基于用户轨迹数据的用户兴趣区域推荐(云南大学信息学院,云南 昆明 650504)
2019-12-06龙玉绒王丽珍陈红梅
龙玉绒 王丽珍 陈红梅
摘 要:推荐系统是通过分析已知信息和用户偏好,在用户选择物品或服务时,向用户提供帮助和建议的系统。但是目前大部分推荐系统都是基于用户评价或评分信息向用户推荐购物、电影等电子商务服务,基于用户轨迹数据进行用户兴趣区域推荐的研究十分罕见。用户的轨迹数据蕴含了用户的偏好,不同的轨迹反映不同的用户特性。所以提出一种从用户轨迹数据中挖掘最大频繁项集,并将最大频繁项集用于计算用户相似性和偏好的推荐方法。该推荐方法还综合考虑了相似用户访问次数、置信度和用户住宅信息等可能会影响推荐质量的因素。将提出的方法和基于协同过滤的推荐方法、基于关联规则的推荐方法进行比较,结果显示本文提出方法的效果较好。
关键词:轨迹数据挖掘;区域推荐;相似用户;频繁项集
中图分类号:TP391 文献标识码:A
User Interest Region Recommendation Based on User Trajectory Data
LONG Yurong,WANG Lizhen,CHEN Hongmei
(School of Information Science and Engineering,Yunnan University,Kunming 650504,China)
Abstract:A recommendation system is a system which provides help and advice to users by analyzing the existing information and users' preferences when users choose goods or services.However,most recommendation systems recommend shopping,movies and other e-commerce services to users based on user evaluation or scoring information.It is very rare to conduct research on user interest region recommendation based on user trajectory data.User's trajectory data contains users different preference,reflecting different user characteristics.Therefore,it is necessary to make recommendations based on user trajectory data.This paper presents an interest region recommendation method,which calculates user similarity and preference by mining maximum frequent itemsets from user trajectory data.We take into account three factors,including numbers of similar user visits,confidence and user residence information.In the paper,the proposed method is compared with the recommendation algorithm based on collaborative filtering and the recommendation algorithm based on association rules,and the results show that the proposed method is effective.
Keywords:trajectory data mining;region recommendation;similar users;frequent itemset
1 引言(Introduction)
近年來,基于位置的社交网络[1]十分流行,用户可以将他们的活动轨迹数据或者访问的地点在网络上进行共享,这些数据都带有位置信息。推荐系统[2-4]可以运用于此类数据。Berjani B[5]、Hu L[6]和Liu Y[7]等人均是利用社交数据进行位置推荐。但是,现有的位置推荐方法大体有如下不足:
(1)数据多为用户签到数据,蕴含信息单一,不能准确评估用户偏好。
(2)向用户推荐的是一个兴趣点而不是一个兴趣区域。
(3)对用户进行相似性评估时,需要用户的评分信息。
针对上述问题,本文提出了一种从用户轨迹数据中挖掘最大频繁项集,并基于最大频繁项集计算用户相似性和偏好用于兴趣区域推荐的方法。
本文主要贡献包括:
(1)不需要用户的评分信息,从用户轨迹数据转化得到的事务数据中挖掘最大频繁项集,基于最大频繁项集定义用户相似性。
(2)提出一种不产生候选模式,只需要扫描两次数据库的频繁项集挖掘方法。
(3)提出一种考虑了相似用户访问次数、置信度和住宅信息三种因素的用户兴趣区域推荐方法,该方法能更准确地进行用户兴趣区域推荐。
2 定义(Definition)
基于用户轨迹数据进行用户兴趣区域推荐的算法中,主要的挑战是相似用户的度量及用户兴趣区域推荐。本节首先对停留区域和停留区域间的邻近关系进行定义,用于将轨迹数据转化为事务数据。其次给出相似用户的定义及推荐得分的定义,最后给出本文的问题定义。
设I={i1,i2,i3,..,in}是项的集合,则称为项集,K=|X|,X称为K项集。事务是事务数据库中的一条记录,代表发生的一次事件。数据库D={T1,T2,T3,...,Tm}是事务的集合,称为事务数据库。支持度计数是指包含特定项集的事务个数。频繁项集是指在事务数据D中出现的频率大于支持度计数阈值的项集。如果频繁项集L的所有超集都是非频繁的,那么频繁项集L为最大频繁项集。
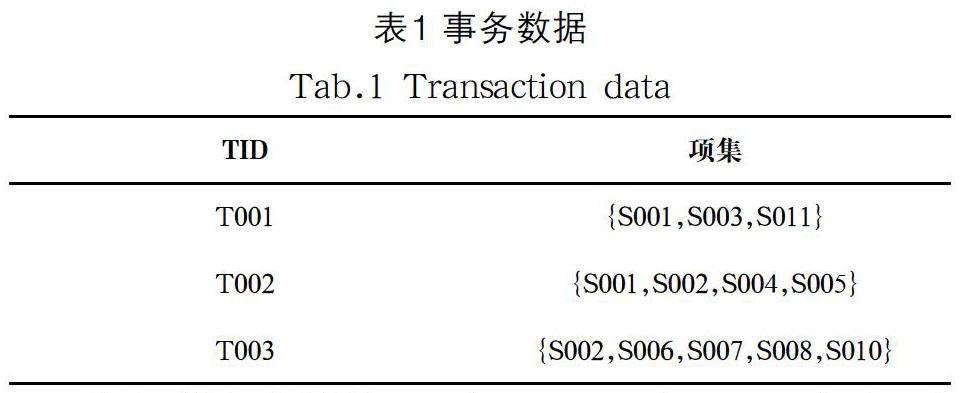
例1:如表1所示,S001是项,{S001,S003}是一个项集,TID:T001是一个事务。D={T001,T002,T003}是事务数据库。{S001,S003}的支持度计数为:1,因为只有一条事务包含{S001,S003}。
定义1(数据点描述)
定义2(轨迹数据)轨迹数据是由许多数据点按时间顺序组成的一个数据点序列。
定义3(停留区域)停留区域是指用户轨迹数据中移动速度低于平均速度或某个用户给定的速度阈值的区域。
例2:如图1所示,图中给出用户A的一条轨迹数据P={p1,p2,p3,p4,p5,p6,p7}。如果用户A在点p3、p4、p5、p6区域内的移动速度小于一个给定的速度阈值,例如30米/分钟,那么区域A1:{p3,p4,p5,p6}是用户A的一个停留区域。
本文定义停留区域是为了对用户的轨迹数据进行预处理,将轨迹数据中对推荐没有价值的数据忽略。由于我们拟推荐的是用户可能访问的兴趣区域,所以我们只关注用户长时间停留或移动速度较慢的区域,即停留区域。假设用户A在区域B1内的速度为600米/分钟。我们只认为用户A经过了区域B1,并不认为A访问了区域B1。
定义4(邻近关系)假设有两个停留区域A1和B2,如果两个停留区域的最小外包矩形有重叠时,我們称停留区域A1和B2具有邻近关系。
图1 停留区域
Fig.1 Stay region
图2 邻近关系
Fig.2 Proximity relationship
本文定义停留区域间的邻近关系是为了确定用户兴趣区域的位置相关性,并确定访问过相关区域的用户。已知停留区域集:SR={A1,A2,B1,B2,C3}。通过计算确定A1、B2、C3具有邻近关系,可以确定访问了邻近区域的用户A、B、C具有一定的访问相似性。
例3:如图2所示,根据定义4,A1、B2和C3是相互邻近的停留区域,对于这样的相互邻近的停留区域,我们可以确定一个用户兴趣区域S,用户兴趣区域S为A1、B2和C3三者最小外包矩形并集的最小外包矩形,图2中虚线的矩形就是用户兴趣区域S。并且确定用户A、B、C访问过该区域。我们将其转化为一条事务:TID为S,项集为{A,B,C}。表示兴趣区域S被用户A、B、C访问过。
根据上述的定义,我们可以将用户的轨迹数据转化为两类事务数据集,一类事务数据TID为用户兴趣区域,项集为用户,如表2所示为一个可能的“兴趣区域—用户”事务数据集,其中TID为用户兴趣区域的编号,项集为访问过该区域的用户。例如第一条事务表示用户{A,B,C,F,H}访问过用户兴趣区域S001。第二类事务数据TID为用户,项集为用户访问过的兴趣区域,如表3所示为一个可能的“用户—兴趣区域”事务数据集。例如第一条数据表示用户A访问过兴趣区域S001、S003、S005。
我们从第一类事务数据集中挖掘最大频繁项集,其中项为用户,包含在最大频繁项集中的用户都是频繁访问过相同的兴趣区域的用户,在一定程度上这些用户的兴趣区域是相似的,于是认为用户偏好也是相似的。所以不需要用户评分数据,我们可以定义相似用户。
定义5(相似用户)假设L为一个最大的频繁项集,我们称属于L的用户为相似用户,其相似性为1,表示为:
其中ui、uj分别表示两个用户。
我们知道,关联规则X1X2表示项集之间的关联关系。规则置信度是指项集X1出现的情况下项集X2出现的概率。我们将其运用到推荐得分的定义中。
定义6(推荐得分)给定一个待推荐的用户兴趣区域S,Score(s)表示待推荐用户兴趣区域S的推荐得分,Score(s)的计算如下:
其中,为相关规则置信度,vt为该用户兴趣区域被相似用户访问的次数,d表示用户住宅区与该用户兴趣区域的距离。
为何要如此定义推荐得分?
从二类事务数据中可挖掘出项为用户兴趣区域的频繁项集。考虑规则置信度是为了推荐频繁项集中的用户兴趣区域。规则置信度表示该用户在访问过其他频繁项集的情况下访问待推荐用户兴趣区域的概率,规则置信度越高,用户访问该用户兴趣区域的概率越大。假设用户兴趣区域{S1,S2,S3}是频繁项集,用户A访问过用户兴趣区域S1和S2,将用户兴趣区域S3推荐给A时,需要考虑规则{S1,S2}{S3}的置信度。考虑相似用户的访问次数是为了将相似用户偶然访问的用户兴趣区域排除,并且用户兴趣区域被相似用户访问的次数越多,说明该用户兴趣区域对这类用户的吸引力越大。考虑用户住宅区和推荐用户兴趣区域之间的距离是因为推荐时离用户住宅区距离较近的用户兴趣区域更有可能被该用户访问。
问题定义(基于用户轨迹数据的用户兴趣区域推荐)给定用户轨迹数据集{PA,PB,PC,...,Pk},支持度计数阈值。向用户推荐top-n个最有可能访问的用户兴趣区域。
3 算法(Algorithm)
在这一部分,将介绍我们提出的两个算法:基本算法basic_algorithm和改进算法improved_algorithm。basic_algorithm算法挖掘频繁项集时运用的是类apriori方法。由于基本算法在计算停留区域间邻近关系时,算法时间复杂度较高,挖掘频繁项集时需要多次扫描数据库、产生大量的候选,所以提出改进算法:improved_algorithm。改进算法将网格划分运用到邻近关系的计算中减少不必要的计算,减少时间的耗费。同时,改进算法在挖掘频繁项集时提出一种不需要多次扫描数据库、不产生候选模式的挖掘方法。
3.1 基本算法:basic_algorithm
首先介绍基本算法basic-algorithm,基本算法中挖掘频繁项集运用的是类apriori[8]方法。
算法1:basic-algorithm
输入:用户的轨迹数据;top-n的n值;频繁项集支持度计数阈值sup。
输出:推荐给用户的top-n个用户兴趣区域。
变量:SRS:用户停留区域集;D:事务集;PIS:“兴趣区域—用户”事务数据(项为用户)的最大频繁项集;RPIS:“用户—兴趣区域”事务数据(项为兴趣区域)的频繁项集;Fk:k阶频繁项集;Ck:k阶频繁项集候选;SUS:相似用户集;Result:推荐结果;RL(i):用户i的推荐列表。
步骤:
步骤1是从用户的轨迹数据中产生停留区域。步骤2是运用用户和其停留区域等信息将轨迹数据转化为事务数据集。步骤3是运用类apriori方法产生项为用户的最大频繁项集,其中3.1是赋初始值,3.2是产生一阶的频繁项集,步骤3.5是通过连接k-1的频繁项集产生k阶频繁项集的候选模式,步骤3.6是统计k阶候选模式的支持度计数,步骤3.7是判断候选模式的支持度计数是否满足阈值产生k阶的频繁项集,步骤3.8是停止条件,当k阶频繁项集为空时循环停止。步骤4是产生项为用户兴趣区域的频繁项集。步骤5是产生相似用户集。步骤6是产生top-n个推荐用户兴趣区域,其中6.1是产生候选推荐集、计算每一个候选推荐用户兴趣区域的得分并按得分进行降序排序,步骤6.2返回top-n个推荐用户兴趣区域。
3.2 改进算法:improved_algorithm
由于基本算法耗时长,查找停留区域间的邻近关系的时间复杂度为。挖掘频繁项集时需要多次扫描数据库。为了改进这些问题我们提出了改进算法。
根據邻近关系的定义,如果两个停留区域的最小外包矩形重叠,两个停留区域之间具有邻近关系。为了识别所有的邻近关系,我们需要计算所有停留区域之间的关系,所以当停留区域的数量巨大时,这是一步非常耗时的操作。为了减少不必要的计算,在改进算法中我们采用网格划分来快速搜索邻近关系。接下来,我们将介绍网格划分。
网格划分:首先,找到所有停留区域最小外包矩形中最大的长度和宽度,分别表示为Lw和Lh。对于一个最小外包矩形,长度是指它在X轴方向上的长度,宽度是指它在Y轴方向上的长度。接下来,找出最小外包矩形最小的X、Y坐标和最大的X、Y坐标,分别表示为minX、minY、maX和maxY。所有停留区域的最小外包矩形的X坐标位于区间[minX,maxX],Y坐标位于区间[minY,maxY]。将空间[(minX,minY),(maxX,maxY)]划分为许多网格。网格的长度是Lw,宽度是Lh。图3给出了网格划分示例。
如何将停留区域的最小外包矩形映射到网格中?
因为停留区域的最小外包矩形是一个区域而不是一个点,它可能位于多个网格中。所以我们将最小外包矩形的中心点映射到网格中,中心点所在的网格也就是该停留区域所在的位置。首先,我们定义一个二维数组:grid来存储位于网格中的停留区域。其次,我们计算停留区域所在的网格。最后将其存储在数组中。
图3 网格划分
Fig.3 Grid partition
例4:在空间中maxX=9、maxY=13、minX=1、minY=1、Lw=2、Lh=3,{(3,3),(3,6),(5,6),(5,3)}这四个点是停留区域o最小外包矩形的坐标。我们可以计算出最小外包矩形的中心点(4,4.5),中心点所在的网格就是停留区域o所在的网格。因此,我们可以计算o所在网格的行数和列数。行号为:=1,列号为:=1。因此,grid[1,1]是o所在的网格。
搜索区域:一个网格的搜索区域是它自己和周围的8个网格。
例5:如图3所示,对于停留区域最小外包矩形o所在的网格,阴影网格为搜索区域。假设位于o附近的停留区域的外包矩形都是最大的。如果它们的中心点位于阴影网格中,它们可能与o有邻近关系。如果中心点没有位于阴影部分则它们不可能与o有邻近关系。因为网格的长度是停留区域最小外包矩形的最大长度,网格的宽度是停留区域最小外包矩形的最大宽度,即使最小外包矩形是最大,停留区域最小外包矩形也不会在X轴方向或Y轴方向跨三个网格。所以,我们不需要搜索其他区域。
另外,由于基本算法在挖掘频繁项集时需要多次扫描数据库,这个操作十分耗时,并且会产生大量的候选集。在改进算法中我们提出一种新方法来挖掘频繁项集。我们以字典序来存放项集和其支持度计数,当我们遍历数据库时对结果集进行更新。这种方法只需要扫描两次数据库,并且不产生候选。为了方便描述,我们将产生频繁项集这部分算法称为DIC_Item。例6详细地阐述了DIC_Item算法挖掘频繁项集的过程。
例6:以从表2的事务数据中挖掘频繁项集为例说明DIC_Item算法。第一次进行遍历数据库,将数据库中支持度计数小于阈值的项去掉,如表4所示,我们进行遍历后可以得到项和其支持度计数:{A:2,B:2,C:2,D:2,E:1,F:1,G:1,H:2},假设我们的阈值为2。我们将支持度计数小于2的项去掉,对项集进行映射,得到如表4所示的结果。
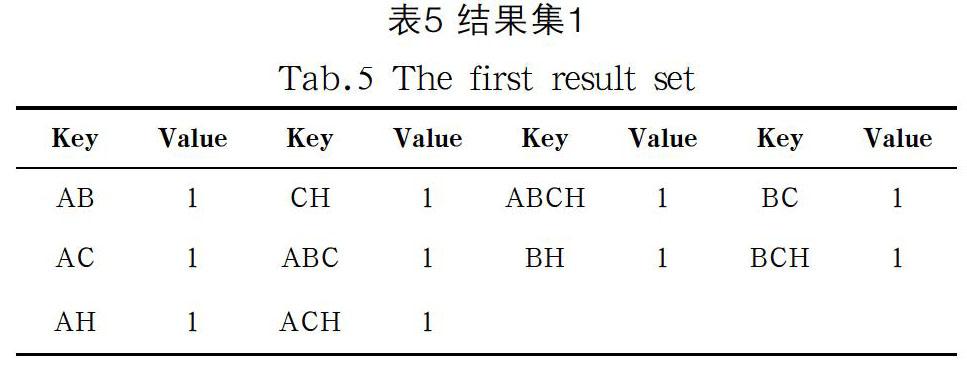
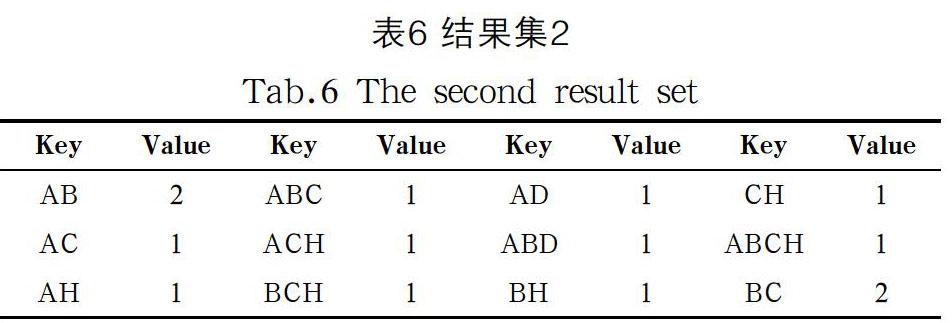
接下来,我们再次遍历数据库对结果集内容进行添加和更新,我们扫描S001的映射集得到项集{AB,AC,AH,BC,BH,CH,ABC,ACH,BCH,ABCH},对结果集中没有的项集进行添加,已存在的项集更新其Value值,得到如表5所示的结果。扫描S002的映射集得到项集{AB,AD,BC,ABD},对于结果集中没有的{AD,ABD}项集添加对应的Key和Value。对于已有的{AB,BC}更新其Value值,得到如表6所示的结果。扫描完所有的事务后得到如表7所示的结果。扫描完所有的事务后对结果集进行遍历,去掉结果集中Value值小于阈值的项集,最后得到的频繁项集是:{AB,BC,BH,CH,BCH}。
根据上述方法:网格划分、DIC_Item,我们的改进算法:improved_algorithm过程如下:
算法2:improved_algorithm
输入:用户的轨迹数据;top-n的n值;频繁项集支持度计数阈值sup。
输出:推荐给用户的top-n个用户兴趣区域
变量:SRS:用户停留区域集;D:事务集;PIS:“兴趣区域-用户”事务数据(项为用户)的最大频繁项集;RPIS:“用户-兴趣区域”事务数据(项为兴趣区域)的频繁项集;F1:1阶频繁项集;G:网格集合;GS:当前网格中停留区域集合;GI:位于搜索区域的停留区域集合;SR,SI:停留区域;S:区域集合;DIC:结果集;SUS:相似用户集;Result:推荐结果。
步骤:
步骤1是从用户的轨迹数据中产生停留区域。步骤2是运用用户和其停留区域等信息将轨迹数据转化为事务数据集,其中2.1是将停留区域映射到网格中,2.2—2.8是遍历网格找寻邻近关系,利用邻近关系找寻属于同一个用户兴趣区域的停留区域并将其转化为事务。步骤3是利用DIC_Item算法产生项为用户的最大频繁项集,其中3.1是第一次扫描事务并得到事务的映射集,3.2是第二遍扫描事务,同时更新结果集,3.3是判断结果集中Value值大于支持度计数阈值的部分。步骤4是产生项为用户兴趣区域的频繁项集。步骤5是产生相似用户集。步骤6是产生top-n个推荐用户兴趣区域,其中6.1是产生候选推荐集、计算每一个候选用户兴趣区域的得分并按得分进行降序排序,步骤6.2返回top-n个用户兴趣区域。
4 实验(Experiment)
第一,比较基本算法和改进算法在不同支持度计数阈值和不同事务数量条件下执行的时间效率。第二,比较三种算法的推荐质量:improved_algorithm算法、基于关联规则推荐[9]和基于协同过滤推荐算法[10]。第三,通过实验分析推荐top-n个用户兴趣区域给用户中n值对准确率的影响。所有算法均采用C#进行编写,并且在Core i3 1.8GHz和4GB内存的计算机上运行。
实验中采用的数据有两种:一种是真实的GPS轨迹数据,它记录了182个用户从2007到2012年的轨迹数据。另外一种是模拟数据,模拟数据是随机产生的,用户兴趣区域和访问过该兴趣区域的用户都是随机产生。
4.1 时间性能的比较
对basic_algorithm算法和improved_algorithm算法进行时间性能的比较。实验研究了事务数量和支持度计数阈值两个参数对算法执行时间的影响
4.1.1 事务数量对算法执行时间的影响
首先,我们来评估事務数量对算法执行时间的影响。在这组实验中,我们采用模拟数据,事务的数目从5000增加到20000。如图4所示,随着事务数目的增多,算法的执行时间也增大。因为随着事务数目的增多,项集的数目也增多,所以相似用户的数量和待推荐用户兴趣区域都会增多,计算推荐得分的次数也会增多。因此,算法执行时间增大。然而,改进算法在计算频繁项集时不需要多次扫描数据库,不采用连接产生候选项集,所以改进算法的执行时间比基本算法的执行时间少。从图4可知改进算法improved_algorithm的执行时间没有basic_algorithm增长迅速,这说明了改进算法improved_algorithm的效果。
4.1.2 支持度阈值对算法执行时间的影响
接下来我们分析支持度计数阈值对算法的影响,支持度计数阈值从8减少到2。如图5所示,随着支持度计数阈值的下降,算法的执行时间增加。这是因为支持度计数阈值变小后满足阈值的项集会增多,从而产生更多的频繁项集。由于本文衡量相似用户是根据最大频繁项集来进行衡量,所以最大频繁项集增多相似用户也会增多,向用户进行推荐时需要计算更多相似用户兴趣区域的推荐得分。因此阈值下降,算法的执行时间增多。从图5可以看出基本算法执行时间比改进算法执行时间增加得更快。因为基本算法会产生更多的候选模式及大量的连接操作。然而,改进算法不需要产生候选模式,并且它产生模式不需要连接操作。所以改进算法的时间增加的比较缓慢。
图4 事务数目对算法执行时间影响
Fig.4 The impact of the number of transactions
图5 阈值对算法执行时间影响
Fig.5 The impact of thresholds
4.2 准确率、召回率和F值的对比
接下来,我们对比改进算法、基于协同过滤推荐算法和基于关联规则推荐算法三者的推荐质量。这部分实验在真实数据上进行。我们用时间来对真实数据进行分类,分为2007年的数据、2008年的数据、2009年的数据、2010年的数据。2007年数据有10508条、2008年数据有19795条、2009年数据有51170条、2010年数据有10015条。推荐质量的对比算法在这四个数据集上进行。
推荐质量我们用准确率、召回率和F值来衡量。在本文中,我们将准确率定义为:推荐给用户的用户兴趣区域集与用户访问兴趣区域集的交集与用户访问兴趣区域集之比。我们将用户访问过的兴趣区域随机的抹掉一部分,查看推荐给用户的用户兴趣区域列表中包含多少抹掉的用户兴趣区域。
定义7(准确率)表达如下:
定义8(召回率)表达如下:
在准确率和召回率的定义中,m为用户数目,|E(i)|为用户i访问用户兴趣区域被抹掉集合的长度,R(i)为推荐给用户i的用户兴趣区域集合,为用户i被抹掉的用户兴趣区域集合与推荐用户兴趣区域集合的交集的长度。
定义9(F值)表达如下:
其中,P为准确率,C为召回率。
在本组实验中对三种算法的准确率、召回率和F值进行对比,参数设置如表8所示。如图6所示,对比三者可知本文提出的算法准确率优于其他两种算法。当数据量变化时,准确率会受一定的影响,但是从图6中可以看出我们提出的算法波动较小,较为稳定。从图7和图8可以看出,我们提出算法的召回率和F值均优于对比算法。
4.3 top-n中n值对准确率的影响
我们将研究推荐top-n个用户兴趣区域给用户的n值对推荐准确率的影响。如图9所示,随着n值的增加三个推荐算法的准确率也增加,但是improved_algorithm算法优于其他两个算法。从图7中可以看出我们提出的improved_algorithm算法在n=10时,算法的準确率较高,随着n值的不断增加,准确率缓慢的增加。这说明我们定义的用户兴趣区域推荐得分具有一定的合理性。用户访问可能性更高的用户兴趣区域,推荐得分更高,用户兴趣区域排名更靠前。所以当n值增大时,准确率不会急剧上升,因为用户可能访问的用户兴趣区域大部分包含在了top-10中,只会有少量出现在top-10后的推荐列表中。
图8 F值的对比
Fig.8 Comparison of F
图9 top-n中n值对准确率的影响
Fig.9 The impact of n on precision
5 结论(Conclusion)
由于许多推荐算法进行推荐时需要用户的评分信息。这样会因为缺少信息影响推荐质量。本文提出了一种不需要用户评分数据的推荐算法。论文定义了停留区域,通过停留区域间的邻近关系将用户的轨迹数据转化为事务数据,并基于挖掘到的最大频繁项集来定义用户的相似性。最后定义了推荐得分。在模拟数据和真实数据上进行了广泛的实验证明了提出方法的有效性,同时,将我们提出算法和基于协同过滤推荐算法、基于关联规则推荐算法进行了对比,结果显示本文提出算法具有更好的推荐效果。在接下来的工作中,我们将在本文基础上扩展,将其运用于选址。
参考文献(References)
[1] Bao J,Zheng Y,Wilkie D,et al.Recommendations in location-based social networks:a survey[J].GeoInformatica,2015,19(3):525-565.
[2] Xin M,Zhang Y,Li S,et al.A Location-Context Awareness Mobile Services Collaborative Recommendation Algorithm Based on User Behavior Prediction[J].International Journal of Web Services Research (IJWSR),2017,14(2):45-66.
[3] Wu T,Mao J,XIE Q,et al.Top-κ hotspots recommendation algorithm based on real-time traffic[J].Journal of East China Normal University (Natural Science),2017(5):195-209.
[4] Schafer J B,Konstan J,Riedl J.Recommender systems in e-commerce[C].Proceedings of the 1st ACM conference on Electronic commerce.ACM,1999:158-166.
[5] Berjani B,Strufe T.A recommendation system for spots in location-based online social networks[C].Proceedings of the 4th workshop on social network systems.ACM,2011:4.
[6] Hu L,Chen J,Shen S,et al.Recommendation Algorithm Research Based on Clustering on Users' Trajectories[C].Proceedings of the 29th CCF National Database Conference,2012:250-256.
[7] Liu Y,Pham T A N,Cong G,et al.An experimental evaluation of point-of-interest recommendation in location-based social networks[J].Proceedings of the VLDB Endowment,2017,10(10): 1010-1021.
[8] Agrawal R,Srikant R.Fast algorithms for mining association rules[M].Readings in database systems(3rd ed.).Morgan Kaufmann Publishers Inc.,1996.
[9] Kardan A A,Ebrahimi M.A novel approach to hybrid recommendation systems based on association rules mining for content recommendation in asynchronous discussion groups[J].Information Sciences,2013(219):93-110.
[10] Yi C,Leung H F,Li Q,et al.Typicality-Based Collaborative Filtering Recommendation[J].IEEE Transactions on Knowledge & Data Engineering,2014,26(3):766-779.
作者简介:
龙玉绒(1994-),女,硕士生.研究领域:数据挖掘.
王丽珍(1962-),女,博士,教授.研究领域:数据挖掘,计算机算法.本文通讯作者.
陈红梅(1976-),女,博士,副教授.研究领域:数据挖掘,人工智能.
