基于复杂网络的微博传播溯源方法
2019-12-11贾志娟
王 宁,贾志娟
(郑州师范学院 信息科学与技术学院,河南 郑州 450044)
0 引 言
随着互联网技术的普及,越来越多的人享受到互联网带来的便利和乐趣。尤其是近几年在线社交网络[1]的迅速发展,使人们越来越多地参与到互联网丰富的社交活动中。作为新生网络的应用形式,微博在近年来发展迅猛,并成为目前国内最具影响力的主流网络媒体之一[2]。在微博系统中,博文信息在微博博主之间进行传播,他们之间的传播方式包括两种:一是直接转发;二是对原来的博文信息进行修改,增加一些个人的观点,然后再进行转发。如果要判断微博博文信息在传播过程中是否有失真、断章取义以及局部抽取等情况,就需要借助信息的源头进行查找判断。在微博信息传播过程中,如何快速准确地查找到信息的源头以及理清完微博的传播路径,是微博信息系统分析中最主要的部分。微博事件的源头发现,就是在这一系列微博中,查找出首发微博。而如何快速查找出微博事件及话题的源头也是近些年来研究者们研究的热点。
Adar E等提出了隐式结构和博客空间的动态[3],并对博客空间中的流进行了研究[4]。J Leskovec等[5]通过创建一个有向图发现了博客空间中信息传播的模式并了解了潜在的社交网络。D Liben-Nowell等[6]提出了一种在全球范围内利用连锁信息数据进行信息溯源的快速方法。该方法利用网络簇以及异步时间的概率模型在社交网络上迅速准确地找到了信息的源头。Jin Xin等[7]提出了话题源头的概念,并基于话题的相关性、文档时间以及文档之间的关系这三个方面提出了TCL的话题溯源模型。文卫华等[8]以微博事件为研究对象对其传播特征进行研究。G S Bindra等[9]对信息流进行追踪,并分析它在社交媒体中的不完整影响,研究表明,k树模型是研究级联中缺失数据影响的有效工具。张旸等[10]通过对微博上不同特征的重要性进行分析,提出了基于特征加权的预测模型。杨静等提出一种基于话题影响力的微博话题溯源方法[11]和一种基于溯源的虚假信息传播控制方法[12],其中传播控制方法利用微博转发关系,结合关系网和信息级联关系网找到微博的真正发起者。郑业鲁等[13]提出了蔬菜供应链全程溯源模型并搭建了蔬菜产品质量安全溯源系统。王澍贤等[14]对意见领袖参与下微博舆情演化的三方博弈进行了分析。刘荣叁等[15]对面向新浪微博的信息溯源技术进行研究。李城等[16]提出了一种微博谣言溯源方法,该方法利用改进的最长公共子序列进行比对微博谣言,从而查找源头。
由于微博本质上属于一种复杂的社交网络,它满足复杂网络所具有的一些特性,如网络节点的度、聚类系数和平均最短路径等,故通过对前人的研究成果进行研究和分析,文中提出一种基于复杂网络的微博传播溯源方法。该方法首先从单条微博的传播过程入手,还原出单条微博的转发评论关系,进而重构出单条微博的转发评论关系树;其次,在此基础上进行扩展,重构出一个微博话题的传播过程;然后基于该方法设计了一个微博话题关键用户查找系统,并基于该系统做了一个微博话题传播溯源实验,实验表明该溯源方法实现了关键用户的查找。
1 基于复杂网络的微博源头发现方法
在本节的溯源方法中,首先介绍了单条微博的转发评论关系重构,然后在此基础上进行拓展,重构出微博话题的转发评论关系图,最后实现微博关键用户的查找。
1.1 重构单条微博的转发评论关系
若干条单独的原创微博信息可以组成一个微博话题,如果想要重新构建出一个微博话题的信息传播关系,那么重新构建出每一条原创微博博文的信息传播关系则是首先需要做的事情。
(1)还原单条微博信息的传播模型。
当微博博主用户发送出一条原创的微博信息后,微博系统将会实时地将该原创微博博文传递给他的微博粉丝用户,粉丝用户可以对该原创微博进行评论或转发,而转发则可以把原创微博信息传递到该粉丝用户的粉丝用户,以此类推,最终使得整条微博在整个微博用户关系网中传播开来。实际上,微博博文是按层次进行转发和评论的,通过一层一层进行推进,形成一个类似于树形的结构。这里,如果把原创微博博主用户看作根节点,把每一个转发评论微博用户都看成是一个子节点,而把用户的每一次转发评论行为看成一条边,那么一条微博的转发评论关系就可以构成一棵微博转发评论关系树,如图1所示。
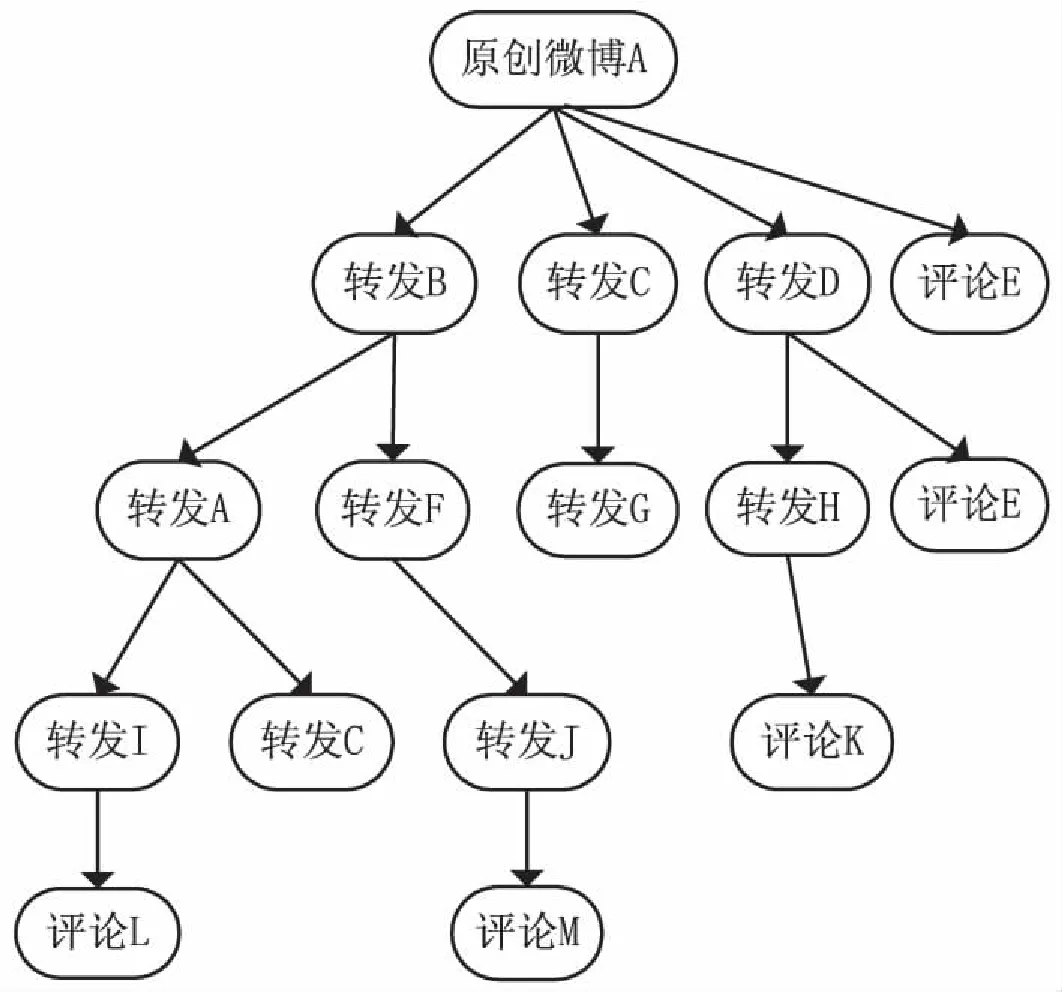
图1 原创微博的转发评论关系树
由图1可知,原创微博博主用户A发出原创微博,然后由微博粉丝用户B、C、D分别进行转发,并且由微博粉丝用户E对该原创微博进行评论,原创微博用户A和粉丝用户F从粉丝用户B处转发。由此能够看出,微博用户A虽然是原创微博用户,但其同样能够成为自己所发微博的转发用户,微博用户B是微博用户A的粉丝,同样微博用户A也可以是用户B的粉丝。在微博系统中,所有的转发评论关系图都可以还原成类似图1所示的一个树形结构。
(2)实现微博转发评论关系树的重构。
通过对微博系统的分析可以看出,粉丝用户对原创微博博主信息的所有转发评论信息全部都可以归总到原创微博博主用户的微博主页,并且能够在该主页上面査找到所有粉丝的转发微博,而微博评论信息则可以在相应的转发微博和原创微博主页中进行查找,具体步骤如下:
(a)获取转发评论数据。在原创微博的主页获取用户的信息(包括用户ID、昵称、发送时间等)和所有转发用户的信息(包括ID、昵称、转发时间、微博ID),根据转发用户的信息依次访问每一条转发微博的主页,在该主页获取该条转发微博的转发和评论微博信息,并把它们保存在相应的数据库列表中。
(b)构造转发评论树。根据第一步得到的转发和评论数据列表,层次地重构转发评论树,其算法流程如图2所示。
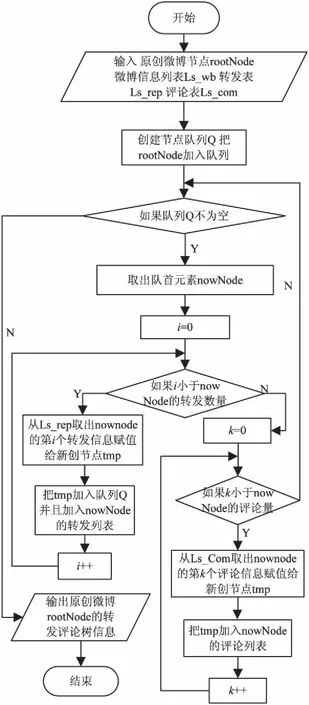
图2 重构转发评论树的算法流程
(c)可视化转发评论树。采用JavaScript可视化组件对单条微博的转发评论关系进行可视化,如图3所示(这里需要说明的是,由于某些微博的转发量比较大,而整个屏幕能够显示的点是有限的,故选择其中的部分点进行展示)。其中,底部标注1所示颜色表示原创微博博主(发布者),2所示颜色表示转发数量大于8的微博用户,3所示颜色表示转发数量为1-8的微博用户,4所示颜色的点则表示转发量为0的用户(末端节点)。如果鼠标被放在图3的任一一个转发和评论节点上面,在图3中均能够显示出相应微博的微博用户昵称、微博转发或评论的时间以及微博的博文内容等信息。

图3 微博转发评论图
(3)微博转发评论关系树的分析。
微博转发评论树的分析主要从传播路径和用户传播能力两个方面进行。传播路径包括传播路径的还原及微博信息的传递,而微博用户的信息传播能力则通过信息传播的广度和深度来进行计算。
根据图1中生成的原创微博的转发评论关系树,还原出微博传播的每一条传播路径,其算法流程如图4所示。
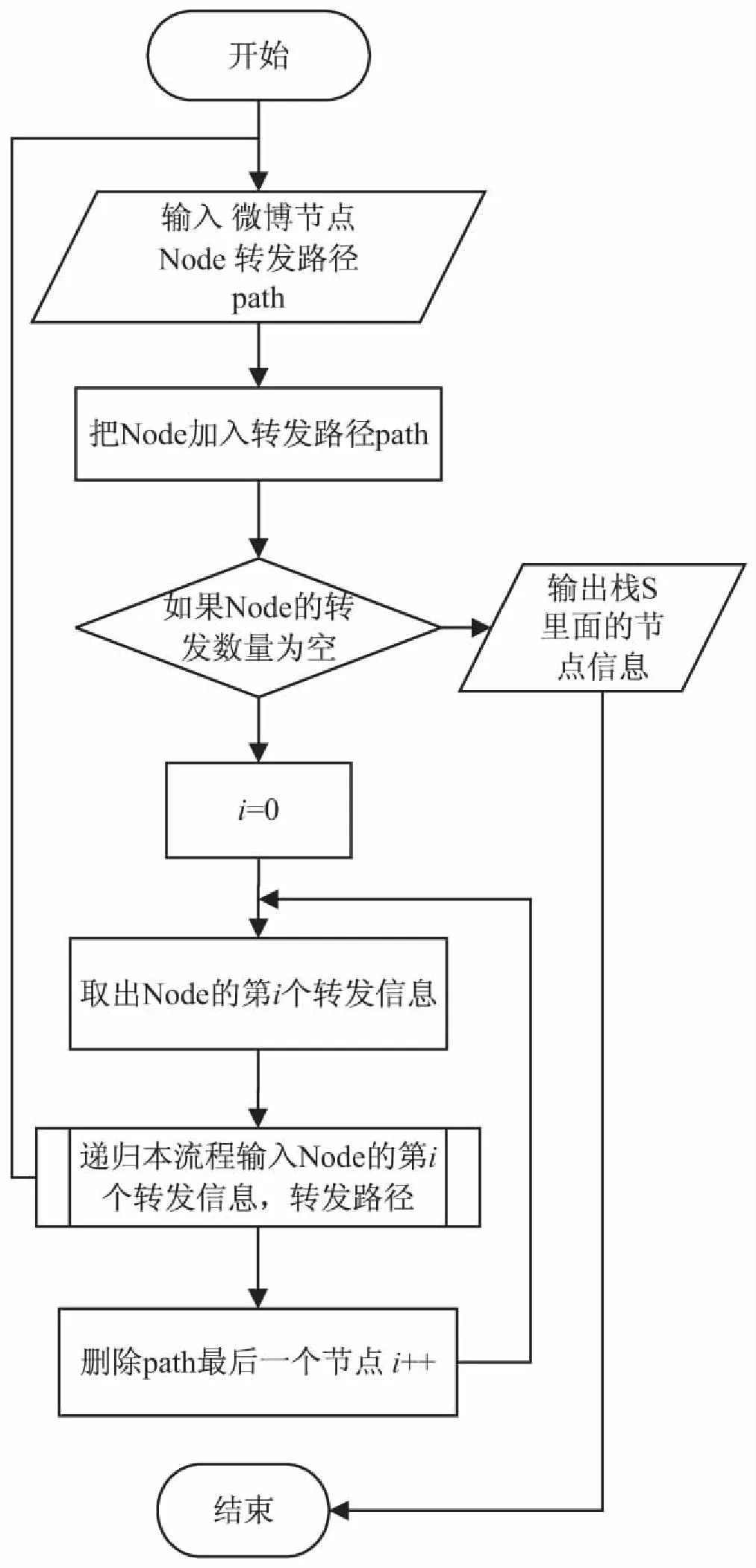
图4 还原传播路径的算法流程
如果要还原出微博信息在任意时刻被微博用户转发和评论的情况,则需要按图5所示的算法流程进行分析。
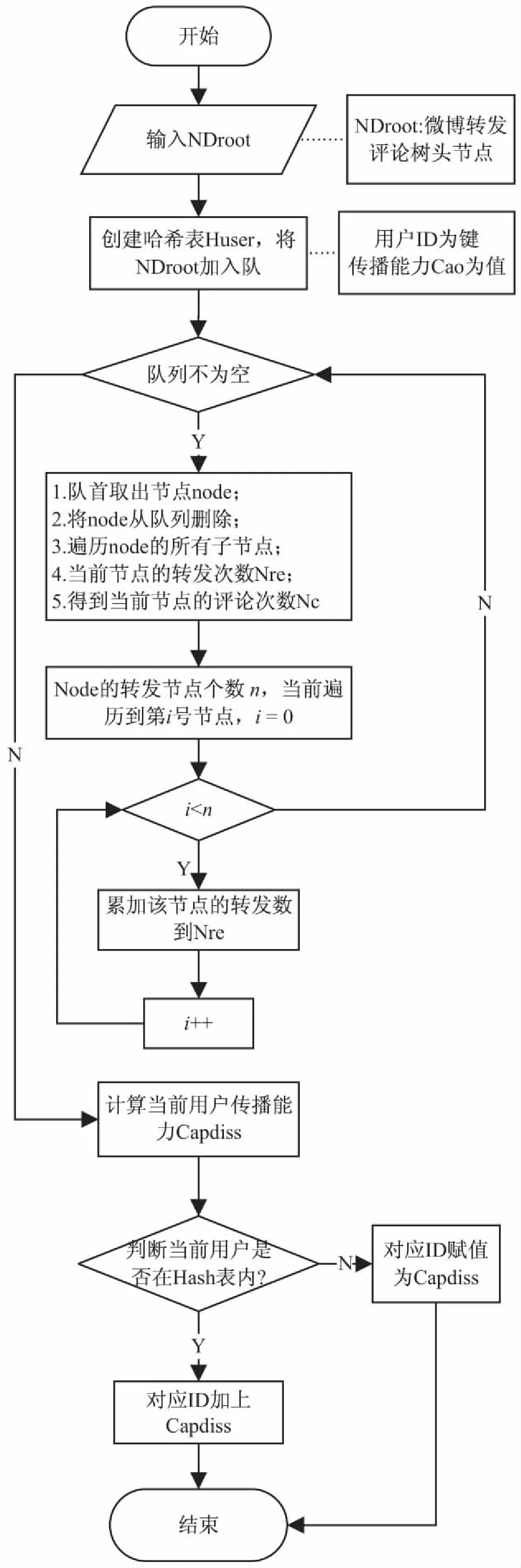
图5 微博信息传递(原创微博在任意时刻被户转发和评论)的算法流程
信息传播的广度是指该微博用户的微博能被多少微博粉丝用户进行转发或者评论。这里,主要考虑第一层的微博被转发和评论的数量。信息传播的深度是指该微博能被传播几层的深度,这与该微博用户后面用户的粉丝有着相当大的关系,但和当前微博用户却没有特别大的关系,故这里仅考虑第二层的微博转发数量。
假设Nr表示用户的微博信息被转发的次数,Nc表示微博的微博信息被评论的次数,Nre表示第二层的节点一共被转发多少次,那么在微博的传播过程中,某个微博用户的传播能力可以表示为:
Capdiss=Nr+log2Nc+log2Nre
(1)
如果一个微博用户曾参与一条微博的多次转发,那么该用户的传播能力则是其对应的每个节点的传播能力的叠加。其算法流程如图6所示。
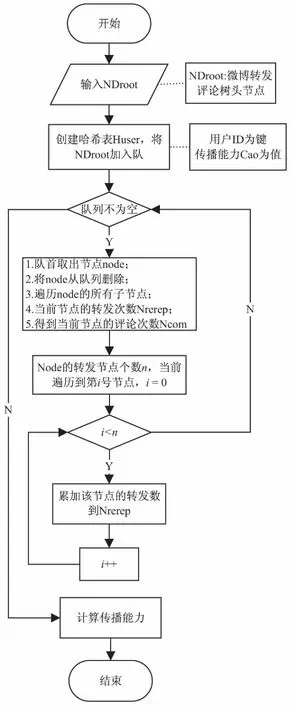
图6 计算用户传播能力的算法流程
1.2 重构微博话题的转发评论关系
本节就微博话题转发评论关系的构建进行简单介绍。首先需要得到该话题的微博地址的ID列表,然后根据原创微博的地址(ID)按顺序构建出每一条微博的转发评论关系树,最终构建出一个微博话题的转发评论关系图,其可视化图如图7所示。

图7 微博话题的转发评论关系图
图7所示是2016年7月19日“中国一点都不能少”话题的微博转发评论关系图,图中的转发评论关系主要由10条微博事件构成,图中底部标注1所示颜色的点表示原创微博博主(发布者)。
微博话题的信息传播分析和单条微博的信息传播分析相似,而不同的是,微博话题的转发评论分析则是把转发评论关系变成了多棵树的分析,故微博话题用户的信息传播能力为:
Ti={M1,M2,…,Mn}
(2)
另外,一个微博用户或许会参与多条微博信息的转发和评论,因此,对于参与该话题的每一个微博用户Uj,他在微博话题中的信息传播能力可以定义为:
(3)
2 系统的设计与实现
基于复杂网络的微博传播溯源方法,本节设计了微博话题关键用户的溯源系统,并通过实验证明该系统实现了关键用户的查找。
2.1 系统设计架构
该系统的设计主要分为微博网络数据的采集及相关处理和微博话题关键用户的溯源,具体步骤如下:
(1)微博数据的采集。
利用爬虫程序在微博系统的网页上抓取若干个微博种子用户的数据,这里主要抓取原创微博用户的信息、微博地址(ID)和发送时间等。
(2)微博数据的本地处理。
首先对微博进行分词及倒排序索引,构建词典索引库;其次整理出每一条微博的转发评论关系,构建其转发评论树;然后对爬虫获得的微博进行主题提取,得到某些谈论话题,并据此对微博进行聚类;最后对这些话题进行索引,构建话题索引库。
(3)查找给定话题对应的微博列表。
首先在索引库(包括词典索引库和话题索引库)中查找微博话题对应的微博列表ID,然后根据微博ID得到每一条微博的转发评论树,重建该话题的转发评论关系。
(4)根据重构的转发评论关系,对用户的传播能力进行分析,计算参与该话题的每一个用户的传播能力,并对其进行排序。
(5)根据微博ID和排名靠前的传播能力这两个方面得到微博信息传播过程中的关键用户。
该系统的工作流程如图8所示。
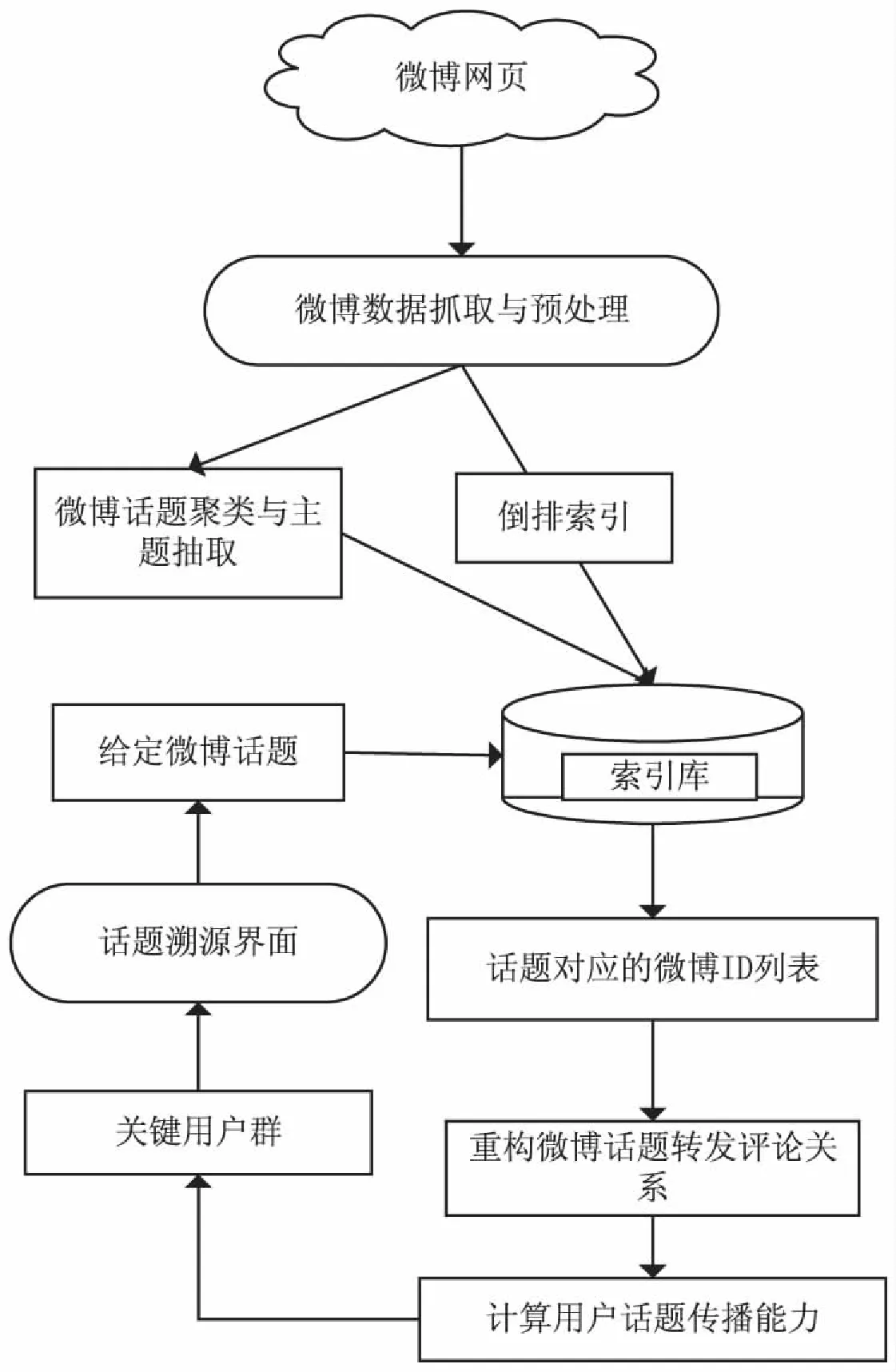
图8 微博关键用户查找系统
2.2 实验与结果分析
根据前面章节抓取的数据以及对各个算法的处理及实现,最终实现了该微博话题关键用户的查找系统,系统展示如图9所示。

图9 微博话题关键用户查找系统首页
以下通过一个例子分析验证该溯源系统的有效可行性。
首先,假定微博话题为“中国一点都不能少”,再通过分词软件ICTCLAS对其进行分词,得到该微博话题的关键词列表为“中国”、“一点”、“都”、“不能少”。
然后,在微博主题索引库中进行关键词匹配,得出该话题与主题“中国”的相似度是最高的,因此,认为所要查的微博话题为“中国”。故当在图10的关键词搜索一栏中键入“中国”一词时,会在窗口右侧显示出参与该微博话题的每个微博用户的详细的微博传播情况(由于页面有限,只截取部分微博用户的传播情况)。从图中可以看出,用户的传播能力逐次降低,且传播能力较高的为央视新闻、范冰冰、人民日报、胡歌、Johnny黄景瑜等。通过对原创微博博主用户以及重点微博用户的分析可知,在传播过程中起关键作用的微博用户群为人民日报和央视新闻,如图10左侧窗口所示。
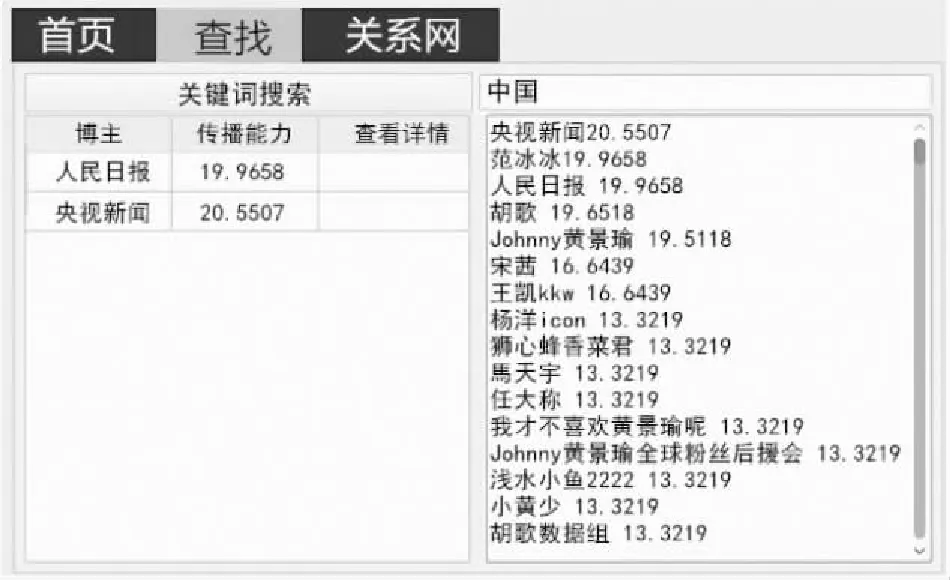
图10 微博话题关键用户查找系统查找页面
以上便是从输入待查的微博话题,到最后返回该微博话题在传播过程中起关键作用的用户群体的整个分析过程。
3 结束语
基于微博本质上是一个复杂网络的特性,提出了一种基于复杂网络的微博传播溯源方法。该溯源方法首先从微博系统中抓取微博数据并对其进行处理,然后根据处理的数据还原出单条微博的转发评论关系,进而构建出单条微博的转发评论关系树;其次,在单条微博的转发评论关系基础上进行扩展,重构出一个微博话题的转发评论关系树,并对该树中每一个微博用户的传播能力进行分析;然后基于该溯源方法设计一个微博话题关键用户的查找系统,最后基于该系统做了一个微博话题溯源实验,实验表明该方法实现了微博话题关键用户的查找。
