利用卷积神经网络对CT图像进行定位的可行性研究
2019-12-10余行蒋家良何奕松姜晓璇傅玉川
余行,蒋家良,何奕松,姜晓璇,傅玉川
四川大学华西医院 放疗科,成都市,610041
0 引言
高精度肿瘤放射治疗的目标是精确控制计划靶区体积,尽可能保护健康组织并降低辐射诱发继发性恶性肿瘤的风险[1-3]。因此,靶区(例如肿瘤区域)和紧要器官(Organs at Risk,OAR)的精确勾画成为放射治疗计划过程中的首要关键步骤。这类勾画过程的本质是对医学影像的区域分割。传统的手动分割存在耗时、勾画者间偏差等问题,因此开发准确的自动分割方法对于辅助预处理放射治疗计划至关重要[4]。
近年来,多种自动分割方法已出现在不同程度的临床应用和研究中。如基于图谱/模板的器官自动勾画方法[5-6]和基于深度学习模型的自动勾画算法[7-8]。而基于深度学习的自动勾画算法以其鲁棒性和灵活性显示出巨大的潜力[9-10]。但是,由于存在大量和多样的解剖结构,在具体实践中,每个自动分割算法都是针对特定区域或模态设计的,其对应的自动分割模型在一个区域中能准确分割图像,而在另一个区域中则可能并不适用。反映在区域的自动勾画中,即针对不同部位的靶区和器官,需要用不同的勾画算法模型(头颈部、胸部、腹部、盆腔等),这意味着在自动勾画危及器官前,必须先针对不同的身体部位选择相应的分割模型。因此,在调用图像分割算法之前预先判断当前处理图像所处的身体部位,就可以自动选择算法模型,实现图像的全自动分割。
CT图像中身体部位的自动识别方法主要可以分为以下3种:基于DICOM(Digital Imaging and Communications in Medicine,DICOM)文件头信息的自动识别、基于CT图像灰度值特征的自动识别和基于机器学习的身体部位自动识别。前两种方法由于缺乏弹性而受到比较大的局限。田野等[11]采用机器学习的算法,选取心脏、肾脏和股骨头作为胸部、腹部及盆腔的代表器官来判断CT图像所属身体部位。该方法对原始二维Haar-AdaBoost方法进行了改进[12],根据器官的实际物理大小使用固定图像分辨率,有效地选择关键Haar特征,对图像进行学习后通过高斯拟合的方法对目标器官进行识别,从而判断其所属身体部位,实验结果表明该方法可以实现胸部、腹部和盆腔的有效识别。但是对于某些CT图像而言,若该图像不包括代表器官,则无法对该CT图像进行判断。
ROTH等[13]利用DICOM标签中的‘StudyDescription’and‘BodyPartExamined’将身体划分为颈部、肺部、肝部、盆腔及大腿,利用卷积神经网络对分类进行训练,从而得到一个可以辅助诊断的分类器。但通过DICOM标签对图像进行分类可能出现分类错误的情况。
本文在卷积神经网络的基础上建立了深度学习模型[14],将含有椎体的身体部位按照椎体划分为4类(颈椎-颈部,胸椎-胸部,腰椎-腹部,骶骨及尾骨-盆腔),通过多平面重建(Multiplanar Reconstruction,MPR)结合矢状位及冠状位对连续CT图像进行分类,探讨了利用卷积神经网络对CT图像进行定位的可行性。同时,为了避免因训练样本过少带来的过拟合问题,采用迁移学习及数据扩增方法提高了模型的泛化能力。
1 材料和方法
1.1 AlexNet卷积神经网络
本文所采用的神经网络为AlexNet网络[15],它是计算机视觉中首个被广泛关注的卷积神经网络,包括5个卷积层和3个全连接层,在第1,2,5卷积层后都跟随着池化层。
1.1.1 卷积层
卷积层是卷积神经网络中的基本结构。卷积是一种局部操作,通过一定大小的卷积核(通常5×5或3×3)作用于局部图像区域获得图像的局部信息。初始低层往往提取低阶特征,如边、角、曲线等。随着卷积层数的增加,卷积核提取的特征越来越复杂,卷积层一般形式如式(1)所示:
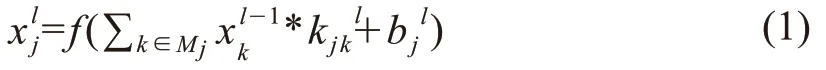
1.1.2 池化层
池化层实质为一种“降采样”操作,操作时基于局部相关性原理进行亚采样,从而在减少数据量的同时保留有用信息,通常有平均值池化和最大池化。同卷积层操作不同,池化层不包含需要学习的参数。池化有以下三种功能:①特征不变性;②特征降维;③在一定程度防止过拟合,一般表现形式如式(2)所示:

其中,β是下采样层的权重系数,bl是下采样层的偏置项。符号down(.)表示下采样函数,它通过对输入特征图xjl-1通过滑动窗口方法划分为多个不重叠的图块,然后对每个图块内的像素进行处理。本文中使用最大池化进行采样处理。
1.1.3 全连接层
全连接层一般位于网络尾端,对卷积层与池化层得到的二维向量特征转化为一维向量进行分类,其一般表现形式如式(3)所示:

其中,wl是全连接层的权重系数,bl为全连接层的偏置项。
1.1.4 反向传播算法
卷积神经网络训练使用的是反向传播算法,通过反向传播算法不断优化各个连接层损失函数的权值与偏置,从而使得真实值输出与计算值输出间的误差达到最小。对于不同的任务有不同的损失函数。本研究中所采用的损失函数为softmax交叉熵函数,通过随机梯度下降,权重系数以及偏置项的更新式如式(4)、(5)所示[16]:

其中,η为学习率,m为小批量样本(minibatch)的样本数目。
1.1.5 激活函数及其他本文中使用的卷积神经网络将ReLu作为激活函数,能够将线性变换的输出进行非线性变换。由于ReLu激活函数本身非常接近线性,还保留了易于优化的属性,故在随机梯度下降阶段的收敛速度较快,数学表示如式(6)所示:

同时,AlexNet通过使用随机失活(Dropout)随机忽略一部分神经元,以防止模型过拟合。
1.2 迁移学习
卷积神经网络的参数训练需要大量的训练样本,因此本文采用迁移学习来解决训练样本不足的问题[17]。迁移学习是一种机器学习的方法,指的是一个模型被重新用在另一个任务中作为预训练模型以提高其泛化能力。迁移学习可以通过已有的知识来解决小样本数据的学习问题,从而提升卷积神经网络在小样本数据集上的分类准确率。与传统机器学习方法相比,迁移学习不再要求必须有足够多的、可利用的训练样本才能学习得到一个好的分类模型,同时也不再要求用于学习的训练样本与新的测试样本满足独立同分布[18-19]。
本研究中的迁移学习示意图(见图1),首先利用ImageNet数据集对AlexNet网络进行训练作为预训练模型,在迁移学习阶段,对于卷积层C1~C5及FC6,将预训练模型的权重参数迁移至训练模型,同时随机初始化FC7、FC8,最后微调优化并在训练集上对整个网络进行训练从而进行参数更新。迁移学习层数不同,初始学习率也有所不同。如若学习速率过小,会导致收敛速度过低,会使训练的时间增加;如若学习速率太大,会阻碍模型收敛,且容易产生震荡。因此初始学习率的设置也会影响到模型的最终效果。本研究中设定的初始学习率为0.005。
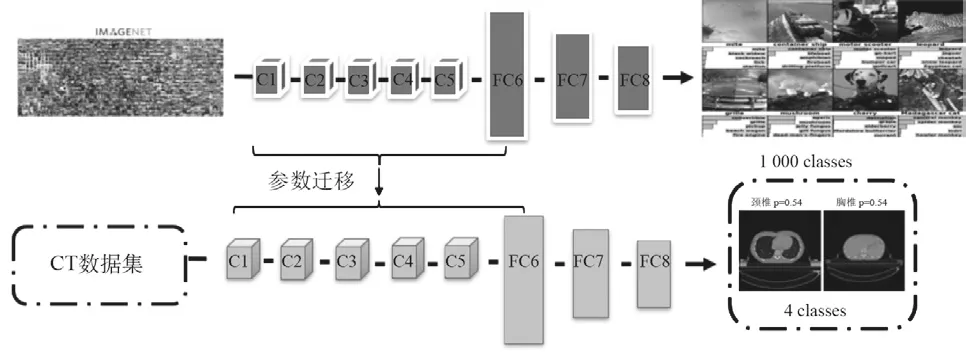
图1 利用预训练模型对AlexNet模型调优示意图Fig.1 Illustration of AlexNet model fine-tuning based on pre-trained model
1.3 实验数据集
选取45例患者的CT扫描图像(其中颈部序列15例,胸部序列15例,腹部及盆腔序列15例),共3 153张CT图像,均使用Siemens syngo CT扫描机采集,扫描层厚为3.0 mm,图像重建分辨率512×512。将CT图像通过RaiAnt软件进行三维MPR重建,由两位医生结合重建矢状位与冠状位对横断面CT图像进行分类。方法为结合矢状位与冠状位找到C1的上界与C7的下界,二者之间的所有横断面CT图像定义为颈部;C7下界(T1上界)到T12下界定义为胸部;T12下界(L1上界)到L5下界定义为腹部;L5下界(S1上界)到尾骨下界定义为盆腔。具体见图2,将含有椎体的身体部分划分为4类,颈部共595张(图1A-1B),胸部共1 105张,腹部共875张,盆腔共580张。
将分类后数据的3/5用于训练,1/5用于验证,余下1/5用于测试。图像均由DICOM格式转换为png格式进行训练及测试。
1.4 数据扩增
在使用深度学习进行图像分类时,通常训练的数据越多,模型的拟合性能越好。尽管在有些情况下图像的质量不够好,但是只要模型能从中提取并学习到有用的信息,那么模型的性能就越好。因此数据扩增方法常被用来提高模型的性能以及防止过拟合[20-21]。
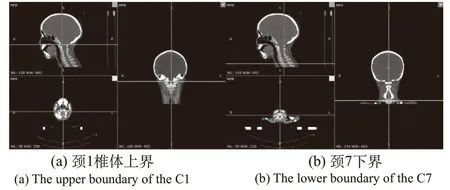
图2 以颈部为例,利用多平面重建进行分类示意图Fig.2 The classification sketch map based on multi-plane reconstruction
本文中采用了旋转、放大、随机增加对比度及亮度、翻转及随机扭曲等操作对原始图像进行数据扩增,每一类扩增6 000张,在一定程度上还解决了数据集不平衡问题。对样本数目比较少的类别采用扩增技术,向数目多的类别样本补齐。
具体的扩增参数如下:旋转概率为0.7,向左向右旋转角度最大角度均为10o;放大概率为0.4,最大倍数为1.1,最小倍数为1.3;随机增加对比度及亮度的概率为0.6,最小倍数为0.8,最大倍数为1.3;翻转概率为0.4;随机扭曲概率为0.2,网格宽度和高度均为4,梯度为8。数据扩增示意图,如图3所示。

图3 数据扩增示意图Fig.3 Data augmentation diagram.
1.5 模型训练
图4为模型训练示意图,图像格式的转换、随机分类、图像扩增、训练及测试均使用python语言完成,卷积神经网络框架为Google的Tensorflow[22]。

图4 模型训练流程图Fig.4 The workflow of model training
训练时,初始学习率为0.005,训练的批尺寸(batch size)为400,随机失活率(dropout rate)为0.8,训练次数(epochs)为30,硬件系统为英伟达GTX 1080TI GPU工作站。
1.6 评估方法
本文使用准确率(accuracy)作为分类评价标准,其定义为分类正确的样本数占样本总数的比例。值越高,说明分类效果越好。
2 结果
表1给出了训练数据扩增前及扩增后的样本数及相应的分类准确率,可以看到数据扩增后的准确率由94.95%提高到了97.72%。表2利用混淆矩阵表示了测试时的结果。表3给出了两种情况下训练及测试时间的差别,扩增后数据训练及测试时间都有所增加。

表1 训练数据扩增前#1及扩增后#2的分类准确率Tab.1 Classification accuracy on the original test images before1 and after2 data augmentation
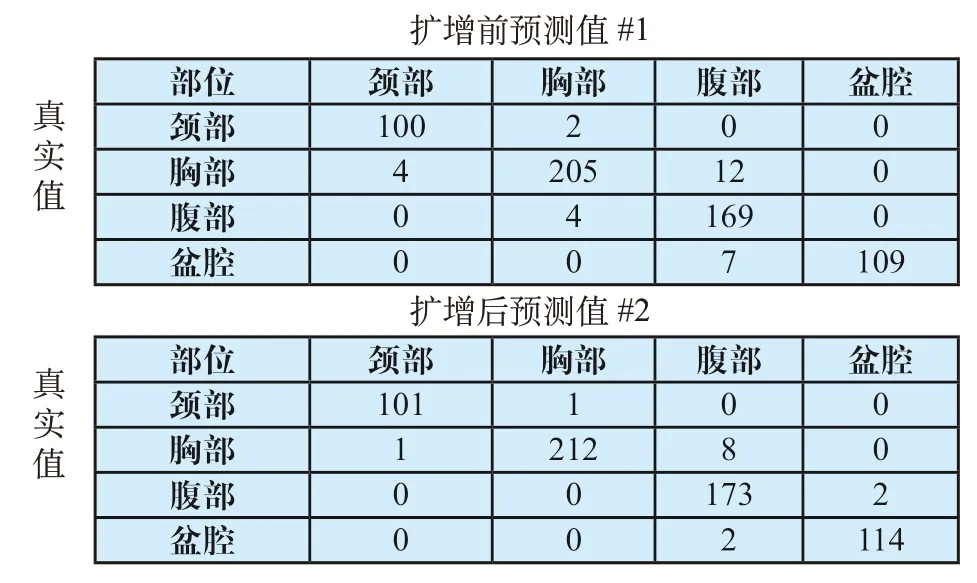
表2 训练数据扩增前#1及扩增后#2的混淆矩阵Tab.2 Confusion matrixon the original test images before1 and after2 data augmentation

表3 扩增前#1及扩增后#2训练时间及测试时间的比较Tab.3 Comparison of the training time and testing time before1 and after2 data augmentation
3 讨论
目前,应用于临床和研究的医学图像自动分割工具,无论是基于图谱/模板还是基于深度学习模型,都包含了一个预先的假设,即要进行分割的图像所属身体部位是已知的,针对特定解剖结构或区域设计的自动分割算法模型会被自动调用。而在具体实践中,这一假设是由前期人工选择完成的。
一个通用的图像分割工具应该是这样的:把任一医学图像输入到系统中,系统自动判断该图像所属身体部位,然后自动调用针对该部位的自动分割算法模型,经过计算后自动得到高精度的区域勾画结果,实现图像的“一键式”自动分割功能。
尽管DICOM 头文件信息有CT扫描部位的信息,但是由于不同医院的建模差异或者扫描方式差异,通过DICOM头文件信息对CT图像所属身体部位进行识别是不可靠的。另外,通过检测图像中是否有某一器官来判断其所属身体部位也存在一定的局限性,因为人体的内在解剖结构是非恒定的,它受到诸如性别、身高和体重等影响。
本文基于ROTH等[13]的研究方法,利用卷积神经网络和椎体分类对CT图像进行判断,从而实现了CT图像所属身体部位的自动分类,其中基于椎体的划分避免了样本重叠或漏缺的现象。另外,通过将迁移学习应用于模型训练和数据扩增解决了小样本量的问题。我们记录了扩增前及扩增后训练时间及测试时间,发现随着样本量的扩增,训练时间及测试时间会相应的增加,这意味着训练样本不是越多越好,因为它会以时间为代价。
AlexNet为卷积神经网络中一个较为基础的神经网络,在本文的分类中,由于类别较少(4类),因此取得了很好的结果。在处理更细、更复杂的分类工作时,可通过增加卷积层或是改进特征提取策略来获得理想的结果[23-24],因此在建立相应的模型方面还有很大的拓展空间。
4 结论
利用卷积神经网络对任一CT图像按照椎体范围进行精确分类和定位是可行的,而数据扩增技术在提高分类准确率的同时也要增加训练及测试时间。
