基于域适应的多场景车辆检测
2019-12-11王翎,孙涵
王 翎,孙 涵
(南京航空航天大学 计算机科学与技术学院,江苏 南京 211106)
0 引 言
目标检测[1]是计算机视觉中的一个基础问题。近年来,由于卷积神经网络(CNN)的研究进展,基于CNN的深度目标检测算法已经取得了显著的成就。但是在现实生活中,图片中拍摄视角变化、场景环境变化、图片质量变化等问题,会导致实验室训练数据与测试数据之间出现域偏移。道路车辆检测就面临这样的问题,用来训练目标检测模型的数据集与使用模型进行测试的数据集可能是在不同视角、不同城市背景、不同天气环境、不同分辨率下采集的。比如自动驾驶领域的数据集Cityscapes、Kitti,可以看出很明显的域差异,如图1所示。

图1 Cityscapes数据集(左)与Kitti数据集(右)示例
这样的域差异会导致训练模型直接使用时的性能大幅下降。由于标注的代价昂贵,一般应用场景下的大量数据标注是不容易获得的。面对无标注的应用场景,研究算法使得在有标注的相似场景下训练的目标检测模型去适应新的应用环境是很有必要的,域适应(domain adaptation,DA)正是解决这一问题的思路之一。
文中主要研究无监督的目标检测域适应问题:源域有完整数据标注,而目标域没有任何标注,源域和目标域存在分布差异,但是检测任务相同。同时在不同城市街景数据集之间进行实验验证,提升模型在不同场景下的车辆检测精度。
1 相关工作
(1)目标检测。
近年来卷积神经网络在目标检测领域应用广泛。在众多方法中,基于区域(region)的CNN方法(R-CNN)取得了显著的成效。这一类方法均是基于R-CNN[2],主要是从图像中提取候选区域框,然后训练一个网络来识别每个兴趣区域(ROI)。文献[3]中提出所有ROI共享卷积特征图的方法对R-CNN进行了扩展。再进一步,Faster R-CNN[4]提出了区域建议网络(RPN),取得了更好的检测效果。Faster R-CNN具有很高的灵活度和准确度,已经应用到许多任务当中。但是,很少有方法考虑到训练的源域数据与应用的目标域数据存在的偏差。文中基于Faster R-CNN进行改进,结合域适应的思想与双层ROI Pooling方法[5]提升目标检测模型在新目标域上的泛化能力,将其应用到不同场景下的车辆检测任务中。
(2)域适应。
域适应[6]是一种非常有效的迁移学习方法,其目的是利用来自不同但相关的域(源域)中丰富的现有标记数据,将从源域中学习的预测模型推广到未标记(或少量标记)的目标域,尽管源域和目标域数据分布之间存在差异。域适应方法的主流核心思想[7-9]是减小域间差异,同时从数据中学习一个具有域不变特性的预测模型。这些方法基本都是用于解决分类问题,文中将域适应的思想应用到目标检测问题中。
2 模型和方法
2.1 Faster R-CNN
文中对基于深度目标检测算法Faster R-CNN进行研究。Faster R-CNN模型架构主要包括三个部分:共享的提取特征图的卷积层、区域建议网络RPN和基于兴趣区域ROI的分类器,如图2左半部分所示。
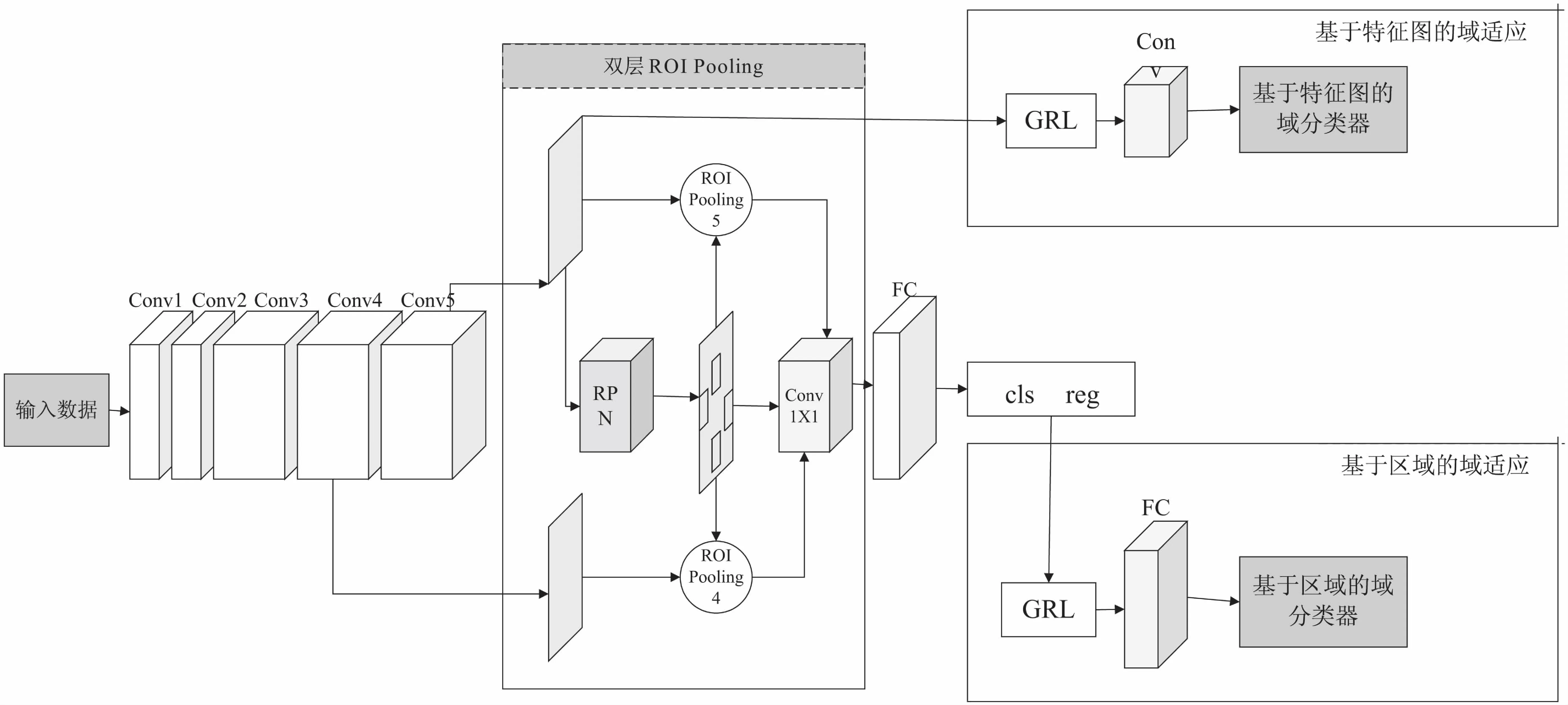
图2 模型结构
Faster R-CNN主要算法步骤如下:
(1)通过卷积神经网络从输入图片中提取特征图,一般采用VGG16[10]或者ZF[11],文中使用VGG16的卷积层作为特征提取器。
(2)基于提取到的特征图,RPN网络生成候选框以及进行初步目标预测。
(3)将候选框特征结果映射回conv5的特征图中,并统一ROI大小,进行ROI Pooling。
(4)将特征区域输入到全连接层中,进一步对目标框的位置进行回归并使用基于兴趣区域ROI的分类器进行类别预测。
Faster R-CNN的损失函数主要包括标签预测损失Lcls以及检测框定位的回归损失Lreg。
其公式如下:
(1)
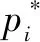
2.2 基于域适应的目标检测
域适应方法中将用来训练的数据集称为源域,符号为S,用来测试应用的数据集称为目标域,符号为T。文中采用无监督的学习方法,源域S中数据均有完整标记(边界框位置和物体类别标记),但是目标域T中数据没有任何标记。文中在Faster R-CNN基础上添加域适应组件,来学习一个适用于无标记目标域的物体检测模型域,域适应组件的设计参考了文献[12]中的思想。文中使用的目标检测模型架构如图2所示,左侧为Faster R-CNN基础架构,其中ROI Pooling部分进行了双层ROI Pooling,右侧包含基于特征图以及基于区域的两个域适应组件。
(1)基于特征图的域适应。
对于目标检测模型Faster R-CNN,基于特征的域适应是卷积神经网络提取的特征图的域适应。对于提取到的特征,文中添加一个域分类器,用来判别样本所属域。添加的域分类器如图2右侧上部分所示。特征图与输入图像的图像块是相对应的,所以,域分类器的作用是判断每个图像块的所属域。
令Ii表示第i张训练图像,Di表示第i张训练图像域标签。Di=0表示源域,Di=1表示目标域。图像经过基础卷积层之后得到的特征图在(u,v)处的值为φu,v(Ii)。基于特征图的域分类器的输出结果记为pi(u,v)。使用交叉熵损失,基于特征图的域适应损失计算公式如下:
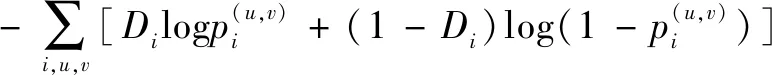
(2)
从域适应的角度来看,基于特征图的域适应的主要思想是提取具有域不变特性的特征,域分类器的分类效果越差,特征图对源域和目标域的共性表征越好,从源域往目标域进行域适应的效果越好。所以,上述域适应损失函数越小,模型在目标域上的适应性越好。但是,从整个模型的优化上来看,Faster R-CNN前面的卷积网络是为了提取表征能力强的特征,以便后面进行目标检测,表征能力越强,域分类器的效果越好,特征的域不变特性越差。因此,需要优化域分类器的参数来最小化基于特征图的域适应损失,同时又需要优化整个卷积网络的参数来最大化该损失。所以在实际实验的过程中,参照文献[13]中做法,文中在训练时采用梯度下降法,同时引入一个梯度逆转层(GRL)。当经过GRL层时,梯度会逆转方向来进行基础网络的优化。该层的作用是为了同时满足Faster R-CNN和域适应组件各自的参数优化要求。
(2)基于区域的域适应。
基于区域的域适应,是指对Faster R-CNN网络最后检测到的目标框区域进行域适应操作。该部分结构如图2右侧下部分所示。文中使用检测到的目标区域的特征向量训练一个域分类器,在该分类器之前添加一个全连接层,将所有区域特征连在一起,作为基于区域的域分类器的输入。令第i张图像的第j个目标区域在该域分类器中的结果为pi,j。基于区域的域适应损失函数如下:
同样的,添加梯度逆转层GRL来实现训练过程中Faster R-CNN和域适应组件的各自优化过程。
综上,整个基于域适应的目标检测网络的损失函数如下所示:
L=Ldet+γ(Lfea+Lreg)
(4)
其中,γ是目标检测网络Faster R-CNN和两个域适应组件的平衡权重。
(3)采用双层ROI-Pooling的域适应目标检测。
无监督目标检测域适应的主要目的是通过源域(有标记)的信息辅助目标域(无标记)的目标检测任务,因此,在进行域适应的过程中,应该尽可能多地提取与利用源域特征。然而,上文提到的域适应方法均是从加强源域与目标域特征共性表示的角度,一定程度上牺牲了一些源域特征的个性表示能力。文中在Faster R-CNN中的ROI Pooling部分进行改进,采用双层ROI Pooling思想使模型从源域中提取更多有用信息,提升域适应目标检测精度。
文中将双层ROI Pooling应用于域适应目标检测。原来的ROI Pooling是将RPN网络提取的区域特征映射回conv5产生的特征图,并使每个ROI固定尺寸。双层ROI Pooling不仅使用conv5,还在分辨率更高、特征更丰富的conv4层进行映射,将conv4和conv5进行ROI Pooling的特征结合,以供后续使用。结合方式是将两个ROI Pooling结果进行“contact”操作,然后使用1×1卷积进行特征融合。双层ROI Pooling的结构如图2中间部分所示。
3 实验结果与分析
3.1 数据集
采用两个数据集进行车辆检测的应用实验。首先是数据集Cityscapes[14],是无人驾驶环境下的图像分割数据集,一般用于评估视觉算法在城区场景语义理解方面的性能。Cityscapes包含50个城市不同场景、不同背景、不同季节的街景。文中使用Cityscapes的训练集(共2 975张)。此外,还使用了Kitti数据集[15]作为实验数据,Kitti数据集是由德国卡尔斯鲁厄理工学院和丰田美国技术研究院联合创办,是目前国际上最大的自动驾驶场景下的计算机视觉算法评测数据集,包含了市区、乡村和高速公路等场景采集的真实图像数据。文中共采用其中7 481张有标注图片进行实验。两个数据集示例如图1所示。
通过Cityscapes和Kitti数据集的相互域适应实验,验证文中方法解决车辆检测中场景不同导致的域适应问题的有效性。
3.2 实验过程和结果分析
采用无监督学习的方式进行训练学习,源域训练图片拥有完整标记(包括检测框和目标类别),目标域训练数据没有任何标注信息。两个数据集均转化为VOC数据集格式,且均只关注car这一个类别。卷积网络的初始参数采用在ImageNet上预训练的VGG16网络的参数。文中实验采用Caffe架构,共训练70 000次,前50 000次训练固定学习率为0.001,后20 000次迭代逐渐降低学习率。域适应损失的权重设为0.1。
文中的两种域适应场景为:(1)源域训练集为Cityscapes中2 975张图片,目标域训练集为Kitti中7 481张图片,目标域测试集为Kitti中7 481张图片(记为C->K);(2)源域训练集为Kitti中7 481张图片,目标域训练集为Cityscapes中2 975张图片,目标域测试集为Cityscapes中500张图片(记为K->C)。
对比实验的方法有三种:(1)只采用Faster R-CNN检测;(2)结合域适应思想的Faster R-CNN检测;(3)结合双层ROI Pooling与域适应思想的Faster R-CNN检测。实验结果如表1所示。
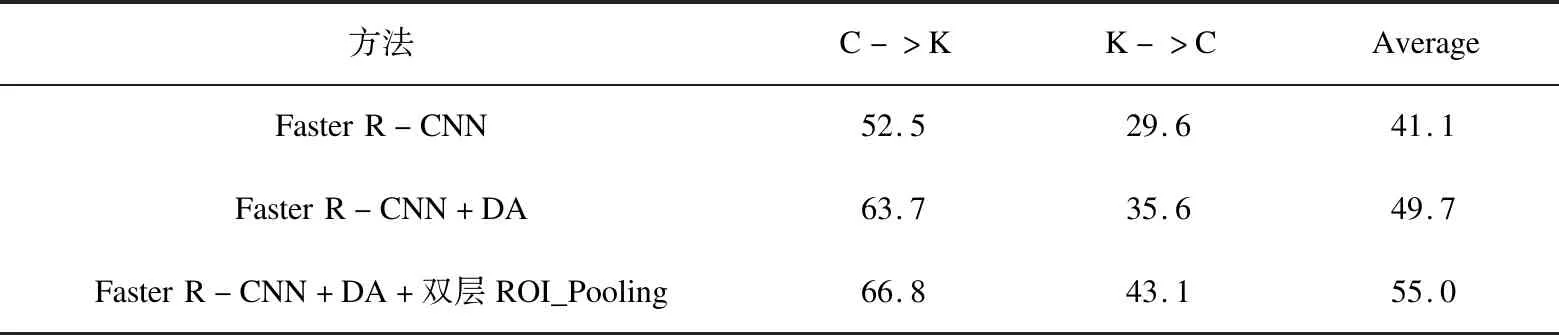
表1 三种方法在两个域适应场景中的实验结果
从表1可以得出以下几点结论:
(1)结合域适应思想的Faster R-CNN模型相比只采用Faster R-CNN的方法,大幅提升了不同场景下车辆检测的精度,证明了文中基于特征图和基于区域的域适应组件在解决由于源域与目标域分布差异导致的检测模型性能不佳问题上的有效性。
(2)结合双层ROI Pooling的域适应Faster R-CNN方法在C->K的域适应场景上获得了66.8%的检测精度,比起域适应Faster R-CNN方法提高了3.1%,在K->C场景上获得了43.2%的检测精度,又获得了8%的提升。
(3)文中的综合域适应检测模型,对车辆检测域适应问题取得了良好的改善效果,证明了该方法的有效性。
4 结束语
针对多场景车辆检测任务中由于源域与目标域分布差异导致的模型性能下降问题,提出基于特征图与基于区域的域适应Faster R-CNN目标检测模型,并结合双层ROI Pooling思想进一步提升域适应效果,在无监督车辆检测域适应任务中取得了良好的结果。后续将对更复杂场景下的域适应目标检测问题继续进行研究。
