到高维内核空间。核函数中的核参数(包括RBF核函数、线性核函数和多项式核函等)K(xi,xj)中的核参数被设置后,核矩阵 Ω的映射一个固定值。由(14)式可以看出,在设定惩罚系数C之后,所求得的KELM网络输出权值 λ是固定的,当模型重复时,获得 λ值保持不变[12-16]。
2 互感器故障诊断模型构建
2.1 测量参数选择
根据互感器故障特征,互感器故障可分为直接判别故障和间接诊断故障。电压互感器一次侧短路属于间接诊断故障,当故障发生时,从图2中的P、Q点可以看出,网络阻抗变化很大,可以作为判断的依据。但是,网络阻抗不能直接测量,另外,激励信号被用于检测,并且采样的检测信号是多个信号的叠加,并且它必须通过频谱分析来确定以获得期望波段的信息。当电流互感器在第二相短路时,网络的阻抗将随着负载的变化而变化。同样需要多个检测信息来判断故障。
分析发现互感器中存在多种类型的故障,某些故障不能通过单个信号识别。因此,根据互感器的结构,测量回路的多个参数并收集采样数据。然后,极限学习机模型用于处理和分析故障样本数据。
由表1中的8种特征信息来进行故障的辨识,可以总结电能计量系统互感器的7种典型故障的样本数据信息。如表1所示,列出故障的数据形式及其所对应的的7类故障:CT1一次端短路,CT2一次端短路,CT1二次端短路(后),CT2二次端短路(后),CT1二次端短路(前),CT2二次端短路(前),CT二次相间短路。高压电力计量系统的原理如图2所示,其中Zi为输入阻抗 。
针对以上几种典型故障类型进行数据的处理以及进行分类。最终得到了互感器的各种电压电流等数据相关信息。
2.2 互感器故障诊断流程
现实中互感器测量的参数多、数据量大,不但计算起来复杂,而且不利于分析问题。为有效提高故障特征量的质量,有必要将其中携带信息量不够丰富、贡献度不高、对故障状态不敏感的数据予以剔除。为此,本文将AT归一化与主元分析法用于故障特征量的提取,并结合KELM算法进行故障状态的判定,其故障特征量的提取及诊断流程如下:
1)归一化,首先对选取的几种故障特征量按照上文给出的归一化方法进行处理。
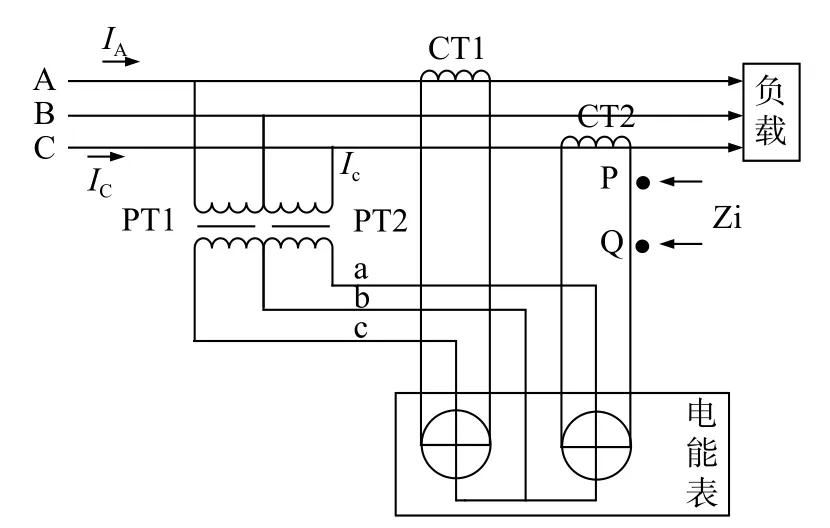
图2 电能计量系统的系统原理框图

表1 输入起始数据
2)故障特征量的提取,在得到归一化处理的互感器数据之后,运用Matlab工具进行PCA处理,用pareto生成图,当贡献率达到一定程度时(一般是95%),线面上无关紧要的维度不会显现,当没有超过95%时,软件只能有10维数据。
3)内核参数和内核函数的选取。进行完原始数据的PCA处理之后就要对各个故障类型进行类别标签的运算。将互感器数据的主成分作为输入参数,分别选择 RBF_kernel、lin_kernel、poly_kernel、wav_kernel函数作为输出层的内核函数,内核参数γ选取0,1,10,100进行分类训练。进行分类训练。将训练样本进行训练之后,通过选择合适的内核参数和内核函数,再对测试数据进行预测。
4)将步骤2)中所提取的故障特征量作为最终KELM的输入故障特征向量,选取其中2/3作为训练样本,其余作为测试样本,最后根据训练好的KELM进行故障状态判断[17-18]。
3 实例分析
本节的仿真实验采用选取云南电网有限责任公司电力科学研究院所提供的电能计量系统数据集。挑选出各种故障类型共80个数据用于测试,其余的数据用于训练。
由于输入的8中互感器数据值差别很大,在进行PCA之前先进行原始数据的归一化。计量系统互感器的电压电流初始输入和输出的数据信息一般不在[0,1]区域,但极限学习机网络模型的输入样本数据与目标样本数据为了计算快速都会在[0,1]区域,因此在进行PCA与ELM算法分析前,应该将这8维数据进行一定的缩减即数据归一化处理。
所获得的互感器数据经过PCA之后的第一主成分的特征值为0.111 1,其方差占总方差的38.34%,根据PCA特征降维的定义得出这对电力计量故障判断影响很大。前4个主成分的方差占总方差的99.99%,根据主成分的选则标准,原来的8项指标可由前4列主成分代替。最终计量互感器故障数据量大大减小,而特征值的减小,对之后的KELM极端学习分类有非常大的帮助,因此采取的PCA降维处理非常有意义。
结合上节所获得的信息,将计量系统互感器数据的主成分作为输入参数。在测试集上,ELM采用隐含层数目为5~15个的单隐层神经网络,选择sin、sig、hardlim函数作为输出层的传递函数,进行分类训练。而KELM采用隐含层数目为5~15个的单隐层神经网络,选择RBF_kernel、lin_kernel、poly_kernel、wav_kernel函数作为输出层的内核类型函数,内核参数γ选取0,1,10,100进行分类训练。将训练样本进行训练之后,再对测试数据进行预测。
用 Matlab 进行仿真,最后函数的训练时间以及训练精度如下所示结果如表2和表3所示。表2分别得出输出层的传递函数sin、sig、hardlim函数的训练时间和训练准确度,表3分别得出输出层的内核类型函数 RBF_kernel、lin_kernel、poly_kernel、wav_kernel函数的训练时间和训练准确度。由表可以明显的对比出最终的函数选择具有良好的训练精度以及较短的训练时间。对于ELM算法中的众多隐层数量以及激活函数中,选择了较为合理的sin函数以及隐含层数目为15的初始设定,对于KELM算法的内核参数γ以及内核函数中,选择了较为合理的RBF_kernel函数和内核参数数目为100的初始设定。
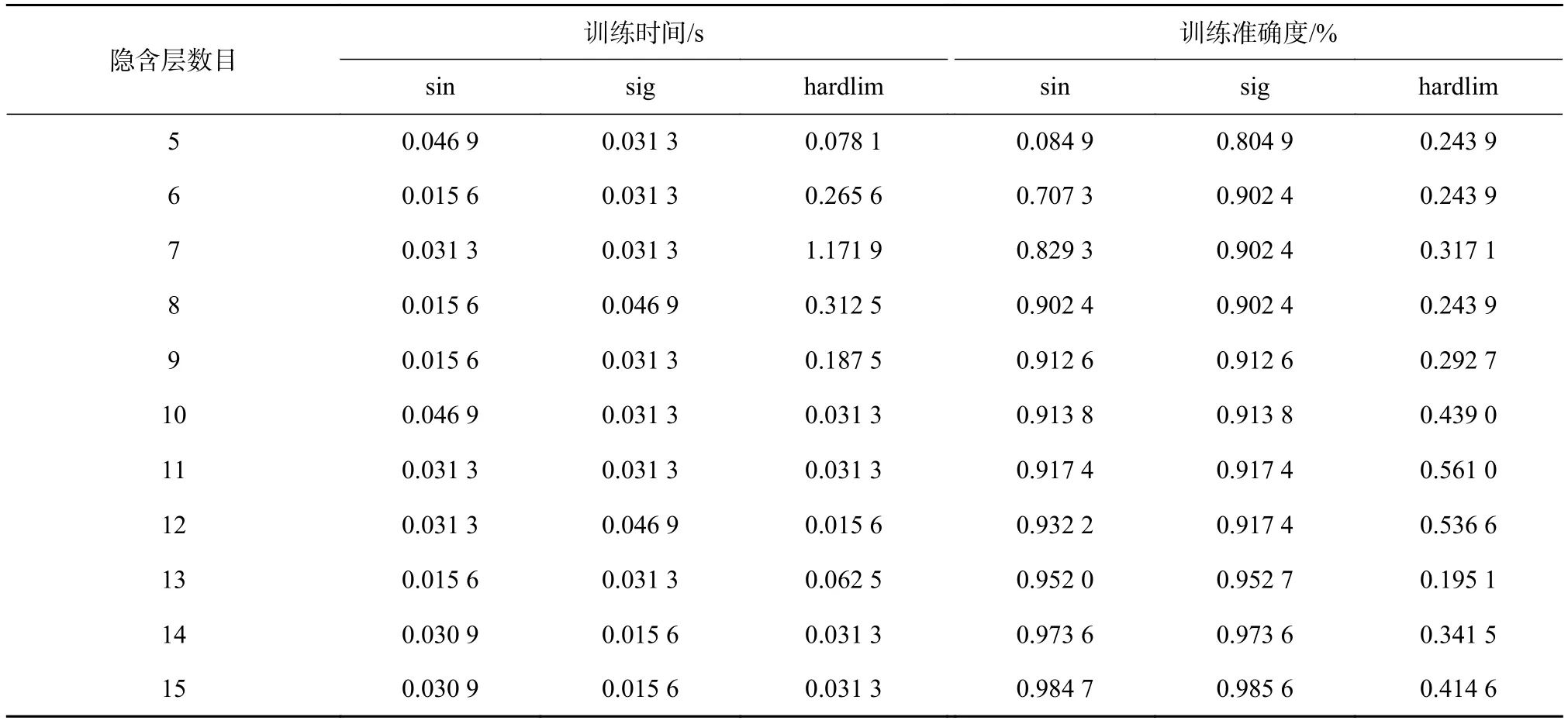
表2 ELM测试集训练时间及准确度对比
将上述数据分别用ELM,PCA-ELM,PSO-SVM和PCA-KELM进行仿真预测,得到图3的仿真结果。
每种算法对每组数据都处理30次,求出均值和标准差。由表4可知相比其他算法,PCA-KELM算法在故障数据集上具有更好的预测精度以及较短的训练时间。PCA-ELM的训练时间与PCA-KELM较为接近,但是预测精度较差。虽然SPO-SVM的预测精度与本文算法较为接近,但训练时间远远大于本文算法。总而言之,将本文算法应用于互感器故障诊断,取得了良好的实验结果,验证了本文算法的有效性。
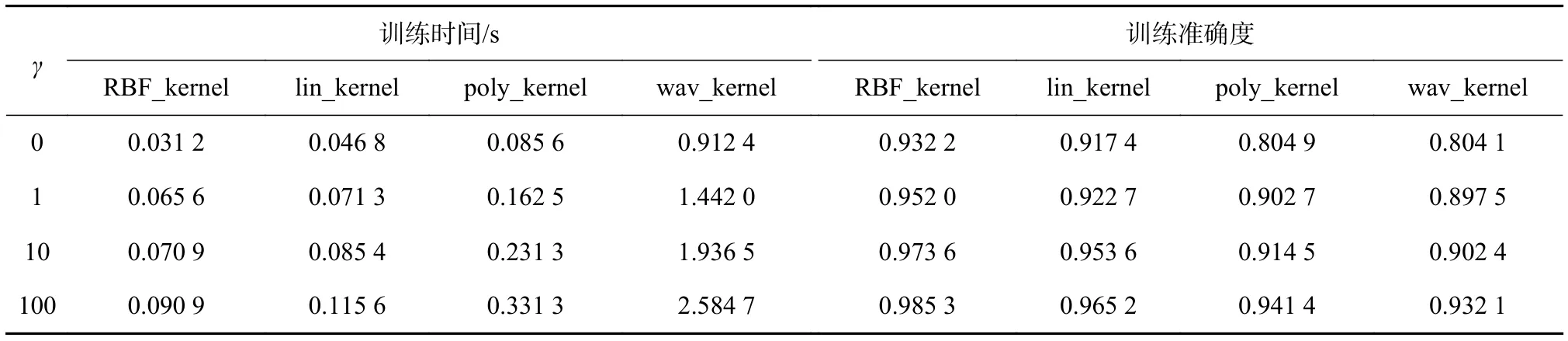
表3 KELM测试集训练时间及准确度对比
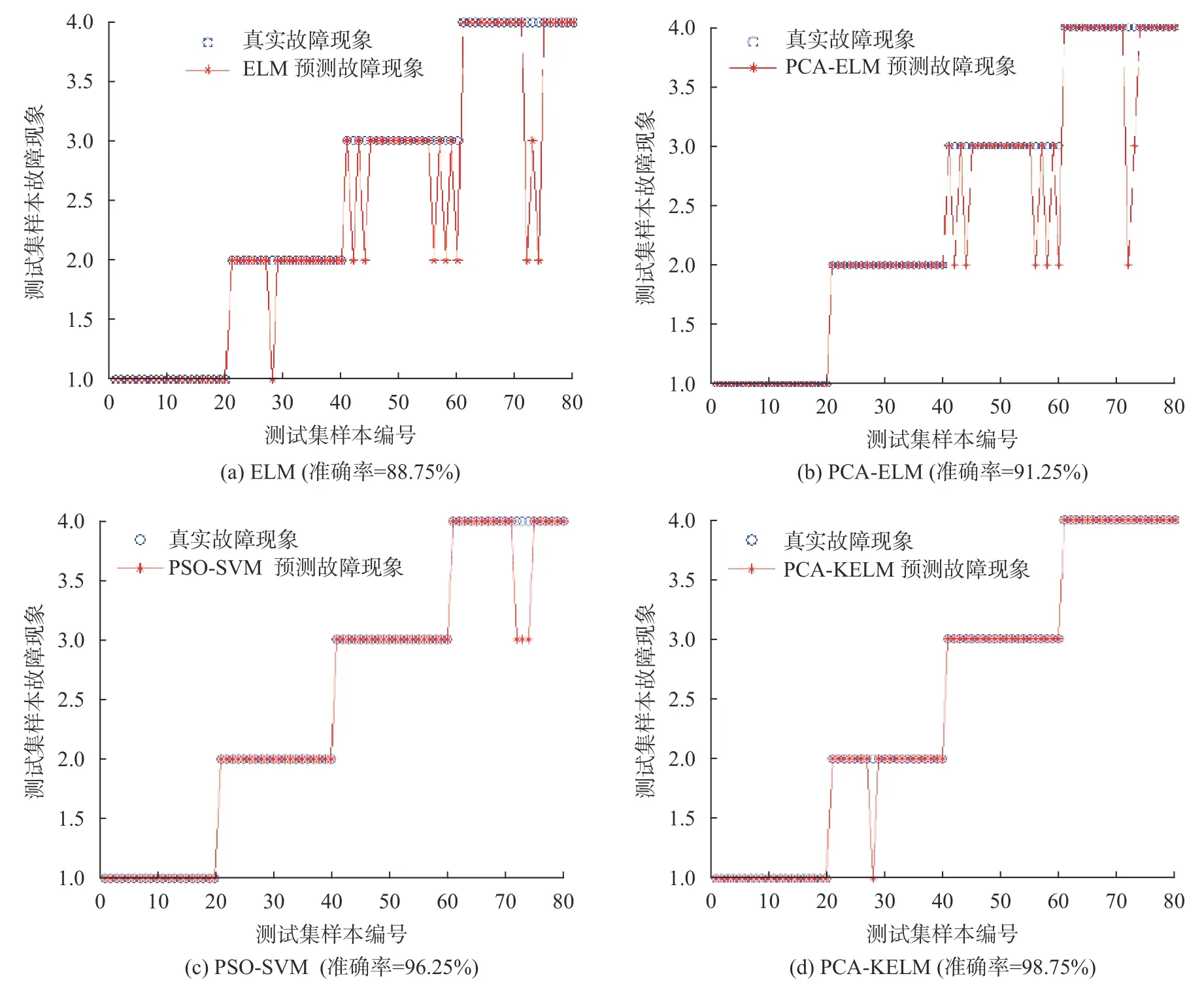
图3 不同方法测试集预测结果对比
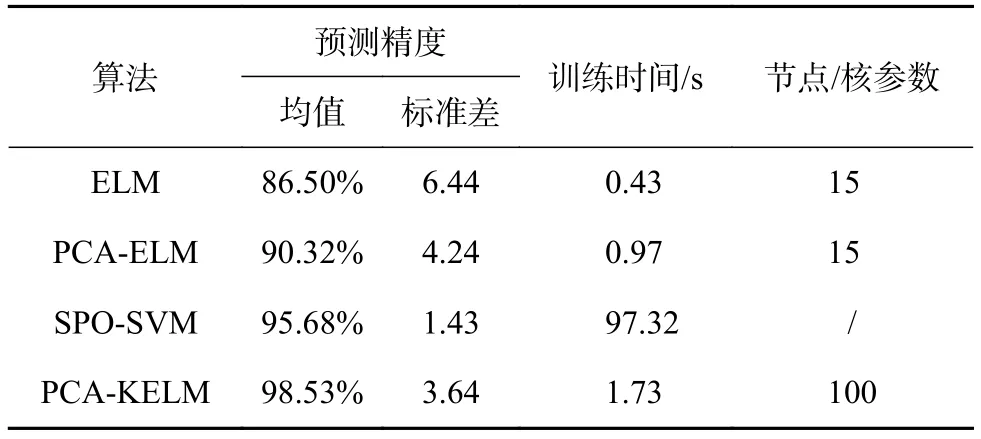
表4 不同方法的训练时间及准确度对比
4 结束语
通过以上仿真实验以及比较可以得出以下结论:PCA-KELM和AT的结合可以提高诊断率,不仅可以从算法分类能力中受益,而且可以改善分类器输入数据结构,适用于实际互感器初期故障诊断。尽管在本研究中已经取得了较为满意的故障诊断率,但在未来的工作中仍然需要解决一些后续工作。目前,这些实验的目的是诊断互感器发生的故障,这被认为是补救措施而不是预测措施。因此,在将预测能力纳入所提出的方法时,需要在以后来的研究中可以加以补充早期电流电压异常,互感器初期失效和发展趋势。
