基于Scrapy和Elasticsearch的校园网搜索引擎的研究与实现
2019-12-10庄旭菲田雪
庄旭菲 田雪


摘 要:针对通用搜索引擎无法及时收录校园网内信息和收录时间滞后的问题,基于Scrapy框架和Elasticsearch全文搜索引擎,提出了一个完善的校园网搜索引擎解决方案。该文主要分析了Scrapy的运行流程,对Elasticsearch的搜索机制进行了研究,在此基础上设计了校园网搜索引擎的系统架构,给出了系统的网页抓取模块、索引检索模块、页面展示模块的关键实现技术。最后通过实验验证,相比于传统的通用搜索引擎,该文设计的校园网搜索引擎的搜索结果相关性更好,数量更多,对于校园网内新信息的收录情况更好。
关键词:校园网搜索引擎 Scrapy Elasticsearch 中文分词
中图分类号:TP391.3;TP393.18 文献标识码:A 文章编号:1672-3791(2019)10(b)-0012-04
近年来,随着高校数字化校园建设的不断加快,校园网络信息呈现出爆炸式增长。高校校园内网站的网络拓扑情况复杂,分布于不同技术架构的服务器上,如果采用传统的站内搜索算法及存储结构,难于实现高效、精准的校园网搜索引擎。而由于校园内网站多数使用二级域名或者直接使用IP地址访问,导致传统的通用搜索引擎无法准确、及时地收录校园网内信息[1]。
为了解决现阶段网络搜索引擎在校园网应用中存在的问题,该文对网络搜索引擎的核心原理、关键技术和工作流程进行了深入分析,结合URL去重策略、防止爬虫被禁止策略、文本分词等多门技术,提出了一个基于Scrapy爬虫框架和Elasticsearch全文搜索引擎的校园网搜索引擎设计方案,并使用Django框架实现了搜索引擎的用户搜索界面。
该文最后的实验结果表明,相比于传统的通用搜索引擎,该文设计的校园网搜索引擎能够及时、准确地进行校园网信息搜索,搜索结果的相关性、准确性及数量级要高于传统的通用搜索引擎。
1 搜索引擎中的關键技术研究
1.1 Scrapy爬虫框架
Scrapy框架是基于异步I/O的twisted框架,所以Scrapy应用在网络爬虫时性能非常高。Scrapy方便扩展,提供了很多内置功能,这些功能可以加快开发速度。Scrapy主要包含引擎(Scrapy Engine)、调度器(Scheduler)、下载器(Downloader)、爬虫(Spiders)、项目管道(Item Pipeline)、下载器中间件(Downloader Middlewares)、爬虫中间件(Spider Middlewares)等组件[2]。
Scrapy的运行流程可以简单理解为:引擎若获取到应答包则发送给爬虫,若获取到实体则发送给实体管道,若获取到请求则发送给调度器。引擎不停地从调度器中取出链接,封装成requests发送给下载器,这个过程不断往复循环就是Scrapy的数据流向。
1.2 Elasticsearch全文搜索引擎
Elasticsearch是基于Lucene的开源搜索服务器,它在Lucene的基础上做了改进,提供了多种语言接口,使搜索变的更加简单[3]。近年来随着实时日志分析平台(ELK)的广泛使用,Elasticsearch也变得越来越流行。
Elasticsearch既有数据的存储,又有数据的分析,是当前流行的企业级搜索引擎。当前使用Elasticsearch作为搜索引擎的公司有联想微软、Facebook、GitHub和Adobe等。
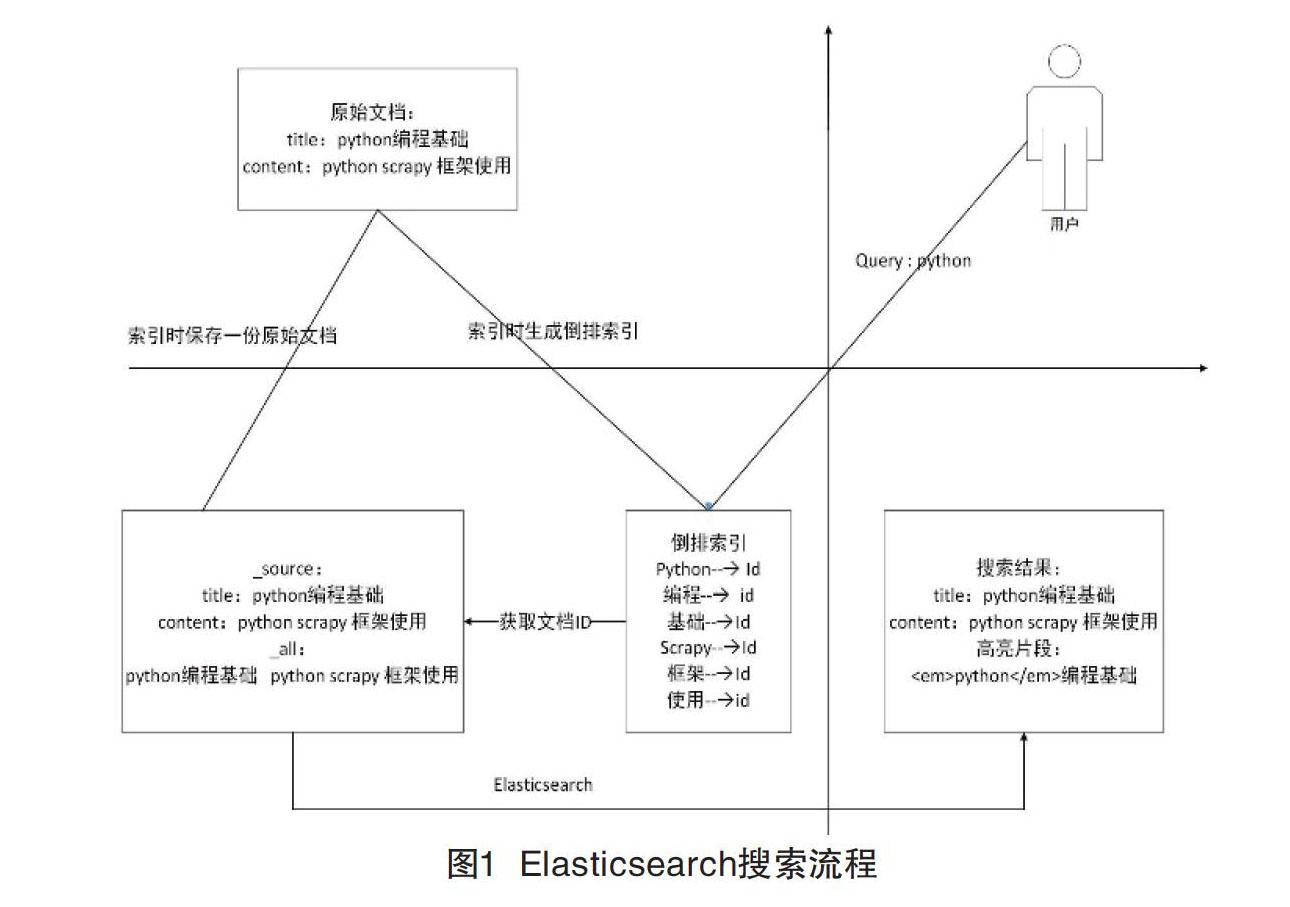
Elasticsearch的核心功能是搜索,如图1所示,描述了将文档索引到Elasticsearch并从Elasticsearch中搜索到该文档的全过程。图1将坐标系分为4个象限,第一到第四象限分别代表了用户、原始文档、Elasticsearch和搜索结果。
索引过程:存在如第二象限所示的原始文档,它包括title与content两个字段。在将文档写入到Elasticsearch中时,Elasticsearch默认会保存两份内容,一份是该文档的原始内容,即_source中的内容;另一份是索引时经分词、过滤等一系列过程生成的倒排索引文件。
搜索过程:第一象限的用户输入关键词python对文档进行搜索,Elasticsearch接收到查询关键词python后到倒排索引表中查询,通过倒排记录表找到关键词对应的文档集合,然后对文档集合进行评分、排序、高亮处理,最后将搜索结果返回给用户。
2 校园网搜索引擎的设计与实现
校园网搜索引擎分为三大模块[4,5],分别为网页抓取模块:通过采取一定的策略从互联网上抓取网页信息;索引检索模块:对获取到的网页信息建立快速高效的索引,便于检索;页面展示模块:将搜索结果按评分高低进行排序,展现给用户。
2.1 网页抓取模块
在进行网页抓取之前,首先需要分析待爬取网站的URL结构,选取适合的网页搜索策略进行数据爬取,例如深度优先策略、广度优先策略、非完全PageRank策略等。获取到返回的网页信息后,进入解析函数进行具体字段的提取,提取的字段信息需要在items.py数据容器文件中定义。
2.1.1 URL去重策略
在进行数据抓取时,若不进行URL去重,不仅会降低爬虫的效率,还会造成硬件资源的浪费。Scrapy框架默认的URL去重方法由dupefilters去重器里的RFPDupeFilter类实现,RFPDupeFilter类会对每一个传递过来的request请求生成信息指纹fp。这种URL去重方法唯一确定了一个request所指向的资源,但是这种去重方法比较耗费内存,采用布隆过滤器则可以改进内存耗费大的问题,但布隆过滤器有时会存在“积极的”误判[6]。相比于互联网资源,校园网内的信息量较少,采用Scrapy框架默认的URL去重方法已经足够。
2.1.2 防止爬虫被禁止策略
爬虫与反爬虫的对抗机制长期存在,为了防止爬虫被禁止,需要采取相应的策略[7]。(1)随机更换user-agent。该文采用fake-useragent开源库,利用其内部维护的user-agent列表,实现随机更换user-agent。(2)启用自动限速(Auto Throttle)扩展。通过设置setting.py文件中的“AUTOTHROTTLE_ENABLED=True”即可启用自动限速扩展,通过启用自动限速扩展以及对相应参数的设置,可以有效地限制爬虫的爬取速度。
2.2 索引检索模块
在网页抓取模块中,已经从页面解析函数中获取到了返回的item对象,此时需要在pipeline中使用Elasticsearch-dsl将爬虫爬取到的数据保存到Elasticsearch中。Elasticsearch的两大主要任务是:索引文档与搜索文档。索引文档是将爬虫爬取到的数据分词并构建倒排索引,搜索文档是将用户输入的关键词分词,匹配出倒排索引中的文档。
分词技术是搜索引擎开发中的重要组成部分,它可以提高搜索结果的匹配度。Elasticsearch本身的分词功能是针对英文的,对于中文分词的支持不是很友好。该文使用插件ik提供的ik_max_word分词器,可以对文本进行最大数量的分词,即将文本做最细粒度的拆分。
2.3 页面展示模块
该文利用Elasticsearch提供的Completion Suggester接口完成搜索建议功能。核心思想是:在index.html里编写一个函数用于绑定输入框的input事件,当input发生变化时,调用get方法获取到用户输入的查询关键词,并向后台处理搜索建议的URL发起请求。
当用户在搜索引擎界面输入查询关键词,点击搜索按钮进行查询时,搜索结果页面会显示查询到的搜索结果、用户的搜索记录、搜索热词、爬取到的网站的数据量和当前系统的访问量。处理用户搜索的核心思想是:当用户点击搜索按钮时,调用add_search方法,获取用户输入的查询关键词,并向后台处理用户搜索的URL发起请求。如果查询关键词的长度大于1,则在搜索记录数组中去重并顯示。处理用户搜索的关键代码流程如图2所示。
该文使用Django框架实现搜索引擎的用户界面,首先在项目目录下新建static文件夹,用于存放静态文件,接着在urls.py文件中进行配置,使得访问http://127.0.0.1:8000/时,显示为自己定义的搜索引擎用户界面。配置完成后,用户搜索界面展示如图3所示。
搜索建议界面展示如图4所示。
搜索结果界面展示如图5所示。
查询时,Elasticsearch会对每个符合查询条件的文档按照查询关键词与文档的相关度进行评分,搜索结果默认按评分降序排序返回给用户。Elasticsearch5.4之后对于text类型的字段,默认采用BM25评分模型。
BM25模型是目前比较成功的概率检索模型。BM25模型在二值独立模型的基础上做了改进,将文档长度、文档词频、idf因子等因素考虑进去,BM25模型的评分公式如下。
对查询Q进行分词,并且依次计算文档D中的每个单词的分数,累加后即为文档D的分数。BM25模型的评分公式主要由3个部分组成:第一部分为从二值独立模型中推导出来的相关性计算公式;第二部分为查询关键词在文档D中的权值,其中fi代表词项在文档中的词频,k1、b是经验参数,K是对文档长度的考虑。当k1取0时,公式的第二部分为1,此时不考虑词项在文档中的词频;当b取0时,表示不考虑文档长度的因素。第三部分是查询关键词自身的权值,tfta是词项t在查询Q中的词频,k2是一个取正的调优参数,用于对Q中的词项频率进行缩放,当取0时,表示不考虑词项在Q中的权值。在没有根据开发测试集进行优化的前提下,实验结果表明参数的合理取值应为:k1在区间(1.2,2)中,b取0.75,k2在区间(0,1000)中。
3 实验结果分析
为了验证该文所实现的校园网搜索引擎的可靠性,分别选取了百度站内搜索、搜狗站内搜索与该文设计的校园网搜索引擎进行对比测试,测试的对象为内蒙古工业大学校园网站,测试的指标为,前20个搜索结果的相关度,测试的关键词为“材料科学与工程学院举办“教授助你成才”系列讲座第四期”。对比结果如表1所示。
接下来测试各搜索引擎对于校园内新发布信息的收录情况,测试对象与上例相同,测试的指标为,所查询信息是否被搜索引擎收录,测试的关键词为,内蒙古工业大学在2019年1月10日发布的新闻信息“图书馆党总支举办“中央红军长征与长征精神”主题党课”。对比结果如表2所示。
测试结果证明了对于给定的查询关键词,该文设计的校园网搜索引擎的搜索结果数量更多,相关性更好,并且可以有效地解决校园内新信息收录不及时的问题。
4 结语
基于Scrapy框架和Elasticsearch的校园网搜索引擎,成功解决了校园网内信息不易被通用搜索引擎收录与收录不及时的问题,满足了校园内师生的信息检索需求。该文的下一步工作是在搜素引擎的基础上,使用Scrapy-Redis进行分布式爬取,提高数据爬取效率,并考虑使用布隆过滤器,降低内存使用,进一步提升校园内师生的搜索体验。
参考文献
[1] 左卫刚.基于Python的校园网搜索引擎研究[J].电子技术与软件工程,2018,144(22):40-42.
[2] 云洋.基于Scrapy的网络爬虫设计与实现[J].电脑编程技巧与维护,2018(9):19-21,58.
[3] 钦蒋承,沈宏良.基于Elasticsearch的校内全文搜索平台的研究与实现[J].现代计算机:专业版,2018,634(34):98-102.
[4] Gormley C,Tong Z.Elasticsearchthedefinitiveguide:adistributedreal-timesearchandanalyticsengine[M].Sebastopol,CA:O'Reilly,2015.
[5] 王伟,魏乐,刘文清,等.基于ElasticSearch的分布式全文搜索系统[J].电子科技,2018,31(347):60-63,69.
[6] 焦萍萍.基于python技术面向校园网原型搜索引擎设计[J].电脑知识与技术,2017(9):20-21,28.
[7] 韩贝,马明栋,王得玉,等.基于Scrapy框架的爬虫和反爬虫研究[J].计算机技术与发展,2019,29(2):145-148.
