基于SPSS的31个地区的聚类分析
2019-12-12刘雪敏
摘 要:近年来,随着我国经济的发展,各个地区的经济发展水平也出现了较大的差异,我们抽取具有代表性的31个地区,基于SPSS对他们从人均食品支出、人均衣着支出、人均住房支出、人均家庭设备及服务支出、人均交通和通信支出、人均文教娱乐用品及服务支出、人均医疗保健支出和其他商品及服务支出八个方面进行聚类分析,分析所属同一类的地区所具有的相似性,为经济良好发展提供有效的建议。
关键词:SPSS;聚类分析;相似性
一、数据来源及分析
(一)数据来源
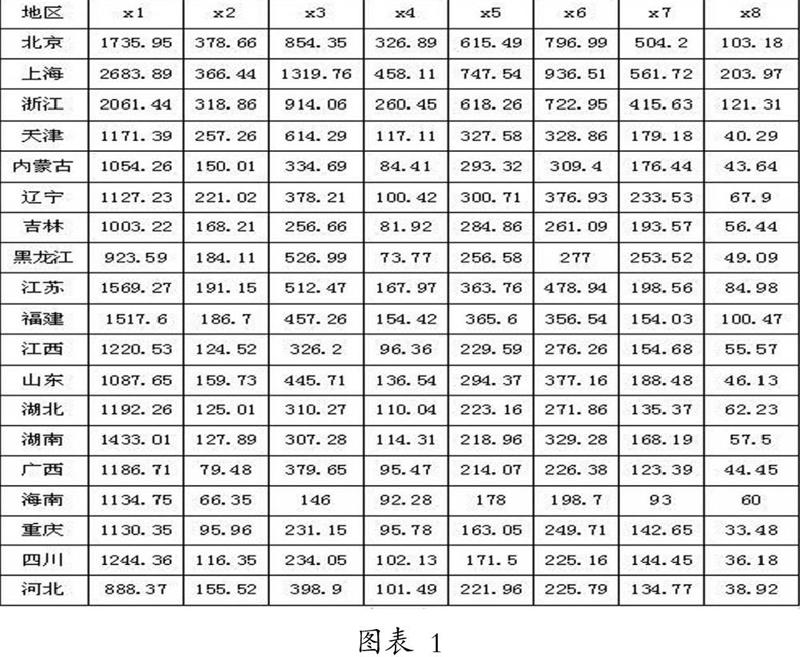
X1人均食品支出(元/人)X5人均交通和通信支出(元/人)
X2人均衣着支出(元/人)X6人均文教娱乐用品及服务支出(元/人)
X3人均住房支出(元/人)X7人均医疗保健支出(元/人)
X4 人均家庭设备及服务支出(元/人)X8 其他商品及服务支出(元/人)
图表 1
注:上图截取了31个地区一部分数据 数据来源:中国统计年鉴
(二)数据分析
以上选择的8个指标都很好的从衣、食、住、行四个方面反映了31个地区的人均消费水平,在一定程度了反映了不同地区的发展水平情况,通过运用欧式距离,将它们之间距离最近的两类合并为新类,然后计算新类与当前各类之间的距离,直至类的个数等于1时,画出聚类图,决定类的个数和最终分类数。
二、SPSS的聚类分析结果
(一)分类数的确定
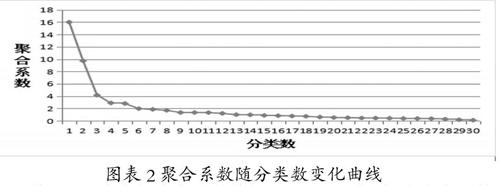
圖表2聚合系数随分类数变化曲线
将SPSS输出的聚合系数值导入EXCEL中,做出聚合系数随分类数变化曲线,由图表2看出分类数3到5类是最合适的,但由于分类数过多不利于分析,所以我们选择分为3类对31个地区进行统计分析。
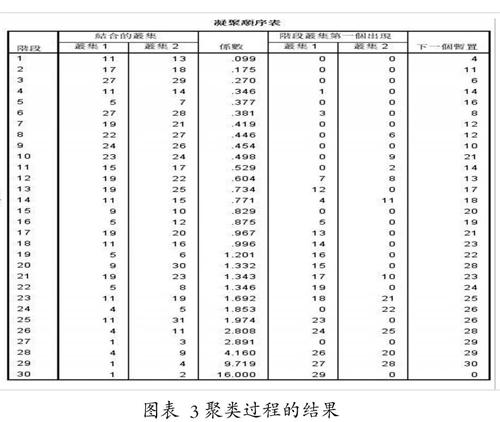
将数据导入SPSS软件,在“分析”菜单中选择“分类”,选择其中的系统聚类分析,将X1到X8八个变量选入变量框中,标注个案中选择地区,再点击右侧“方法”,聚类方法选择组内连接,区间测量采取平方Euclidean距离,并将其采用Z分数标准化,最后,单机确定按钮,SPSS则输出图表3。图表3是对每一个阶段不同聚类结果的反映,其中第四列为聚合系数,其值越大,代表其相似性越大,聚合损失量则会越少。
(二)具体分类情况
如上图所示是树状聚类图,由上面分析可知将其分为三类,易得分为北京、浙江、上海、其他地区,三类情况。
结束语:
将上海分为第一类,北京、浙江分为第二类,其他分为第三类,根据经验易得第一类为最发达地区,拥有各种机遇,主要发展高新技术产业;第二类为较发达地区,其经济上也有很大的突破,其应主要发展制造业,不断升级改进;第三类为经济欠发达地区,应该借用各地区的优势,积极发展自己特色的产业,提升经济实力。
参考文献:
[1]吕卫平,张晓梅.基于SPSS的聚类分析应用[J].福建电脑,2013(09):20-23.
[2]薛薇.统计分析与 SPSS 的应用 [M].北京:中国人民大学出版社,2011.
作者简介:刘雪敏(1998-),女,汉族,河北省张家口市人,本科,河北大学经济学院。研究方向:经济统计学。
