改进型LSTM网络光伏发电功率预测研究
2019-12-14薛家祥
叶 興,薛家祥
(华南理工大学机械与汽车工程学院,广东 广州 510640)
0 引 言
光伏发电并网系统中光伏板易受太阳能辐射强度等气象因素以及光伏阵列自身因素影响,导致输出功率波动较大,发电功率具有明显的随机性,对电网的安全运行带来了一系列的安全问题,因而对光伏发电系统功率的预测显得尤为重要。
在光伏发电预测方面国内外科研人员在该领域采用各种理论与预测模型,进行了大量的探索与研究[1-3]。Muhammad Waseem Ahmad 等[4]提出了基于随机森林算法和额外树算法组合光伏发电预测模型,模型的输入充分考虑光伏发电的气象因素,从而预测出下一小时的光伏输出功率,但是预测时间过于短暂,无法长时间预测。De Giorgi等[5]采用多元线性回归方法,以光伏发电系统的太阳能辐射等气象因素来预测发电功率,但是精确度较差。单英浩等[6]提出了基于改进BP-SVM-ELM与粒子化SOM-LSF的微电网光伏发电组合预测方法,考虑目标光伏电站与其相连的光伏电站之间的能量关系预测光伏电站发电功率,该方法只验证了微电网而没有对大规模光伏电站进行研究。张雨金等[7]提出Stacking-SVM的短期光伏发电功率预测方法,该方法使用与测试样本相同类别的训练次数SVM,最后使用次级SVM对多个预测输出进行结合得到最终预测结果;但该方法仅考虑雨天、晴天、多云天气的预测,没有考虑具体的天气参数等因素的影响。
长短期记忆(long short-term memory,LSTM)网络是一种改进的循环神经网络(RNN),LSTM已被应用于空气质量指数、电力负荷、语音识别等的预测中,并且取得了较好的精准度[8-10]。本文综合了太阳辐射强度、温度、风速、相对湿度等多种气象因素,提出了基于改进型长短期记忆网络的光伏发电预测方法,结合一定数量的历史功率数据、光伏电站气象数据搭建光伏发电功率预测模型,通过Python3.6、TensorFlow、Spyder软件对所构建的模型进行训练和测试,并与单因素下的预测性能进行对比,结果表明多因素参与下的预测更加接近真实值。
1 LSTM深度学习原理
1.1 RNN神经网络与正则化一般推导过程
如图1所示,长短期记忆人工神经网络是基于循环神经网络,在其基础上进行优化与改进。因此本文先以循环神经网络推导其一般计算过程。RNN相比于前馈神经网络引入了定向循环,其能够处理输入之间的关联问题。

图1 RNN模型结构
RNN的一个特点是所有的隐含层共享一套(U,V,W)参数,以该模型推导RNN神经网络计算过程,RNN前向传导计算:

ot——模型输出层t时刻的输出向量。
模型反向传播的目的是为了得到预测误差E关于参数(U,V,W)的梯度,即对参数求偏导。每个时刻预测值与实际值都有一定的误差,对误差求关于共享参数的梯度,以便模型后续计算过程的参数调整。本文以误差Et为例推导梯度计算。Et对特征矩阵V的梯度计算有:

yt——t时刻的实际值。

由式(1)可知 ∂st依赖 ∂st-1,∂st-1依赖W、∂st-2,可得:
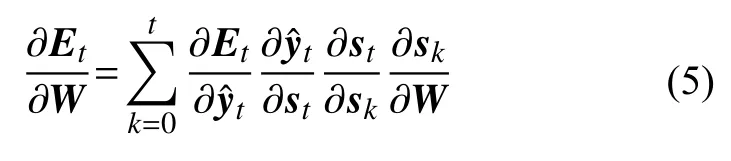
可见所有隐含层中共享权重W,并且变量依赖权值。在反向传播算法中定义一个delta向量:
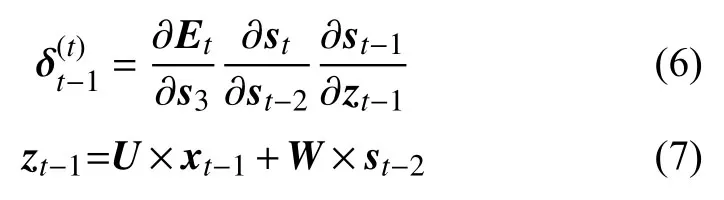
联合式(6)、式(7)可得:

同理可得:

到此,完成模型梯度的求解。
深度神经网络往往具有庞大数量的神经元,因此容易造成神经网络过拟合。一般引入DropOut层与正则化来解决模型过拟合问题。
DropOut层的作用是在神经网络训练的过程中,按照一定的概率丢弃神经元,并且丢弃是随机的[11]。DropOut同时也强迫神经单元和随机挑选出来的神经单元共同工作,以此来降低神经元节点之间的适应性,其示意图如图2所示。DropOut数学表达式如下:

正则化是对模型添加先验,从而减少模型的复杂度。当模型过拟合时,函数会倾向于噪声点,也就表明函数的曲线会在噪声点之间跳跃,可能会导致函数的切线斜率在局部变动非常大;对于多项式模型来说,函数导数的绝对值,实际上就是多项式系数的一个线性加和,这也就是说,过拟合的模型,至少某几个参数分量的绝对值非常大。因此,当系数增大时,损失函数会增大,由梯度的计算公式可以知道梯度的增大会使得系数的下降程度变大,这样就阻止了系数的进一步增大。本文采用L2正则化其数学公式:

E——模型损失函数;
λ——正则化参数。
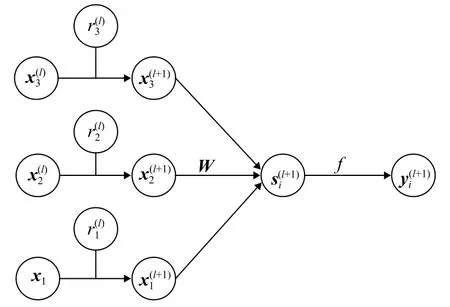
图2 DropOut示意图
1.2 标准LSTM模型
相比RNN神经网络,LSTM网络能够捕获间隔较大的时序数据之间的依赖关系,摆脱RNN网络训练后期出现梯度消失和梯度爆炸等问题。LSTM是将RNN的隐含层神经元替换成记忆单元,LSTM引入“门”来控制丢弃或者增加信息,神经网络通过单元状态上的门结构来选择记住或者遗忘信息。门结构中包含了sigmoid函数,函数输出区间 (0,1),“0”表示遗忘,“1”表示记忆信息。LSTM 单元中有3种调节信息流的门结构:遗忘门、输入门、输出门。
1)遗忘门:遗忘门决定了上一时刻的单元状态Ct-1保留到当前时刻状态Ct程度,遗忘门计算公式为:

其中ft为遗忘门输出值,σ为Sigmoid函数,bf为偏置。
2)输入门:输入门和一个tanh函数配合控制前一时刻网络的输入xt保存到单元状态Ct的程度。结合上一时刻单元状态Ct-1与遗忘门ft的乘积,再计算当前输入的单元状态,其计算公式如下:

3)输出门:输出门控制单元状态Ct输出到LSTM的当前输出值ht,首先运行sigmoid函数来确定单元状态输出部分,再将单元状态通过tanh函数进行运算,最终两者相乘得到输出,计算公式为

LSTM运行流程如图3所示,输出值ht已经达到神经元所需的阈值,则将其与当前层计算值相乘值作为输出进入下一层进行计算,未达到阈值,神经元则将其遗忘。

图3 LSTM网络运行流程图
1.3 LSTM模型改进方法
深度学习问题本质上就是找到神经网络的最小损失函数点,往往引入优化算法帮助更新与计算影响模型训练和模型输出的网络参数,逼近或达到最优值,寻找最小损失函数点,提高模型精确度。
本文采用 RMSProp算法[12]优化LSTM网络。RMSProp算法采用累积平方梯度,即算法初始迭代点占的权重很小,迭代点靠后的梯度的权重大,这样模型可以丢弃靠前的梯度,从而加速整体的收敛速度。算法采用了动态的调整模型学习速率,在计算累积平方梯度时加入了衰减系数来控制模型获取的历史信息等优点。其算法过程如下:
1)计算梯度g,定义 ∇w为权值的Nabla算子,m为训练样本数。其公式为:

2)计算累积平方梯度r:

其中 ρ为衰减速率。
3)计算权值更新:

其中 δ为一个十分接近于0的极小数,ε为学习速率。
4)更新权值:

2 基于改进型LSTM网络的光伏发电功率预测
2.1 光伏发电功率预测模型
本文提出基于改进型LSTM网络的光伏发电功率预测模型,模型首先需要进行样本训练过程,训练完模型后输入数据完成预测过程。预测模型训练过程需要不断进行误差与参数更新,迭代的过程需要计算机进行较大规模的运算,通常是将模型训练过程放在高性能的计算机上,或者利用云计算的计算能力将模型部署到云服务器上,快速得到训练模型。然后将模型移植到一般的计算机上进行预测,模型的整体流程如图4所示。

图4 光伏发电功率预测流程图
2.2 数据源及其预处理
本文光伏发电功率历史数据集来自澳大利亚艾利斯斯普林斯光伏电站,所采用气象数据(包括风速、温度、相对湿度、全球水平辐射、漫反射水平辐射),囊括了2016年3月3日-2018年5月9日的每日数据,数据每5 min采集一次。为了验证预测模型的性能,模型运行环境是以keras为前端,谷歌第二代人工智能学习系统TensorFlow为后端,在Python3.6中完成预测模型程序的编写,Spyder软件编译。并输入数据进行模型的仿真验证。
本文除了5个气象因素作为预测模型的输入序列,还需要24个历史光伏数据同时作为模型输入序列。表1为光伏电站历史部分数据。

表1 光伏电站历史部分数据
深度学习预测模型中,常对数据进行预处理,从而消除不同特征的量纲的影响和提高模型的计算能力和收敛速度,需对收集到的到的数据进行zscore标准化处理:

式中:x——标准化前的数据;
z——标准化后的数据;
µ——样本的均值;
σ——样本的标准差。
数据经过z-score标准化后平均值为0,标准差为1,数据呈标准正态分布。经过处理后的数据可以放在一个矩阵中进行运算,经过标准化处理后数据样本有效样本数是91 445,LSTM模型完成预测训练后,按照下式对预测的输出数据进行处理,从而得到真实的预测功率数据:

2.3 评价指标
深度学习中常采用均方误差(mean squared error,MSE)作为损失函数来检验和衡量模型的精确度和效果。MSE的定义如下:

式中:yt——t时刻实际发电功率值;
m——样本数据量。
从MSE的定义中可知,MSE是预测数据和真实值误差的平方和的均值。显然,均方误差值意味着模型预测值与真实值的接近程度。均方误差值越小,模型精度越高。
2.4 预测模型建立与仿真结果及分析
LSTM模型结构的搭建与参数的设置,对于样本训练过程的优化、训练时耗、预测精度起关键性作用。模型的搭建首先应确定网络深度,为了使训练最优分别对2~6层隐含层的网络进行对比,分别迭代100次,以此确定最佳的网络深度。
表2中比较了不同隐含层模型训练时间与训练后模型的损失函数值,隐含层层数少于4层时,损失函数值随隐含层数目增加而减小;隐含层层数大于4时,损失函数值随隐含层层数增大而增大,模型出现过拟合现象,训练时间也增多。由结果可见,当隐含层数目为4时,损失函数值最小,训练时间模型精度最高,误差最小。因此本文选用隐含层为4层深度的网络。本文模型分别采用350、200、100个神经元的LSTM层和50个神经元的普通层,并对每个层进行DropOut层操作。DropOut层选择一个常数0.25作为丢弃神经元输出的概率模型利用RMSPropS算法进行优化,衰减速率和学习速率分别取值为0.9和0.001。模型选取了5个气象参数与24个历史功率数据作为输入的LSTM层的训练样本,模型整体结构如图5所示。

表2 隐层数目对预测效果的影响

图5 光伏发电功率预测模型图
在相同的计算机上,将收集的数据中,进行标准化处理后,选取68 583样本数作为训练集,22 862作为测试集,选择迭代次数为100次。对网
络进行仿真实验。实验结果如图6所示,模型在迭代100次后训练的损失函数值与测试的损失函数值分别为0.077 8和0.078 2。选取预测值与真实值的100个数据进行对比,从图6(b)可以明显地看出两者曲线较为贴合。说明改进型的LSTM模型的预测精度较高,预测效果良好。

图6 模型预测结果
考虑到光伏电站的气象因素对发电功率影响,以及对预测结果的影响,本文在模型的基础上剔除气象因素的条件,仅仅依靠历史功率数据进行光伏发电的预测,并对两者进行对比。
单一因素输入的模型,训练集损失函数值从图7(a)可以明显看出比多因素输入模型的损失函数值大。以及测试集的损失函数值波动与最后收敛的值都比多因素输入下的测试集损失函数大。从图7(c)可以看出单一因素的预测结果比气象因素下的预测结果差。

图7 单一因素与多因素模型预测结果对比图
3 结束语
本文将深度学习理论应用于光伏发电系统功率预测,本文通过RNN与LSTM门计算过程推导了LSTM一般计算过程。建立基于改进型长短期记忆(LSTM)网络模型,仿真证明了模型充分考虑多气象因素下的预测性能优于单因素预测模型。所提模型基于Python语言与TensorFlow框架搭建,相比于其他语言搭建模型更加灵活。虽然本文所提模型能获得良好的光伏发电预测效果,但所提模型无法满足数据实时输入与输出的要求。下一步可通过优化模型得到实时输入输出的光伏预测数据以及将模型嵌入到具体的APP中,使得模型具有更大的实用性与普遍性。
