基于FunkSVD矩阵分解和相似度矩阵的推荐算法
2019-12-12王运倪静马刚
王 运 倪 静 马 刚
(上海理工大学管理学院 上海 200093)
0 引 言
近年来,互联网呈现出迅猛的发展趋势,用户接触到的信息也变得越来越多,如何从海量数据中找到用户感兴趣的内容变得至关重要。对于用户来说,可以节省搜寻时间,提高效率;对于企业来说,可以提升用户满意度,也为企业吸引更多的用户。因此,合适的推荐算法显得尤为重要。针对这一目标,广大专家学者提出了大量的相关算法,其中最广泛使用的有基于内容的推荐算法、协同过滤推荐算法和混合推荐算法等[1-2]。基于内容的推荐算法可以根据用户的已有数据找出兴趣相似的物品进行推荐,但是需要用户有足够多的数据;协同过滤推荐算法利用用户对物品行为的相似性找出相似用户进行推荐,最为经典;而混合推荐算法是上述算法的融合,推荐准确性更好。
但是,需要处理的用户数据往往面临稀疏等缺点,针对这些问题,文献[3]利用用户-标签-资源三维关系刻画用户偏好,并以此来找出相似用户从而进行Top-N推荐;文献[4]采用社交网络中的信息及用户标签数据来计算用户之间的相似度并作推荐,有效克服了数据稀疏的缺点;文献[5]提出将栈式降噪自编码器运用于基于内容的推荐模型中,可以深层次挖掘用户之间的潜在关系,同时与基于标签的协同过滤算法结合在一起进行推荐。根据上述文献中的方法可以在用户数据稀疏时较好地求出用户之间的相似度,然而,当一个用户没有数据或者数据极少时难以准确计算出用户之间的相似度。本文采用了FunkSVD矩阵分解与相似度矩阵的推荐算法来计算用户相似度。考虑到用户的偏好因素,利用用户评分数据与物品标签数据计算用户之间的相似度,同时,存在用户之间评分数据过少的情况,因此,将得到的用户相似度矩阵进行FunkSVD矩阵分解,加权矩阵分解前后的相似度值并做评分预测。经过Movielens数据集的实验表明,该算法的评分预测准确性得到了提升。
1 相关理论
1.1 传统基于用户的协同过滤推荐
在众多推荐算法中,基于用户的协同过滤推荐算法[6]被使用次数最多,并且效果最为理想,其主要思想为相似的用户具有相同的偏好,所以推荐的准确性更好。当两个用户对同一物品的评分越接近,则说明用户之间的相似性越高[7],用户之间共同评分的物品数越多,计算的相似度值也会更准确。其相似度计算方法如下:
(1)
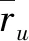
(2)
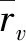
1.2 FunkSVD矩阵分解
在推荐系统中,包含许多用户和物品的数据,但是,单一用户的评分物品数经常是稀疏的,通过将用户对所有物品的评分值预测出来,可以将评分值高的物品推荐给用户,间接达到推荐的目的。对于填充用户物品评分矩阵这一问题,可以有很多的解决办法,其中矩阵分解较为理想[8]。矩阵分解法有传统的奇异值分解、BiasSVD算法、SVD++算法和FunkSVD算法[9]。奇异值分解简单直接,但是需要用户物品评分矩阵中没有缺失值,同时当数据量很大时计算十分耗时;BiasSVD在计算中考虑了其他限制条件,比如若有干扰用户评分因素的情况存在,则只适合应用在特定的场景;SVD++在BiasSVD的基础上又做了增强,增加考虑用户的隐私反馈,算法较为复杂,在实际应用中较少出现;而FunkSVD算法是奇异值分解的改进,避开了数据稀疏的缺点,同时将矩阵分解成两个新的矩阵计算时间较短,在实际中应用十分广泛[9]。
正如前文所述,FunkSVD是传统奇异值分解的改进版,它可以将目标矩阵分解成两个矩阵。将期望矩阵M进行如下分解:
(3)
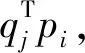
(4)

(5)
式中:λ为正则化系数,需要调参。对于这个优化问题,一般通过梯度下降法进行优化得到结果。
分别对pi、qj求导得到:
(6)
(7)
则在梯度下降迭代时,pi、qj的迭代公式为:
(8)
(9)
通过迭代最终可以得到P和Q,进而用于用户评分预测。
然而,本文没有将FunkSVD应用在用户评分矩阵中,而是提出了一种新的思路,将其应用在用户的相似度矩阵中,并且考虑到用户偏好的情况,在得到初始相似度矩阵时利用了用户评分数据与物品标签数据进行综合计算。同时,提出了新的模型将矩阵分解后的相似度值再次加权,有效避免了用户数据稀疏的情况。
2 用户相似度计算
对于基于用户的推荐算法而言,用户相似度计算的准确性高低是核心所在,同时,在本文提出的算法中也是极其重要的一步。
2.1 用户物品标签相似度
传统推荐算法是按照用户物品评分数据来计算用户之间的相似度,当两个用户对同一物品的评分相似时则说明两者具有极高的相似性,同时,共同评分物品数越多,则可以更精确地刻画出用户之间的相似度,与式(1)相同(假设得到的相似度为sim(u,v)item)[10]。
当数据稀疏时可以根据用户偏好来计算用户之间的相似度,用户的偏好即为标签。例如,当用户A对物品1的评分为4分,物品1由标签a与b组成,则可以认为用户A对标签a与b的评分均为4分,如果对同一标签有多次评分,则取值为它们的平均值。用户之间的标签相似度计算方法与式(1)类似,式(1)中的共同评分物品集合对应为共同标签评分集合即可(假设得到的相似度记为sim(u,v)tag)[11]。
根据前文计算的用户物品评分相似度与用户标签相似度可以计算出用户的物品标签相似度[12],计算方法如下:
(10)
式中:con为用户u与用户v的共同评分物品数;φ为参数,用于平衡用户物品评分相似度与用户标签评分相似度对物品标签相似度值计算的影响程度,实验中会根据数据调出。当两个用户的共同评分物品数一定时,参数值越小,则用户物品评分相似度越接近用户的物品标签相似度[13];反之,则需要用户标签相似度来共同刻画。
2.2 FunkSVD矩阵分解相似度
根据式(10)可以计算出任意两个用户之间的相似度,经过一系列的计算可以得到用户的相似度矩阵,如表1所示。用户与自身的相似度为1,与其他用户之间的相似度满足0≤sim(u,v)item_tag≤1。
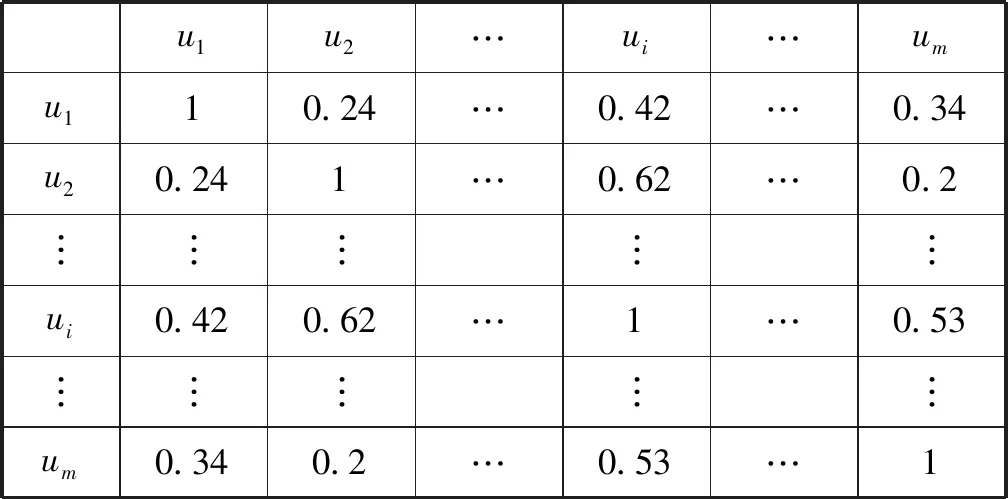
表1 用户相似度矩阵
当两个用户的最小评分物品数非常少时,即小于参数∂(与后文中的∂一致,实验中会根据数据调出),则可认为由式(10)计算的相似度不够准确,并将相应的用户相似度记为0,如将表1中的用户1与用户2,用户2与用户3之间的相似度值替换为0,最终可以得到一个新的用户相似度矩阵。然后,利用FunkSVD对其进行矩阵分解,生成的相似度矩阵如表2所示,并记用户u与用户v之间的相似度值为sim(u,v)matrix。
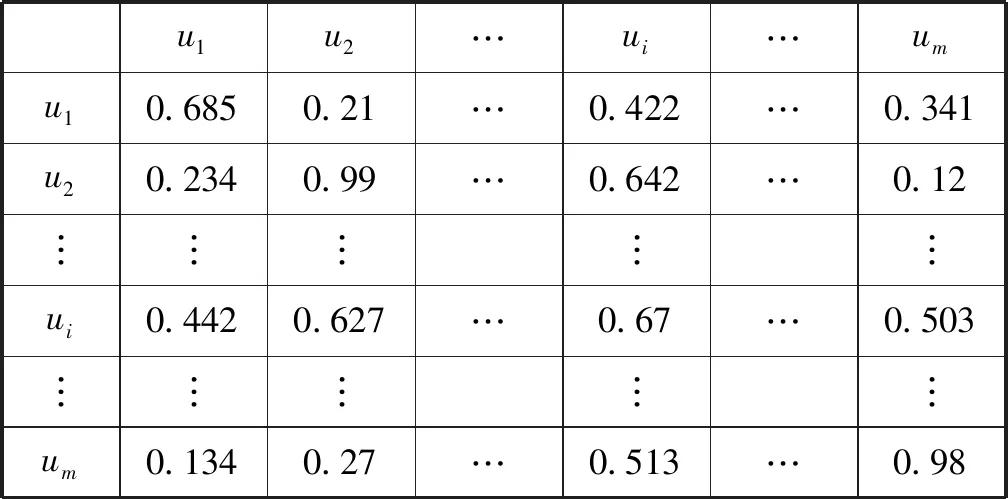
表2 矩阵分解生成用户相似度矩阵
2.3 用户综合相似度计算
根据用户物品标签数据可以计算出用户的相似度矩阵,同时,FunkSVD矩阵分解方法可以计算出一个新的用户相似度矩阵,所以,最终的用户综合相似度计算方法为:
(11)
式中:∂为参数,用于调节物品标签相似度与矩阵分解后的相似度对综合相似度值的影响程度,实验中根据数据调出;m为用户u的最小评分物品数;n为用户v的最小评分物品数。当两个用户的最小评分物品数一定时,参数值越小,则由物品标签算出的相似度值可以更好地表示为用户之间的综合相似度;反之,则需要由矩阵分解算出的相似度值来近似表达。
3 实验及结果分析
3.1 实验数据及评价指标
本实验所用数据为Movielens 100K数据集,MovieLens是由明尼苏达州大学的GroupLens项目组开发的,其中包含943名用户对1 682部电影的评分,评分记录多达100 000条。另外,每位用户对超过20部电影有评分,数据集有动作、冒险、儿童,纪录片等18种标签[14]。实验中,将数据集按照8∶2分为训练集与测试集。并采用平均绝对误差(Mean Absolute Error,MAE)作为评价指标,衡量算法的优劣。设预测的用户评分集合为{p1,p2,p3,…,pn},对应的实际用户评分集合为{q1,q2,q3,…,qn}[10],则平均绝对偏差MAE为:
(12)
式中:pi为用户对物品i的预测评分;qi为用户对物品i的实际评分。式(12)的值越小,说明预测值与实际值越接近,算法的准确性也就越高。
3.2 实验步骤
本文提出了基于FunkSVD矩阵分解和相似度矩阵的推荐算法,该算法在考虑到用户偏好的同时有效地缓解了用户数据的稀疏性问题。在采用Movielens 100K数据集的前提下,算法步骤如下:
步骤1根据用户评分数据计算用户之间的用户物品评分相似度;
步骤2根据用户的评分数据及物品标签数据计算用户的标签评分相似度;
步骤3利用式(10)对步骤1和步骤2中的相似度值进行加权组合,所得即为用户的物品标签相似度,同时,得到一个最初的用户相似度矩阵;
步骤4将步骤3相似度矩阵中两个用户最小评分物品数小于参数∂的相似度值设为0,并对修改后的相似度矩阵进行矩阵分解生成新的用户相似度矩阵;
步骤5对于步骤3和步骤4中的用户相似度矩阵,对其中任意两个相对应的相似度值利用式(11)进行加权计算,最终生成用户的综合相似度矩阵;
步骤6根据用户的综合相似度矩阵对目标用户采用式(2)进行评分预测;
步骤7对预测的结果进行平均绝对误差分析,衡量算法优劣。
经过上述步骤可以测算出此算法的评分预测准确性高低,同时,将与其他算法进行比较来验证该算法相对优劣。
3.3 参数调整
本文的算法在求解参数时经过了大量的实验。对于式(11),由于参数较多,可以分为前后两部分进行调试,对于用户物品标签相似度中的参数,只要存在参数φ使得用户物品标签相似度作为用户的最终相似度时结果最优,则该参数为最优参数。同理,可得公式后半部分的最优参数,将求解后的参数代入式(11)后可再由实验算出参数∂。
在用户物品标签相似度的计算中,参数φ可以平衡用户物品评分相似度与用户标签相似度对物品标签相似度值计算的影响程度。其值越小,则物品评分相似度可以近似刻画用户的物品标签相似度;反之,用标签相似度来描述较为合适。经过多次实验发现当参数φ变化跨度为10时MAE的值变化较为直观,同时,最优的几组数据在10到40之间,因此,不同参数φ与相似用户数下MAE值的变化情况如图1所示。
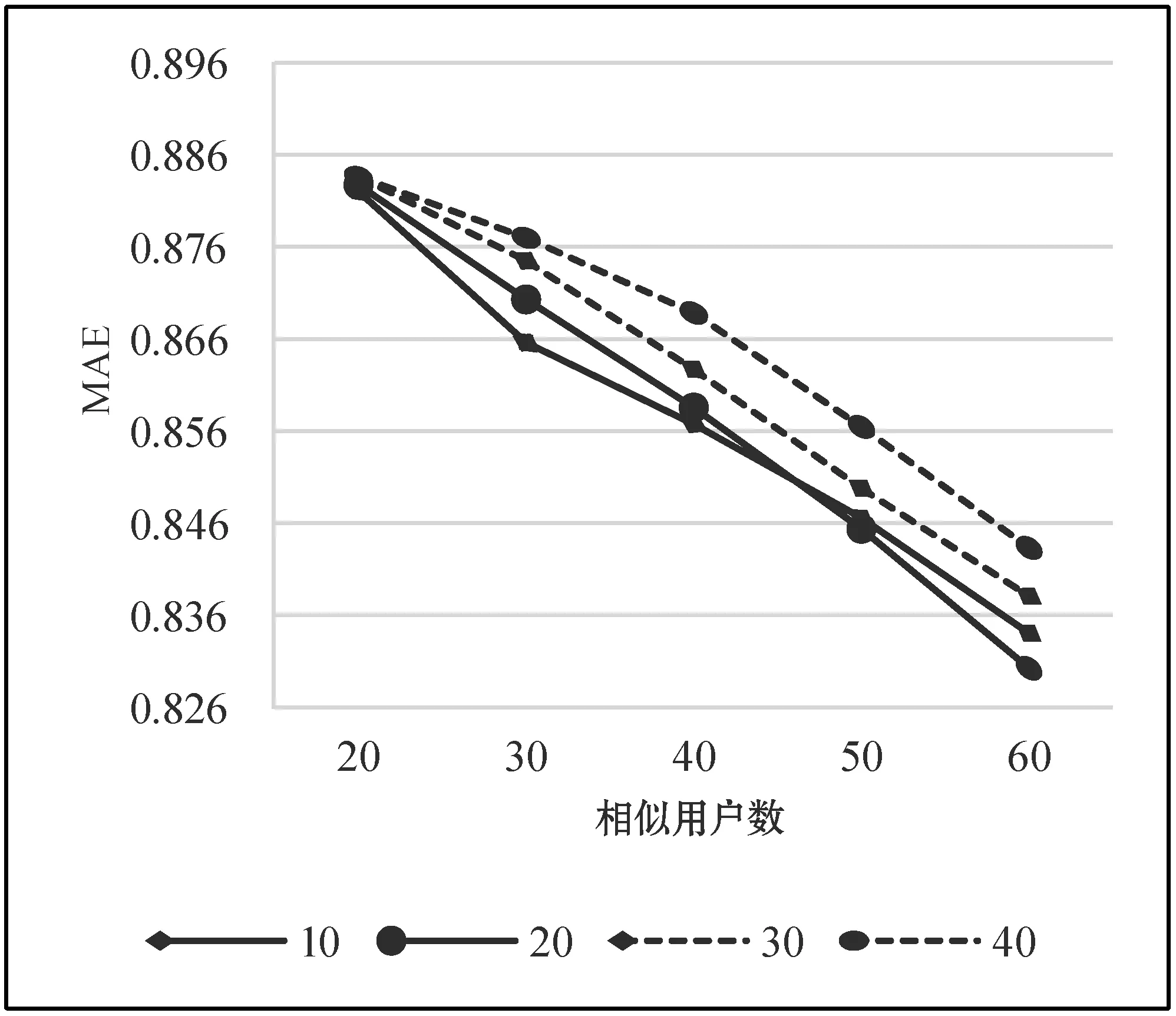
图1 不同参数φ及相似用户数对应MAE统计图
根据图1中数据可以发现,当参数为10或20时,MAE值的变化较为接近,且20较好;当参数为30时,MAE的值整体较大;当参数为40时,整体值最大。图中数据也说明参数取值小于20时,参数值越小,用户物品评分相似度作为用户的物品标签相似度会导致评分预测越不准确;参数取值大于20时,参数值越大,用户标签相似度来补充计算用户的物品标签相似度会使相似度不准确,而预测结果也会随之变差。最终,最合适的参数φ值应为20。
在FunkSVD矩阵分解的计算中,经过多次实验表明参数α为0.1、λ为0.02时结果较好。同时,分解的矩阵存在维度K,通常而言,维度K取值很小时矩阵分解的效果就已经很好,且由多次实验发现最优解在10以内,因此可得图2所示数据。

图2 不同参数K及相似用户数对应MAE统计图
由图2可知,当参数K值大于6时,参数值越大,不同相似用户数下的MAE值整体越大,即结果越差。同时参数值小于6时,MAE值虽然整体较为接近取为6的值,但依然较差,固最优参数K取值应为6。
式(11)中,存在参数∂,当两个用户的最小评分物品数一定时,参数值越小,则物品标签相似度作为用户的综合相似度结果较好;反之,需要矩阵分解后的相似度作为补充,即加权组合才可以。多次实验发现最优的几组数据在参数值取为10到40的时候产生,可得图3所示数据。

图3 不同参数∂及相似用户数对应的MAE统计图
由图3可以得出:当参数值从10到30时,MAE的值整体逐渐变小;当值为40时,MAE整体变为最大。这说明了当参数值为30时,用户的物品标签相似度作为用户综合相似度会使用户评分预测结果较好,参数值过小,则用户物品标签相似度的计算不够准确;参数值过大,矩阵分解后的相似度值作为补充会使最终的评分预测准确性降低。所以,最合适的参数∂应取值为30。
3.4 算法比较
本文的推荐算法通过准确计算用户之间的相似度值从而达到提高用户评分预测准确性的目的,为了验证该算法的有效性,将基于FunkSVD和相似度矩阵的推荐算法(recommendation algorithm based on FunkSVD matrix decomposition and similarity matrix,FSM-RA)与其他几种经典的推荐算法进行比较,进行比较的推荐算法有:Tag-CF(基于标签的协同过滤推荐算法)、Item-CF(基于物品的协同过滤推荐算法)和IT-CF(基于物品与标签的混合协同过滤推荐算法)。实验结果如图4所示。
由图4可知:基于物品的协同过滤推荐算法准确性最差,而且随着相似用户数的增加没有显著变化;基于标签的协同过滤推荐算法的准确性比基于物品的协同过滤推荐算法的较高。同时,随着相似用户数的增加,评分预测的准确性会有所提升,可能在该数据集下,利用用户偏好来计算用户之间的相似度比基于物品评分效果较好;而基于物品和标签的混合协同过滤推荐算法与基于标签的相比,准确性稍微高一点,随着相似用户数的增加准确性有所增加,也说明了利用用户评分与用户偏好综合计算相似度效果更好;最后,对于本文中的算法,即基于FunkSVD矩阵分解和相似度矩阵的推荐算法,评分预测的准确性整体最高(MAE值最小),表明了即使用户数据稀疏也可以通过对相似度矩阵进行矩阵分解,再与原先相似度矩阵加权的方式来更准确地计算相似度值,同时也说明了本文算法是较优的。
4 结 语
传统基于用户的协同过滤推荐算法在计算用户相似性时经常面临数据稀疏的缺点,而利用标签或者物品标签混合的方法来计算用户相似度可以较好地改进这个缺点。但是,当有新用户或者物品数目过大时仍然面临稀疏性的问题。因此,本文提出了一种基于FunkSVD矩阵分解和相似度矩阵的推荐算法。该算法在考虑用户偏好的同时利用FunkSVD对相似度矩阵进行矩阵分解,并采用新的模型,将矩阵分解前后的对应相似度值进行加权组合。经过Movielens数据集的实验表明,该算法有效克服了数据稀疏的缺点,在评分预测的准确性上相较于传统算法有所提升。另一方面,该算法也验证了矩阵分解技术在相似度矩阵中的应用会有奇效。
但是,在计算综合相似度的过程中,多个参数的求解方式没有严格的科学依据,有可能陷入局部最优解,而非全局最优解,因此,接下来会寻找关于参数求解的相关科学依据。同时,对于最近几年比较火热的技术,例如深度学习也可以用于推荐算法[15],应当与这种方法也做一次比较,所以,也会继续研究深度学习在推荐算法中的应用[16]。
