基于流量水印的网络跳板检测算法*
2019-12-11赵鑫鹏邹福泰
赵鑫鹏,吴 越,邹福泰
(上海交通大学 网络空间安全学院,上海 200240)
0 引 言
在基于僵尸网络的攻击中,攻击者通常会通过一些中继主机进行命令的发布,窃取数据也通过一些中继主机回传到登台服务器,在实现网络攻击的同时隐藏自己,逃避检测,这给攻击源追溯工作带来了很大的挑战。
本文针对基于跳板的网络攻击,提出了一种基于丢包的流量水印算法,具有隐形性和鲁棒性,同时也实现了在线检测,确保了攻击源追踪的实时性。本篇论文组织如下,第1节介绍了跳板检测的相关研究,第2节分析了基于跳板的网络攻击的流量特点,第3节介绍了流量水印算法的实现,第4节从隐形性和鲁棒性等角度分析了流量水印算法的性能,第5节作出总结。
1 相关研究
自从Staniford-Chen和Heberlein[1]首次提出跳板检测的问题以来,学术界提出了若干种使用加密流量的跳板,可以分为被动检测与主动追踪两大类。
在被动检测方面,Zhang和Paxson[2]等人提出的基于ON/OFF的方法是第一种基于时序的方法,Yoda和Etoh[3]等人提出了一种基于偏差的跳板检测算法,偏差定义为两个连接的平均传播延迟和最小再传播延迟之间的差,若观察到的两个不相关的连接的偏差足够大,可以与同一连接中的连接偏差区分开来。Wang[4]等人提出了一种基于分组间延迟(IPD)来检测跳板的方案,他们的研究表明流量的IPD特性可以再路由器及跳板之间保留。Blum[5]等人提出并分析了基于计算学习理论和随机游走分析思想的跳板检测算法。
在主动检测方面,Wang和Reeves[6]第一次提出了一种流量水印方案,该方案通过调整数据流中所选数据包的延迟,将水印嵌入到流量中,如果延迟扰动不是很大,则水印信息可以沿连接链保留,到目前为止,流量水印方案都是唯一有效的跳板溯源防范。Mazurczyk[7]和Iacovazzi[8]等人撰写的综述对现有的流量水印方案做了综合的分析和比较,现有的绝大多数方案都是基于数据包的时序实现的,RAINBOW[9]是一种典型的基于时序的流量水印算法,对每个数据包都会做出延迟,延迟的值由一个累积函数计算得出。RAINBOW的检测算法基于未嵌入流量水印之前的IPD与检测器捕获到的数据数据流的IPD之间的比较。Wang[10]提出了一种基于间隔质心的水印方案,在该方案中,时间轴分为若干个长度为T的间隔,对于每个间隔,计算该间隔内数据包时间戳的平均值作为质心,在流量水印算法中,数据流的某些数据包被延迟发送,因此每个时间间隔的质心也发生了变化,检测算法也是基于每个时间间隔的质心的统计分析。其他研究人员也提出了各种类似的方法[11-13]。
基于时序的算法也面临很大的挑战,因为IPD可能会受到网络波动的影响,或者被攻击者人为的修改,因此一些研究人员提出了具有鲁棒性的算法,可以对抗定时扰动、重新打包和糠包注入等攻击。
Iacovazzi[14]提出了一种称为DROPWAT的流量水印算法,人为的丢弃特定的数据包以在流量中嵌入水印,具有很好的隐形性和鲁棒性,但是该论文在检测流量水印时没有考虑TCP慢启动对IPD的影响,检测也是离线检测,有一定的滞后性。本文受该论文启发,也使用丢包的方法生成流量水印,但是考虑到了TCP慢启动流量传输过程中的网络环境变化对IPD的影响,改进了流量水印检测算法,并实现了在线检测。
2 基于跳板的的攻击及其特征
2.1 数据窃取攻击
攻击者为了窃取用户的隐私数据,会设法在用户的计算机上安装恶意软件(诱导下载等),这类恶意软件都带有远程控制工具(RAT, Remote Administration Tools),可以使攻击者控制受害主机,执行监听用户的键盘输入,屏幕监视,窃取网站访问记录,窃取文件等多种攻击,并且定期的将窃取到的数据传送到登台服务器(Staging Server),隐私数据的泄露会给用户带来极大的损失。为了避免暴露登台服务器的IP地址或者地理位置,攻击者会设置若干个跳板来躲避追踪。
2.2 跳板
在数据泄露阶段,跳板有多种实现方式,例如http代理,shadowsocks代理,TOR代理等等;对于一些具有针对性的攻击,攻击者会通过反向shell连接到受害者主机,获取到受害主机的shell之后进行攻击,在这种场景下跳板使用的协议为ssh协议。从以上分析可知,现在基于跳板的网络攻击中,跳板使用的协议大多为加密协议,因而基于数据包大小的流量水印算法在这些场景下的隐形性会失效,并且需要在通信流的源头加入水印,否则会破坏加密数据包的完整性,导致通信双方无法正常通信,达不到跳板检测的目的,使用基于时间延迟的流量水印算法则可以避免以上问题。
由于在基于跳板的网络攻击中,跳板都是充当代理的角色,因此我们可以针对代理的特征来分析跳板的特征。
2.3 丢包给跳板通信带来的时间延迟
丢包现象是计算机网络中很常见的现象,一般由以下几种原因造成:硬件故障,网络拥塞导致的缓冲区溢出,误码率较高的组件导致的数据损坏,数据包过滤等等,在TCP/IP体系中,由TCP协议来处理丢包问题,而现有的TCP协议采用快重传算法来解决丢包问题。
在出现丢包的情况下,跳板在传输层处理数据包的行为如图1所示。
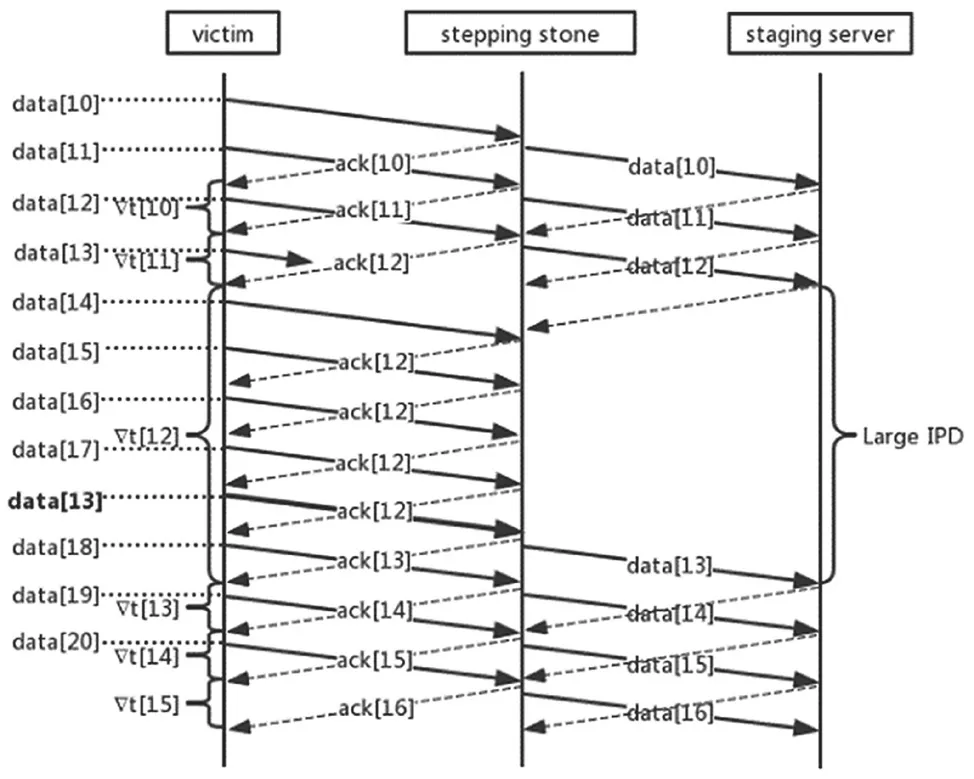
图1 丢包给跳板通信带来的时间延迟
图的左半部分是发生丢包现象时TCP协议的快重传算法,数据包[13]被丢弃,跳板接没有收到数据包[13],却收到了后续的数据包,便连续发送三个数据包[12]的确认包,数据发送方意识到数据包[13]丢失,重新发送丢失的数据包。而跳板在接收到数据包[13]之前,会重新组织乱序的数据包,而不会将数据包[14]-[17]发送给下一跳,这样数据包[12]和数据包[13]之间就形成了较大的时间延迟,我们可以利用这个特性生成流量水印。
3 流量水印
流量水印是一种主动流量分析手段,在数据发送端主动调制数据流,例如改变数据包之间时间延迟、改变数据包大小、改变数据传送速率等等,将水印嵌入其中,在数据接收端附近或者跳板附近便可以根据对流量进行水印检测,从而对恶意流量进行追踪。
3.1 流量水印系统
流量水印系统分为两个模块:流量水印生成模块和流量水印检测模块,流量水印生成模块部署在受害主机的防火墙,作用是在受害主机与跳板之间的通信流量中嵌入流量水印,同时记录流量水印的IPD信息,定期地将IPD信息同步到流量水印检测器,流量水印检测器的作用是在线检测流量水印,由数据报获取模块、异常检测模块和特征匹配模块三个子模块构成,对于监听到的数据流,首先进行异常检测,对于符合特征的数据流进行特征匹配,若匹配成功,则说明检测到了流量水印,具体如图2所示。
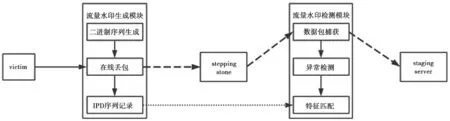
图2 流量水印系统
3.2 流量水印生成模块
流量水印生成模块的作用是伪随机的丢弃一些数据包,使其看上去像是由于网络拥塞而产生的丢包现象。流量水印生成模块由二进制序列生成模块、在线丢包模块和IPD序列记录模块三部分组成。
二进制序列生成模块的作用是生成长度为N,1出现的概率为P的0-1序列B,输入为种子seed,两个大素数q1,q2,大整数M以及概率P。该模块首先根据递推公式

生成一个伪随机整数序列,并对一个大整数M取模,即可以得到取值在[0,M-1]之间的伪随机序列S,对于S中的任意一个元素Si,若:

则Bi的值取为1,否则取为0,这样既可得到1出现的概率为P的0-1序列B。
在线丢包模块的作用是根据伪随机序列随机的丢弃数据包,对于受害者与第一个跳板的通信,从三次握手之后的数据包开始计数,对于第i个数据包,若Bi为1,则丢弃该数据包,对于每个数据包,最多会被丢弃一次。
在Alice与Bob的TCP通信过程中,Alice发送的第i个数据包的序列号seqi可以通过Alice发送的第i-1个数据包的序列号seqi-1和TCP报文长度leni-1计算得出:

因此可以通过序列号判断数据包是数据流中的第几个。
IPD序列记录模块的作用是记录数据流中的IPD,并定期的将该序列同步到流量水印检测器,用于流量水印的检测。根据图1所示,跳板在转发发出第i个数据包的时候会向受害主机发出第i个数据包的确认包,因此我们可以通过确认包的时间间隔来计算流量水印的时间间隔,第i个数据包和第i+1个数据包之间的时间间隔∇ti定义为第i个数据包的确认包与第i+1个数据包的确认包的时间间隔。每次流量水印生成之后,都可以得到相应的IPD序列∇t,定期将∇t通过网络同步给各个检测器即可。
流量水印生成模块的算法伪代码如下:
functiongenerator(N,seed,p,,q1,q2)
foriin[0,N-1]
seed←seed×q1+q2(mod M)
ifseed<M×pthen
Bi←1
else
Bi←0
end if
end for
whilecapturing packet
ifipsrc==ipvic
andipdst==ipssthen
ifBnumber==1then
drop(packet)
end if
end ifipsrc==ipss
andipdst==ipvicthen
ifnumberack=i+1
∇ti←tpacket-tlast
i←i+1
tlast←tpacket
end if
end if
end while
return∇t
end function
3.3 流量水印在线检测
流量水印检测器一般要部署在网络的关键节点,由于一般网络中的主机数量众多,经过流量水印检测器的流量也很大,这给在线检测带来很大挑战,因此很多流量水印算法都采用离线检测的方法来检测流量水印,这样会有一定的延迟性,本文提出一种在线流量水印检测算法,可以实时在线检测流量水印。
实时检测要求算法对于内存和CPU的消耗保持稳定,并且能够及时对一个数据流是否带有流量水印做出判断。本文所提出的流量水印检测算法使用关联容器map<key,value>来管理内存,其中key是数据流的源IP地址和目的IP地址通过编码生成的,具有唯一性,同时也可以快速查找,value是存储数据流信息的对象,在循环捕获数据包的过程中动态维护map,保证检测进程平稳运行。流量水印检测算法分为三步:数据包捕获、异常检测与特征匹配,流量水印检测算法伪代码如下:
functiondetector(map,packet)
stream←encode(IPsrc,IPdst)
ifSYN==1 and ACK==0then
ifmap[stream]!=NULLthen
outlier(map[stream])
delete map[stream]
set(map[stream],seq,time)
else
set(map[stream],seq,time)
endif
elseifSYN==1 and ACK==0then
ifmap[stream]!=NULLthen
add(map[stream],seq,ackseq,time)
endif
elseifFIN==1then
ifmap[stream]!=NULLthen
outlier(map[stream])
delete map[stream]
map.erase(stream)
endif
else
ifmap[stream]!=NULLthen
add(map[stream],seq,len,time)
endif
endif
end function
数据包捕获是算法的第一步,也是对内存资源消耗最多的环节,在抓包的过程中要做到及时释放内存,才能使保证线上检测的平稳运行,该步骤实现如下:
对于每个捕获到的TCP数据包,首先对源IP地址-目的IP地址进行编码得到key值stream,然后根据其包头信息判断该数据包在TCP通信过程中所处的阶段(握手阶段,通信阶段,挥手阶段)进行讨论:
1)握手阶段:根据stream查找其在map中是否存在对应的value,若存在,则对该数据流进行异常检测,然后将其重置,释放内存并记录捕获该数据包的时间,否则为其创建一个节点value,将<key,value>插入到map中;
2)通信阶段:根据stream查找其在map中是否存在对应的value,若存在且数据包顺序正确,则记录捕获该数据包的时间,若节点内的数据包大小超过设定的阈值N,则对该数据流进行异常检测;
3)挥手阶段:则根据stream查找其在map中是否存在对应的value,若存在,则对该数据流进行异常检测,并及时释放其占用的内存。
数据包捕获算法的伪代码如下:
objectNode
seqlast
lenlast
time[N]
numpacket
endobject
functionset(Node,seq,t)
ifNode==NULLthen
Node←newNode()
endif
numpacket←1
seqlast←seq
time[0]←t
end function
functionadd(Node,seq,len,t)
ifseq==seqlast+lenlastthen
seqlast←seq
lenlast←len
time[numpacket]←t
numpacket←numpacket+1
endif
end function
异常检测步骤是对每个数据流的数据包时间间隔∇tˆ做统计,若
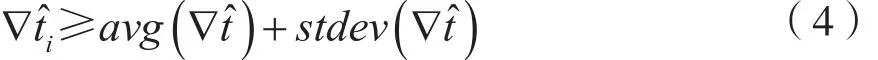
则认为∇tˆi是较大的时间间隔,统计其中较大的∇tˆ 的数量,并求出比例r,若

则进行特征匹配。
特征匹配是将受害主机端统计的∇t与∇tˆ做匹配,对于每对∇ti与∇tˆi,计算他们在数据流中的特征值(即∇ti在∇t 中的偏离程度)
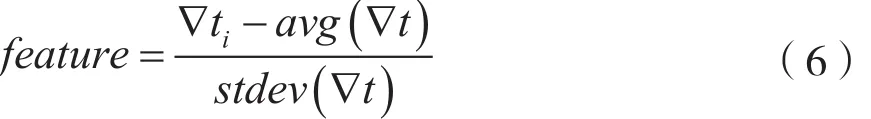
若特征值之差小于设定的阈值α,则∇ti与∇tˆi匹配成功,统计匹配成功的∇t所占比例rate,若:

则表示检测到了流量水印,其中β是设定的阈值。
3.4 流量水印系统部署与检测
将蜜罐机部署在物理可控的范围内,在蜜罐机中放入活跃的带有远程控制工具(RAT, Remote Administration Tools)的恶意软件样本,通过分析样本的网络活动获取其第一跳跳板的IP地址,并部署一台linux服务器作为该蜜罐机的防火墙,在该防火墙中加载流量水印生成模块,在蜜罐与第一跳跳板的通信流量中嵌入流量水印。
在网络关键节点处部署流量水印检测器,在检测器中运行流量水印在线检测程序,在检测到流量水印之后,将IP地址传送到MySql服务器中。
流量水印系统部署如图3所示。

图3 流量水印系统部署
4 检测结果分析
4.1 评价指标
流量水印系统的应该从隐形性与鲁棒性两个方面去评价。
隐形性方面,可以使用Kolmogrov-Smirnov测试来比较正常流量和嵌入水印的流量。给定参考分布函数F(x),则K-S测试值为:

其中,Fn(x)是n个采样值的分布函数。
在鲁棒性方面,测试在不同网络拥塞程度下,流量水印检测的准确率与误报率。准确率(Accuracy)计算公式为:
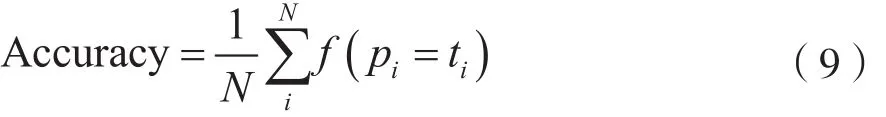
其中,N为流量中数据流的数量,f为指示函数,ti为样本真实的标签,pi为预测值。
误报率(False Positive Rate, FPR)计算公式为:

其中,FP为误报的数量,TN为未嵌入流量水印且判断正确的样本数量。
4.2 实验结果
攻击场景按照图搭建,蜜罐部署在实验室内,中运行Zeus病毒,跳板使用aws的服务器,两个跳板分别部署在英国机房和美国机房,采用ShadowSocks代理,加密方式为aes-256。
隐形性方面,计算流量水印参数p取不同的值得情况下与正常加密流量的K-S距离,结果如表1所示。
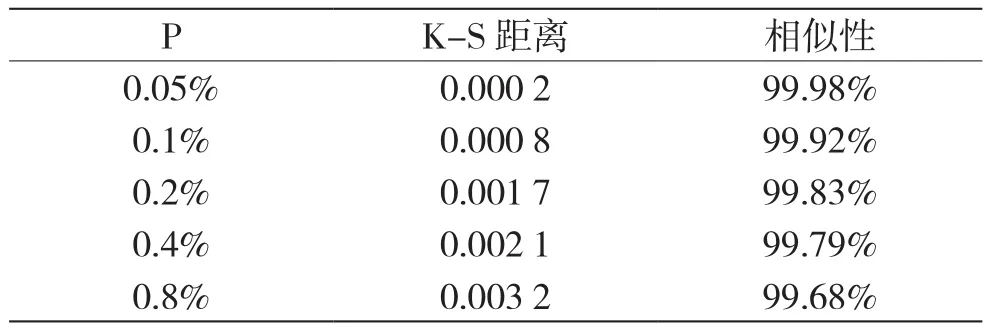
表1 隐形性测试结果
结果表明,即使是丢包概率取为0.8%,嵌入流量水印的流量与正常流量仍有99.68%的相似度,我们可以认为对于未授权的第三方流量水印是不可识别的。
在鲁棒性方面,实验室带宽为50 Mb,测试分别占用10 Mb,20 Mb与40 Mb的情况下,流量水印的准确率与误报率,结果如表2所示。
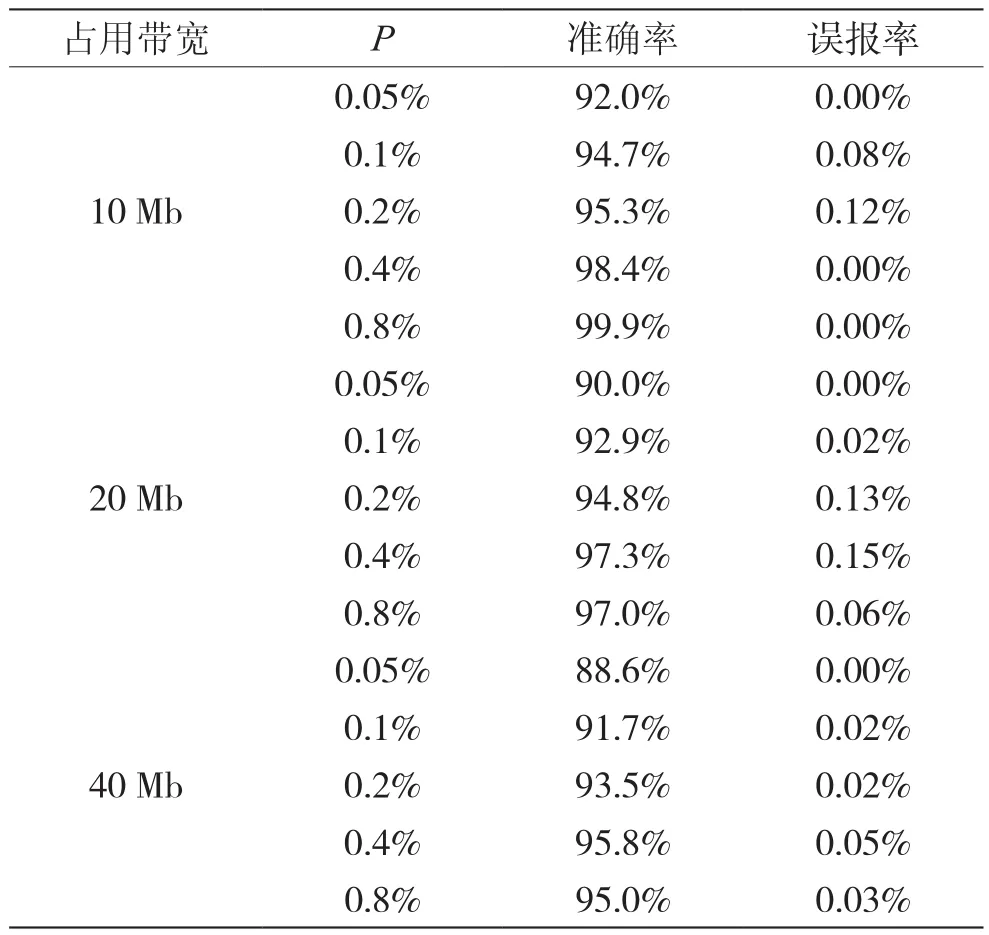
表2 鲁棒性测试结果
结果表明,即使是在网络拥塞的情况下,P取0.4%与0.8%仍可以保证该算法具有95%以上的准确率与0.15%以内的误报率。
5 结 语
本文主要研究了基于流量水印的网络攻击跳板检测方法,探讨并借鉴了国内外研究中常见的跳板检测方法,考虑到丢包现象给跳板间的IPD造成的影响,本文采用了基于丢包的流量水印算法,并且考虑到TCP慢启动与网络波动给IPD带来的影响,本文根据发送端收到的ack确认包对每两个数据包之间的延迟做出估计,并实现了流量水印的线上实时检测,并通过实验对本算法的隐形性和鲁棒性作出评估。
流量水印对于基于跳板的网络攻击具有很好的追踪效果,但是流量水印检测器的部署是一个很大的挑战,因为检测器必须要能够捕获到跳板流量才能实现检测,部署的数量、密度、位置等等需要通过进一步的理论计算与实践才能得出。因此,在今后的研究中,除了要提高流量水印的隐形性与鲁棒性之外,检测器的部署也是一个值得研究的方向。
