基于迁移学习与自适应特征融合的建筑物识别
2019-12-11王泽泓刘厚泉
王泽泓,刘厚泉
(中国矿业大学 计算机科学与技术学院,江苏 徐州 221116)
0 引 言
特定建筑物识别具有很好的应用前景。利用建筑物识别技术,可以从图像中理解地点。面对陌生未知的建筑物,通过建筑物识别技术,游客可以识别到图像中的地点,因而建筑物识别技术可应用于旅游景点的地点识别。
近年来,研究人员在建筑物识别和物体识别方面做了许多研究。传统的建筑物识别方法通常是对大量建筑物图像手工设计特征或设计特征检测算子,并设计相应算法进行识别。如David Lowe提出的尺度不变特征变换(scale-invariant feature transform,SIFT)[1]用于在图像中检测出关键点,描述图像的局部特征,进而设计识别算法。现在有研究人员尝试利用SIFT结合边缘特征与关键点特征进行建筑物识别[2]。Dalal等提出方向梯度直方图(histogram of oriented gradient,HOG)[3]用于计算和统计图像局部区域的梯度方向直方图来构成特征,之后结合SVM[4]广泛应用于图像识别。现在有研究人员尝试使用HOG特征进行建筑物识别[5]。但是,以上方法都需要人工设计特征或者人工设计特征提取算子。而如何提取特征以及充分利用提取出的特征,是建筑物图像识别中最关键的问题。
为了解决上述问题,文中引入卷积神经网络(convolutional neural network,CNN)[6]。CNN广泛应用于各种视觉识别任务。Maxime Oquab等提出的迁移学习[7-9]可以有效解决难以获得高质量的建筑物的大型数据集的问题,因为浅层神经网络提取出的特征是比较通用的特征。Karen Simonyan等提出对卷积网络的特征图进行融合[10-12],以充分利用更多的特征,得到更好的效果。因此,文中基于迁移学习对预训练的VGG-16网络[10]进行改进,设计能够自适应特征融合的卷积神经网络应用于建筑物图像识别任务中。
1 自适应特征融合的建筑物识别方法
1.1 方法概述
文中将卷积神经网络应用于建筑物图像识别,同时利用迁移学习,利用在ImageNet数据集上预训练的VGG-16网络的权重,并对网络结构进行改进,使其能够自适应地进行特征融合,充分利用各个层提取出的特征,以提高VGG-16网络的性能。
1.2 数据来源与预处理
文中的建筑物图像是利用网络爬虫在网络上获取的,这些图像共6 273张,共12个类别(目前数据集及文中算法已在https://github.com/zehong1995/structureRecognition开源)。由于从网络上爬取的图片尺寸不一,所以首先使用三次样条插值方法对原图进行降采样,得到相同尺寸124×124的图片。建筑物图像预处理见图1。

图1 建筑物图像预处理
1.3 自适应特征融合的网络结构
由于卷积神经网络中浅层可以学习到比较通用的低级特征,深层可以学到特定的高级特征,且网络层数越多,整个网络在样本空间中就可以拟合更复杂的函数。所以,为了更充分地利用各层提取出的特征,提出自适应特征融合方法(见图2),此网络由VGG-16改进而来。VGG-16网络是2014年由牛津大学的视觉几何组(visual geometry group)提出,该网络共有五个卷积块,每个卷积块后都是最大池化层,最后三层为全连接层。文中只使用VGG-16的前五个卷积块,之后将第二至第五个卷积块中池化层前的特征图取出,分别进行自适应的特征映射,得到四个映射的特征向量,再与第五个卷积块中最大池化层提取出的特征图相融合。在对不同层次特征进行自适应特征映射部分,由于每层的特征图的尺度不同,所以文中先使用1×1卷积[13]提取特征,之后使用全连接层使得每个特征图都能映射为相同长度的特征向量,再对每个特征向量添加一个可学习的权重γi,再使用求和方法将5个相同尺度的特征向量进行融合,最后使用三层全连接层对提取出的特征向量进行分类。
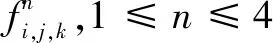
(1)
θn=max(Wnpn+bias,0)
(2)
(3)
基于上述结构,对提取出的中间特征先进行1×1卷积,增强模型的非线性性质,之后对特征进行特征映射,将不同尺寸的特征向量映射成为相同尺寸,再使用激活函数Relu[14]进行非线性变换。由于不同层次提取的特征的重要性不同,又难以人工判断,所以最后需要进行一个加权求和,其中前四个映射好的特征需要进行一个可学习的加权求和,第五个特征权重设置为固定值1。在这里,将第五个卷积块输出的特征的权重设置为常量1,而将其他的特征的权重设置为可学习的,有如下几方面的考虑:
(1)因为VGG-16网络能够较好地提取特征,所以文中不对第五个卷积块输出的特征图设置可学习的权重。
(2)对于前面层提取的特征,设置可学习的权重,一方面是为了使模型能够自己学习到最佳的权重,即能够自适应地进行特征融合,另一方面是避免在前面层提取的特征对最终效果有负面影响的情况下,能够使得该分支很容易地学到恒等映射,即对于式3,希望有:
fv=θn
(4)
那么,只需要模型学习到
γn=0
(5)
这样就不会对模型效果有任何负面效果。
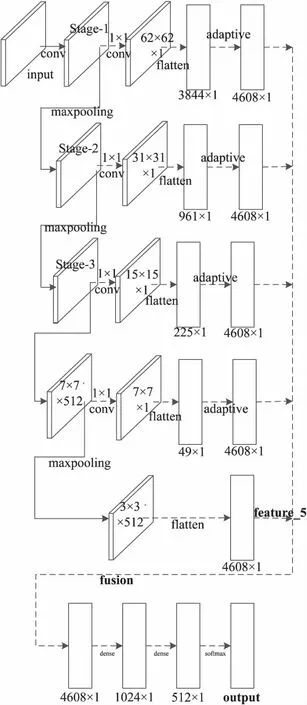
图2 自适应特征融合网络的详细结构
2 实验过程与结果
2.1 训练过程
文中训练了两个网络,用以对比提出的自适应特征融合网络的有效性。一是对在ImageNet数据集上预训练的VGG-16网络进行训练,二是对自适应特征融合网络进行训练。将数据集分为两部分,5 051张作为训练集,1 222张作为测试集。
由于所采用数据集的规模较小,为了避免过拟合并提高模型效果,两个网络的训练都采用相同的数据增强方法(见图3)[15],包括旋转、水平翻转、垂直翻转、宽度放缩、高度放缩。在测试时为了贴近真实场景,不采用数据增强。

图3 数据增强方法
在训练过程中,两个网络都采用了多类交叉熵损失函数,VGG-16网络采用Adam[16]优化算法,学习率为0.000 01,经过250个epoch的迭代。自适应特征融合网络采用Adam优化算法,学习率为0.000 01,首先冻结VGG-16的五个卷积块的权重,训练迭代50个epoch,再解冻卷积块的权重,对整个网络训练迭代200个epoch,共训练迭代250个epoch。
2.2 实验平台
实验是在一台具有Intel Core i7-4790K CPU(4.0 GHz×8)、32 GB RAM、一个4 GB的Nvidia Geforce GTx970图形处理器、64位Ununtu 18.04的计算机上进行的。运行环境为Python3.6和Keras 2.2.4(后端为Tensorflow 1.12.0)。
2.3 评价指标
通过识别准确率、召回率和处理速度对模型进行评估。召回率是指对某一个类别,该类别中能够被正确识别的比例。处理速度是指每秒钟模型能够预测多少张图片。
2.4 实验结果对比
经过上述相同epoch轮次的训练,最终VGG-16网络的识别准确率为97.86%,自适应特征融合网络的识别准确率为98.93%,比VGG-16网络识别效果提高了1.07%,对比如表1所示。图4中分析了两个网络的召回率对比,图5中详细分析了两个网络的结构差别。
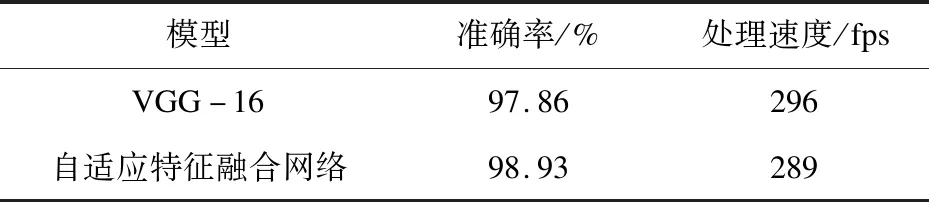
表1 两个模型的实验结果
图4 两个网络的召回率对比
根据实验结果,说明了提出的自适应特征融合网络在准确率上和召回率上都优于VGG-16网络,且处理速度与VGG-16模型大致相当。

图5 两个网络结构的详细对比
3 结束语
特定建筑物的识别在旅游景点的地点识别上具有广阔的应用前景,但是传统方法需要进行繁杂的特征设计和特征提取。对此,文中提出一种基于迁移学习的识别方法,从VGG-16网络迁移而来,并进行自适应的特征融合的改进。实验结果表明,提出的自适应特征融合网络提高了VGG-16网络的性能,能很好地解决建筑物识别问题。
