套索回归模型在教师评分系统中的应用研究
2019-12-07◆张戈朱俭
◆张 戈 朱 俭
套索回归模型在教师评分系统中的应用研究
◆张 戈 朱 俭通讯作者
(中国社会科学院大学 北京 102488)
本文主要探讨了L1正则化模型和L2正则化模型在大学教师评分系统中的应用。对教师评分已有数据进行分析,建立拟合预测模型,采用岭回归和套索回归两种线性回归方法建模,在此基础上对模型的优化方案进行了深入研究。
岭回归;套索回归;过拟合;调整参数
教师评估系统是各个高校几乎都会用到的一套对教师教学水平的评价系统。随着各个大学对教学评估系统应用的推进,其评价体系和结构日趋完善,评价数据也像滚雪球一样逐年累积,数据量越来越庞大。在大数据和机器学习背景下,如何能够有效地利用这些数据,对它们加以分析和处理,并在此基础上得到对未来更有价值的信息和结果是我们最为关心的问题。因此,我们的研究在已有数据基础上拟合一个预测模型,用该模型给出教师的合理评分。
1 问题提出
在教学评估系统中,系统会根据该课程的全体学生的打分给出综合评分。打分项的设计是在原有系统评分项基础上不断更新迭代得出的评分项,包括“备课认真”、“有教材课件”、“有辅助资料”、“有教具”、“遵纪守时”、“认真负责”、“热情敬业”、“进度适当”、“重点突出”、“难易适度”、“有吸引力”、“教学内容完整”、“逻辑清晰”……一共40个打分项。每个打分项的取值范围不等,但40个单项的最高分总和为50。除了这40个单项之外,还有一个“综合评价”分,该项最高分为50。学生根据自己的感受对以上各项打分。收集数据后,系统分别算出各单项平均分(无异常数据处理)和“综合评价”的平均分,然后将这些平均分相加,算出来的分数即为教师评分(最高100分)。
从目前评估系统的评分方法来看,该评价体系存在这样几个问题:第一,评分项过多(41个),建立的模型过于复杂,容易出现过拟合现象;第二,各个单项的权重均一致,设计不合理。比如“有教具”这项对于不同专业的老师并不一样,有的专业需要教具,有的专业只用课件讲课即可,因此类似这种单项,其权重不应和其他单项一致;第三,各个单项的取值范围并不相同,有的单项取值在0到10之间,有的单项取值在0到3之间,这样就造成了各单项数据影响力差异过大,在涉及距离公式计算的模型中,影响预测结果的准确度。
2 线性模型
针对以上问题,本研究将分析采用哪种回归拟合数据,建立预测模型。我们先来看回归分析中最经典的线性模型——线性回归,也称为普通最小二乘法(OLS)。它的原理是,当训练数据集中y的预测值和其真实值的平方差最小的时候,此时的w值和b值作为线性函数的w值和b值。线性回归模型没有参数可调,也就是说模型的复杂度用户不可控。在我们选取了500条数据进行线性回归测试,可以看到模型测试评分训练集和测试集得分差异过大,这表明模型出现了过拟合,而且训练集测评仅为0.5分,模型预测结果准确率不高,因此我们尝试使用岭回归模型。
2.1 岭回归模型
岭回归是回归分析中常用的线性模型。它可以有效防止模型的过拟合现象。在岭回归中,模型会保留所有的特征变量,但是会减小特征变量的权重值,特征变量对预测结果的影响“统一”变小了。这种通过保留所有特征向量,只降低特征向量的系数值来避免过拟合现象的方法,称为L2正则化。L2 正则化公式非常简单,直接在原来的损失函数基础上加上权重参数的平方和:

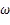
2.2 套索回归模型
套索回归(lasso)是除了岭回归之外的一个对线性回归进行正则化的模型。和岭回归一样,它也将特征向量系数限制在非常接近0的范围,但是它对系数进行限制的方式不同,它直接在原来的损失函数基础上加上权重参数的绝对值:
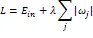
3 模型优化
3.1 异常数据处理
对于学生的评分会因各种原因存在数据异常的情况,比如有的学生会根据自己的喜好、老师给的平时成绩或者一次和老师的谈话,就对老师打出比较极端的分数,少数过高或过低的评分就是我们所说的异常数据。这些数据并不能合理体现老师的教学水平,相反,如果这些数据的权重和其他数据一样,可能会对老师评价得到不相符甚至于相反的结果。因此,我们需要对这样的数据对异常判断和处理。

图1 线性函数方程
首先,我们选取一些过高或过低的分数,并将它们删除。但是这“一些”是多少,5%、10%还是15%,不能靠数据处理人员一张嘴来决定,而是靠数据说话。因此我们在做处理时,依次选取最高和最低的5%、10%和15%的数据进行删除,按删除后的数据重新拟合模型,并给出模型评分,将评分最高的删除比例保留,从而得到相对合理的拟合模型。图2是采用模型测评方法-交叉验证法在去掉15%的两端数据后得到的模型测评分数。测评分数为0.88,可见在处理掉一些极端数据后,模型预测的准确率比较理想。

图2 异常数据处理后模型测评分数
3.2 模型参数优化
在前面我们选择套索模型对数据进行拟合,但模型的测评分数并不算高,这样一来,预测结果即教师评估分数可能会出现偏差,因此我们进一步调整套索模型参数alpha和最大迭代次数max_iter对模型进行优化。我们采用python的sklearn库来建立套索模型,实验环境采用jupyter notebook。
图3是python3编写的在调整alpha参数为1、0.1和0.0001,max_iter参数为100000时的代码。图4是在上述不同的alpha值,max_iter为100000时的套索回归系数值对比图。

图3 不同alpha值max_iter值为100000时套索模型代码
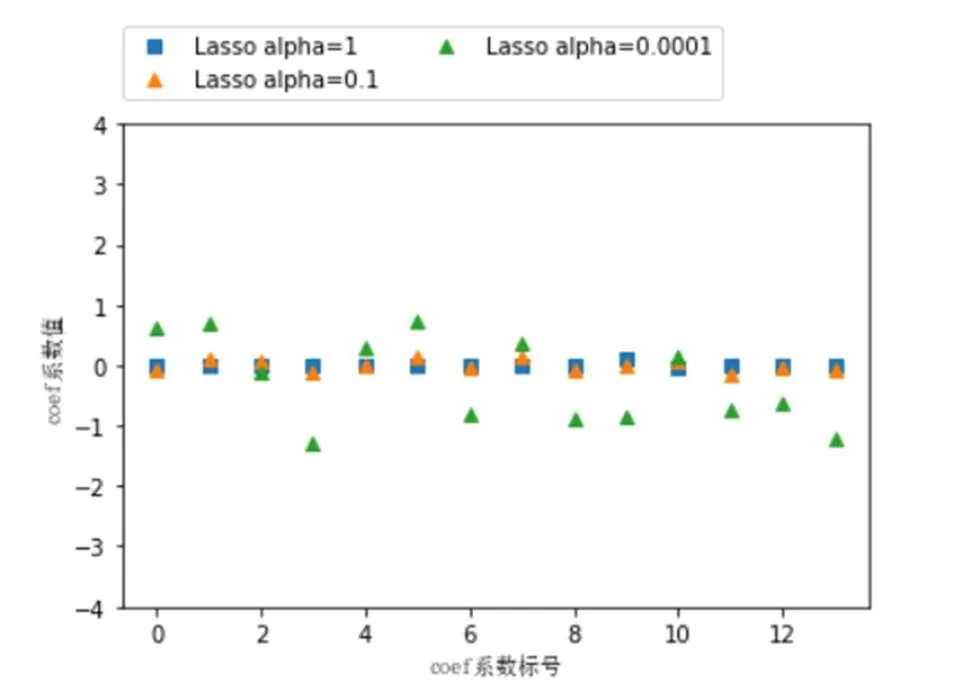
图4 不同alpha值套索回归系数值对比
从图中可以看到当alpha值为1和0.1的时候,大部分系数都为0,这就意味着几乎所有特征向量均被正则化,对我们的预测结果均起不到作用。alpha值为0.0001的时候,只有少数几个系数为0,这个就是套索模型自动选择出的可以忽略不计的特征向量,因此,我们将alpha系数调整为0.0001。同理,在alpha值固定的情况下,我们继续调整max_iter参数,这样就可以使套索模型优化到最佳状态,同时结合训练集和测试集的测评分,最终得到最理想的预测模型。
4 总结
我们经过线性模型的分析和研究最终确定套索模型作为系统的拟合模型,解决了由过多特征向量带来的模型过拟合现象,依靠该模型的自主选择特征向量机制自动淘汰了一些权重值不高的几乎可以忽略的特征,降低了模型复杂度,使模型更为合理,更利于模型的泛化。在确定回归模型后,我们进一步对模型的主要参数进行了调整,使数据训练集和测试集评分均得到了提高,模型可用度提升,教师的评分更为准确。
当然,系统中仍存在一些问题有待解决,比如特征向量值取值范围存在差异,会造成有的特征向量影响力会明显高于另外一些特征向量。本研究在今后的工作中会继续研究如何采用数据归一化和标准化的方法使数据更为合理、可用。
[1]肖玲玲,郑华,林烁烁,陈晓文.基于岭回归的四带图像偏色校正算法[J].计算机系统应用,2019(08):129-135.
[2]王宏伟,黄元生,姜雨晴,刘诗剑.基于套索算法和高斯过程回归的中长期居民用电量概率预测[J/OL].华北电力大学学报(自然科学版):1-11[2019-08-29]
[3]红色石头的专栏.https://blog.csdn.net/red_stone1/article/details/80755144
[4]李克文,周广悦,路慎强,郭俊.一种基于机器学习的有利区评价新方法[J].特种油气藏,2019,26(03):7-11.
[5]谷慧娟. 基于套索回归的财务危机预警模型研究[D].天津财经大学,2010.
[6]汤荣志. 数据归一化方法对提升SVM训练效率的研究[D].山东师范大学,2017.
[7]张里,王兰,李红军,廖小君,王婷婷,张江林,刘友波.基于聚类分析的风电功率预测数据预处理方法[J].可再生能源,2018,36(12):1871-1876.
[8]李克文,周广悦,路慎强,郭俊.一种基于机器学习的有利区评价新方法[J].特种油气藏,2019,26(03):7-11.
[9]Science; Studies Conducted at Georgetown University on Science Recently Reported (Ridge regression estimated linear probability model predictions of O-glycosylation in proteins with structural and sequence data)[J]. Science Letter,2019.
[10]Wen Lei,Shao Hengyang. Analysis of influencing factors of the carbon dioxide emissions in China's commercial department based on the STIRPAT model and ridge regression.[J]. Environmental science and pollution research international,2019.
[11]Gana Rajaram,Vasudevan Sona. Ridge regression estimated linear probability model predictions of O-glycosylation in proteins with structural and sequence data.[J]. BMC molecular and cell biology,2019,20(1).
[12]Wang Chunjie,Li Qun,Song Xinyuan,Dong Xiaogang. Bayesian adaptive lasso for additive hazard regression with current status data.[J]. Statistics in medicine,2019,38(20).
[13]张倩.基于随机森林回归模型的住房租金预测模型的研究[D].东北师范大学,2019.
[14]Yaqing Zhao,Howard Bondell. Solution paths for the generalized lasso with applications to spatially varying coefficients regression[J]. Computational Statistics and Data Analysis,2020,142.
中国社会科学院大学校级科研项目资助。
