基于多智能体的PC构件生产线智能调度系统
2019-12-05李旭红王佳佳张泉东潘欣宇曾晓文
李旭红,王佳佳,张泉东,潘欣宇,曾晓文
(1.江苏省生产力促进中心,南京 210042;2.江苏科技大学 机械工程学院,镇江 212003;3.江苏汤辰机械装备制造股份有限公司,镇江 212413)
0 引言
建筑工业化已成为国际建筑行业发展的主流,混凝土预制件的工业化生产是建筑工业化的一个重要环节,目前大多数国内混泥土预制件生产线的智能化和信息化水平不高,响应我国颁布的《中国制造2025》和“两化融合”战略[1~3],本文以PC构件(预制混凝土构件)生产线为研究对象,对基于多智能体(Multi-Agent)的PC构件生产线智能调度系统进行研究。
1 PC构件生产线调度系统分析
PC构件自动化生产线是由配料系统、配模系统、输送系统、堆垛养护系统等系统模块所组成,如图1所示,PC构件生产线爆炸图。
实现PC构件生产线设备的智能调度,首先要重点解决设备的三大问题:聋、哑、傻。治聋,要求PC构件生产设备具有较强的感知外部信息的能力和允许外部信息输入的功能;治哑,则要求PC构件生产设备具有较强主动发送自身状态信息的能力;治傻,则要求PC构件生产设备具有逻辑处理和分析判断能力[4,5]。
2 PC构件生产线多智能体调度系统模型

图1 PC构件生产线爆炸图
在PC构件生产线的Multi-Agent控制系统中,根据工作内容可分为4大模块,分别为配料、配模、输送、养护。各个模块的工作都由其下的各个设备Agent共同完成,然而任何一个设备Agent都没有全局信息,只具备局部信息和知识,并且PC构件生产线存在大量的协作关系,因此各个设备Agent之间的信息交换是协同工作的基本保障。
考虑协作的需要,在各工作模块中设立代理Agent,其可以是该工作模块下的一台资源设备,也可以是外加的一个独立Agent。代理Agent将其下各个设备智能体信息包括:工作状态、故障信息、健康状态等,进行收集汇总,然后与其他工作模块的代理Agent进行信息交换,实现PC构件生产线全部设备的互相感知,最终保证协同运作的实现。具体模型如图2所示,代理Agent分别为:配料Agent、配料Agent、输送Agent、养护Agent,代理Agent的设备Agent通过对几乎拥有全局信息的代理Agent进行信息读写,从而实现对全局设备信息的认知[6]。
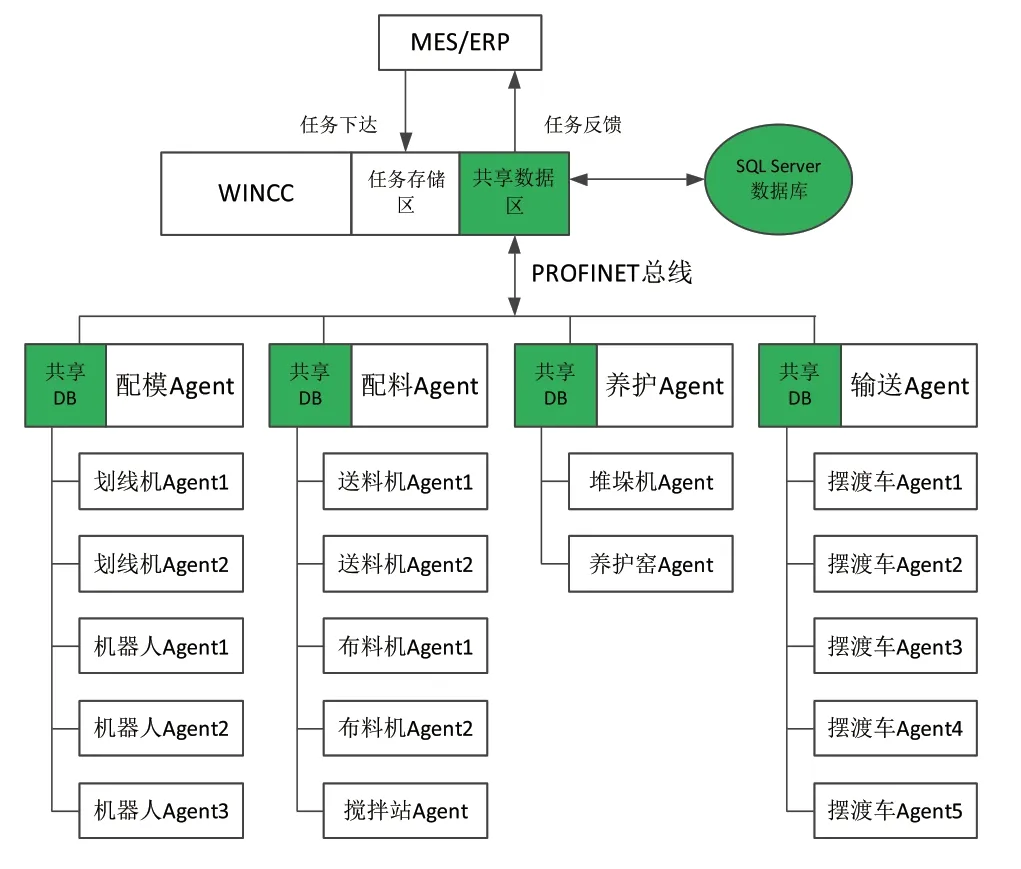
图2 PC构件生产线多智能体调度系统模型
3 关键调度问题解决方法
3.1 基于黑板会话的数据交互
综合考虑上述PC构件生产线多智能体调度系统模型,本文建立以黑板会话机制为基础的双层黑板会话模型[7,8],如图3、图4所示,在双层黑板会话模型中,第一层为代理Agent与子设备Agent之间的黑板模型,第二层为最高管理层Agent与代理Agent之间的黑板模型。

图3 双层会话第一层模型
其中,代理Agent(包括配料Agent、配模Agent、输送Agent、养护Agent)的部分数据存储区,作为其子设备Agent的公共访问区,即共享数据存储区,任何子设备Agent都可以对其代理Agent的共享数据存储区读写数据。代理Agent的公共数据访问区就是第一层黑板,作为数据交换的一个枢纽。

图4 双层会话第二层模型
其中,最高管理层Agent的部分数据存储区,作为代理Agent的公共访问区,即共享数据存储区,任何代理Agent都可以对最高管理层Agent的共享数据存储区进行读写数据。最高管理层的公共数据访问区就是第二层黑板,作为数据交换的另一个枢纽。
3.2 任务竞标规则
当今主流的协商机制包括:协作规划机制、合同网机制、FA/C法机制等,虽然合同网机制与Multi-Agent系统契合度较高,但因为PC构件生产线为典型的流水线生产方式,各个工作模块相对独立和唯一,工作模块之间不可彼此代替,所以合同网机制在Multi-Agent系统中不完全适用。
综合考虑Multi-Agent系统的自适应适需求,再结合PC构件生产线的协作控制具体情况和控制要求,本文采用协作规划机制与合同网机制相结合的混合协商机制[9~12]。在管理Agent与代理Agent之间采用协作规划机制,代理Agent与其子设备Agent之间采用合同网机制。混合协商机制如图5所示。
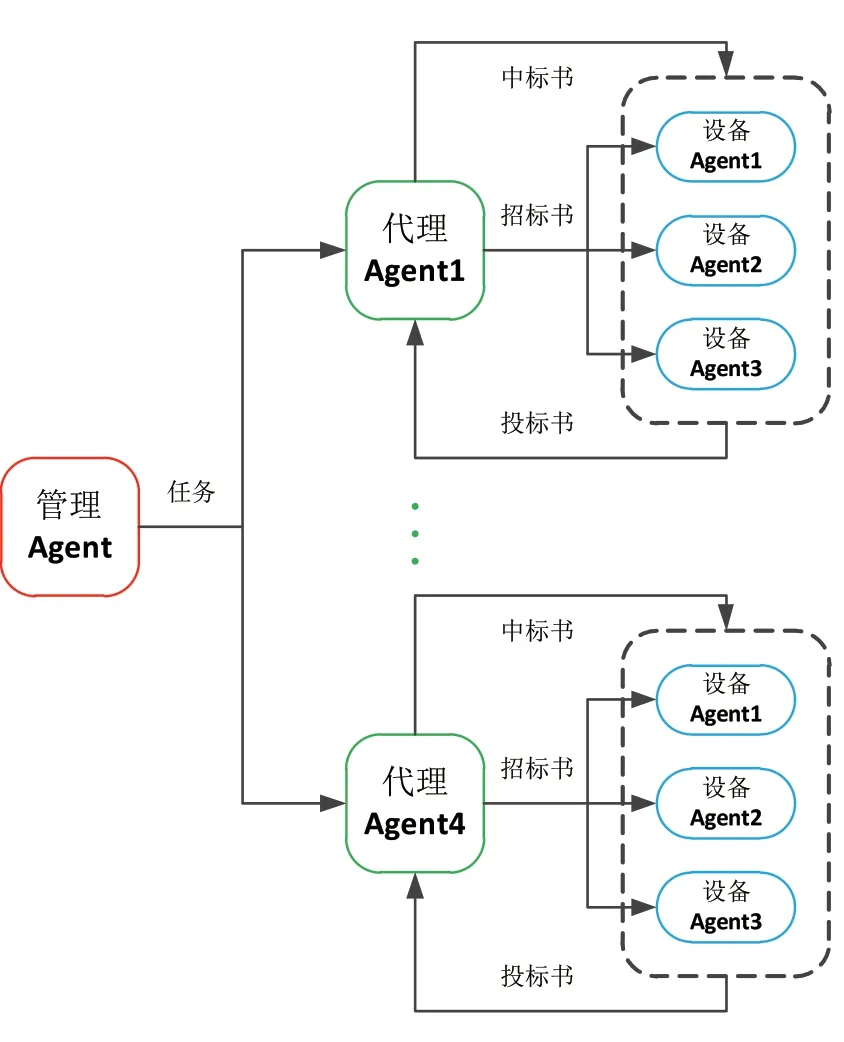
图5 混合协商机制
首先,管理Agent将任务信息分配给各个代理Agent,任务信息包括任务描述、任务截止日前、任务质量要求等。代理Agent将来自管理Agent的任务通过招标的方式传达给其设备Agent,设备Agent通过各自的评估模块进行任务评估和自我能力评估,设备Agent根据评估结果来决定是否要进行投标。自我评估满足要求的设备Agent会向代理Agent发送投标申请,代理Agent接受到来自设备Agent的投标请求时,进行二次评估筛选,最终将任务下达给指定设备Agent进行执行。
此外,系统具有动态调整特性。当有紧急任务插入时,代理Agent会将该任务的优先级设为最高,优先进行任务招标。当生产线中出现设备故障时,设备Agent会马上将自身设置为故障状态,在系统进行任务招标时,会自动避开对该设备的任务招标。当该设备Agent故障解除后,又会重新将自己恢复为任务待命状态,并告知其代理Agent,等待任务招标的到来。
3.3 基于KNN的机器学习的能耗评估算法
K近邻(k-Nearest Neighbor,KNN)算法,是一种理论上比较成熟的算法,也是最常用机器学习算法之一。该算法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别[13~15]。
由于PC构件重量的不同、设备运行速度的不同、设备运动加减速时间等生产工艺参数的不同,导致生产能耗不同,生产能耗难以通过直接计算得到。下面以清扫机、划线机1、划线机2和摆渡平车组成的h调度模型为例,如图6所示,进行具体的KNN机器学习能耗评估算法设计。

图6 h评估调度模型
目标为划线机1时:
PC构件完成清扫工序后,运动到达划线机1耗能记为,energy1;能耗enery1=加速阶段能耗+恒速阶段能耗+制动阶段能耗。
其中,加速阶段和减速阶段的具体能耗不方便直接计算,恒速运动距离难以确定而导致恒速运动能耗难以计算。由于运动构件重量是PC构件重量与模台重量之和,其中模台的重量固定,地滚驱动轮的运送方式固定,又因为能耗不会产生跃变,定为连续变化,上述特征满足KNN机器学习算法的基本条件,因此,本系统从理论上讲,可以采用KNN机器学习算法进行生产能耗的评估。
首先,通过手动或者默认经验值进行生产线的初步运作,产线设备将每一种状态信息(PC板的重量、加速时间、减速时间、最高速度等参数),所对应的生产能耗记录下来,可以存储在SQL等数据库中,也可以存储在云端。原始数据如表1所示,目标数据如表2所示。多条相同生产线可以将各自的状态信息都存储到一个云端中,实现信息数据资源共享。
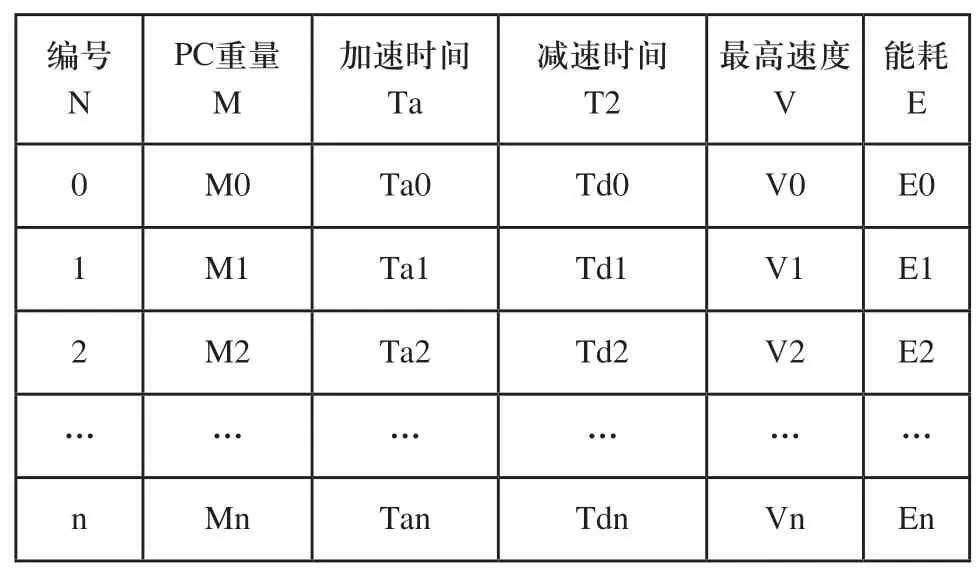
表1 原始数据
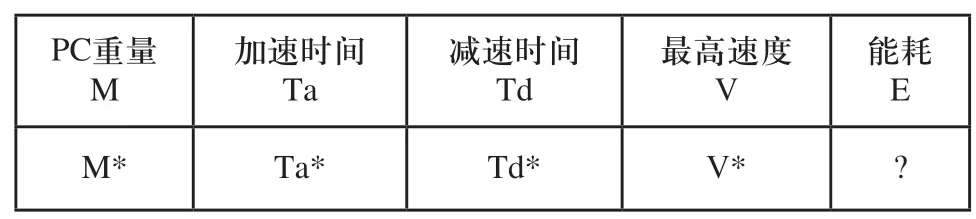
表2 目标数据
对原始数据和目标数据进行标准化处理后,转化成服从标准正太分N(0,1)的数据,通过KNN算法,求解目标数据与原始数据欧式距离d最近的5条数据,如式(1)所示。

求解出最近邻5条数据能耗分别为:E1、E2、E3、E4、E5,目标数据能耗取5个数据的平均值,如式(2)所示。

目标为划线机2时:
PC构件完成清扫工序后,运动到达划线机2的耗能记为,energy2。能耗energy2=地滚驱动轮能耗+摆渡平车能耗。
其中地滚驱动轮能耗=2个加速阶段能耗+2个恒速阶段能耗+2个制动阶段能耗;其中摆渡平车能耗=空载能耗+载板能耗,空载与载板能耗皆包括:加速阶段能耗、恒速阶段能耗、制动阶段能耗。如同目标为划线机1,本系统从理论上讲,可以通过KNN机器学习算法进行生产能耗的评估计算。计算过程与目标为划线机1时类似,具体过程此处不再鳌述。
KNN机器学习算法好坏的评判标准是通过均方根误差来进行评判的,具体方法是将样本分类成训练集TRAIN_LIST和测试集TEST_LIST。其中,训练集占样本比例为75%,测试集占样本比例为25%(比例值可以随具体情况进行调整)。
首先,将测试集TEST_LIST中的数据进行KNN计算,并得到预测值predicted_1~predicted_N。然后求解预测值和真实值(actual_1~actual_N)的均方根误差RMSE。很明显,预测值与真实值的均方根误差RMSE的值越小表示误差越小,算法模型效果越好。
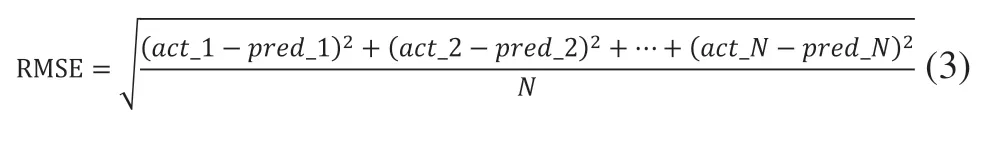
式中,RMSE为均方根误差;
act_1~act_N为真实值;
pred_1~pred_N为预测值。
3.4 基于配方的综合评估调度算法
在PC构件生产过程中,对于生产速度的要求会随着订单堆积度而有所不同。订单堆积度的数学表达式,如式(4)所示。

式中,LN为产线待生产产品数量;
VN为产线平均生产速度;
综合考虑产线评估得分,求解综合评估得分,如式(5)所示。

式中,β为综合评估得分;
T为时耗评估得分;
E为能耗评估得分;
θ1为时耗权重系数;
θ2为能耗权重系数;
其中,时耗权重系数θ1、能耗权重系数θ2和订单堆积度服从一定的函数关系。宏观而言,时耗权重系数θ1,随订单堆积度的增大而增大,能耗权重系数θ2随订单堆积度的增大而减少。
本系统采用配方的方式,进行权重参数配定。首先,对订单堆积度进行区间限定,为了便于处理,可将订单堆积度映射到区间[0,10]上,然后,进行量化取值,本系统可量化为11个等级{1,2,3,4,5,6,7,8,9,10,11}。配方表如表3所示。
综合评估得分是调度选择的重要指标,但是评估的最终结果,仍然需要考虑优先级最高的环境评估和健康评估,当环境评估和健康评估生效时,就会自动屏蔽综合评估得分β。

表3 配方表
4 试验仿真
4.1 基于KNN机器学习的能耗评估算法仿真试验
实验所用历史数据由江苏汤辰机械装备制造有限公司提供,本数据为江苏汤辰机械装备制造有限公司与江苏科技大学合作研发的PC构建自动化生产线的生产数据,本数据具体来自该生产线上位机软件WINCC的3000多条数据记录。该历史数据存储在CSV文件中,文件名为PC_data.csv,如图7所示。
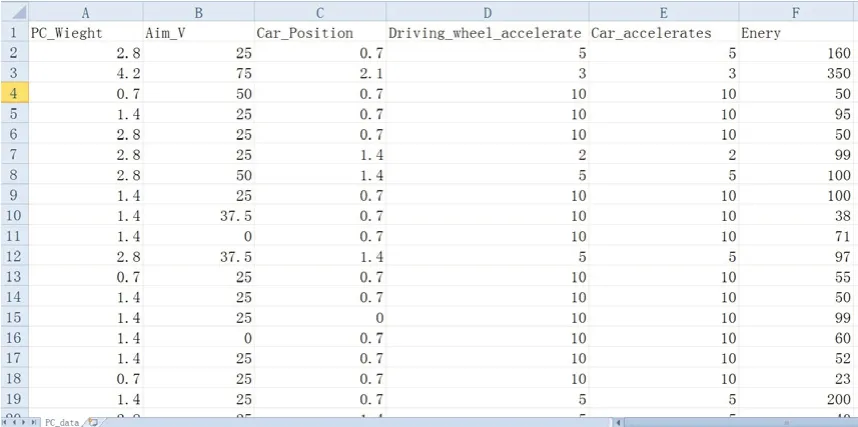
图7 生产线历史数据
通过调用Python的可视化库matplotlib,将原始数据、标准化数据和归一化数据同时显示在一张图表中,图8所示。标准化后的数据被转换为服从标准正太分布的数据,其均值为0,标准差为1;归一化后的数据被归一到区间[0~1]上。

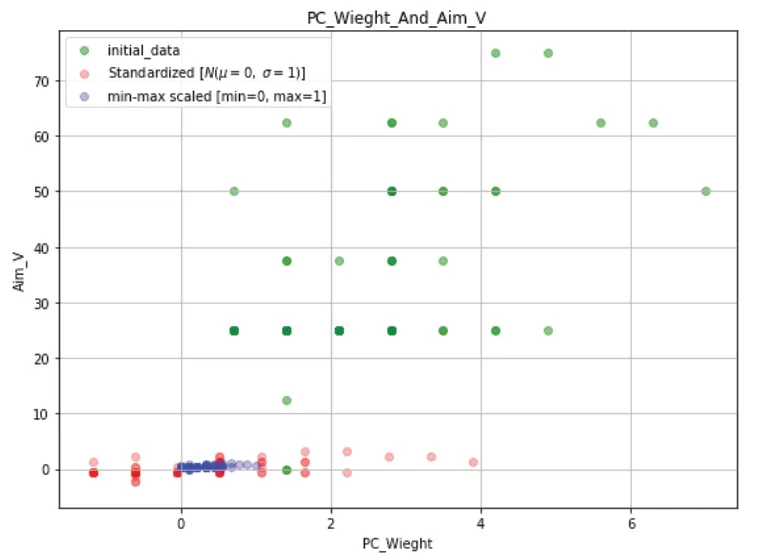
图8 可视化显示
基于多变量的KNN机器学习评估调度算法仿真实验,首先,对全部变量PC构件质量(PC_Wieght),目标运行速度(Aim_V),摆渡平车位置(Car_Position),驱动轮加减速时间(Driving_wheel_accelerate),摆渡平车加减速时间(Car_accelerates),最终能耗(Enery)进行标准化处理,具体程序代码与程序输出,如图9所示。
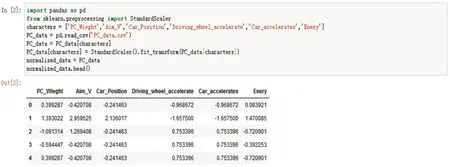
图9 数据多变量标准化处理程序
构建多变量欧式距离计算函数forecast_Enery_multivariate(),求解各个变量测试集test_set中全部数据的欧式距离,选择欧式距离最小的五组数据求均值,从而得到每条数据的预测能耗值forecasted_enery,最后,求解测试集数据的预测能耗值与真实能耗值之间的平方根误差rmse,具体程序代码与程序输出,如图10所示,rmse=0.85,表明多变量的KNN机器学习评估调度算法对能耗预测的预测精确度比较理想。

图10 预测评估求解程序
4.2 基于HMI配方的变评估权重系数设计仿真
如图11所示,通过WINCC的Simulation仿真模块,对订单堆积度进行随机变量配置,其中变化范围为1~11,然后启动随机变量仿真。
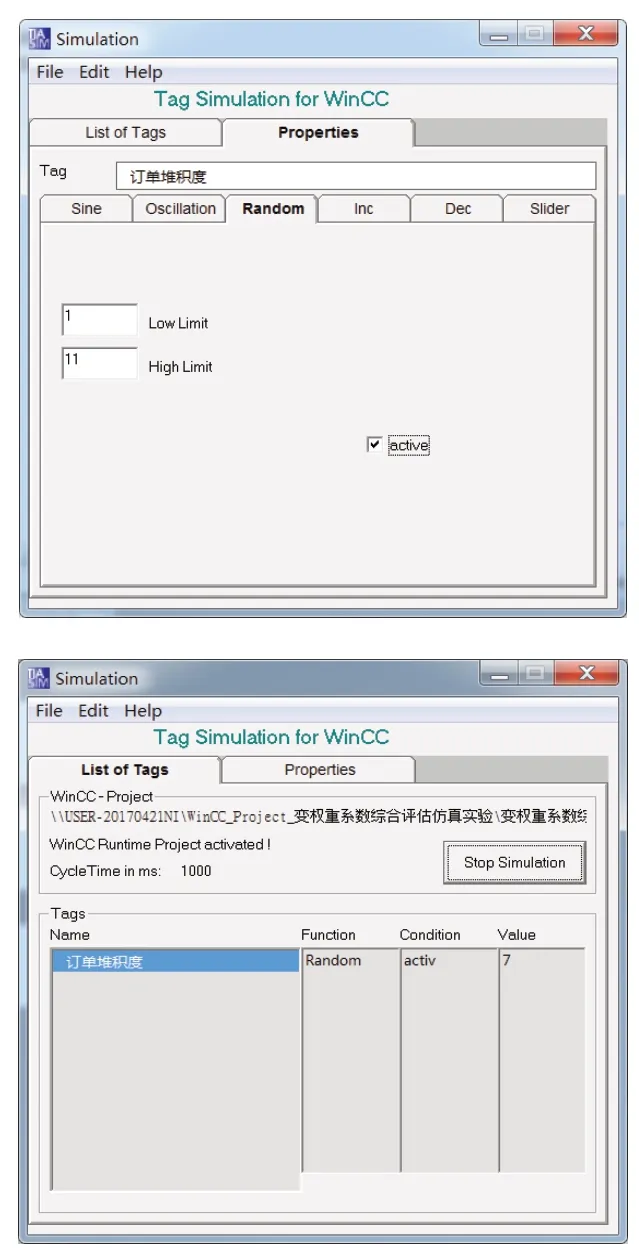
图11 订单堆积度的Simulation配置
如图12所示,时耗权重系数和能耗权重系数都是与堆积度有一一对应的关系,其中,时耗权重系数随堆积度的增大而增大,即耗权重系数与堆积度呈正相关关系,其中,能耗权重系数随堆积度的增大而减少,即能耗权重系数与堆积度呈负相关关系。
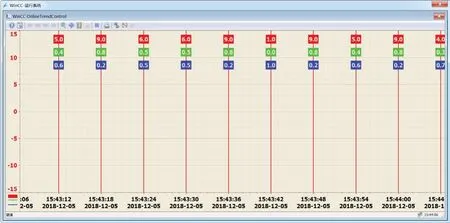
图12 变权重系数仿真图
在实际的工程应用中,变权重系统有很多种实现方式,其中,配方的方法是工控自动化领域中非常常用的变系数分配法。如图13所示,在HMI软件EPRO的配方系统中,通过对堆积度(Plugging_degree)、时耗权重系数(Time_parameter)、能耗权重系数(Enery_parameter)建立配方库(formula)。系统实际运算时,通过配方索引(堆积度)对配方权重参数进行查找取值。
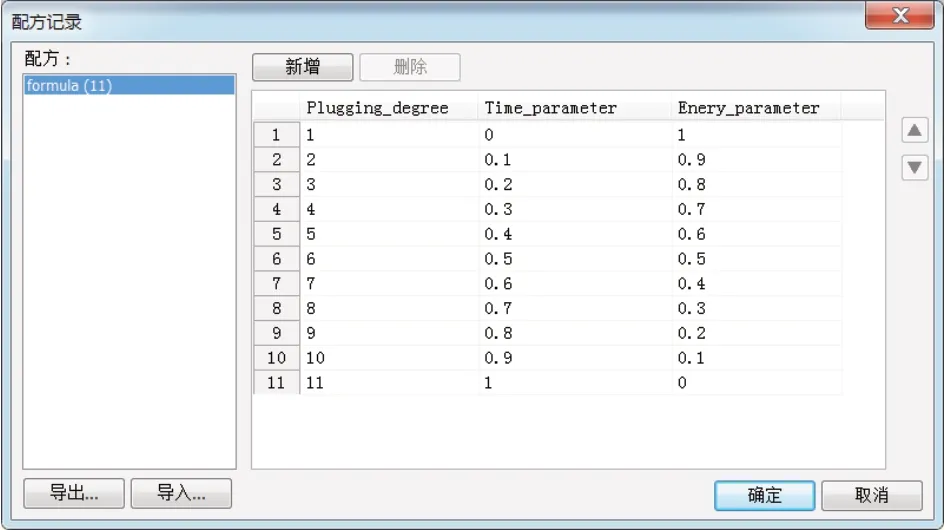
图13 变权重系数仿真图
5 结语
本文通过分析PC构件生产线调度系统的动态复杂性,提出了一种基于多智能体的PC构件生产线的智能调度系统。结合PC构件生产线工艺流程,划分配置了多智能体模块,并重点解决了双层黑板会话、基于合同网机制的竞标、基于KNN机器学习的能耗评估算法和基于配方的综合评估调度算法等问题。
1)通过Python进行KNN能耗评估算法试验仿真,证实了该评估算法的准确性较为理想;
2)通过WINCC的Simulation仿真模块,对订单堆积度进行随机变量配置,动态展示了动态权重系数的综合调度评估算法,并给出了基于HMI配方的可行性方案。
3)本系统很好的将多智能体理论试应用于PC构件自动化生产线的调度系统中,对PC构件工业化生产建立更完善的理论体系具有重要意义。
